基于相似性的CITCP强化学习奖励策略①
2022-05-10潘超月曹天歌
杨 羊,潘超月,曹天歌,李 征
(北京化工大学 信息科学与技术学院,北京 100029)
1 引言
持续集成环境允许代码频繁地集成到主干上以进行软件的更改[1].持续集成测试用例优先排序针对每次集成连续地进行测试用例执行序列的调整,以保障持续集成的每次修改没有引入新的错误[2].基于强化学习的持续集成测试用例优先排序技术[3],通过历史经验的学习自适应地进行测试用例优先排序策略的调整,以适应持续集成环境的变化,其框架被定义为reinforced test case selection (RETECS).
强化学习与持续集成测试用例优先排序的交互如图1所示.强化学习主要包括环境、智能体、动作和奖励4 个元素[4].针对持续集成测试用例优先排序,环境是持续集成周期,环境中的状态是在每一集成周期提交的测试用例的元数据,包括测试用例预计运行时间和测试用例历史执行结果等;智能体是依据历史经验进行测试用例优先排序决策的中枢;动作是智能体根据历史学习的策略进行当前持续集成周期测试用例优先级排序结果的返回;奖励是对当前测试用例优先排序策略的反馈,通过评价当前集成周期测试用例执行结果以实现奖励.
强化学习是一种基于奖励机制的机器学习方法,核心是通过奖励函数对当前行为进行有效的评估,并反馈给智能体选择合适的后续行为,以实现期望的最大化.基于强化学习的持续集成测试用例优先排序技术,通过对测试用例实施奖励以实现测试用例优先排序策略的调整,从而最终提高持续集成测试用例优先排序的质量.测试用例的奖励包括奖励函数设计方法和奖励对象选择策略.Yang 等人[5]系统化研究了奖励函数设计方法,提出了基于历史信息的奖励函数,通过提取测试用例历史信息序列的特征以实现测试用例检错能力的度量,可以实现测试用例优先排序效果的优化.
奖励对象选择策略通常选择执行失效测试用例作为奖励对象实施奖励.然而,实际工业软件持续集成测试具有集成高频繁和测试低失效的特点.例如,在Google开源数据集GSDTSR 中,共集成336 个周期,其中284个周期存在执行失效,涉及5 555 个测试用例的1 260 618次测试执行,其中失效执行只占0.25%.在基于执行失效的奖励对象选择策略下,持续集成测试的低失效会引发奖励对象稀少,从而导致强化学习奖励稀疏问题,减缓了强化学习速度,甚至可能导致智能体生成高随机的策略[6],难以真正应用于实际工业生产环境中.如何解决基于强化学习的持续集成测试用例优先排序技术在实际工业环境中产生的奖励稀疏问题,是本文的研究重点.
奖励稀疏问题的核心是奖励对象稀少,可以通过增加奖励对象来解决奖励稀疏问题.测试用例优先排序旨在优先执行潜在失效测试用例.当前执行失效的测试用例,基于失效测试与测试失效的相关性[7],在后续测试执行中具有较大的失效可能性,该理论不适用于执行通过的测试用例.在测试用例优先排序中考虑测试用例之间的依赖关系,理论上会使排序结果更优,但依赖性分析特别是大规模程序的依赖性分析是一个非常耗时的过程,难以满足持续集成测试的快速反馈需求.在测试用例优先排序中考虑测试用例之间的相似关系,即基于相似性的测试用例优先排序[8],通过测试用例间的相似性度量,优先执行有相同特征的测试用例,可以有效提高测试序列的检错能力.因此,本文基于相似测试用例的假设,提出一种测试用例相似性的度量方法,并选择与失效测试用例集相似的通过测试用例实施奖励,以解决奖励对象稀少导致的强化学习奖励稀疏问题.
根据集成测试的快速反馈需求,Bagherzadeh 等人[9]认为持续集成测试用例优先排序的最优序列为检错能力高并且执行时间短的序列,即优先执行检错能力高的测试用例,在相同的检错能力下优先执行运行时间短的测试用例.因此,本文针对测试用例相似性度量考虑以下两个因素.首先,测试用例的历史执行信息序列相似的测试用例具有相似的检错能力,即两个测试用例在历史执行过程中执行结果相似,在后续测试中执行结果可能相同.所以选择与失效测试用例历史执行信息序列相似的执行通过测试用例实施奖励,有助于在后续测试中提升高检错能力测试用例的执行顺序.其次,在第一个条件的基础上,具有相似执行时间的测试用例有利于优化测试执行时间,从而提升反馈速度.
本文通过历史信息序列特征和执行时间设计了一个多维度相似性度量方法,通过增加奖励与执行失效测试用例相似的执行通过测试用例,解决强化学习奖励稀疏问题,从而实现基于强化学习的持续集成测试用例优先排序技术在实际工业界的应用.最终,在大规模工业数据集上验证了基于强化学习的持续集成测试用例优先排序在基于相似性的奖励对象选择策略下的有效性.
2 基于相似性的奖励对象选择策略
基于强化学习的持续集成测试用例优先排序通过历史经验的学习,尽可能多地奖励潜在失效测试用例,通过测试用例优先排序策略的调整以实现在后续测试中优先执行失效测试用例.基于失效测试与测试失效的相关性[7],当前执行失效测试用例在后续测试中具有更大的潜在失效可能性,智能体对其实施奖励有助于提高测试用例优先排序效果.然而实际工业程序中低失效的持续集成测试导致基于强化学习的持续集成测试用例优先排序奖励对象稀少,即奖励稀疏,减缓了强化学习的速度,甚至形成难以收敛的高随机策略.
为了解决强化学习的奖励稀疏问题,在奖励失效测试用例的基础上,基于测试用例相似性假设[8],本文针对执行通过测试用例与执行失效测试用例进行相似性分析,从而实现对执行通过测试用例实施奖励,并提出基于相似性的奖励对象选择策略.
2.1 持续集成测试用例特征分析
基于相似性的测试用例优先排序技术在回归测试中证明了存在相似性的测试用例拥有相似的错误检测率[8],并且具有潜在失效可能的测试用例倾向于聚集在连续的区域[10].
相似性度量的概念是许多研究领域的研究主题.两个物体共有特征的程度被称为相似性,它们不同的程度被称为距离.许多软件测试文献量化了测试用例之间的相似性,例如在基于覆盖的测试优化中,使用覆盖信息进行测试用例之间相似性的度量[11].测试用例的相似性度量因素还涉及测试路径[12,13]、测试用例相关源代码[14]、测试输入和输出[15]、从测试脚本中提取的主题模型[16]、测试用例的历史失效信息[17]等.
在基于强化学习的持续集成测试用例优先排序中,智能体根据历史学习的策略针对测试用例元数据进行识别以产生测试用例优先排序结果.测试用例元数据通过持续集成测试日志的提取,包括Cycle、ID、Duration、LastRun、LastResults和Verdict,这些属性及其解释如表1所示.

表1 测试用例元数据
针对在同一周期的测试用例,根据当前执行结果的不同,即Verdict的不同,可以有效地识别失效测试用例对被测系统的失效影响.对于执行通过测试用例,基于Verdict 无法度量其失效影响,然而其历史执行结果LastResults 可以描述其在历史执行过程中的失效情况.针对历史执行过程相似的测试用例,其在未来执行中可能有相同的测试结果.因此,可以基于测试用例的历史执行过程进行测试用例的相似性度量.
持续集成测试是一种黑盒测试方法,在快速反馈需求下,基于黑盒测试的测试用例执行时间,在相近测试内容下其执行时间非常接近.测试用例优先排序旨在优先执行潜在失效测试用例.在实际工业程序中,潜在失效的测试用例可能与执行失效测试用例不完全相同,但是非常相似,例如,当新测试用例是旧失效测试用例的修改版本时,新测试用例可以捕捉未检测到的系统故障,但是当前执行通过.新测试用例与旧测试用例的执行时间Duration 非常接近或者相同.因此新测试用例由于与旧测试用例相似,并且具有类似的执行时间,具有相似的失效影响,在后续测试中应该被优先执行.
基于测试失效的假设,失效测试用例对被测系统具有失效影响,智能体对其实施奖励.本文通过提取测试用例的历史执行信息序列LastResults 与测试执行时间Duration 进行执行通过测试用例与执行失效测试用例集的相似性度量,以识别执行通过测试用例集中具有失效影响的测试用例,从而实现奖励的实施.
2.2 测试用例相似性度量方法
测试用例的相似性度量,通过提取测试用例的特征以实现测试用例间的相似性计算.本文针对持续集成测试用例使用历史执行信息序列LastResults和执行时间Duration 信息,进行测试用例的特征向量定义,如定义1 所示.
定义1.测试用例的特征向量(feature vector of test case).
其中,totalTimei表示持续集成i周期的计划执行时间,t.durationi表示测试用例t在i周期的执行时间,是测试用例t在i周期执行时间的归一化,t.lastresultsi表示测试用例t在i周期测试执行后的历史执行信息序列.
测试用例的特征向量通过测试用例的特征提取以实现测试用例间的相似性度量.本文通过测试用例的历史执行信息序列和执行时间的属性,进行测试用例的特征提取,定义了测试用例的特征向量,并进一步根据特征向量进行两两测试用例间的特征距离计算以实现相似性计算.
相似性函数通过两两测试用例间的特征距离计算以度量测试用例相似程度.相似性距离计算的常用方法包括杰卡德距离[11]、Gower-Legendre[18]、Sokal-Sneath[19]、欧氏距离[20–22]、余弦相似性[23]和比例二进制距离[21,24,25]等.Wang 等人[26]通过深入研究了这6 种常用相似性计算公式对基于相似性的测试用例优先排序效果的影响,研究表明欧氏距离比其他相似性距离计算公式更有助于进行测试用例优先排序,从而更有效地发现程序错误.因此,本文采用欧氏距离进行持续集成测试的测试用例相似性函数计算,通过特征向量的逐一比较实现测试用例的相似性度量,其相似性计算函数如定义2 所示.
定义2.测试用例相似性函数(test case similarity,TCS).
其中,t1表示执行通过测试用例,t2表示执行失效测试用例,Featurei(t1j)表示测试用例t1在第i集成周期的特征向量的第j个特征,n是测试用例t1和t2的最短有效历史执行序列长度.由于在持续集成测试中测试用例出现的频率不同,导致测试用例的历史执行信息序列长度不同.为了有效地进行特征向量的比较,基于失效测试与测试失效的相关性[7],本文依据测试用例中历史信息序列较短的序列长度,选择临近历史信息序列进行相似性的计算,从而实现全面测试用例相似性比较.
测试用例相似性函数通过两两测试用例的特征向量距离计算,以实现测试用例的相似性度量.距离越小,即相似性值越低,表明这两个测试用例越相似.
2.3 基于相似性的奖励对象选择方法
基于失效测试与测试失效的相关性[7],失效测试用例具有较高的检错能力,在后续测试中需要进行优先级的提升,因此智能体优先对失效测试用例实施奖励以实现测试用例优先排序策略的调整,使其适应后续持续测试.然而,持续集成测试的低失效特征,即失效测试执行稀少,导致基于强化学习的持续集成测试用例优先排序奖励对象稀少,导致奖励稀疏问题,影响了强化学习的学习速度和学习质量.
在持续集成测试中,对于当前执行通过测试用例,一方面存在频繁失效、偶然通过的测试用例,另一方面存在测试用例是旧测试用例的修复版本.这些测试用例在后续测试中存在失效可能性,因此具有一定的失效影响,然而无法基于当前执行结果进行有效的度量.为了有效度量执行通过测试用例的失效影响,本文通过与执行失效测试用例的相似性分析,以选择执行通过测试用例集中与执行失效测试用例相似的测试用例实施奖励,进一步提出基于相似性的奖励对象选择策略.智能体针对执行通过测试用例,使用与执行失效测试用例的相似性分析方法,实现执行通过测试用例的失效影响分析,从而增加奖励与执行失效测试用例相似的执行通过测试用例.
针对在某一集成周期的测试用例集,在测试执行后,智能体首先对失效测试用例进行奖励,进一步将执行通过测试用例逐一与失效测试用例集进行相似性分析以寻找具有失效影响的执行通过测试用例.若执行通过测试用例与执行失效测试用例存在相似性,则该执行通过测试用例具有失效影响,智能体应该奖励该测试用例,否则执行通过测试用例不被奖励.其执行流程如图2所示.根据其执行过程,本文进一步定义了基于相似性的奖励对象选择策略如定义3 所示.
定义3.基于相似性的奖励对象选择策略(similaritybased reward object selection strategy).
对于第i个周期的测试套件Ti={t1,t2,…,tj,…,tn},如果测试用例tj执行失效,则奖励测试用例tj;若测试用例tj执行通过,但测试用例tj与Ti中的失效测试用例t′存在相似性,即则奖励测试用例tj;其他情况智能体不奖励测试用例.
基于相似性的奖励对象选择策略的奖励方式,如式(3)所示.
其中,rewardvalue是基于任意奖励函数计算的测试用例的奖励值,t.verdict表示测试用例t的执行结果,1 表示执行失效,0 表示执行通过,t′是该周期中任意执行失效测试用例.
本文通过持续集成测试用例的特征分析,提出考虑测试用例历史执行信息序列和执行时间的多维度测试用例特征向量表示方法,并进一步基于特征向量进行测试用例间的相似性度量.基于测试用例的相似性特征,本文提出基于相似性的奖励对象选择策略,在奖励失效测试用例的基础上,通过相似性的判断,自适应地选择执行通过测试用例进行奖励以解决在实际工业程序中的奖励稀疏问题.
3 实验设计及结果分析
基于强化学习的持续集成测试用例优先排序过程如图3所示,其中虚线部分存在于持续集成环境中,实线部分存在于强化学习框架中.对于每个集成周期中提交的测试用例集,强化学习的智能体根据历史学习的测试用例优先排序策略定义测试用例的优先级,进一步根据快速反馈的时间约束选择测试用例以进行测试排序从而实现测试执行,最后根据执行结果进行评价并反馈给开发人员和强化学习的智能体.智能体根据反馈的结果选择测试用例实施奖励,即奖励对象选择策略,并进一步根据奖励的结果为后续集成测试调整测试用例优先排序策略,使其适应于持续集成系统的连续变化.
3.1 研究问题
本文针对在实际工业程序存在集成高频繁但是测试低失效的特征,在基于强化学习的持续集成测试用例优先排序中研究奖励对象稀少导致强化学习的奖励稀疏问题,提出基于相似性的奖励对象选择策略.本文从以下3 个研究问题进行实验的分析和验证.
问题1.在基于相似性的奖励对象选择策略中,如何进行相似性阈值的选取,从而实现持续集成测试用例优先排序?
问题2.基于相似性的奖励对象选择策略对基于强化学习的持续集成测试用例优先排序质量的影响如何?
问题3.基于相似性的奖励对象选择策略对基于强化学习的持续集成测试用例优先排序框架的时间开销影响如何?
问题1 通过不同阈值下基于相似性奖励对象选择策略对测试用例优先排序效果的影响研究,选择适合目标程序的最佳阈值.问题2 通过基于相似性的奖励对象选择策略与基于执行失效的奖励对象选择策略进行测试用例优先排序质量的对比,验证基于相似性的奖励对象选择策略的有效性.问题3 是对不同奖励对象选择策略下的框架时间开销进行对比.
3.2 评价指标
本文为了比较不同奖励对象选择策略,在基于强化学习的持续集成测试用例优先排序下对持续集成测试用例优先排序效果通过NAPFD (normalized average percentage of faults detected),TTF (test to fail),Recall和时间开销4 个评价指标进行度量.
(1)NAPFD
平均历史检测率(APFD,average percentage of faults detected)[27]作为测试用例优先排序效果评价的有效方法,在检测到序列中所有错误的假设下,根据测试序列中失效位置的索引进行测试序列的评价.然而,基于强化学习的持续集成测试用例优先排序,使用测试用例选择的快速反馈机制模拟,使得只有占一半执行时间的测试用例被执行,即存在失效的测试用例不被执行.由于APFD 只适用于可以检测到所有错误的测试用例序列,即不存在测试用例选择.因此,Qu 等人[28]于2007年提出APFD的扩展NAPFD,根据实际检测错误率来进行失效分布的计算,适用于存在测试用例选择的测试用例优先排序序列.
NAPFD 作为测试用例优先排序的评价标准[28],其定义为:
根据NAPFD的定义,在持续集成测试中,如果所有的错误均被检测到,则p=1,NAPFD 与APFD 等同;如果存在错误未被检测到,则p<1,基于NAPFD的评价更符合实际情况.
(2)TTF
TTF 根据测试执行中首次执行失效的测试用例在测试序列中的位置进行评价.测试用例优先排序的目标是优先执行失效测试用例.失效位置越靠前,测试用例优先排序效果越好.因此,TTF 可以有效地评价测试用例优先排序的效果.TTF 值越小,即执行失效测试用例在执行序列中位置越靠前,则测试用例优先排序的效果越好.
(3)Recall
为了有效地评价持续集成测试用例优先排序的质量,引入Recall 来评价每一周期实际检测到错误的比例.Recall 根据测试执行序列中实际检测错误与集成周期内实际存在错误的比重进行度量.Recall 在测试选择的基础上,计算占总执行时间一半的测试用例集检测到的错误占该周期实际总错误的比例.Recall 值越高,则执行序列检测的错误越多,相应的测试用例优先排序效果越好.
(4)时间开销
时间开销作为测试用例优先排序技术的重要评价指标,对算法的执行效率进行评价.针对基于强化学习的持续集成测试用例优先排序技术,其时间开销包括奖励计算的时间、智能体的学习时间、测试用例执行信息的更新时间和测试用例优先排序的时间等.
3.3 实验对象及设计
本文针对个6 工业数据集进行相关实验,其中IOF/ROL、Paint Control和GSDTSR为Spieker 等人[3]研究中所使用的数据集,Rails为开源工业数据集(http://gihub.com/elbum/CI−Datasets.git),其他2 个数据集为研究者共享的持续集成测试日志(https://travistorrent.testroots.org/buildlogs/20-12-2016/).测试用例是唯一识别码,在持续集成的不同周期中测试不同的组件,并记录了相关的测试执行结果.表2列出了6 个工业数据集的持续集成测试的详细信息,包括测试用例数、持续集成周期数、持续集成测试执行结果数、持续集成失效率和频率.集成周期不仅给出了持续集成的周期数,并标注了实际测试过程中失效周期数,执行结果数强调的是在整个持续集成过程中测试执行总数,失效率表示持续集成测试过程中测试失效占总测试执行的比例,频率统计了测试用例在每一周期进行测试的概率.
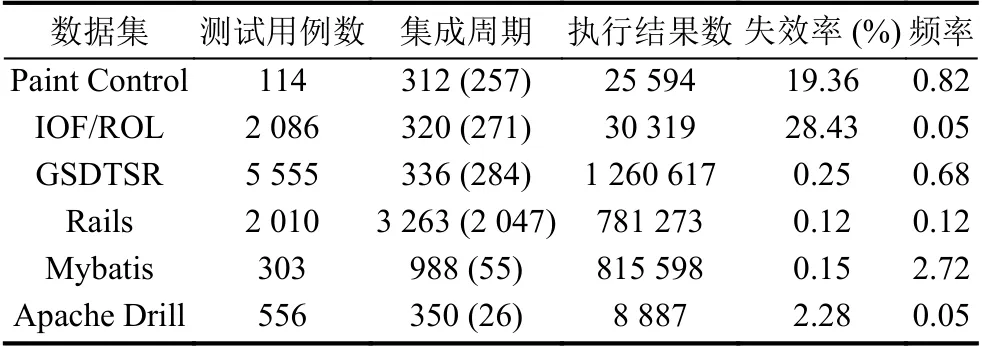
表2 工业数据集信息
在基于强化学习的持续集成测试用例优先排序中,奖励函数设计方法采用目前最优的基于历史信息的奖励函数[5],即基于平均历史失效分布的奖励函数APHF(average percentage of historical failure).在实际工业数据集中,针对庞大历史信息,本文使用滑动窗进行临近历史信息的特征选取[29],即通过提取临近历史信息的特征以实现奖励计算效率的提升.本文基于持续集成测试的连续变化,采用基于动态滑动窗的临近历史信息选择方法,即滑动窗尺寸随着持续集成测试进程动态变化,以实现自适应的奖励计算[30].
3.4 实验结果及分析
本小节分别针对3 个研究问题进行实验结果的展示及分析.
3.4.1 测试用例相似性阈值选取分析
本小节针对问题1 进行实验分析.测试用例相似性通过测试用例之间的特征匹配以实现相似性度量.在基于相似性的奖励对象选择策略中,使用执行通过测试用例与执行失效测试用例进行相似性对比,从测试历史执行信息序列和测试执行时间角度进行多维度特征匹配,从而确定智能体是否对执行通过测试用例进行奖励.由于工业数据集存在不同的失效率、测试频率等特征,在具体数据集中相似性阈值的不同,会导致不同的奖励对象数量,从而产生不同的测试用例优先排序效果.因此需要针对不同的数据集进行相似性阈值的选取分析.
首先对工业数据集进行相似性特征分析,即基于相似性度量方法进行测试用例相似性指标值的分析,图4统计了在6 个数据集上进行测试用例相似性值分析的具体分布情况,针对具体数据集,纵坐标表示基于相似性计算获得的相似性值.由于在不同数据集上测试用例的执行过程和结果不同,导致相似性值的范围不同,并且相似性值存在较多的异常数据,因此为了更好地确定适用于不同数据集的相似性阈值,本文首先依据相似性值的分布针对具体数据集选取相似性值分布的下四分位数、中位数和上四分位数作为基于测试用例相似性的奖励对象选择策略阈值,其统计结果如表3所示.
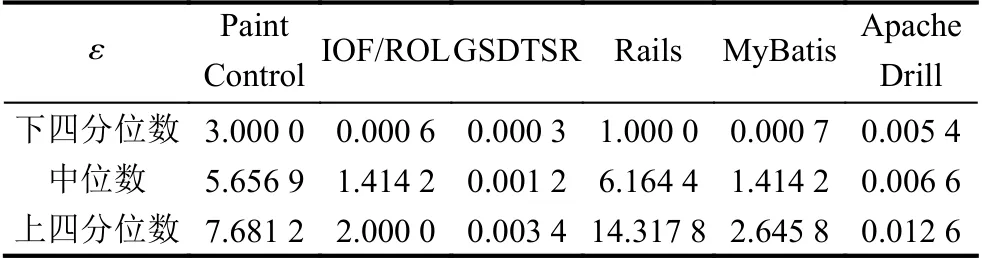
表3 针对工业数据集的测试用例相似性阈值ε 选取
进一步在基于强化学习的持续集成测试用例优先排序中依据基于相似性的奖励对象选择策略,使用不同的相似性阈值进行基于强化学习的持续集成测试用例优先排序,并使用NAPFD 指标进行持续集成测试用例优先排序质量的评价,并实现不同阈值的测试用例优先排序效果的对比,其结果如表4所示,其中加粗字体标注了在该阈值下可以取得最好的NAPFD 值.
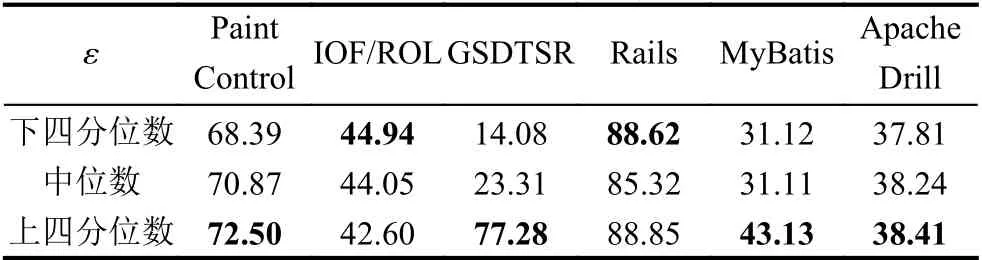
表4 基于不同相似性阈值选取的持续集成测试用例优先排序NAPFD 值(%)
相似性阈值的选取,决定了在基于强化学习的持续集成测试用例优先排序中增加奖励的执行通过测试用例的数量.增加奖励的数量过多,反而会降低失效影响大的执行通过测试用例的优先级;而增加奖励的数量过少,导致部分失效影响大的执行通过测试用例无法获得有效的奖励,从而降低测试用例优先排序效果.
因此针对6 个数据集,本文根据NAPFD的结果对比分别选取Paint Control的7.681 2、IOF/ROL的0.000 6、GSDTSR的0.003 4、Rails的1.000 0、MyBatis的2.645 8和Apache Drill的0.012 6 作为基于相似性的奖励对象选择策略的相似性阈值,以实现在有效的奖励数量增加下获得测试用例优先排序效果优化,为后续实验及分析奠定基础.
3.4.2 基于相似性的奖励对象选择策略有效性分析
本小节针对问题2 进行实验分析.基于相似性的奖励对象选择策略,在奖励失效测试用例的基础上,通过相似性分析自适应地选择执行通过测试用例实施奖励,从而实现奖励对象数量的增加以解决奖励稀疏问题.在基于强化学习的持续集成测试用例优先排序中,本文采用相同的奖励函数设计方法APHF,通过不同奖励对象选择策略,即基于执行失效的奖励对象选择策略(APHF_P)和基于相似性的奖励对象选择策略(APHF_S),在NAPFD、Recall和TTF 三个指标下进行测试用例优先排序质量的对比.实验结果如表5所示,其中加粗数据部分标注了在基于相似性的奖励对象选择策略下,测试用例优先排序评价指标值优于基于执行失效的奖励对象选择策略的情况.
根据表5所示的实验结果,从整体平均上来看,基于相似性的奖励对象选择策略在不同的评价指标上均可以有效地进行指标值的提升,NAPFD 可以获得5.94%的提升,Recall 可以有效地改进5.51%的错误检测率,并且在TTF 上可以有效地提升57.42 个失效测试用例在测试序列中首次执行失效的位置.针对具体数据集的分析可以看出,在6 个数据集上,基于相似性的奖励对象选择策略可以有效改进4 个数据集的测试用例优先排序质量,尤其在GSDTSR 中可以明显提升34.51%的NAPFD 值、34.13%的Recall 值和293.15位的TTF.
在基于相似性的奖励对象选择策略下,通过相似性阈值的判断来增加奖励执行通过测试用例.相比于基于执行失效的奖励对象奖励策略,基于相似性的奖励对象选择策略增加了强化学习的奖励数量,缓解了面向持续集成测试用例优先排序的强化学习奖励对象稀少问题.奖励对象的增加,使得强化学习的智能体可以接收到更多环境的反馈,从而更好地进行测试用例优先排序策略的调整,最终实现测试用例优先排序质量的提升.
综上所述,基于相似性的奖励对象选择策略通过增加奖励与执行失效测试用例存在相似的执行通过测试用例,有效地增加了面向持续集成测试用例优先排序的强化学习奖励对象,解决了强化学习的奖励稀疏问题,并进一步有效地提升了测试用例优先排序效果.
3.4.3 基于相似性的奖励对象选择策略的时间开销分析
本小节针对问题3 进行实验分析.基于相似性的奖励对象选择策略在基于强化学习的持续集成测试用例优先排序中,通过相似性分析以实现测试用例优先排序质量的提升,在一定程度上是以时间开销为代价进行测试用例优先排序质量的提升,理论上增加了基于强化学习的持续集成测试优先排序框架的时间开销.本文进一步在基于强化学习的持续集成测试用例优先排序中使用基于执行失效的奖励对象选择策略和基于相似性的奖励对象选择策略进行时间开销的对比分析,其时间开销展示如表6所示.

表6 基于不同奖励对象选择策略的持续集成测试用例优先排序时间开销(s)
基于强化学习的持续集成测试用例优先排序框架的时间开销,不仅包括了奖励计算的时间、智能体的学习时间和测试用例优先排序的时间,还考虑了奖励对象选择的时间,以及相似性分析的时间.根据表6所示的时间开销结果,明显看出基于相似性的奖励对象选择策略在大部分数据集上均明显增加了时间开销,这是由于在每一周期进行相似性分析增加了相应的时间开销,然而基于相似性的奖励对象选择策略通过解决强化学习的奖励稀疏问题,加速了强化学习的学习速度,因此对于框架整体来说,其平均时间开销的增加均是秒级,是可以接受的时间开销增加.
综上所述,基于相似性的奖励对象选择策略在有限的时间开销增加下,不仅通过奖励对象的增加有效地解决了基于强化学习的持续集成测试用例优先排序奖励稀疏问题,还有效了提升了持续集成测试用例优先排序质量.
4 结论与展望
本文针对工业程序的持续集成测试存在频繁迭代和测试失效低导致奖励稀疏的问题,在基于强化学习的持续集成测试用例优先排序中,依据测试用例的历史执行过程和执行时间提出了基于相似性的奖励对象选择策略,在奖励失效测试用例的基础上,通过选择与失效测试用例存在相似的通过测试用例作为额外奖励对象,有效解决了奖励稀疏问题.提出的方法在有限时间开销增长下,有效地提升了测试用例优先排序效果.
未来进一步研究构建基于强化学习的持续集成测试用例优先排序策略网络.通过自适应学习测试用例的新特征以实现测试用例优先排序策略的调整,从而生成适合后续的测试用例优先排序策略.
