基于银行个人信用评分组合模型的建设银行MS分行的个人信用评分系统的应用研究
2022-05-05李佳成任姿霖
李佳成,任姿霖,王 攀
(四川工商学院经济管理学院,四川 眉山 620000)
前言
自我国实施改革开放政策至今,国内银行业实现了快速稳定发展。目前而言,商业银行的贷款经营模式是依靠信用而进行的,其存在的风险也会在日常治理中体现。商业银行的盈利一直以来也是依靠存贷款利率之差来维持良好的运营。一旦出现大规模的不良贷款,相关的经济链也会受到牵连。考虑到商业银行贷款规模、社会变化影响以及不良贷款发展趋势诸多问题,通过建立一个更完善的信用评分模型,以此来降低不良贷款规模以及不良贷款率,维持商业银行稳定发展是非常必要的。
本文通过主成分分析建立新的银行个人信用评分模型,精确的判断每个客户的信用分数,以此观测对方逾期还款的可能性,在此基础上可以清楚的做出拒绝其贷款请求或者提高贷款利率等决策。由此能提高银行资金的使用率,针对不同信用积分的客户灵活调控贷款利率。
1 国内外文献综述
在国外,陈启伟(2018)等人提出了一种基于梯度提升迭代决策树集成的信用评分模型,使用不同的特征子集和参数干扰的方法,训练得到了多个梯度提升迭代决策树分类器,再使用投票法将所有的基分类器进行集成,实现了信贷客户的风险评估。Wang Bao(2019)等人提出了将无监督学习与监督学习相结合的信贷风险评估组合策略,使用K-Means 对数据集聚类,然后使用自组织映射模型进行训练得到分类器,实现了对信贷客户的分类。[1]
目前国内的信用模型主要分为传统算法和机器学习。为探究两种算法对银行信用评分模型的影响,张杏枝(2019)通过对比Logstic 回归和XGBoost 在银行信用评分中的应用效果,说明了KGBoost 在模型精度和处理缺失值上占优,但计算速度和解释性不如Logistic回归,容易被方差较大的数据和异常值影响。[2]周丽峰(2021)采用随机生存森林建立大数据信用模型,由于大数据的超大数据容量、高度复杂数据类型、信息稀疏性等数据特点,致使模型预测贷款客户的违约风险效果未能达到最佳。[3]
以上国内外文献通过大量的数据与实证分析,对银行信用评分模型从预测精度,主观依赖,解释性,稳定性等方面进行了分析,因此本文放弃采用“黑箱”特点的模型并尽量避免需要专家知识和经验,最后采用以主成分分析为主,灰色关联度和Q 型聚类分析为补充的组合模型。
2 模型设定
2.1 模型构建思路
本文主要对个人的信用风险进行评分及划分信用等级两个目的,由于影响个人信用风险的因素较多,因此本文决定选用主成分分析对数据进行降维处理,并根据其主成分的贡献率建立主成分评分模型。随机选取了总金额额度、信用额度、成功借款次数、借款总额、逾期次数、还清笔数、严重逾期次数、月收入、投资类型九个因素作为模型的原始变量。
主成分综合模型只能对数据进行评分,无法有效的对信用风险划分等级,因此,本文采用灰色关联度对数据样本的优劣进行排序,再以Q 型聚类分析根据灰色关联度的结果划分为五个类别,对应五个信用等级,按照灰色关联度结果对五个类别进行内部排序,选择内部五个灰色关联度最低的样本作为代表两个信用等级之间的临界样本,将四个临界样本带入主成分综合模型中计算得到五类信用等级之间的临界值得分。其他客户数据就能根据主成分综合模型得到其对应得分,并根据其得分与临界值之间的比较确定自身的信用等级。
2.2 灰色关联度模型的建立
2.2.1 利用层次分析法求取指标权重
(1)构造判断矩阵
首先将总金额额度、信用额度、成功借款次数、借款总额、逾期次数、还清笔数、严重逾期次数、月收入、投资类型九个指标数据作为准则层,分别设为,用表示和对上层目标的影响比。
(2)层次单排序及其一致性检验
设准则层中与措施层因素的成对比较判断矩阵在单排序中经一致性检验,求得单排序一致性指标为CI,相应的平均随机一致性指标为RI,则B 层总排序随机一致性比例为

2.2.2 计算灰色关联系数及灰色加权关联度
(1)计算灰色关联系数
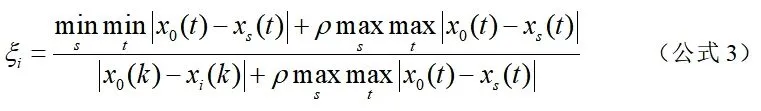
(2)计算灰色加权关联度
灰色加权关联度的计算公式为

2.2.3 评分等级的划分
通过Q 型聚类分析对客户样本灰色关联度进行五级划分,将客户样本划分为五个等级,并将每个等级内样本灰色关联度最小的作为等级之间的临界值。

2.2.4 建立主成分评分模型
(1)对原始数据进行标准化处理
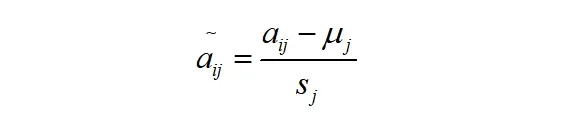
对应地,如公式6 这样

为标准化指标变量。
(2)计算相关系数矩阵R
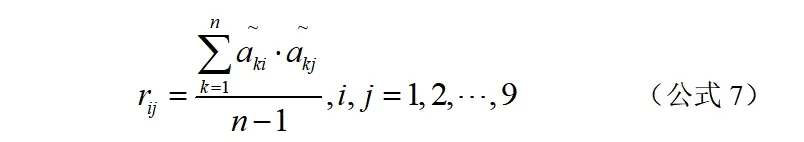
(3)计算特征值和特征向量
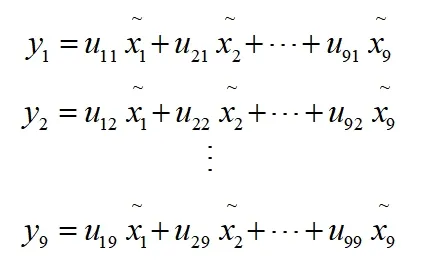

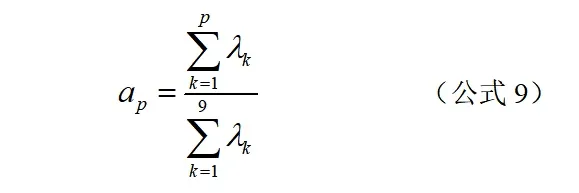
第二步,计算综合得分:

3 实证分析
3.1 变量的选择及预处理
本文选用的是MS 建设银行个人信贷,所用数据都经过了去除客户隐私,再将数据进行分析和研究。我们选取总金额额度、信用额度、成功借款次数、借款总额、逾期次数、还清笔数、严重逾期次数、月收入、投资类型九个指标数据。数据都来源于问卷调查。
其中月收入是一个区间范围,例如5000-10000,因此,将月收入取其区间的均值作为其准确的月收入,另外投资类型指客户所借资金的用途,分为个人投资和非个人投资,用1 和0 来量化这两种情况。由于用户的资料填写不完善,月收入变量中有不少样本是空,直接删除不完整客户样本后还剩13963 个样本。
3.2 灰色关联度模型估计与分析
3.2.1 利用层次分析法求取指标权重
(1)构造判断矩阵

表1 对比矩阵表
(2)层次单排序及其一致性检验
根据公式(1)(2)计算得出,一致性比率 满足一致性要求,故前面的权重向量可以使用。
3.2.2 计算灰色关联系数及灰色加权关联度

表2 部分样本关联系数和关联度值
由公式(3)(4)计算得出的8 个样本的结果显示,按照灰色关联度排序可看出表中所展示的8 位客户,,由于样本中客户7 与虚拟的最优客户的关联度最大,即客户7。由于其余七位,银行在放贷时即可优先处理客户7 的贷款申请,给予一定的贷款优惠。利用此算法可对当前银行所有待处理的贷款申请根据客户与最优客户的关联度进行排序,以此区分用户的贷款优劣程度。
3.3 评分等级的划分

图1 聚类图
根据公式(5)得到的聚类结果和灰色关联度排序,AB 类临界值样本为第12676 位,关联度为0.6429,BC 类临界值样本为第8733 位,关联度为0.5759,CD类临界值样本为第969 位,关联度为0.4328,DE 类临界值样本为第1059 位,关联度为0.3704。
3.4 主成分评分模型估计与分析
根据公式(7)求得相关系数矩阵,再根据公式(8)(9)利用MATLAB 求得相关系数矩阵的前5 个特征根及其贡献率如下。
可以看出前五个特征根的累计贡献率就达到了91%,主成分分析效果很好。下面选取前五个主成分进行综合评价。
由此可得五个主成分分别为

分别以五个主成分的贡献率为权重,构建主成分综合评价模型

3.5 模型的回测分析
将这13963 个样本标准化后的变量值带入公式(11),获得了这13963 个人的信用评分,用其实际逾期还款次数检验模型的评分结果,准确率为83%,有过多次逾期还款的人基本上评分结果都为负。

表5 评分检验表
结合聚类分析得到的四个代表临界值的样本,代入上述主成分综合评分模型中,计算得出AB 类临界值为1.2736470238996,BC 类临界值为-0.0818424587177281,CD 类临界值为-1.00874805249367,DE 类临界值为-1.06641614462261。
3.6 实证结果解读
本文模型采用的是由主成分综合评分模型,灰色关联度和聚类分析是为了确定信用五级分类的临界值。主成分综合评分模型由五个主成分构成,通过公式(11)计算得到客户的信用分,根据分值所处哪类信用区间,对其归类,由此可决定其贷款是否优质,贷款风险如何,是否优先处理等一系列考虑。[10-13]主成分评分模型能客观的反映出每位客户的真实信用得分。银行信贷业务依赖市场对人们的影响,若市场萧条,个人收入不高,贷款的人数及条件自然会变化,依靠灰色关联度结合Q 型聚类分析所划分的评分等级,能实时反映出市场变化给客户群体所带来的影响,以此调整出更适合当前市场的评分等级划分。模型由于主成分分析缺乏主观性,可能对道德等因素造成逾期还款的影响难以正确估计,可结合一些蚂蚁花呗或者京东白条之类的贷款记录,对模型进行优化。
4 结语
银行现在受到金融证券化的冲击,以前筹资只能找银行贷款,现在企业可以在证券市场发行各种证券进行筹资,因此,银行贷款中个人贷款占比逐渐上升,企业贷款数量减少,为了维持资金的流动性,对于那些贷款条件在信用分数及格线的客户,银行可能会犹豫是否放宽条件允许放贷。根据本文个人信用评分组合模型,不仅能更科学的预计客户的逾期还款的风险,还能根据信贷群体的变化合理制定更符合当前市场的信用等级,从而使银行安全且最大化的提高放贷金额,让资产与负债维持平衡。本文模型在实时性和客观性上有明显优势,模型相较于深度学习类模型更易于理解。本文的模型在银行个人信用评分方面的应用优势毋庸置疑,也为银行业的新型个人信用评分模型的建立提供了新的思路。
