基于深度生成对抗网络的恶意TLS流量识别
2022-05-05秦鸣乐
秦鸣乐,年 梅,张 俊,2
(1.新疆师范大学计算机科学技术学院,新疆 乌鲁木齐 830054; 2.中国科学院新疆理化技术研究所,新疆 乌鲁木齐 830011)
0 引 言
随着用户隐私保护和安全意识的增强,TLS、IPSec、SSH和VPN之类的技术应用越来越广泛,使网络传输中加密流量的比例越来越高。据思科加密流量分析报告显示:截止2019年5月,Google网页流量中加密流量占比为94%[1];截止2020年7月,使用TLS加密的火狐浏览器占比为83%[2]。加密流量已成为互联网中的主要流量。流量加密一方面加强了信息通信的保密性和可靠性,另一方面也给不法分子带来可趁之机。很多网络攻击者通过加密信道和流量加密技术隐藏自己的恶意行为[3],来规避防火墙的检测,给网络安全监测带来巨大考验。传统的基于明文特征的DPI、DFI网络流量识别检测方法不再适用[4-5]。经典的机器学习方法虽然可以解决基于端口和有效载荷方法无法解决的许多问题,但仍存在一定的局限性,包括:
1)恶意加密流量类别不平衡。使用不平衡的数据集训练模型,导致将小样本应用错误地识别为类似的大样本应用,从而影响分类结果。
2)数据流量的特征需人工提取,依赖专家经验,耗时耗力,特征提取的准确度受专家主观性影响。
1 相关工作
目前针对使用TLS等协议加密的网络流量检测和识别主要分为机器学习和深度学习2种。文献[6]经过深入分析,通过提取流量元数据和TLS头部大量特征进行恶意软件分类。文献[7]提出从网络流数据中提取256个特征,并将其转换为灰度图像,再将处理后的图像输入优化的CNN中进行相关训练和分类。文献[8]使用LSTM网络在KDD数据集中执行了5种分类,分类效果较好。
此外,针对流量数据不平衡问题,很多学者也提出了多种不同的解决方案,主要分为欠采样和过采样2类。通过改变数据集中多数类和少数类的样本比例来降低不平衡程度。由于从次要类别复制相同的副本,因此过度拟合始终是过采样的主要缺点。为解决过拟合问题,文献[9]提出SMOTE算法,该算法通过人工合成少数类样本来提升少数类样本的占比。文献[10]提出基于单边选择的欠采样算法,该算法通过单边采样去除大类数据集中的噪声样本。文献[11]提出SBC(Under-sampling Based on Clustering)算法,该算法利用聚簇后正负比例来确定抽样比例。
综上可知,使用过采样后的数据集会反复出现一些样本,训练出的模型会有一定的过拟合;欠采样的数据使训练集丢失数据,模型只学到了总体模式的一部分,虽然基于SMOTE的合成方法在一定程度上解决了上述问题,但SMOTE一方面增加了类之间重叠的可能性,另一方面生成一些没有提供有益信息的样本。基于此,本文提出在语言和图像生成方面有优异表现的深度生成对抗网络(Deep Generative Adversarial Networks, DGAN)进行小类别数据样本的生成和扩展,通过使用DGAN的生成模块对少数类别的流量生成指定数量的加密流量,以此获得质量高且平衡的数据集,使不均衡数据集中恶意TLS流量识别效率得到提升。
此外,针对平衡后的数据,本文提出使用双向门控循环单元网络(BiGRU)与注意力机制相融合的恶意加密流量识别模型,利用双向GRU(Gate Recurrent Unit)进行特征学习,使用注意力机制改进对数据包重要特征的提取能力,减轻噪音特征影响,最后通过Softmax分类器进行恶意加密流量的多分类识别。
2 相关知识
2.1 GAN
生成对抗网络(Generative Adversarial Network, GAN)是由Goodfellow等人[12]在2014年提出。受博弈论中2人零和博弈思想的启发,GAN主要由生成器和鉴别器2部分组成。整个网络模型如图1所示。
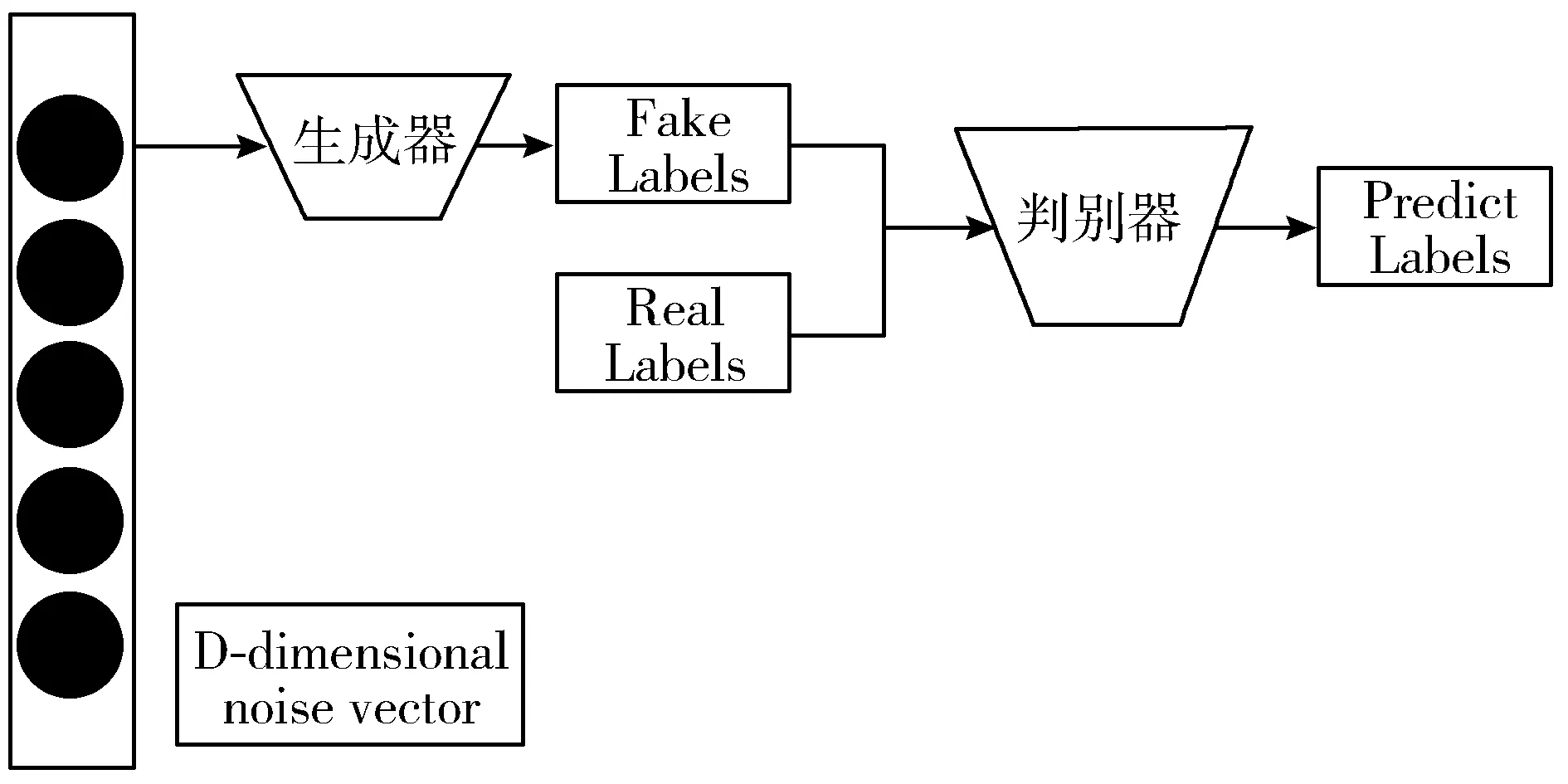
图1 生成对抗网络模型图
GAN的博弈过程可以看作是一位数据制假者和一位数据鉴别者的博弈。在博弈过程中,数据制假者会一直提高数据制假能力,使生成数据达到以假乱真的地步,成功骗过数据鉴别者。而数据鉴别者的任务是提高自己的鉴别能力,找出真假数据间的区别,通过对抗训练来不断提高各自的能力,最终达到纳什均衡的状态[13]。生成对抗网络的目标函数如式(1)所示。
minGmaxDV(D,G)=Ex~pdata(x)[logD(x)]+
Ez~pz(z)[log(1-D(G(z)))]
(1)
式中G代表生成器,D代表判别器;V为价值函数,V(D,G)相当于表示真实数据和生成数据的差异程度,maxDV(D,G)意思是固定住生成器G,尽可能地让判别器D最大化地判别出样本来自于生成数据还是真实数据。maxGV(D,G)表示固定住判别器D,训练生成器G,模拟生成类似于真实样本的模拟数据。z是服从高斯分布的随机噪声,pdata(x)表示真实数据的概率分布,pz(z)代表随机噪声的概率分布;x~pdata(x)表示从真实数据的分布中随机抽取x;z~pz(z)表示从高斯分布的随机噪声中抽取噪声z;D(x)和G(z)表示判别器和生成器在接收括号内输入后所输出的向量。利用GAN纳什平衡时生成的数据扩展小样本数据集,提高小类别样本的识别性能。
2.2 双向门控循环单元层BiGRU
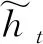
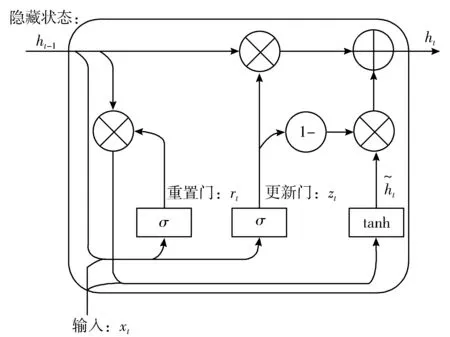
图2 GRU单元结构
rt=σ(ωr·[ht-1,xt])
(2)
zt=σ(ωz·[ht-1,xt])
(3)
(4)
(5)
GRU虽然能够很好地捕捉到行为序列的长距离信息,但是单向的GRU在t时刻只能捕捉到t时刻之前的历史信息[16]。BiGRU(双向GRU)是由前向GRU与后向GRU组合而成,其基本思想是将每个训练序列根据前向和后向表示成2个独立的递归神经网络,并连接到同一个输出层。BiGRU可以更好地学习双向序列特征,提高预测准确率。
2.3 注意力机制
近两年,注意力机制[17](Attention Mechanism)被广泛应用在自然语言处理、图像识别及语音识别等任务中。Google机器翻译团队[18]在2017年提出使用自注意力及多头自注意力机制的神经网络架构在机器翻译任务中取得了较为出色的效果。因此,本文将注意力机制运用在恶意加密流量识别中,通过对不同时序特征分配不同的权重值,加强重要特征对识别效果的作用。
3 恶意加密流量识别方法
本文提出的恶意加密流量识别过程主要包括3个阶段:流量数据预处理、基于小样本数据集扩展的数据集平衡处理以及恶意加密流量识别模型构建和测试。
3.1 数据预处理
原始数据集文件为pcap格式,首先需要进行预处理。即将会话作为流量粒度[19],将pcap文件转换为csv文件,转换流程如图3所示。首先使用Streamdump工具,根据五元组获取TCP层非重复TLS流量,然后进行切割,重组为多个会话;接着删除数据包数目少于3的无效会话;进一步去除MAC地址、IP地址等对分类产生干扰的特定信息;提取每条会话前N个数据包的前M个字节,超出长度则截断,不足则补充0,之后将所获得的字节序列采用Z-score进行归一化至(0,1),并标记该会话。Z-score标准化公式如公式(6)所示,其中xmean表示总体样本空间的分值均值,xstd为总样本空间的标准差。
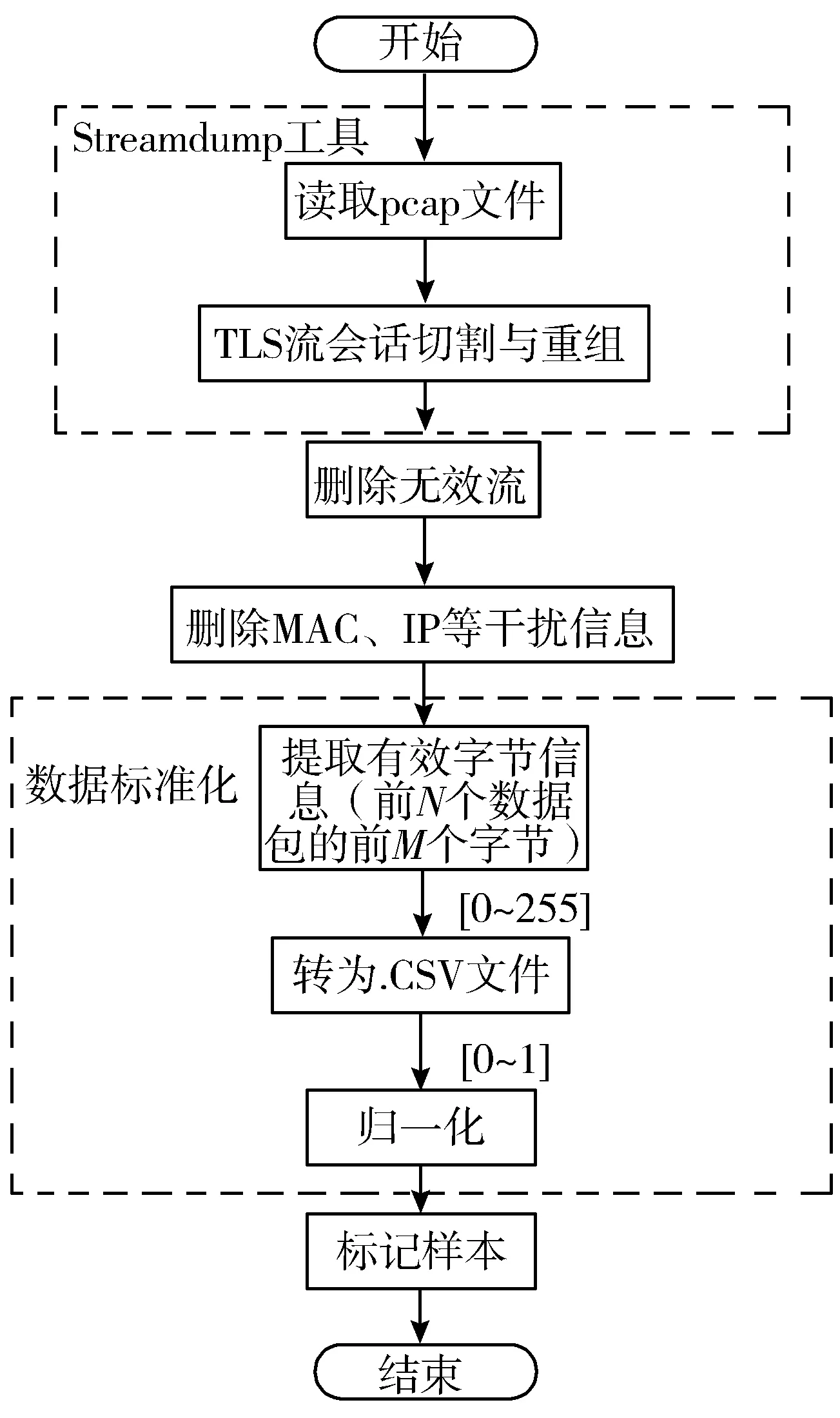
图3 数据预处理流程图
(6)
3.2 基于生成对抗网络的小样本数据集的扩展
为了获取质量较高且平衡的样本,本文使用深度生成对抗网络,通过训练少量训练数据集,获取训练数据集的特征,模拟生成接近训练数据的模拟流量数据,扩充小类数据集。DGAN模型训练流程如图4所示。
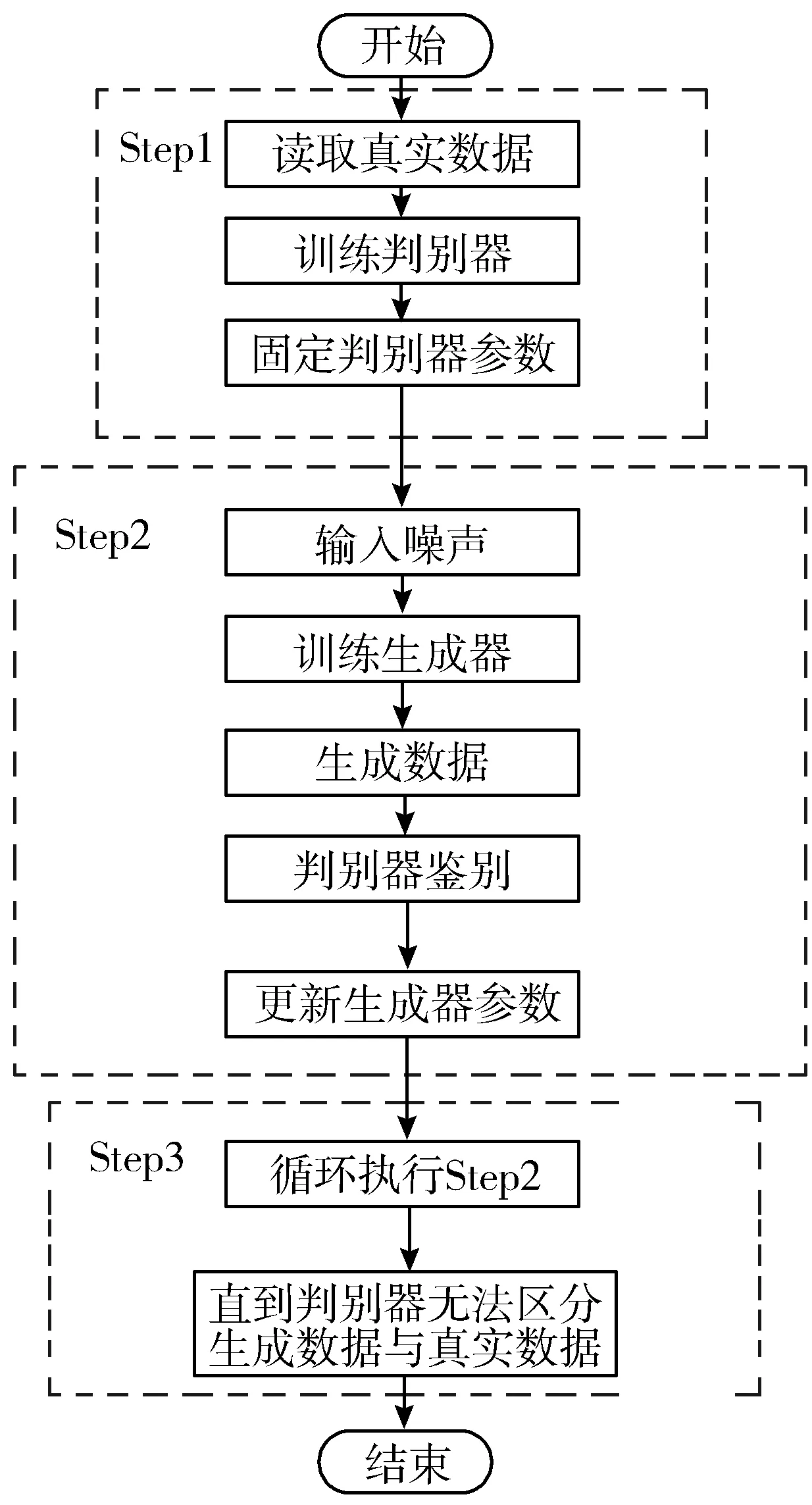
图4 DGAN训练流程
3.3 恶意加密流量识别模型
本文的流量识别模型的网络架构如图5所示。将平衡数据集预处理后的N×M一维字节序列数据送入双向GRU进行特征学习,同时使用注意力机制加强对会话层关键时序特征提取[20]。为防止过拟合,采用早停法技术[21](Early Stopping)提前结束训练过程,避免网络模型的过度拟合。最后使用Softmax分类器实现恶意加密流量识别。本文输出网元数量为12个。假设输入函数为x, Softmax输出函数定义如公式(7)所示:
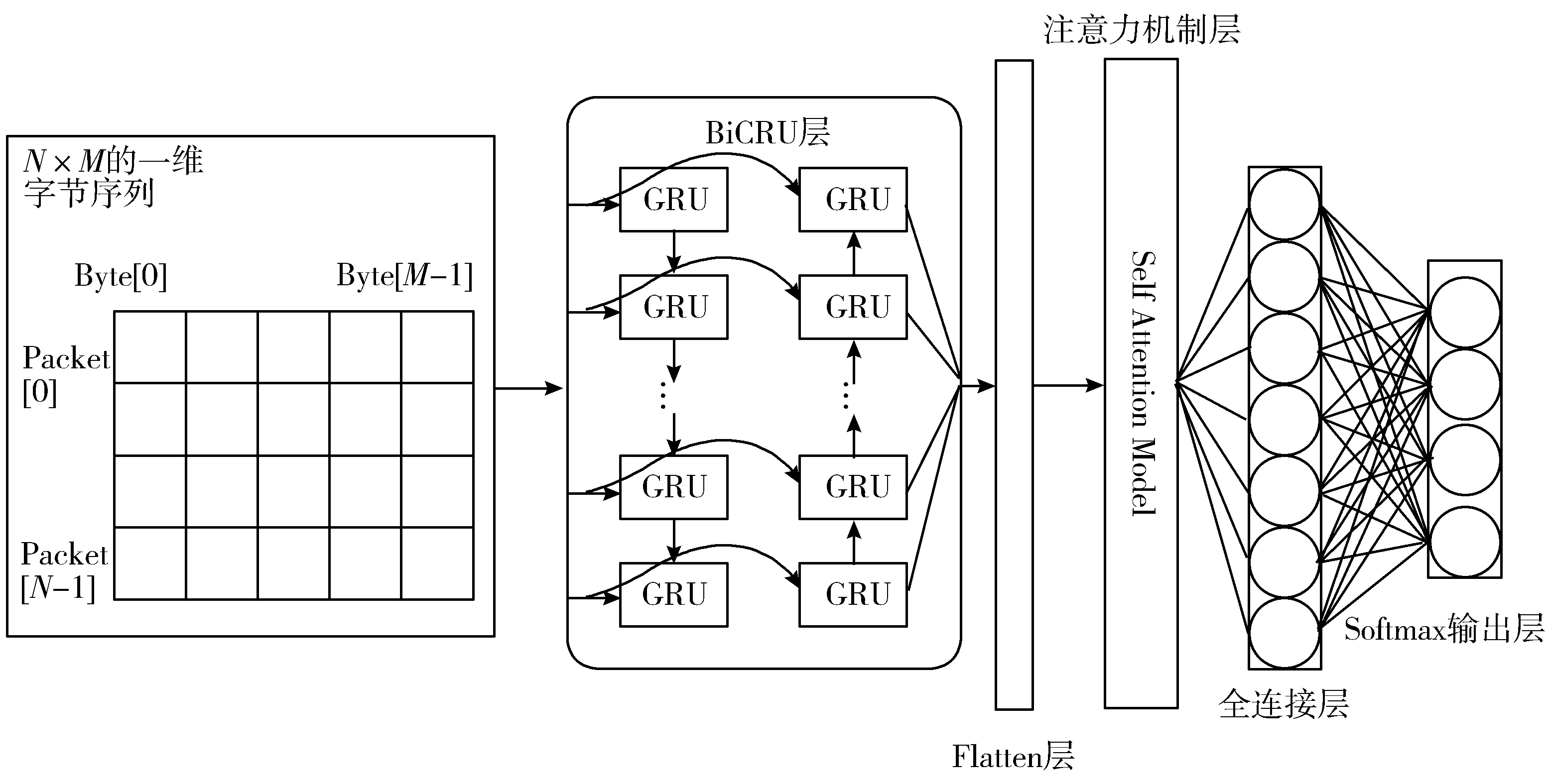
图5 模型架构图
(7)
4 实验结果与分析
4.1 实验数据及环境
实验中,使用CICIDS2017[22]数据集中的流量作为正常流量;Malware-Traffic-Analysis[23]、Stratosphere IPS[24]并集作为恶意流量。实验环境为Windows 10系统,CPU为i7-6700,主频3.7 GHz,内存8 GB,Python 3.6环境,基于TensorFlow 2.3完成模型的构建以及训练调优。实验数据集的内容分布如表1所示。
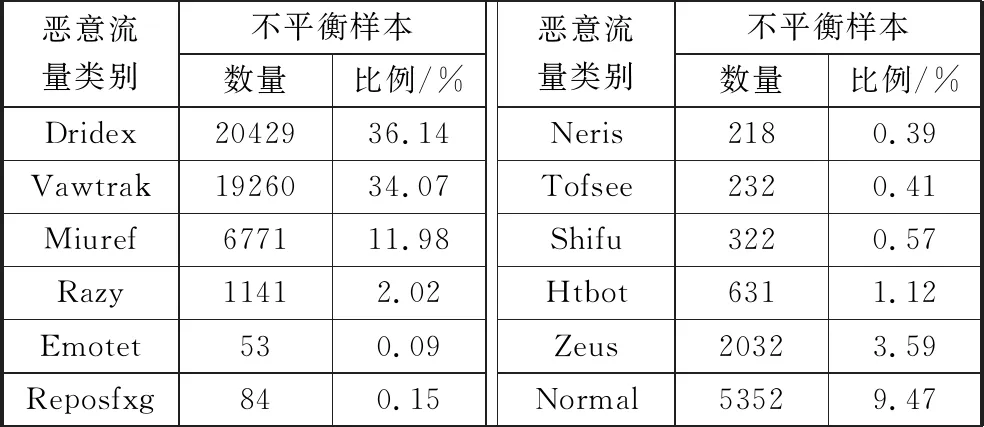
表1 不平衡数据
分析发现,使用Streamdump切分并获取的会话大都包含8个以上的数据包,且每个pcap文件的前8个数据包都包含了TLS的握手信息。为缩减计算规模并保留流量关键信息,本文选取数据包个数N=8,每个数据包的长度M=100 B。
4.2 实验评价指标
本文采用准确率(Accuracy, A)、精确率(Precision, P)、召回率(Recall, R)以及F1值作为模型的评价指标。准确率是被分类的样本的正确率,一般正确率越高,分类器效果越好,它主要反映分类器将正判别为正、负判别为负的能力。精确率表示正确预测为正的占全部预测为正的比例。召回率主要是指被正确分类的某类样本占该类样本的比例。准确率、精确率、召回率分别定义如下:
(8)
(9)
(10)
其中,TP表示把属于某个类别的流量正确分类为该类别,FP表示把不属于某个类别的流量分类为该类别,TN表示把不属于某个类别的流量分类为不是该类别,FN表示把属于某个类别的流量分类为不是该类别。
F1-score是综合考虑Precision和Recall的调和值,用于反映整体指标,计算公式为:
(11)
4.3 数据集平衡实验
由表1可知,恶意加密流量中的数据是不平衡的,部分恶意类别如Dridex类别样本,占总数据集的36.14%,而Emotet、Reposfxg、Neris等类别的样本仅占总数据集的0.1%~0.4%。基于此,本文提出使用DGAN解决恶意加密流量分类识别中数据不平衡的问题。
基本的GAN网络训练不稳定,不易收敛,容易出现生成器产生无意义输出的现象。Radford等人[25]提出使用深度卷积生成对抗网络(DCGAN),该网络创新地将基本的GAN网络中生成器的全连接层替换为反卷积层,从而在图像生成任务中实现了出色的性能。但针对一维字节序列的数据,DCGAN的训练效果较差,且生成器训练极不稳定,无法收敛。因此,针对一维字节序列数据,本文选用DNN(深度神经网络)作为GAN中生成器和判别器的基模型,通过同时训练生成模型和判别模型以达到对数据进行真假判别的二分类识别。
4.3.1 生成对抗模型的参数设置
深度学习模型调试时,调参技巧对生成数据质量的改进拥有不错的效果,为此本文采用实验进行参数设置。
1)在判别器进行数据输入时,进行归一化处理,该技术使得非线性变换函数的输入值落入到对输入比较敏感的区域,避免梯度消失。同时,可提高学习过程的稳定性,并解决权重值初始化效果差等问题。
2)为获得较好的结果进行了不同训练比例的尝试,当生成器与判别器的训练比例为1∶2时,生成器Loss值的上升情况会相较1∶1有所减缓。因此,本文选用在训练1次生成器后训练2次判别器来平衡2个网络。
3)在训练数据集时,如直接使用0.01的学习速率,判别网络的损失将会锐减至很小,导致不能指导生成网络的参数进行更新。因此,本文通过实验逐步衰减,最终设置生成器与判别器的学习率为0.001和0.004。
4)激活函数选择使用LeakyReLU代替ReLU避免梯度稀疏,增强模型的稳定性。
5)使用随机失活技术DropOut增加网络的鲁棒性,减少过拟合。
图6为使用上述参数对部分小样本数据训练5000次后生成器与判别器的损失情况。由图6可知,在前1000次迭代中生成器损失一直处于较高水平,此时生成器还在学习真实样本数据的特征,在迭代1000次后,生成器损失下降并逐渐趋于稳定。此时,表明生成器已能够快速生成与真实数据相似的虚拟样本。总体来说,2个函数震荡变化,生成器与判别器这2个网络结构相互制约,最终达到纳什均衡。

(a) Emotet Loss
利用训练好的深度生成对抗网络模型的生成器生成数据,使用高斯噪声触发生成器,产生加密流量样本从而补充小类别的样本。本文选择5000条数据作为基准值,对不足5000条的样本类别使用DGAN训练生成。同时,使用随机欠抽样方法,对超过5000条的样本进行平衡,从而使整个数据集趋于平衡。
4.3.2 小样本数据平衡实验结果分析
为验证使用DGAN生成样本的有效性,分别将平衡前与平衡后的小类别样本数据导入到基模型GRU中,并对数据平衡前后的分类效果进行比较分析。表2为小样本数据在基模型上平衡前后的Precision、Recall以及F1指标对比。由表2可知,在基于GRU的分类方法中,几个小样本类别的Precision、Recall以及F1指标与非平衡数据相比提升显著。该结果表明,使用深度生成对抗网络对小样本数据进行扩充和平衡能有效降低小样本类别被误判的几率,从而提高模型整体识别精度。同时也表明,本文所提模型DGAN经过不断训练生成的样本数据对恶意TLS流量识别是有效的。
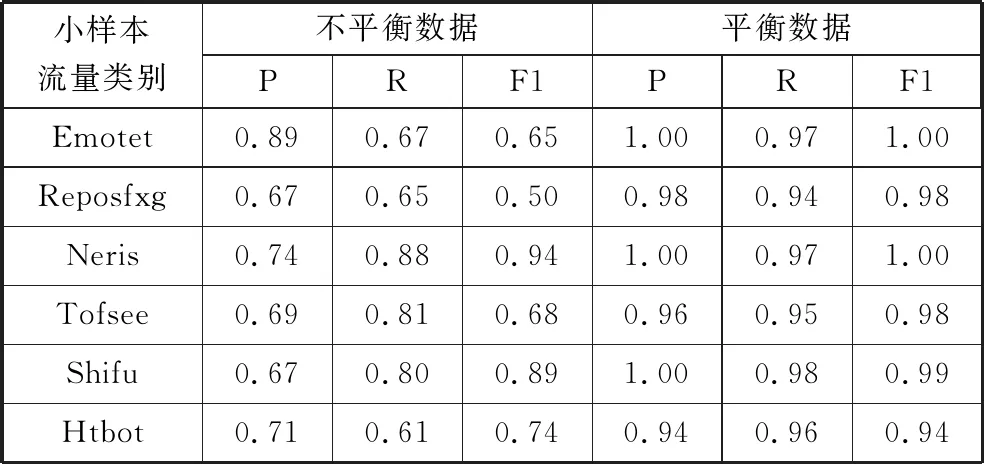
表2 小样本数据平衡前后各项评价指标对比
4.4 相关工作对比实验
为了进一步验证本文模型A-BiGRU的有效性及可用性,在公开数据集上选取3种相关工作的模型1D-CNN、BiLSTM、GRU与本文模型进行对比实验。在基于1D-CNN的分类实验中,采用文献[26]提出的模型分类结构,提取TLS会话流前784个字节,输入2层一维卷积神经网络提取字节序列局部特征组合。BiLSTM模型采用文献[20]提出的分类模型,提取TLS会话流前8个数据包与每个数据包前100个字节,输入BiLSTM模型。GRU模型使用2层的网络结构来提取字节序列的时序特征。
训练过程中,将数据集随机地划分为训练集与测试集2部分,分别占比80%与20%。实验选用categorical_crossentropy(交叉熵函数)作为损失函数,Adam作为优化器。各模型在平衡前后测试集上的评价指标如表3所示。
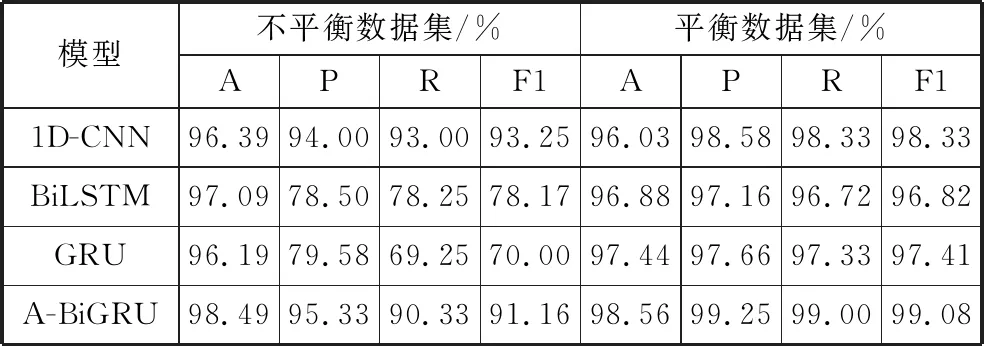
表3 数据集平衡前后各模型评价指标对比
由表3可知,虽然各模型在不平衡数据集上的准确率较高,但精度、召回率以及F1值相对较低。平衡后的数据集在模型识别中的精度、召回率以及F1值等指标相较于不平衡数据集分别提升了20%~30%。此外,在使用DGAN生成的平衡数据集上,本文所提模型A-BiGRU相较于其它基模型在准确率上提升了2%~3%,召回率和F1提升了1%~3%。这表明该模型能成功从恶意TLS流量中区分恶意家族,对于复杂的网络流量具有很好的分类效果。同时也表明,使用双向GRU与注意力机制融合的模型效果要优于使用单个模型的分类效果。
5 结束语
本文提出使用深度生成对抗网络DGAN来解决流量识别中类别不平衡的问题,利用DGAN数据扩充的优势,为数量较小的数据类别进行补充,形成平衡的流量样本。其次,本文提出使用双向GRU与注意力机制相融合的模型对平衡后的数据集进行特征学习,该模型能够充分利用深度神经网络挖掘深层数据包内与包间时序特征的学习能力,有效提升对恶意TLS流量的识别分类效果。未来将考虑设计一种多类别流量数据生成的网络结构,可以满足一个网络训练多种类别流量数据生成的任务。
