基于全局自注意力的小麦图像识别
2022-05-05何晨曦王正勇卿粼波何小海吴小强
何晨曦,王正勇,卿粼波,何小海,吴小强
(四川大学电子信息学院,四川 成都 610065)
0 引 言
民以食为天,粮食安全问题对于人民的日常生活和健康以及国家的建设和经济发展,都有着举足轻重的作用。小麦图像的病虫害识别,也可以叫不完善粒识别,是指在接近实际比例的大批麦子中识别出病虫害的小麦比例。而小麦的病虫害包括破碎、生虫、生病、发芽以及发霉这5种,加上完善粒,即正常小麦,一共是6类。不完善粒的含量对于评判一批小麦质量是一个十分重要的参考。但是,中国目前小麦质量检测依旧是由专业质检人员来检测,他们根据个人经验来判断。该方法工作量大、主观性强、不够稳定,耗费大量人力资源的同时,还会受到不同质检员主观因素的影响,可重复性比较差。
1985年,Zayas等[1]根据小麦的外形特征进行识别,这种识别效果不佳。机器视觉技术是在1991年由Thomson等[2]提出,他们通过拍摄并且识别小麦来对其进行分类,正常小麦识别率仅为83%,但是他们只筛选出发芽的小麦,对于其他不完善的小麦品种不予以判别和区分。到了21世纪,于2007年,Neethirajan等[3]根据提取的50多个小麦特征,使用神经网络进行识别,识别效果有了显著提升。陈丰农[4]于2012年提取小麦的178维特征,使用SVM算法进行分类识别。
早期的研究机器学习的数据量小,可泛化性不强,而随着卷积神经网络(Convolutional Neural Network, CNN)的快速发展,采用CNN卷积神经网络来识别分类小麦得到越来越多的发展。2017年,曹婷翠等[5]提出基于LeNet-5构建神经网络来识别小麦类别。陈文根[6]于2018年采用了5层卷积的神经网络的方法。祝诗平等[7]于2020年提出使用近红外光谱图像提取,来对正常和破损小麦进行识别,有不错的效果。然而现在的小麦识别通常有多分类,二分类已经无法满足实际需求。如图1所示依次为正常、破碎、生虫、生病、发芽、发霉6类小麦典型图像。
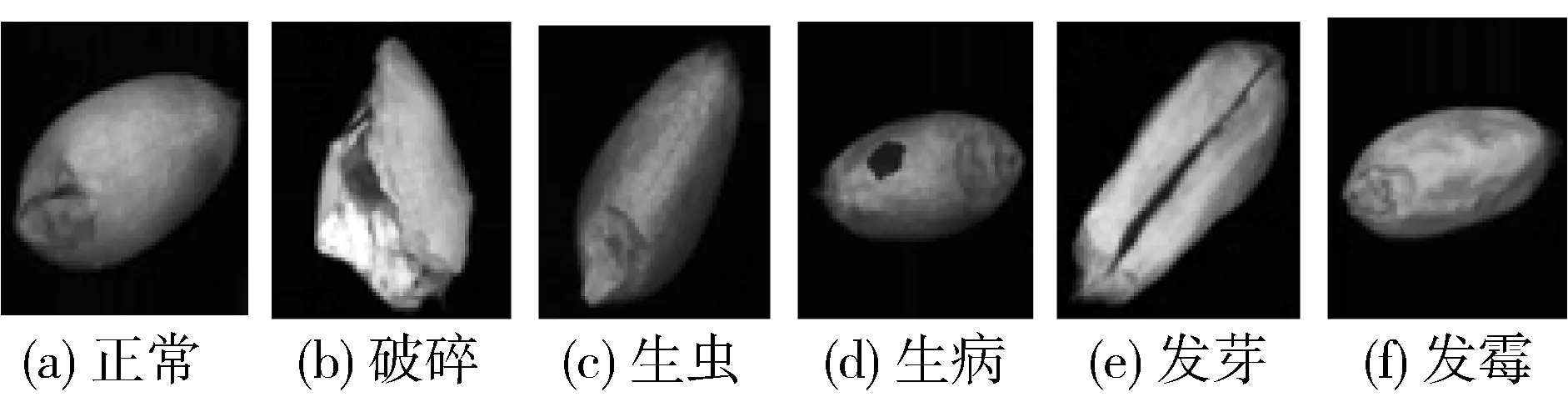
图1 小麦典型图像
随着深度学习的普及,基于深度学习的方法大大超过了传统机器学习的方法。然而经典分类网络LeNet-5、ResNet-18、VGG-16、EfficientNet在实验室采集的数据集上实现的效果还不错,但是到了实际场景中测试,性能会显著下降。在不受约束的情况下,实际场景的背景、照明变化,小麦异物干扰是相当常见的,这与人们想要关注的小麦特征无关,因此要关注的是最重要的一些特征。受到某些人脸识别方法的启发[8-10],本文使用类似注意力的机制来关注最具区别性的特征,以提高小麦识别的准确性。
郑文明[11]提出了一种基于群稀疏降阶回归的识别方法,选择对识别贡献最大的最优子区域。刘媛媛等[12]提出了通过多通道特征提取、多尺度特征融合和姿态感知识别3个部分来解决多视点识别问题。此外,生成式对抗网络(Generative Adversarial Network, GAN)也被应用于多视点对攻。基于GAN[13]的方法可以合成特征变化较大的小麦图像,扩大训练集。
与理想化的小麦相比,不同的姿态和拍摄角度操作可能会导致小麦图像变形,这可以被视为无序的子区域,还有就是图像中因为异物的遮挡导致信息缺失的子区域。通过与自然语言的类比,可以用另一种不同的方式来处理小麦的识别分类。有一个有趣的现象,人们可以理解一些即使有某一个词语语序错乱的句子,因为人类的认知模式通常会促使人们全局地去理解和思考这句话。同样像自然语言处理(Natural Language Processing, NLP)中的图像描述任务,可以使用几个视觉语言来描述图像的特征。在这种认知模式的启发下,假设在全局范围内通过一系列视觉语言来识别小麦种类是可行和有效的。因此,本文采用Convolutional Visual Transformers (CVT)来识别小麦的种类。结合局部二值模式(Local Binary Patterns, LBP)特征和CNN特征,进一步丰富了视觉语言的表示,参照了混合特征提取。
之所以使用LBP特征,是因为它可以捕捉到图像像素的细微变化,提取图像纹理信息。设计注意特征融合(Attention Selective Fusion, ASF),自适应地融合LBP特征和CNN特征。ASF同时聚合了2种特征之间的全局和局部关系,有效地提高了识别性能。简单地将融合后的特征图通过扁平化和投影的方式转换成一系列视觉语言。在得到这些视觉语言后,利用多层Transformer编码器来提高性能。多层Transformer编码器的全局自注意特性使网络能够对具有代表性的视觉语言的上下文信息进行建模,并关注最具判别性的特征。总的来说,本文的工作可以总结如下:
1)提出Convolutional Visual Transformers并将其应用于小麦识别分类,充分利用小麦图像的LBP深度特征和RGB深度特征的互补性,突破基于传统方法的小麦不完善粒性能识别瓶颈。
2)利用全局-局部注意力机制融合不同图像特征,同时利用全局自注意力机制建模视觉序列特征的内部关联机制,引导网络关注判别性区域和细粒度特征,实现自然场景下小麦不完善粒的精细化识别。
1 相关工作
1.1 特征融合
深度学习中的多尺度特征融合得到了广泛的应用,如人脸识别[14]、目标检测[15]、语义分割[16]等。然而,基于深度学习的方法需要大量数据才能很好地泛化。融合不同的特征图可以丰富整个网络的代表性,从而有效地提高泛化能力和识别性能。结合LBP特征和具有密集连接的RGB特征,有利于提高识别精度。以往的特征融合方法通常采用元素的求和或拼接操作作为融合策略,并没有很好地利用互补信息,放弃了冗余信息。与现有的方法不同,本文使用注意选择性融合ASF,如图2所示,将LBP特征和RGB特征结合起来,从局部和全局的角度压缩无用信息。

图2 注意选择性融合
1.2 计算机视觉中的Transformers
Transformers[17]在自然语言处理中表现优秀。受Transformers的成功启发,一些研究人员尝试将Transformers投入到计算机视觉任务中,如目标检测[18]、姿态估计[19]、高分辨率图像合成[20]、视频实例分割[21]、轨迹预测[22]。Vision Transformer (ViT)[23]是第一个将Vanilla Transformer应用到图像的工作。ViT直接将图像分割成小块,并将这些小块输入Transformer。根据文献[23],在ImageNet[24]上训练时,ViT的准确率低于ResNet。ViT首先在大型数据集上进行训练,然后针对下游任务进行微调,因为Transformers需要大量数据才能在计算机视觉任务中很好地泛化。Wang等[25]提出了Pyramid Vision Transformer (PVT)用于像素级密集预测。PVT可以作为不需要卷积的特征提取骨干,但具有特征金字塔结构。ViT和PVT都是没有卷积运算的纯Transformers。在大规模数据集上进行充分训练时,基于Transformers的方法与基于CNN的方法相比表现出了优越的性能。受Vanilla Transformer和ViT的启发,直接在小麦分类识别中应用Transformers。Transformers利用全局自注意力机制对输入序列之间的长依赖关系进行建模。这种全局的自我注意使模型能够忽略信息缺失区域,并在小麦有异物遮挡和不同姿势的情况下从全局角度识别小麦。
如图3所示,本文使用的Convolutional Visual Transformers的概述可以分为3个部分:视觉语言提取、关系建模和小麦图像分类。利用预先训练好的ResNet-18作为主干,提取特征映射。对所有提取的特征进行注意选择性融合,得到具有代表性的视觉语言。输入的视觉语言是通过简单地将特征图的空间维度扁平化并投射到特定的维度得到的。然后应用多层Transformer编码器对不同视觉特征组件之间的关系进行建模。该网络最后通过一个简单的Softmax函数计算表达式概率。总的来说由2个关键组件组成:1)注意力选择性融合;2)多层Transformer编码器。

图3 卷积视觉Transformers
2 本文算法
2.1 概述
参考图3,对于给定的尺寸为H×W×3的小麦图像IRGB,首先得到其LBP特征图像,其大小为H×W×1。特征提取主干由2个ResNet-18网络组成,一个用于RGB图像,另一个用于LBP特征图像。使用ResNet-18的前5个层作为主干以尺寸H/R×W/R×Cf来提取特征图XRGB和XLBP,其中R为ResNet-18的下采样率,Cf为第5层输出的通道数。简单来说,Hd=H/R,Wd=W/R,而本文中,R=32,H=W=227,利用预先训练的权值初始化整个网络权值。在不损失泛化的前提下,利用ASF将从RGB图像中提取的特征与从其LBP特征图像中提取的特征结合起来。ASF模块动态调整这些特征的权值,引导网络更多地关注对提高小麦识别至关重要的区别特征。ASF的融合权值通过全局-局部注意生成,集中全局和局部进行进一步的识别。融合的特征图Xfused的大小也是Hd×Wd×Cf,将这些扁平的特征输入到线性投影中,并添加一个可学习的分类标记,然后嵌入大小为(HdWd+1)×Cp的视觉语言,其中Cp为投影平滑的特征通道。最后,通过一个全连通层和Softmax函数生成小麦识别的概率。
2.2 注意力选择性融合
本文的注意选择性融合包括全局注意和局部注意,如图2所示,这样可以更加灵活地融合不同类型的信息。正如上面说到的,提取自网络结构根基的2个特征图XRGB、XLBP∈RHd×Wd×Cf,首先融合LBP特征XLBP和CNN特征XRGB,用于捕获后续的信息交互:
U=WlXLBP+WcXRGB
(1)
其中,U表示LBP特征XLBP和RGB特征XRGB求和之后的综合特征图,+表示像素级求和。Wl和Wc表示通过2个1×1卷积来实现的初始融合权重。为了同时进行全局和局部选择性融合,本文分别选择全局平均池化和像素级卷积作为全局上下文和局部上下文聚合器。全局上下文逐渐压缩每个大小为Hd×Wd的特征图为一个标量,并利用特征的信道间关系。与全局上下文不同,局部上下文保留并突出输入特性的细微细节,这是对全局上下文的补充。聚合局部和全局上下文有助于网络从不同类型的特征中获益,并更准确地识别模糊的小麦纹理。全局上下文和局部上下文的计算如下:
(2)
(3)
其中,G(U)∈R1×1×Cf和L(U)∈RHd×Wd×1分别表示全局融合权重和局部融合权重。AP表示全局自适应平均池化,其数学表达式如下:
(4)
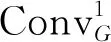
由全局融合权重G(U)和局部融合权重L(U)可以得到精细化的全局-局部注意力权重,由如下公式表达:
GL(U)=G(U)⊕L(U)
(5)
其中,⊕表示广播加法。
那么融合后的特征图Xfused可由如下公式表示:
Xfused=XLBP⊗σ(GL(U))+XRGB⊗σ(1-GL(U))
(6)
其中,⊗表示像素级相乘。
2.3 多层Transformer编码器
融合后的二维特征图Xfused需要被平面化成一维视觉嵌入序列,并作为多层Transformer编码器的输入。因此,本文将Xfused∈RHd×Wd×Cf重构为一个扁平的序列,并将其输入到一个线性投影中,得到Xfused∈RHd×Wd×Cp,其中HdWd为序列长度,Cp、Cf分别设为512和768,因为ResNet-18输出的特征图通道数是512,并且Transformer结构的原型来自于自然语言处理中,自然语言处理中Bert模型的输入特征维度就是768,本文把这个特征图转化为特征序列。与文献[26]中一样,分类字段[cls]在开始的时候被添加到输入序列Xf中。利用Transformer编码器输出处的[cls]标记的可学习状态来表示整个特征序列,为最终预测服务。为了将位置信息合并到多层Transformer编码器中,将一维可学习位置嵌入添加到特征嵌入中:
(7)
其中,PE(HdWd+1;Cp)∈R(HdWd+1)×Cp学习每个位置索引的嵌入,包括[cls]标记,Z0表示产生的位置感知特征序列。
为了模拟小麦特征嵌入的所有元素之间的复杂交互,本文在标准多层Transformer编码器中输入Z0。Transformer编码器通过multi-head self-attention(MHSA)计算嵌入Z0的权重。这是通过可学习的查询Q、键K和值V来实现的。通过以下公式来计算single-head global self-attention (SHSA),第1层SHSA可以表述为:
headj=Attention(Qj,Kj,Vj)
(8)

MHSA(Z0)=concat(head1,…,headNh)W0
(9)
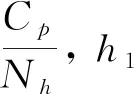
(10)

(11)
(12)
信息缺失区域可以再结合图4的注意力图进行证明,位于小麦两端的部分,往往具有更多的图像纹理细节。这种从一定程度上忽略无用信息的方法更有助于网络关注区分区域。

图4 注意力图
3 实验结果与分析
3.1 实验细节
本文的实验数据由中储粮成都储藏研究院有限公司收集并提供,由中储粮的专业质检员根据小麦质检手册的唯一规定标准来对采集到的小麦进行人工分类标注,分为正常、破碎、生虫、生病、发芽以及发霉6类,将人工分类好的各类小麦数据分开打包并附上标签。硬件方面,采集设备为维视相机MV-EM200C和光学镜头BT-2336构成的自动图像采集设备,运用图像处理算法将图像调整至227×227大小,具体做法是固定图像宽高比,将图像缩放至227×n(n≤227),并在较短的边两侧等量补0,将图像调整至227×227大小。
数据集共收集了25000张小麦图片,其中10000张正常,破碎、生虫、生病、发芽以及发霉这5种各3000张,按0.8∶0.2的比例选取20000张作为训练集,5000张作为测试集,尽可能使得训练测试集更接近于实际真实比例。6类图片都根据质检员的判断人工打好了标签。本文方法的学习率初始化为0.005,使用线性学习速率预热1000步和余弦学习速率衰减,同时使用Adam优化器对整个网络进行优化,利用标准交叉熵损失对模型进行监督,提高模型的泛化能力。在单个NVIDIA GTX 1080Ti GPU卡上进行实验。
3.2 实验结果
图5为实验的Train_loss,图6为实验的Test_accuracy,可以明显地看出,实验结果在可以接受的波动范围内,最后测试集识别率稳定在89%。

图6 Test_accuracy
为了更加直观地展现测试集中6个类别的分类情况,本文给出一个混淆矩阵来反映测试结果。如图7所示,各个类别的分类情况一目了然。
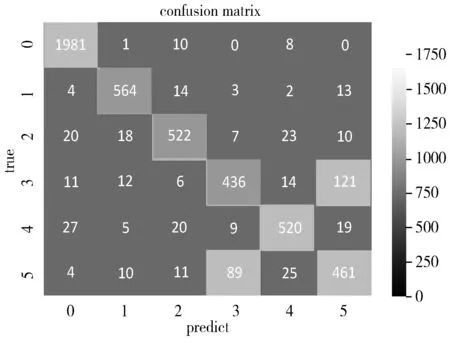
图7 混淆矩阵
3.3 与其他方法对比
为了验证本文方法的有效性,与经典分类网络LeNet-5[27]、VGG-16[28]、ResNet-18[29]、EfficientNet[30]进行对比。此外还对比了参数量以及训练时间。参考表1的实验数据,对于小麦六分类,在数据集有限的情况下,测试集的准确率89%,是有明显提升的。
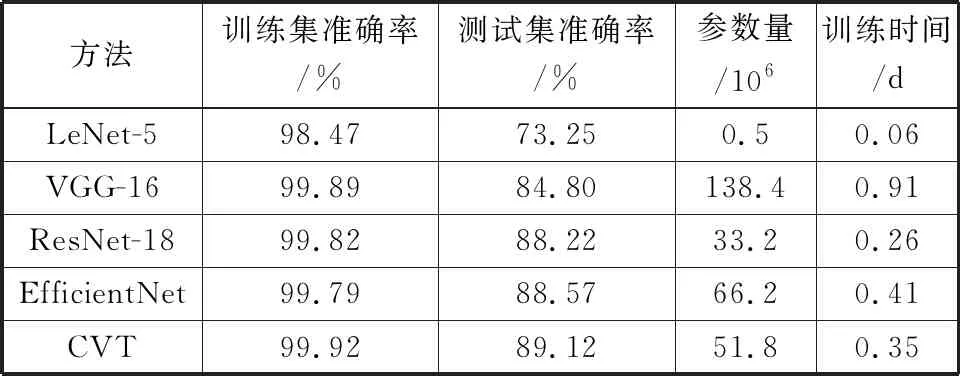
表1 CVT和传统方法比较
表1中训练集与测试集的精度差别很大,存在过拟合的现象。一方面由于本文研究的小麦病虫害识别属于细粒度分类问题,类内差异大,类间差异小。比如生虫、生病和发霉这3种情形,中储粮的专业质检员才可以大致区分,不具备专业知识的普通人很难区别。另一方面由于真实场景下数据采集、标注难度大,不同质检员的分类也难免会有偏差,导致本文样本的种类界定有少量模糊的可能。此外出于人工成本的考虑,本文构建的数据集规模也有限,只有25000张小麦图片。
本文为了应对可能存在的过拟合现象,在序列编码阶段采用了Dropout技巧,同时也采取了数据增广策略,通过对训练图像做一系列随机改变,来产生相似但又不同的训练样本,从而扩大训练数据集的规模。结合表1可知,相对其他方法,过拟合对于本文的影响较小。
3.4 消融实验
如图3所示,本文的方法由LBP特征与注意选择融合ASF模块和多层Transformer编码器(MTE)组成。为了验证这些模块的有效性,在本文的小麦数据集上进行对比实验,舍弃了之前的CVT的部分模块。由于ASF是用来整合LBP特征和CNN特征的,所以没有LBP模块就不能保留ASF。为了验证LBP特征以及多层Transformer编码器MTE对小麦图像识别的有效性,对比数据见表2。可以看出,LBP特征对小麦识别有较小提升。这可以解释为LBP特征可以提取纹理信息,反映细微的纹理变化,这些变化反映了小麦之间的细微差异。然而,直接使用LBP特征进行实验的效果是有限的,因为简单的添加融合策略不能令人满意。多层Transformer编码器MTE更明显地有助于提高小麦识别性能。
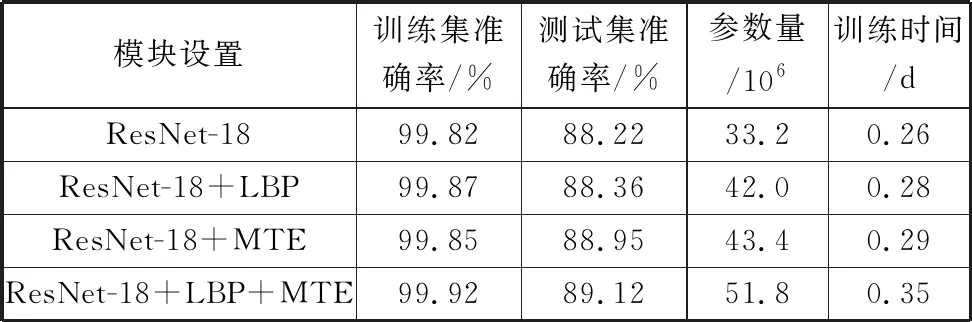
表2 CVT中模块的有效性
不同于以往的小麦二分类,本文是基于和中储粮合作的小麦六分类识别项目,考虑到全部是由中储粮质检员根据小麦质检手册的标准人工打标签,质检员质检本身存在主观偏差,难以避免,再加上拍摄场景的亮度、硬件设备等因素的不确定性对图片的细微干扰,不同储藏时间、不同来源地的小麦,也增加了小麦每一类的复杂度和差异性,这都使得小麦图像六分类十分困难。因此本文增加模块的识别率相比之前的识别率提升已经十分可观。此外,虽然训练时间略有上升,但在实际场景中的应用是完全可以接受的,因此就精度指标来说,引入LBP特征和MTE是有意义的。
3.5 可解释性分析
如图4所示,通过可视化小麦的注意力权重图(Attention Map),可以直观地发现,更具有判别性的区域的权重更高,这也是本文方法取得较好识别效果的关键所在。
从注意力图可以看出,位于小麦两端的部分,往往具有更多的图像纹理细节。结合实际,因为小麦发芽、生虫等,主要集中于两端,而中部的细节,往往比较少,这也与实际相符。当人们从全局的角度重点关注细节多的部分,而选择性忽视细节少的部分,可以使小麦的识别更加可靠。
4 结束语
本文将Convolutional Visual Transformers (CVT)用于小麦的识别,通过将小麦图像转换成一系列视觉语言,并从全局角度进行识别来解决小麦识别问题。为了实现这些目标,本文设计了注意选择性融合,动态自适应地结合LBP特征和CNN特征,以提高识别精度。通过对融合后的特征图进行扁平化和投影,生成视觉语言。多层Transformer编码器利用全局自注意机制,从全局角度将注意力转移到有区别的视觉语言上。实验结果表明,CVT网络在小麦数据集上优于LeNet-5、ResNet-18、VGG-16、EfficientNet。
虽然本文数据源于实际,但是仍然有一些不足,对于不同地区、不同时间的小麦,仍然无法做到全面覆盖,在小麦数据库这一方面,未来还有可以更加完善的空间。此外,本文的网络设计相对复杂,对实际检测系统的实时性有一定的影响,因此,如何使用更加轻量级的网络以及如何简化网络,是未来可以提升的地方。
