改进的KNN分类异常点检测方法
2022-05-01朱林杰赵广鹏康亮河
朱林杰 赵广鹏 康亮河
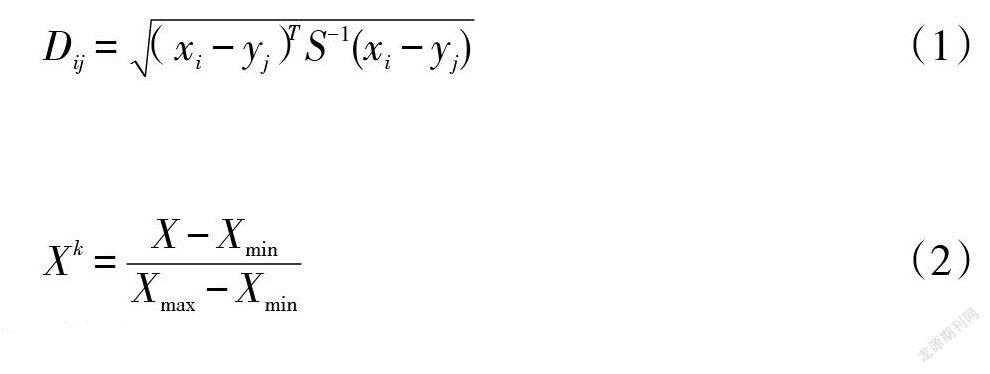




关键词:特征选择;孤立森林算法;NSL-KDD
中图分类号:TP391
0引言
随着信息技术的发展,在大数据时代,准确收集各方面的数据格外重要,然而数据容易被异常点污染,因此数据质量的监测被越来越多的学者重视。在异常检测系统研究领域中,异常点检测是其中一项非常重要的环节。在物联网领域中,前人提出了许多方法处理研究数据异常值来保证检测结果的准确性,例如SVM、KDE、聚类、贝叶斯、决策树等方法,但是很少有方法是通过研究数据的相关性去进行异常点检测研究。
通常我们收集的数据中,会包含因人为的或是因机器错误而导致的许多杂乱的、有噪声的、异常的稀疏数据,也会包含远远偏离大部分值的数据异常点,异常点检测与估计通常用无类别标签来找到某个区域的异常数据。由于网络上的数据类型庞大且其处于不定时的变化状态中,我们无法快速定位并准确查找到异常点,同时也增加了相应研究的工作量。另一方面,由于存储方面的限制,硬件代价比较高,导致目前获得的有用算法比较少。因此,找到数据中的异常点检测就显得非常重要。
近年来,虽然利用距离方法度量两个数组之间的距离有一定的优势,但目前有的度量方法仍存在一定的缺陷。在考虑数据之间的稀疏性与相互关联的情况下,结合马氏距离,发现两个变量的相互关联是显而易见的,都会存在一定的相关性。计算两个变量的协方差矩阵时,通过先处理数据帧,将数据平滑成一维数组,再计算两个一维数组的马氏距离。与多数据点相似,少数数据点有不同的特征,远离多数点,先计算特征向量,再进行异常点打分,从而找出异常点。文章分析了该领域的研究方法,通过学习理解目前的研究,比较了几种不同的异常点检测方法。
1相关工作
虽然关于异常点检测的研究已经持续了许多年,但仍有很多需要改进的地方。Nonso Nnamoko等人[1]通过研究异常点和类之间的平衡提高了关于治疗糖尿病预防方面的检测率。PetraJ Jones等人[2]提出了新的异常点检测方法,该方法通过减少异常点来改进kmeans,从多个方面来评估异常点,并获得了不错的结果。Henriqueo等人[3]分析了许多文献,讨论了许多现有的方法,比较了候选异常点求解方法。Zahra Gha⁃foori等人[4]提出无监督的维数约简技术和随机的近邻嵌入检查,改进的维数约简技术提高了异常点检测的精度。Yacine Chakhchoukh等人[5]提出了一个有力的卡尔曼过滤增强异常点检测和黑客攻击的诊断方法。CarmonaJ等人[6]提出在高维数据集中,使用距离度量来检测异常点,通过和四种方法比较,他的方法在低维和高维数据中适用。Mansoor Ahmed Bhatti等人[7]研究了采用机器学习方法在物联网中检测异常点的应用,在精度、准确性、召回率、f-scores四个方面,达到了97.8%精度改进结果。PeterFilzmoser等人[8]分析了多变量异常点检测方法,他们从全局、局部、组合等方面讨论了不同数据格式的整合。John Wiley等人[9]用概率的方法有效的检测了异常点。FarekLazhar[10]在文章中使用模糊聚类和半监督的方法检测异常点,实验结果表明,使用该方法进行异常点检测改进了分类器的性能。Javier Martinez Torres等人[11]通过对空气污染数据质量的异常值分析,用四个步骤概括了异常点检测的重要性,并采取新措施改善了空气质量。RüdigerLehmann[12]使用均值漂移与方差波动法进行异常值检测的比较研究。Yu Kangqing[13]设计了一个流算法用于在数据挖掘中检测异常点增量。Ijaz Muhammad Fazal[14]研究了异常点检测和过采样方法在疾病处理中的影响。
2提出的方法
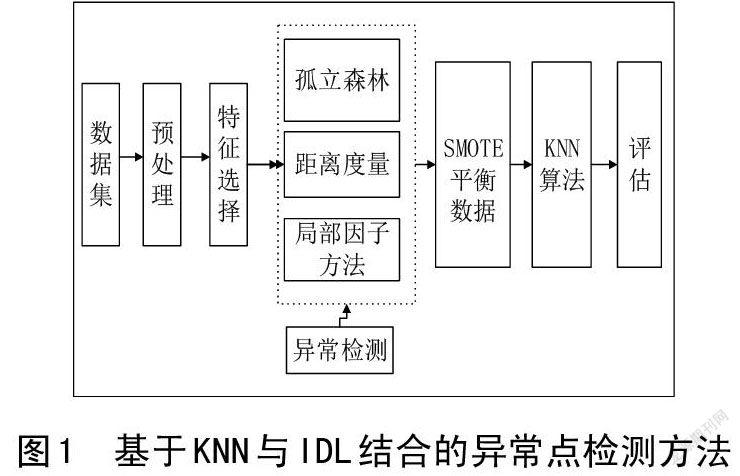
在计算异常点检测时,会缺少相关的知识,异常点处理会受到影响,为了考虑到单一方法的局限性,采用isolationforest、距离度量和局部因子方法异常点检测的方法,该方法首先采用马氏距离计算两个变量之间的距离,得到两个n行n列协方差矩阵,然后扩展成多个变量,将变量转换成不相关的空间,最后汇成距离向量矩阵;接下来根据距离与密度的关系找出离群点,观察是否是密度小的数据区域,并且找出远离线性关系的每一个样本点;然后根据每个值的情况确定异常点,如果多数点相似,少数数据点既有不相似的特征,远离多数点的这些数据,从而得出异常点。
2.1特征选择
卡方检验是一种使用频率比较高的特征选择方法。卡方检验可以测量随机变量之间的相关性,消除与类别无关的特征。它能够推断出类别之间的特征依赖性,并计算特征信息值和卡方统计值[15]。
建立的模型如图1所示。
2.2发现异常点
采用isolation forest、距离度量和局部因子方法,结合每一个算法的优点查找异常值。然后使用马氏距离度量[16],具体公式如下[17-18]。
其中,S表示协方差。根据得到的值,判断其是否为异常值,通过这些方法获取数据点,进行综合判断,得到最近邻[19]。
3实验结果与分析
基于距离的方法是一种简单有效的快速计算距离的方法,在机器学习领域中,尽管这方面研究已经持续了许多年,学习异常点检测仍具有一定的困难,异常点通常出现在数据采样处理之后,这就使得使用算法进行错误分类受到比较大的影响。因此,为了更好的检测异常,结合了算法的优点用于实验,通过文章的实验结果证明,相对于传统方法来说,文章提出的算法在平衡召回率和精度方面有所改进,结合的检测方法在分类效果上有一定的优势。
改进的异常点检测方法在测试阶段,采用公开数据进行测试时,測试误报率明显降低,相对于单一的检测方法,混合的检测方法有所改进。为了检测和改进异常点检测效率,使用结合的方法查找异常点,然后找到异常点后,再使用SMOTE算法使得数据达到平衡。
3.1数据集
KDDtrain包含42个属性,125973条数据,分为正常和异常数据,KDDtest包含42个属性,22544条数据,分为正常和异常数据,见表1所列。
3.2实验平台
python3.7,intel(R)core(TM),i5-9400F,2.90GHz,8G内存,windows10操作系统。
3.3参数设置
树规模T=100。K=3。为了验证混合异常点检测算法的性能,分类性能被检测使用以下方式。
TP(真阳性):预测为正样本,实际为正样本
FP(假阳性):预测为正样本,实际为负样本
TN(真阴性):预测为负样本,实际为负样本
FN(假阴性):预测为负样本,实际为正样本
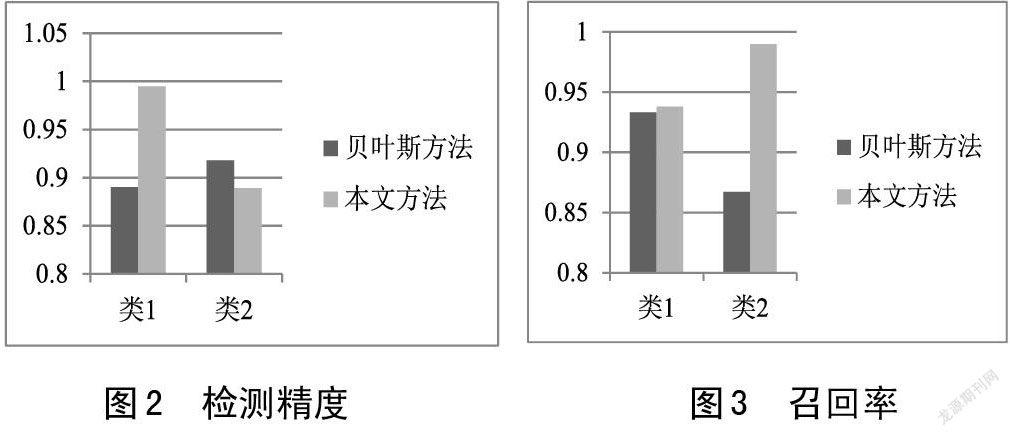
类1表示正常的类别,类2表示异常的类别。
从图2中实验结果可以看出,通过与贝叶斯方法比较,文章提出的方法对正常类别的检测精度比较高,错误类别的检测精度略低于贝叶斯方法,分析其原因,在于实验采样的样本规模仍较少导致。但根据分析情况,能够看出找出异常点,总体上检测能力远远提高,从召回率方面来看,如图3所示,文章提出的方法在召回率结果上明显优于贝叶斯估计方法。正常检测率达到93.8%,异常检测达到了99%,文章所提出的方法改善效果显著,可以较好的表现出异常点检测的效果。另外从误报率结果来看,如图4所示,实验结果中发现出现的误报率比较小。达到了6.2%的误报检测性功能,通过本文提出的方法检测到异常点并处理后,通过k值选择,同贝叶斯方法比较后可以明显的看出采用本文方法进行异常点检测有所改进、检测精度略有提高、误报率得以降低。从整体结构看,虽然检测到的样本稍微有些变化,但总体趋于平稳,整个检测系统的效果优于经典的方法。
4结论
异常点检测是数据挖掘领域一个重要的过程。文章提出了改进KNN与异常点检测算法相结合来处理数据的方法,该方法有助于查找并识别异常点,保证攻击的数据在数据挖掘领域中得到正确检测,通过实验证明,本文提出的方法能够有效的处理异常点。在现实生活中,有许多系统數据需要处理异常点,因此异常点检测是关键部分。异常点因为数据的稀疏等因素数量一般超出给定数据集中多数相似点的个数,识别它往往会有一定的困难,有时,异常值对于我们分析数据有一定的影响,如果系统没有识别出异常值,会导致预测结果不准确;如果异常值太多,又会影响系统的准确性,通过采用消除变量方式把特征向量降低,消除异常值的影响,通过系统检测并标记异常值,得到异常值的大小后计算,使预测性能得到提高。总之,从实验结果进行分析文章方法在数据量比较大的情况下,精度与召回率大幅度提升,误报率有所下降,这样充分说明,本文方法对于入侵攻击由较强的检测能力。相对与贝叶斯方法,较好的提升了分类精度。另外,在将来在大数据时代,数据量越大,数据的维数也越高,同时会导致出现更复杂的情况。因此,消除维数方面的影响,会减少系统的运作成本。
