基于BERT与BiLSTM混合方法的网络舆情非平衡文本情感分析*
2022-04-28顾凤云
刘 继 顾凤云
(新疆财经大学统计与数据科学学学院 乌鲁木齐 830012)
随着大数据时代的来临,不同用户通过社交媒体平台(如微博、论坛等)产生了海量的情绪化数据,而舆情文本情感分析发挥着非同小可的作用。目前,文本情感分析作为突发公共事件管理与控制的重要范畴,通过识别舆情文本情感倾向,由此发掘出网民产生情感极性的原因。网民情绪的表达会影响舆论传播的广度及其深度,若负面情绪快速传播则不利于事件解决,还会恶化事态的发展形势。因此,在重大突发事件管理中,舆情文本情感分析对舆情预警、有效引导及良性发展具有重大的意义[1]。
1 相关研究
情感分析是对主观性文本中的情感和态度进行分类,主要方法为机器学习、深度学习等方法。从机器学习的视角出发,基于机器学习[2]的文本倾向性分析方法需要使用语料库,训练分类模型。如朱军等人[3]对文本数据使用词袋模型进行分类,考虑Word2Vec建立新的词向量;在集成算法朴素贝叶斯与SVM[2]中,精准率和召回率都有所提升。在文本分类上神经网络结构取得显著成效,利用搭建神经网络结构,构成不同的神经网络算法如CNN、双向LSTM、文本CNN等。Y.Kim[4]最早提出将CNN应用于文本的倾向性分析,并得到较好的效果;在Y.Kim分析的基础上,Conneau等人[5]采用了深度卷积网络方法提出VDCNN模型。随后预训练模型开始兴起,在NLP领域有了重大突破;Vaswani等人[6]提出的BERT模型在评价指标中得到更好的提升。Devlin等人[7]主要介绍BERT模型的实际价值,并在11个自然语言处理任务上获得了较好的研究成果。段丹丹[8]用BERT模型对正负平衡的短文本数据进行预训练,用特征向量来表示语言模型,随后将获得的特征向量输入Softmax进行分类,利用F1值作为评价指标。李可悦等[9]采用BERT模型的预训练完成单条文本的特征向量表示,随后有区别性地将特征向量输入分类器,采用电商文本的样本进行算法验证。宋明等[10]通过爬虫获得微博非平衡文本数据,将BERT模型的损失函数换为Focal Loss进行情感分析;分类结果在准确性上进行验证,中性偏高但是负向偏低。
由于单模型的局限性,研究者开始探索混合模型。国显达等人[11]利用混合CNN与双向LSTM做文本情感分析,通过比较得出CNN与双向LSTM[12]模型的优越性。谌志群等[13]对文献[12]进一步优化,将BERT与双向LSTM结合优于CNN与双向LSTM,采用平衡数据得到较好的评测效果。Cai等[14]对网民的情绪取向利用统计方法进行分类,然后使用BERT与BiLSTM的双向编码组合的预测方法,对用户所表达的情绪倾向进行建模和预测。赵亚欧等[15]对不同类别的平衡样本利用ELMo和Transformer的混合模型进行情感分类,在评价指标上得到了提升。庄穆妮等[16]主要采用LDA主题模型与BERT模型,通过改进BERT预训练任务与词向量深度融合的方式,多次累加深度预训练任务进而提高模型在情感分类中的精确度。
上述研究中样本数据基本属于正负平衡数据,但在实际爬取的文本数据中很少出现正负数据平衡的情况。非平衡文本数据会出现评测失衡的问题,小样本数据易出现过拟合问题,基于此,本文提出了M2BERT-BiLSTM模型进行情感分析,对舆情非平衡文本进行有效分析。
2M2BERT-BiLSTM模型构建
BERT[6]是从Transformer中衍生出来的预训练模型,可将其沿用至自然语言处理任务。Transformer是Google Brain中Ashish Vaswani等在Attention Is All You Need[6]中所提出的sequence2sequence模型,应用方式主要是先进行预训练语言模型,然后适当地分配给下游任务如分类、标记等。
由于BERT是从Transformer中衍生的模型,Transformers模型包括encoder和decoder。此处主要说明encoder部分,考虑摒弃时间循环结构,主要依赖位置编码来辅助建模。

图1Transformer模型结构编码器部分
图1为Transformer模型的编码器部分。第1部分Transformer模型中没有使用序列的顺序信息,“位置编码”提供每个字的位置信息给Transformer, 才能识别出语言中的顺序关系。第2部分多头自注意力机制实际上是由h个self-attention并行组成。输入为Tembedding经过线性变换得到Q、K、V(Q = linear_q(Tembedding)、K = linear_k(Tembedding)、V = linear_v(Tembedding))后同时经过h次的放缩点积attention,得到多头信息。将(1)式结果进行拼接,再通过线性变换得到的值作为多头attention的输出。
(1)
MultiHead(Q,K,V)=Concat(head1,…,headh)Wo
(2)
第3部分残差连接,即在上步中注意力机制进行转置使其维度与Tembedding一致,将两者相加的作用是隐藏层可归一为标准正态分布。在反向传播时,为避免构建BERT模型层次太深或出现梯度消失等问题,训练时常用的方法为残差连接。
Thidden=Activate(Linear(Linear(Tattention)))
(3)
第4部分前向传播,即为两层线性映射并用激活函数。
BERT模型应用方式主要是先进行预训练语言模型,然后适当地配给下游任务如分类、标记等(见图2)。BERT模型通过两种无监督方法相结合进行预训练;Masked LM主要为随机遮盖或替换单条文本里面任意字或词,模型通过对剩余词汇的理解,预测出被遮盖或替换的词。具体为以下内容:

图2 语言模型任务
a. 80%被替换成[mask]; 例如 我喜欢小猫。—我喜欢小[mask]。
b. 10%被替换成任意其他token;例如 我喜欢小猫。—我喜欢小米。
c. 10%原封不动.例如 我喜欢小猫—我喜欢小猫。
另一种无监督方法为Next Sentence Prediction。句子以[CLS]开始, 在两句话之间和句末加[SEP], 此目的是让模型理解两个句子之间的联系。训练输入句子A和B,模型预测A的下句是不是为B。
输入文本数据的第一个标记都是[CLS],对应的是 Transformer 的输出,是用来表示整个句子的,可用于下游的分类任务。
原模型(图3)隐藏层的计算结果里只要取出C(维度是Thidden∈R[batch size,sequence length,embedding dimension])进行混合模型的计算。现沿着sequence length的维度分别求Maxpooling、Meanpooling、M2pooling。M2pooling即均值与最大池化进行链接(两者链接是将两者前后链接),Meanpooling即沿着句子长度维度只求均值,Maxpooling沿着句子长度维度只求最大值。均值池化会将大多数总体信息特征均等处理;最大值池化获取的特征较稀疏,但会保留极化特征;均值与最大池化拼接会在保留多数总体信息特征的基础上突出极化特征。
(4)
(5)
M2pooling=concatenate(Meanpooling&Maxpooling)
(6)

图3M2BERT-BiLSTM模型
其中N表示embedding dimension维度; Thidden(1)表示Thidden中sequence length维度位置为1;M2pooling∈R[batch size ,embedding dimension*2];均值与最大池化拼接的方法就相当于DOC2VEC的方法,将单条评论转换成一条向量,转换出向量的维度是一致的。因此通过gt作为BiLSTM的输入,表示如下:
gt=S1(Wg*Mt+bg)
(7)
其中t={1,2,…,Y},Wg(矩阵调整成与级联后的维度相同)Wg∈Rdg*Y,bg为gt的偏置,Mt为最大值与均值拼接后的特征向量,S1为激活函数Sigmoid函数。
输入向量后需进到隐含层中,由于BiLSTM模型的隐含层分为向前隐含层与向后隐含层。向前隐含层h↑是通过t时刻从正向计算,而向后隐含层h↓是从反向计算,计算如下:
(8)
(9)

隐含层在t时刻输出的向量为Vt,计算如下:
Vt=ht↑⊕ht↓
(10)
将进行隐含层ht↑与隐含层ht↓连接组合成特征向量H, 全连接层使用ReLU作为激活函数,利用特征向量H的输出作为输出层,并采用Softmax函数进行分类。
本文采用M2BERT-BiLSTM方法构建模型,预测微博评论的情绪倾向。M2BERT作为上游部分,BiLSTM作为下游部分;混合模型不是简单的权值组合模型,计算复杂度有所增加,但计算的准确性上升。M2BERT具有学习附近单词统计特征的能力,而BiLSTM具有学习上下文信息的能力,这符合人类语言系统的逻辑。
3 “新型冠状病毒肺炎”微博数据的测试分析
3.1数据选取本文使用VG浏览器以“新型冠状病毒肺炎”为关键词采集有关话题的内容,总共采集微博13 077条数据,内容为用户名、正文、UID、评论内容、bid。数据未带倾向性的标注,但要确保数据有效性,首先对文本内容进行SnowNLP(自然语言处理)分类,再进行人工标注(标注分为正向、中性、负向三类)。通过人工与机器算法的对比分析,进一步调整得出较为准确的正负语料。鉴于本文只研究情感二分类(即正向与负向),正向评论以1表示,负向评论以0表示。选取数据集80%作为训练集,20%作为测试集(见表1)。

表1 微博的评论数据集合
3.2参数设置在易用性与速度方面,PyTorch较优,因此本文模型利用PyTorch搭建。通常采用CPU,特殊样本可以通过GPU加速。BERT模型中的动态学习率和提前终止(early stop)可以确定参数Num_epochs和Learning_rate。设置Num_epochs =7表明本文模型进行了7期训练;主要是根据记录Num_epochs的AUC,如果当前的AUC比上一个epoch没有提升,则降低当前的学习率,该测试中的AUC在7个epoch都没有提升,即停止训练;则模型的学习率为5e-5。Batch表示每次输入模型中训练的部分数据,Batch_size为每个Batch中训练样本的数量。Batch_size可以设置为16、32、64、128、256等,Batch_size=16、32、64的时候迭代次数增加,但训练速度过慢;Batch_size越大越能够表现出全体数据的特征,确定的梯度下降方向越准确;在设置为256的时候迭代次数减少,但造成参数修正缓慢;则Batch_size设置为128。Pad_size表示短评论文本进行填补,长评论文本进行切分处理;微博评论文本属于短文本,因此将每条评论处理长度为20。在BERT[6]模型中Hidden_size设置为768,它表示模型隐藏层神经元数,在混合模型中没有改变,将Hidden_size设置为768(见表2)。

表2 参数设置
3.3结果分析本文从准确率(Precision_score)、召回率(Recall_score)、F1(F1-score)三个方面作为评价指标。Precision是判别模型对负样本的区分能力;Recall体现模型对正样本的识别能力;只有当精确率与召回率的数值同为1时F1值达到最大。若正负数据集为非平衡文本,在计算精确率与召回率时会出现差距。F1-score结合Precision与Recall两个评价指标可以更加全面的反映分类性能。F1值评估分类器性能时,分类器的性能越好F1值越接近于1,因此作为本文衡量实验效果主要评价指标。
①W2V-SVM:使用Jieba进行分词并将数据转换成list in list形式,初始化word2vec模型和词表,各个词向量用平均的方式生成整句对应的向量。用矩阵生成建模,用转换后的矩阵拟合SVM模型,对评论进行模型训练。
②W2V-Logistic:以上方法拟合Logistic模型,对评论进行模型训练。
③LSTM:将文本语料贴上标签并分词,统计词出现次数调用Keras中LSTM,计算预测值进行评价。
④W2V-TextCNN:将句子进行切分,去掉停用词与标点符号。Embedding层调用google开发的Word2Vec方法将文本向量映射为数字向量;经过一维卷积层与最大池化层,最后接一层全连接的softmax层输出每个类别的概率。
⑤BiLSTM:定义超参数大小,定义两层双向LSTM的模型结构,最后使用全连接层在经过softmax输出结果。
⑥BERT:数据预处理是中文数据集,所以使用预处理模型BERT-base,参数为原始参数,利用预训练文本特征后输入BERT模型分类。
⑦Mean-BERT: 从BERT模型隐藏层输出的T沿着sequence length维度的序列使用、即均值池化
⑧Max-BERT:隐藏层输出的T沿着sequence length维度使用即最大池化。
⑨M2BERT:对从隐藏层输出的T沿着sequence length维度使用即均值与最大池化进行拼接。
⑩M2BERT-BiLSTM:最大与均值池化的拼接后输入到BiLSTM的模型中。
在BERT模型中数据集要shuffle,为防止过拟合加入dropout机制、L2正则等。
从以上整体结果分析,非平衡文本数据的问题导致整体的分类效果偏向于对负样本的区分;由于数据特殊性负面情绪比较明显,正面情绪比较中性化则在判别的过程中出现了明显区分。比较BERT与W2V-SVM模型的准确率,W2V-SVM模型达到80.46%,与BERT模型仅差1.67%,说明在评价指标准确率上两者的差距小;但是在召回率相差9.02%。W2V-Logistic在准确率与召回率相对稳定,但F1值比BERT模型低4.04%。LSTM与BiLSTM两者相比,BiLSTM模型各项指标均有不同程度的提升,说明前后两个方向获取文本信息将会更有优势,BiLSTM学习能力比单向的LSTM强。双向LSTM模型虽然考虑了前后文本信息,但神经网络的学习能力加上词向量的组合会更好一些;相比于BERT模型,W2V-TextCNN模型的F1值相差0.79%(见表3)。

表3 基本模型结果比较
Mean-BERT的测试结果受到样本的影响,本文通过筛选出语义不明确的样本进行测试,评价结果中Precision与Recall的得分相差较大;语义不明确的样本信息特征均等处理,导致极化特征未凸显,在非平衡文本数据的情况下忽略特征的情感含义造成模型难以识别计划特征。从以上结果来看,Max-BERT模型提取出极化特征,但小样本只将关键词信息提取出来会使得文本信息大量丢失;评价指标F1值达到79.88%,比BERT模型降低了0.52%,说明此模型比BERT略差。均值与最大化拼接不仅考虑当前文本极化特征,而且不会丢失大部分文本信息,BERT模型与此模型F1值相差0.13%;F1值相比于均值池化与最大值池化有所提高(见表4)。在图4中,根据AUC做出比较并选择较优模型进行集成处理。M2BERT-BiLSTM模型不仅在F1值上有较高的提升,并且在评判正负样本分类的结果上也没有太大的差距。在可控范围之内达到较优的效果,在非平衡文本数据的情况下选择M2BERT-BiLSTM模型进行情感分类。
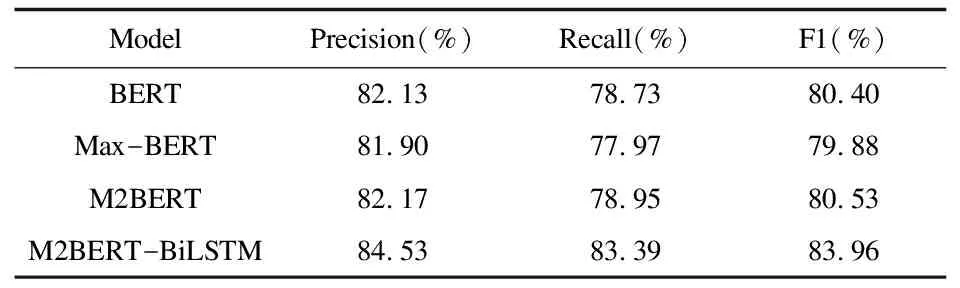
表4BERT改进模型结果比较

图4 不同模型的AUC比较
图4为BERT和M2BERT-BiLSTM模型训练集与测试集的AUC值比较。根据图4可以分析出从epoch1到epoch5的过程中,M2BERT-BiLSTM模型训练集与测试集的AUC差距从12.55%逐渐缩小至1.07%;而相比于M2BERT-BiLSTM模型,BERT模型训练集与测试集的效果较差。因此在准确性上M2BERT-BiLSTM模型比BERT模型有较好的效果。
4 “新型冠状病毒肺炎”事件的文本情感词网分析
通过M2BERT-BiLSTM模型对“新型冠状病毒肺炎”事件的文本数据进行分类,分类后得到的正负向文本进行词网分析。为增强正向与负向的特征词显示度,提取出每行评论文本特征词后删除事件名称(新型冠状病毒肺炎等),然后利用Gephi软件进行绘图。情感特征词网可以更加直观地反映出原文本语料的内容,例如:“武汉”与“医护”分开时,在不同的语境中表达不同的含义。正向可表达为“武汉的医护人员辛苦了”,还可以表示“保护好奔赴于武汉的医护人员”;负向可以表达“武汉医护人员的隔离问题怎么办”,还可能表达“武汉医护人民出门要戴口罩”。

图5 新型冠状病毒肺炎正面情绪文本特征词网
通过图5可以得出,正面情绪特征词网聚集较为明显,其中主要聚集点有7部分。聚点1“保护”为出发点,网民正面情绪主要来自于医护人员、社会工作者、物资及时的送达、“逆行者”等。在疫情期间各地医护人员勇敢逆行,火速驰援湖北武汉,奋战于一线的医护人员积极带领公众共度难关,因此保护医护人员的安全成为公众所期盼的愿望。聚点2“武汉”为中心点信息主要为相信国家和政府“封城”的措施是有效的,在家自行隔离能有效控制疫情传播。聚点3“加油”为中心点信息希望全国各地疫情早日散去,坚持就是胜利,可以听到好消息。聚点4以“接触”为起点较为零散,主要展示出的信息为不能欢度春节,但人们尽量做好防护措施。聚点5为小团体,主要表达为燃眉之急的事务为企业复工;由于疫情的原因居家隔离没有经济来源。还说明此次疫情表现出科技的重要性,大数据技术可以提升疫情的有效管理。聚点6主要是网民希望出行尽快恢复正常;大多网民从未有过长时间的居家隔离,因此群众们还未适应。聚点7为我国在第一时间防止疫情扩散,万众一心抗击疫情。其余为散落词团,可先不作为重点考虑。

图6 新型冠状病毒肺炎负面情绪文本特征词网
从图6整体可以得出,负面情绪特征词网中言语离散,说明负向的语言较为单一且不聚集。负面情绪成团较少,但是明显成团的地方需要特别关注,其中主要聚集点有5部分。聚点1“野生”“海鲜”“市场”等词可知疫情发现地在海鲜市场,得出野生海鲜市场会造成公众负面情绪高涨,而北京新发地市场的三文鱼等水产品检测出新冠病毒,将会引起公众情绪的二次爆发。为防止引起公众负面情绪波动,相关单位应对各地所有海鲜市场等易发生疫情的市场做出规范的防控措施;加强对肉类、海鲜等货物的监测监管,掌握其来源和流向;加强工作人员的健康管理,外来人员的体温检测等措施;通过官方平台将采取的措施及时公布,使公众舆论不产生大幅度上升。聚点2“武汉”为中心点,“造谣”“报道”“轨迹”为环绕点可知,疫情得到有效防控,但各地陆续出现无症状感染者。通过各大平台,相关单位应将感染患者的行动轨迹及时公布、对于疫情制定的措施及时有效报道,以免公民随意猜测,容易形成谣言无限扩散从而造成不必要的恐慌。通过聚点3以“隔离”为出发点,“外地”“检测”“谣言”“传播”为辅助点分析,各地区对于外来人员首先做核酸检测,并且对于有疑似症状者采取恰当的医学观察;对于外来人员的核酸检测给予证明,防止人员行动不便。聚点4为“医类方面”“口罩”的原因主要可以从两个角度出发:一是在疫情初发阶段口罩的稀缺;二是在全国各地仍有感染患者,口罩负面情绪上涨,从侧面反映出疫情情况好转已有人放松警惕。关于医药的传言,相关单位要及时回应,以防止公众盲目相信并出现抢购的情况。聚点5为分散点,主要讨论病毒的潜伏期、公布航班的情况等。
5 结 语
本文紧紧围绕“新型冠状病毒肺炎”事件的相关话题,根据有关的知识探讨了舆情非平衡文本数据的情感分析。对微博相关的内容进行抓取,通过人工与机器算法的对比分析得出较为准确的语料,在通过M2BERT-BiLSTM模型对舆情非平衡文本数据进行情感分类。运用正负向评论分别计算行特征词与共现矩阵,利用Gephi中模块度画出正向情绪特征词网与负向情绪特征词网,更加清晰了解舆情的情感特征;根据舆情文本的特征词网分析出事件产生正面情绪与负面情绪的主要原因,有助于相关部门通过相关的分析及时采取措施。本研究也存在不足之处,采集的数据集不大以至于未能挖掘更多的情感特征以供情感分析,在后续研究中将扩大数据范围进行深入的研究,为舆情的分析与引导提供更好的建议。
