遗传帝国竞争混合算法在装配序列规划中的研究与应用
2022-04-27黄丰云蒋园健
黄丰云,熊 雄,周 铮,蒋园健
(武汉理工大学机电工程学院,湖北 武汉 430000)
1 引言
装配序列规划(Assembly Sequence Planning,ASP)是装配工艺规划中的重要内容,装配序列的优劣将直接影响到装配工艺,进而影响装配成本,因此对ASP问题的研究有重要意义。在已有的装配序列规划方法中,智能优化算法是一种常见的ASP求解方法。文献[1]基于拆卸法原理,通过拆卸矩阵得到可行合理的可拆卸候选集,来指导装配序列的构造,保证了序列的几何可行性,并用蚁群算法优化得到最优装配序列。文献[2]将粒子群算法应用于复杂产品装配序列规划,通过采用新的学习机制来改进算法,增强了算法的搜索能力。文献[3]也通过引入拆卸矩阵,使得装配过程中重定向次数和装配工具转换次数等降到最低,并用遗传算法求解得到最优装配序列。文献[4]利用有向图法获得了表达装配关系的矩阵,并依据矩阵来建立评价序列优劣的标准,对帝国竞争算法进行了研究与改进来求解最优装配序列。
近年来,除了用单一算法进行装配序列规划外,许多研究者将不同种算法融合来求解ASP问题。文献[5]建立蚁群遗传混合算法求解ASP问题,先用蚁群算法产生初始序列,再使用遗传算法对蚁群算法的初始序列进行优化,根据优化解生成蚁群算法中蚂蚁的信息素,通过加速蚁群算法最优解信息的积累来更快地得到最优装配序列。文献[6]在分析可行装配序列的推理约束条件后,建立了考虑稳定性、聚合性及装配方向改变次数三个因素的优化评价模型,以遗传模拟退火混合算法求解最优装配序列。文献[7]将几何可行性和一致性设计作为约束条件,再将可装配性和这两个约束结合起来建立目标函数,提出一种结合免疫算法和粒子群优化算法的装配序列规划方法。文献[8]将帝国竞争算法和遗传算法混合来求解ASP问题,首先利用帝国竞争算法产生可行的装配序列作为遗传算法初始种群,然后调用遗传算法继续迭代,达到最大迭代次数后输出最优装配序列。
相对于单一的算法,混合算法在求解ASP问题上表现出更大的优势,它综合了各自算法的优缺点,搜索能力更强。例如,遗传算法具有良好的全局搜索能力,可扩展性强,容易与其他算法结合的优点,但是其局部搜索能力较差,导致利用单一算法求解比较费时,在算法执行后期搜索效率较低,容易产生早熟收敛的问题。模拟退火算法具有良好的局部搜索能力,但他对整个搜索空间的拓展性不够好,因此全局搜索能力不够强,运算效率不够高。文献[6]正是利用遗传算法的全局搜索能力与模拟退火算法的局部搜索能力,提出遗传模拟退火混合算法,快速获得最优装配序列。
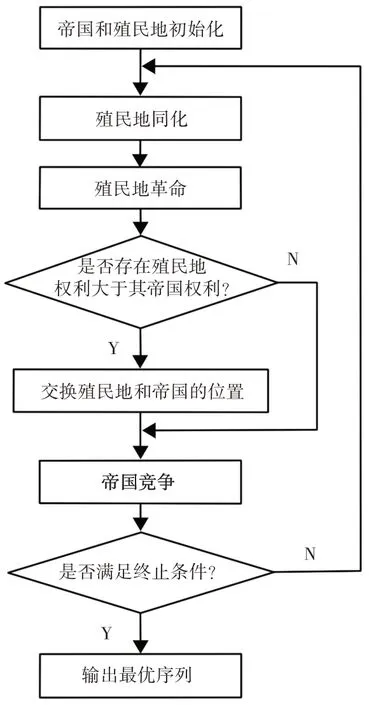
帝国竞争算法[9](Imperialist Competitive Algorithm,ICA)是Atashpaz-Gargari和Lucas于2007年提出了一种通过模拟殖民地同化机制和帝国竞争机制而形成的新的智能优化算法。ICA在寻优方面有着很好的全局搜索能力和信息不依赖的寻优性能,算法利用同化机制让殖民地向其所属帝国移动进行局部搜索,保证了算法的局部搜索能力。同时,ICA中帝国竞争操作使帝国的殖民地可以分配到其他帝国,突破了原有的搜索界限,增加了国家的多样性,可以避免“早熟”现象的发生。利用帝国竞争算法的良好局部搜索能力,遗传算法的较强全局搜索能力和可扩展性,提出遗传帝国竞争混合算法。不同于文献[8]中对ICA设定固定的迭代次数,在ICA达到设定迭代次数后将产生国家作为遗传算法初始种群,利用遗传算法继续寻优,直到达到规定最大迭代次数,算法终止。以遗传算法作为初始算法,迭代一定次数后的序列作为帝国竞争算法的初始帝国,转至帝国竞争算法继续寻优,在帝国竞争算法迭代过程中,达到某种条件时,认为算法陷入局部最优,更新遗传算法种群,再调用遗传算法继续寻优。交替执行两种算法,直到达到算法停止条件,输出混合算法最优装配序列。
2 系统整体架构
在进行装配序列规划时,首先根据CAD产品的装配模型,获得装配的装配有向图和装配连接图,并根据图推理获得装配干涉矩阵、连接矩阵等,根据各矩阵构建表达综合成本的适应度函数,适应度函数值越低,说明综合成本越低,装配序列越优。混合算法以装配综合成本最低为目标,进行混合迭代,当达到算法终止条件时,输出结果。基于混合算法的装配序列规划系统整体架构,如图1所示。
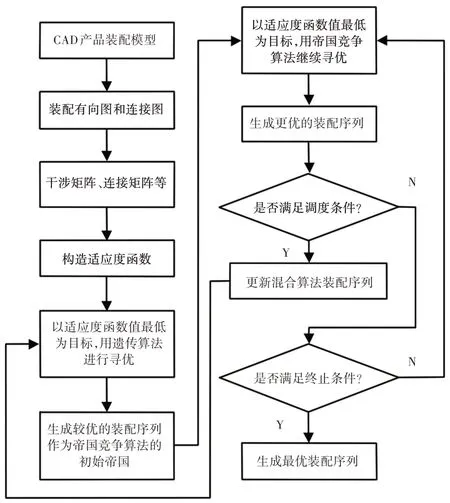
图1 基于混合算法的装配序列规划方法整体架构Fig.1 An Overall Architecture of Assembly Sequence Planning Method Based on Hybrid Algorithms
3 适应度函数构造
在ASP问题中,首先要保证的是装配序列可行,然后,综合考虑装配序列可行性、装配序列稳定性、装配重定向性和装配聚合性。量化各项指标的计算方法,通过加权处理得到综合适应度函数,为最优装配序列生成提供计算依据。
3.1 装配序列的可行性
在空间直角坐标系中,零件的基本装配方向有d(k)={+x,-x,+y,-y,+z,-z}={d k}六个方向,建立零件在空间直角坐标系中的干涉矩阵,其中,k为装配方向,a ij为零件P j沿k方向装配到位时与零件P i的干涉情况,其取值为:

定义I k(P i)(k=1,2,3,4,5,6)为零件P i沿k方向运动到装配位置时与已装配好的各零件之间的干涉值之和,若I k(P i)=0,则零件P i可沿方向k进行装

定义V g为所有零件装配到位后的干涉值之和,则有:

判断一个装配序列是否可行的依据是:如果V g=0,装配序列可行,如果V g≠0,则装配序列不可行。
3.2 装配序列的稳定性
装配序列的稳定性是指零件或子装配体参与装配中,零件与零件之间,零件与子装配之间在自身重力和夹具等产生的装配力作用下,保持装配零件稳定性的能力[10]。装配序列的稳定性体现了装配的安全性和可靠性。
为量化表示装配序列的稳定性,建立装配体的连接矩阵C=其中c i j表示零件P i与零件P j的连接关系,其取值为:

稳定连接表示零件之间通过紧固件或者是过盈配合连接,接触连接表示零件之间相互接触但必须有外力才能保持稳定的连接。装配序列稳定性的表示为:
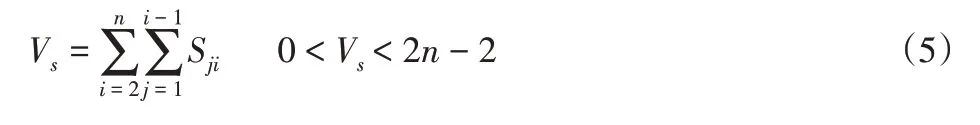
式中:n—零件的个数;S ji—零件P i的稳定性,这里的装配序列稳定性不仅考虑了序列中零件与相邻零件之间的稳定性,还考虑了零件与已经装配好的零件间的稳定性,更符合实际。S ji的取值与c ij的取值相同。显然,V s越大,装配序列越稳定。
3.3 装配的重定向性
装配的重定向性表示了装配方向的改变次数,装配方向的改变次数越多,操作越复杂,装配效率越低。建立零件的装配方向矩阵其取值为:

装配方向的改变次数V d的求解算法如下:
(1)令i=0,m=1,V d=0;
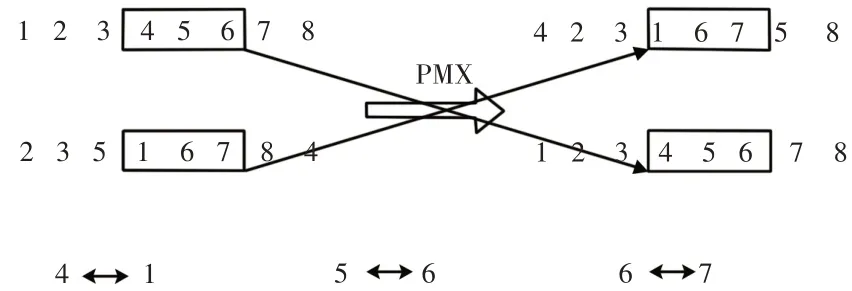
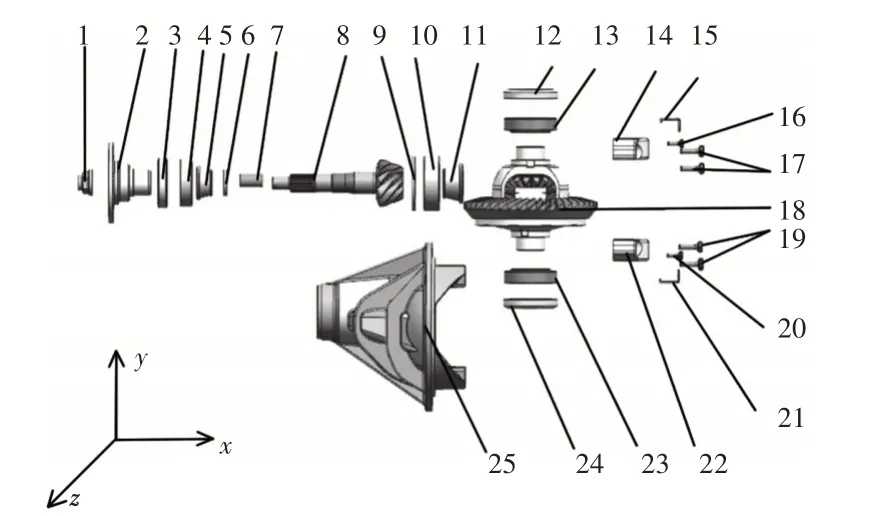
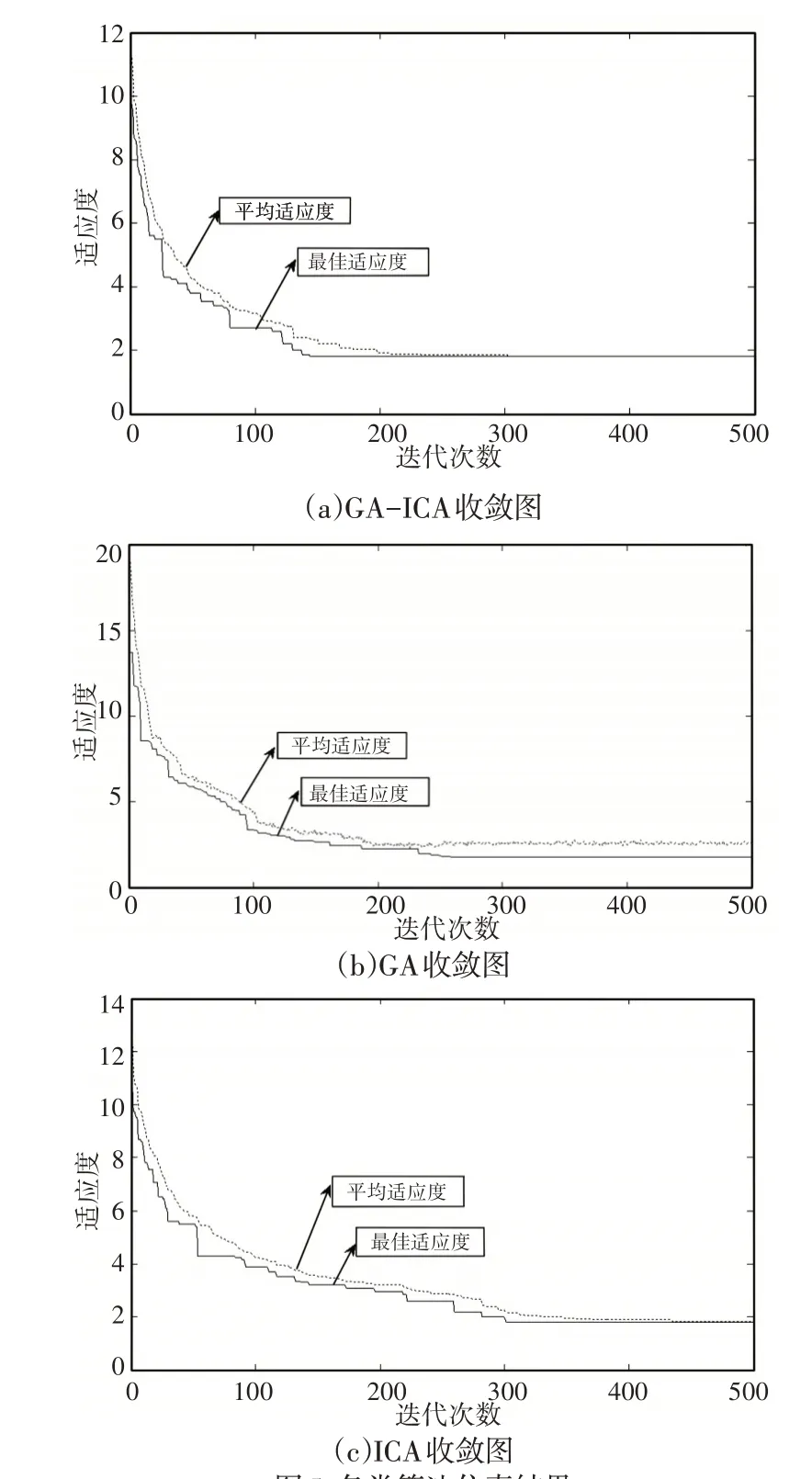
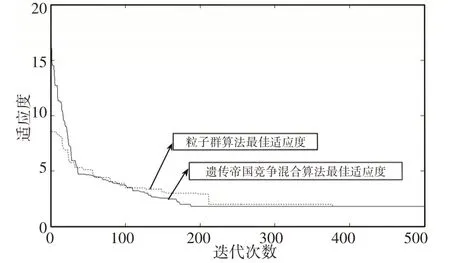
(3)令i=i+m+1,如果i (4)结束。 V d越小,装配的方向改变次数越少,装配序列越好。 装配的聚合性表示装配过程中装配工具的改变次数,根据实际情况,建立装配工具集矩阵,则装配工具改变次数V t的求解算法为: (1)令i=0,m=1,V t=0; (2)若T(i+m)=t i+m=k(k为装配方向),但T(i+m+1)=t i+m+1≠k,则在装配零件P i+m+1时需要改变装配工具,V t=V t+1,转至步骤(3),否则,令m=m+1,如果i+m+1 (3)令i=i+m+1,如果i (4)结束。 V t越小,装配的工具改变次数越少,装配序列越好。 综合考虑装配序列的可行性、装配序列的稳定性、装配序列的重定向性、装配序列的聚合性,可建立对这些评价指标加权的适应度函数,如下: 式中:ω1,ω2,ω3,ω4—各 项指标的权重系数。 适应度值越小,表示综合装配成本越低,装配序列越好。 针对ASP问题的特点,在进行混合算法求解ASP问题时,对遗传算法和帝国竞争算法做以下改进: (1)对零件序列的编码采用十进制实数编码,遗传算法中的种群个体、帝国竞争算法中的国家和殖民地位置为零件组成的序列。 (2)在遗传算法中引入最佳个体保留策略,最佳个体保留策略的操作过程如下: 找出当前代中最好的(最优的装配序列)和最差的个体;若当前代所有种群中最好个体比迄今为止的最好个体还要优,则以这个个体作为新的迄今为止的最好个体;用迄今为止的最好个体替换掉当前群体中的最差个体。 (3)在帝国竞争中,改变标准帝国竞争算法中将权利最弱的帝国的殖民地分配给权利最高的帝国,采用赌轮选择法,随机选择帝国分配殖民地,可防止算法早熟。 遗传算法作为混合的初始迭代算法,其作用是:产生初始较优的序列作为帝国竞争算法的初始帝国;在帝国竞争算法陷入局部最优时,调用遗传算法,增加局部搜索能力。 遗传算法的求解过程如下: (1)设置初始参数,包括种群数量Q,交叉概率P c和变异概率P m,迭代次数T。 (2)随机生成Q个父代个体,并将父代按适应度值从小到大顺序排列(适应度值越小,序列越优),记录父代对应的标签。 (3)对父代进行选择操作。 (4)对选择的父代进行交叉、变异操作,获得子代装配序列,并计算适应度值。 (5)把所有的父代子代个体放在一起,按最佳个体保留策略操作,并计算所有个体适应度值,迭代次数加1。 (6)当迭代次数未达到T时,转至(3),当迭代次数达到T时,选择最优(适应度值最低)的前λ个个体,作为帝国竞争算法的初始帝国,调用帝国竞争算法。 4.2.1 建立初始帝国 在混合算法中,帝国竞争算法选择遗传算法中前λ个最优个体作为帝国竞争算法初始帝国,并随机生成N pop-λ个初始国家,计算每个国家的权利,在ASP问题中,权利的大小与适应度函数有关,适应度函数值越小,权利值越大。 式中:c i—第i个国家的权利;fitness(i)为第i个国家的适应度值。 对计算的权利值进行排序,选择权利值最大的前N imp个国家作为初始帝国,其余的N col个国家作为初始殖民地。 对初始帝国权利归一化处理 式中:p n和c n—第n个帝国的归一化权利和标准权利,根据帝国的归一化权利,分配殖民地,第n个帝国的殖民地数量为: 其中,round为四舍五入取整。 4.2.2 殖民地同化 殖民地同化过程采用部分匹配交叉(Partially Matching Cross‐over,PMX)算法交叉M次,其中,部分匹配交叉(Partially Matching Crossover,PMX)算法的处理过程如下: 假设帝国的位置为( 1,2,3,4,5,6,7,8),殖民地的位置为(2,3,5,1,6,7,8,4),首先随机选择两个交叉的点,假如第一个随机选择的交叉点位置为4,第二个交叉点位置为6,将这两个点之间的位置将进行交叉,其它的位置进行复制或者用相匹配的数进行替换。在此实例中,第一个父代个体中456被选中,第二个父代个体中167被选中。那么4与1,5与6,6与7相匹配。匹配过程,如图2所示。 图2 PMX交叉操作Fig.2 PMX Crossover Operation 首先将456与167分别加入到子代2和子代1中相应的位置,然后将其他位置上的数字直接复制到相应的后代中,如果该数字已经在该子代中已经存在,则用相应的匹配法则进行替换,最终得到两个新的子代,选择两个子代中权利较大的个体,替换原来的殖民地成为同化殖民地。 4.2.3 殖民地革命 殖民地革命过程采用交换变异(Exchange Mutation,EM)算法变异R次,即从殖民地个体中选择两个基因位置,然后互换这两个位置的基因,得到新的殖民地。为了更好的保持殖民地的多样性,综合考虑到迭代次数和帝国权利大小,设计殖民地革命概率动态调节公式: 式中:p r—革命概率;ξ—调节系数;d—当前迭代次数;Gmax—最大迭代次数—帝国i的殖民地归一化权利—帝国i的最大归一化权利。在式(12)中,权利越小的殖民地,革命的概率越大,这样可以促进解的不断优化,在算法迭代后期,革命概率会变大,可增加搜索范围,避免算法陷入局部最优,增强全局搜索能力。 在完成殖民地同化和革命操作后,对所有帝国及其所属殖民地,检查帝国和殖民地的权利大小,如果存在殖民地权利大于其帝国权利,交换殖民地与帝国位置来更新帝国。 4.2.4 帝国竞争 帝国竞争算法中帝国之间的竞争是算法收敛的关键步骤,帝国竞争实际上是帝国所属殖民地的再分配过程,通过竞争,权利较大的帝国获得更多的殖民地,相应的,权利最小的帝国不断失去殖民地,当其殖民地全部消失时,该帝国消失。帝国竞争过程如下: (1)计算帝国总权利。帝国的权利由该帝国的权利和帝国所属殖民地的平均权利的加权和组成,公式为: 式中:TR n—第n个帝国的总权利;δ—权利系数;p n—帝国的权利;p n j—帝国的殖民地j的权利;N R n—帝国殖民地的个数。 (2)帝国权利的归一化。第n个帝国的归一化权利TP n计算公式如下: (3)根据归一化的帝国权利,赌轮选择分配权利最弱殖民地的帝国i。帝国竞争算法通过不断的殖民地同化、革命,帝国竞争,最终只剩下一个帝国,即得到算法最优解。 4.2.5 混合算法中帝国竞争算法计算流程 帝国竞争算法在经过反复殖民地同化、革命,帝国竞争后,不断收敛到最优解,当只有一个帝国后,算法达到终止条件,也可以用迭代次数作为终止条件,此处以迭代次数作为终止条件。混合算法中帝国竞争算法的计算流程图,如图3所示。 图3 改进帝国竞争算法流程图Fig.3 Improved Imperial Competition Algorithms Flow Chart 计算流程如下: (1)设置帝国竞争算法的初始参数,包括算法的初始国家数量N pop-λ,初始帝国的数量N imp,从遗传算法中选择前λ个最优个体作为帝国竞争算法初始帝国,调节系数为ξ,权利系数为δ,最小和最大迭代次数Gmin和Gmax,殖民地同化操作次数M,革命操作次数R,当前迭代代数K=K+T。 (2)计算N pop-λ个国家的适应度值,并按适应度值升序排列。当λ≤N imp时,从N po p-λ个国家中再挑选出适应度值最低的前N imp-λ个作为初始帝国,使初始帝国数量达到N imp,初始殖民地数量为N pop-N im p;当λ>N imp时,按适应度值升序从λ个中选取N imp个作为初始帝国,将剩下的λ-N imp个并入到初始国家中。 (3)所有帝国和殖民地进行同化、革命和竞争操作。 (4)计算所有帝国和殖民地的位置和适应度值,迭代代数K=K+1。 (5)当帝国竞争算法迭代代数K未达到Gmin时,继续进行(3)操作;在K达到Gmin时,且满足调用条件(见4.3.1节)时,调用遗传算法,更新迭代代数K=K+T;当K达到Gmax时,终止帝国竞争算法操作。 4.3.1 遗传帝国竞争算法融合策略 在算法开始时,采用遗传算法迭代T次,计算所有序列的适应度值,并根据适应度从小到大顺序取出前λ个个体,作为帝国竞争算法初始帝国,并随机生成N pop-λ个初始国家,开始执行帝国竞争算法。当帝国竞争算法在执行过程中陷入局部最优时,调用遗传算法提高局部搜索能力。混合算法的融合策略如下: (1)设定遗传算法迭代次数T,当达到T时,将产生的序列作为帝国竞争算法的初始帝国,并随机生成N po p-λ个初始国家,开始执行帝国竞争算法。 (2)设定帝国竞争算法的最小和最大迭代次数Gmin和Gmax。 (3)在帝国竞争算法执行过程中,对于∀G i,G min≤G i≤G max时,对于最佳帝国,若其后的连续n代( )Gmin≤G i+n≤Gmax,n=1,2...,都存在Δf i+n-1-Δf i+n<τ,则可认为帝国竞争算法中帝国竞争已停滞,算法陷入局部最优,此时需要调用遗传算法提高局部搜索能力。其中为第i代帝国的平均适应度值,为第i代帝国的最小适应度值)。 4.3.2 混合算法的装配序列更新策略 在混合算法执行的过程中,存在遗传算迭代T次后,执行帝国竞争算法,以及帝国竞争算法在陷入局部最优时调用遗传算法的过程。但是,在帝国竞争算法执行阶段,遗传算法并未进行全局搜索,其装配序列也未改变,在调用遗传算法时,需要及时更新遗传算法的装配序列,同理,在遗传算法执行过程中,帝国竞争算法也未执行,其装配序列也未更新。因此,需要对混合算法相互调用时装配序列更新做研究。针对ASP问题的特点,同时兼顾考虑算法局部搜索时,保持种群的多样性,提高局部搜索能力,定义如下的装配序列更新策略。 (1)帝国竞争算法执行后调用遗传算法时,选择权利值最高的前α个国家和殖民地加入遗传算法种群中,按赌轮选择法从遗传算法种群随机删除α个个体,执行遗传算法; (2)遗传算法迭代T次后,执行帝国竞争算法时,选择最优的前β(β≤Nimp)个个体替换最弱的β个帝国,执行帝国竞争算法。 基于如上策略,保证了混合算法迭代过程中序列的及时更新,同时增加了群体的多样性,提高了局部搜索能力。 4.3.3 混合算法的计算流程 (1)设置算法初始参数,包括P c,P m,λ,n,N pop,N im p,τ,α,β,K等。 (2)执行遗传算法,计算每一个种群个体的适应度,记录对应的序列。 (3)判断遗传算法迭代次数是否达到T,若是,从遗传算法所有父代与子代个体中取出前λ个作为帝国竞争算法初始帝国,并随机生成N pop-λ个初始国家,开始执行帝国竞争算法,按4.2.5节方法更新帝国竞争算法迭代代数K;若否,继续执行遗传算法。 (4)判断帝国竞争算法迭代数K是否达到Gmin,若否,继续执行帝国竞争算法;若是,启动遗传帝国竞争算法融合策略,连续判断从当前代之后的n代帝国竞争算法迭代的Δf变化情况,以确定是否调用遗传算法。若满足调用条件,则调用遗传算法,计算遗传算法的全局最优解,并转至(2),更新帝国竞争算法迭代代数K;否则,继续执行帝国竞争算法,并更新代数K。 (5)判断帝国竞争算法迭代代数K是否达到Gmax,若否,继续执行帝国竞争算法,若是,计算帝国竞争算法的全局最优帝国,记录前α个帝国或殖民地的序列,并更新遗传算法的序列,转至(2),更新帝国竞争算法迭代代数K。 (6)判断K是否达到混合算法最大迭代代数MaxDecad es,若是,则输出最优装配序列;若否,则继续执行前面步骤,直至达到最大迭代代数MaxDecad es。 以某乘用车后桥减速器零部件装配为例,对所提混合算法在MATLAB程序中进行验证,所涉零部件共计25个,如图4所示。零件的编号和零件名称,如表1所示。需要指出的是,混合算法不需要指定装配基础件,装配基础件的获得由程序运行中自动得到。 图4 减速器爆炸图Fig.4 Reducer Explosion Chart 表1 减速器零件编号和名称Tab.1 Reducer Part Number and Name 对混合算法设置参数:遗传算法中,最大迭代次数T=20,初始种群数量Q=200,交叉概率P c=0.9,变异概率P m=0.1,λ=15;帝国竞争算法中,初始种群规模N imp=10,初始国家数目为N pop=500;调节系数ξ=0.3,权利系数δ=0.1,最小迭代次数Gmin=50,最大迭代次数Gmax=100,α=β=10,n=2,τ=0.2,混合算法中K=1,最大迭代次数Max Dec ades=500。 各个算法执行50次中算法收敛到最优解的情况,如表2所示。某次迭代中混合算法,遗传算法和帝国竞争算法求解装配序列的迭代收敛曲线,如图5所示。某次迭代中混合算法同文献[11]对比的迭代曲线,如图6所示。 表2 50次迭代收敛情况Tab.2 Convergence of 50 Iterations 图5 各类算法仿真结果Fig.5 Simulation Results of Various Algorithms 图6 GA-ICA与PSO仿真结果Fig.6 Simulation Results of GA-ICA and PSO 从执行效果看,混合算法在50次迭代中均收敛到最优解,收敛率达到100%,而单一算法在50次迭代中均有无法收敛到最优解的情况。从某次迭代中的收敛曲线可以看出,混合算法的求解效率明显优于单一的优化算法,混合算法最佳个体在144代收敛到全局最优解,而单一的GA、ICA、PSO分别在258代、301代、188代收敛到最优解,混合算法需要最少的迭代次数即可完成收敛。而且,混合算法在233代时所有种群均收敛到最优解,而单一算法迭代500代只有部分个体收敛到最优解。混合算法可获得一条装配综合成本较小(适应度值最低)的可行装配序P25-P6-P9-P10-P4-P11-P8-P7-P5-P3-P2-P1-P18-P13-P23-P12-P24-P14-P22-P17-P19-P15-P16-P20-P21。 针对ASP问题的特点,提出了用遗传帝国竞争混合算法求解ASP问题的方法。建立了综合考虑装配序列可行性、装配序列稳定性、装配重定向性以及装配聚合性四个评价指标的适应度函数,利用两种算法各自的优点,提出了遗传帝国竞争混合算法的融合策略,以适应度值最低为目标,利用混合算法快速得到最优解。以减速器为实例对混合算法进行了试验,验证了混合算法的可行性,通过实验对比分析,结果表明,混合算法收敛速度明显优于单一的优化算法,为ASP问题求解提供了一种有效的方法。3.4 装配的聚合性
3.5 建立适应度函数
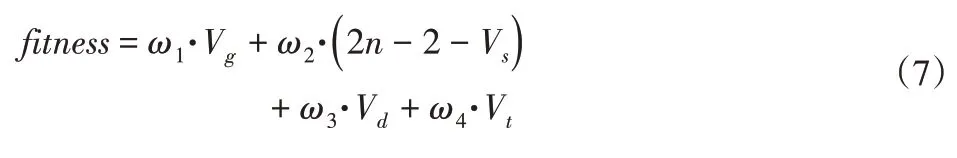
4 基于遗传帝国竞争混合算法的ASP寻优
4.1 基于遗传算法的ASP求解过程
4.2 基于帝国竞争算法的ASP求解过程







4.3 基于遗传帝国竞争混合算法的装配序列规划
5 实例验证与分析


6 结论
