基于跳跃连接注意力网络的音乐分离
2022-04-27王岚
王 岚
(中国传媒大学,北京 100024)
0 引言
随着移动互联网的发展,大量形式多样的音乐不断涌现,人们对音乐分离的需求也逐步增多。分离技术被广泛应用于许多领域,并成为许多领域的预处理步骤,如卡拉OK[1]、歌词自动识别、歌手识别等,在一些商业应用中发挥着至关重要的作用。单声道的歌声与伴奏分离是指用一个声道来记录包含歌声和伴奏的音乐信息,并尽可能彻底地分离它们。本文针对单声道的音乐进行分离技术的研究。
鸡尾酒问题[2]由COLIN CHERRY 在1953 年首次提出,指的是在多人同时交谈的鸡尾酒会,一个人可以专注于一个人的讲话,而忽略另一个人的干扰,建模过滤掉目标语言的模型。歌声和伴奏的分离已经进行了半个多世纪的研究,研究方法分为传统的分离方法和基于深度学习的分离方法。传统的分离方法主要是基于信号处理统计和基于心理声学的方法,对音乐中非线性关系的处理表现出了局限性。近年来,神经网络在音乐信号中非线性关系的处理方面表现出良好的非线性能力,可以处理更高维度的数据,因此在音乐分离系统中的应用变得越来越普遍。
近年来,基于卷积编解码器的分离模型[3]取得了良好的分离效果。卷积编解码器把输入音频转换成图像的形式进行处理,取得了显著的成功。但频谱图通过瓶颈层时被压缩,重新缩放到目标频谱的大小后会损失重要频谱信息,而损失的信息影响着分离的效果。为解决这个问题,本文提出在卷积编解码器的跳跃连接上加入注意力机制。注意力可在远距离上捕捉到信息间的关联,将注意力机制应用到分离模型,能够指导解码部分重构目标源频谱,以解决网络丢失重要信息问题,提升分离性能。
1 分离方法
1.1 分离模型
本文所提的整体分离流程如图1 所示。音乐数据为歌声与伴奏混合而成的数据。音乐数据进入分离模型前需进行预处理步骤,预处理使用短时傅里叶变换把音乐信号从时域变换到频域,得到幅度谱和相位谱,取出其幅度谱输入到分离模型得到时频掩膜,将时频掩膜和混合声源进行运算,进而得到预测声源的幅度谱,最后将预测声源的幅度谱与原始的相位谱对应元素相乘得到预测的音源即歌声和伴奏。本文的基线模型为卷积编解码模型[3],此模型由6 层编码器和6 层解码器组成。
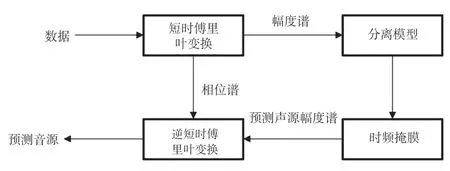
图1 分离流程图
图2 为混合了歌声和伴奏的声源,图3 是使用基线模型分离出的音频的歌声部分,图4 是真实干净的歌声部分声源。

图2 混合歌声和伴奏的频谱图

图3 基线模型分离出的歌声频谱图
观察频谱图可知,图2 中混合了歌声和伴奏的音频的频谱更为丰富,伴奏与歌声的频域信息在时间上重叠交错,从图中难以区分歌声频谱;图4 中真实干净的歌声频谱谐波结构较为清晰,没有谐波的时间段为仅有伴奏演奏并无人声演唱的部分;使用基线模型分离的音频频谱图的开始部分出现干扰音源引入的现象,即黑框部分为模型引入的噪声,相比于图4 中干净声源频谱在纵轴上出现断续现象,这是因为分离模型随着模型层数的增加丢失了有效信息,从而不能更好地恢复频谱信息。针对分离模型出现丢失恢复重要信息的问题,本文改进后的模型如图5 所示。

图4 真实干净歌声频谱图
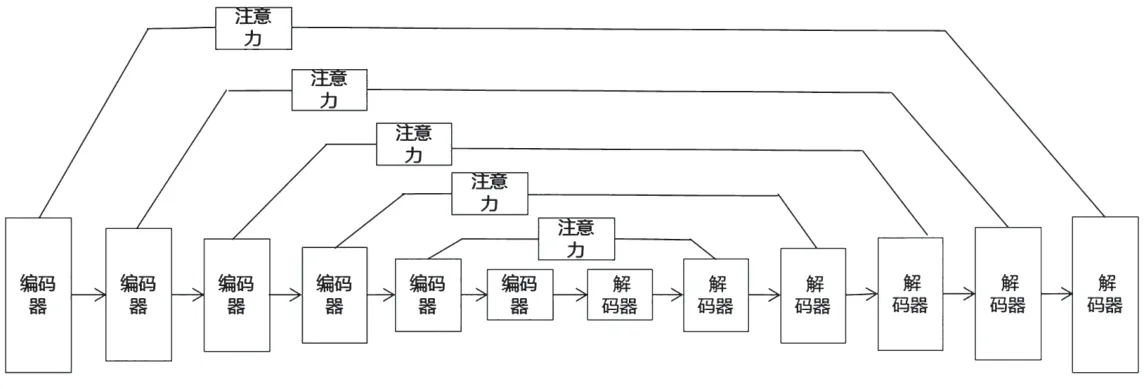
图5 跳跃连接注意力模型
本文的跳跃连接注意力模型由6 层编解码结构组成,每层编码器由卷积、批归一化[4]和ReLU激活函数组成,编码器层的目标是提取音乐信号特征,是把图像的分辨率从大逐步变到小的过程,经过最后一个编码器得到目标源信号的高维特征,经由解码器恢复。解码部分由反卷积、批归一化及ReLU 激活函数组成,解码器把图像的分辨率由小恢复到大。跳跃连接使用适应音乐分离的注意力机制,使编码器和解码器进行信息的交流,以有效恢复频谱信息。本文将注意力机制加入到跳跃连接上,以解决网络丢失重要频谱信息的问题。
1.2 注意力机制
跳跃连接注意力模型中,注意力机制的具体构造如图6 所示。注意力机制由卷积和Sigmoid 激活函数构成,符号⊕表示将信号按照通道数相加,符号⊗表示哈达玛乘积。输入为每层编码器和解码器分别经过二维卷积然后把编码器和解码器的信息融合,经激活函数进行非线性转换,再经过卷积和激活函数为信息分配权重,最后与解码器运算,以指导解码器恢复频谱信息。注意力机制的设计遵循为信息分配不同权重的思想,重要的信息分配更大的权值。

图6 注意力机制具体结构
1.3 训练目标及损失函数
本文的训练目标为时频掩膜。分离模型输出歌声和伴奏的时频掩膜y^1和y^2,输出的时频掩膜与混合信号z进行哈达玛运算得到预测的歌声和伴奏即和,如式(1)和式(2)所示,符号⊙表示哈达玛运算。

损失函数采用最小绝对值偏差损失函数,定义如式(3)所示,预测的歌声和伴奏的值与真实的值进行反向传播,更新模型参数。

2 实验结果与分析
2.1 数据集
实验的数据集为开源数据集MUSDB18,此数据集由150 条全长英文音轨组成,分为训练集文件和测试集文件,其中训练集由100 条音轨组成,时长大概400 min,测试集由50 条音轨组成,时长大约200 min。每个音频文件都包含混合音频及其相应的源,即包括混合声源、歌声、鼓、贝司以及其他声源。由于本文评估歌声和伴奏,因此将除歌声以外的其他声源混合,得到伴奏的独立声源,以反向传播更新参数。该实验在100 个训练集文件进行模型训练,在50 个测试集上进行模型的测试。
2.2 客观评测指标
歌声和伴奏的分离通常在盲源分离评测指标[5]中进行评估,评测的3 个指标分别是源失真比(Signal Distortion Ratio,SDR)、源干扰比(Signal to Interference Ratio,SIR)以及源伪像比(Signal to Artifact Ratio,SAR)。源失真比表示总体的分离效果,也是最为重要的分离指标,源干扰比表示分离模型对干扰信号的抑制程度,源伪像比表示分离算法抑制引入噪声的能力。SDR,SIR,SAR 的单位都是dB,都是分数越大代表分离效果越好。SDR,SIR,SAR 的计算方式如式(4)、式(5)和式(6)所示。
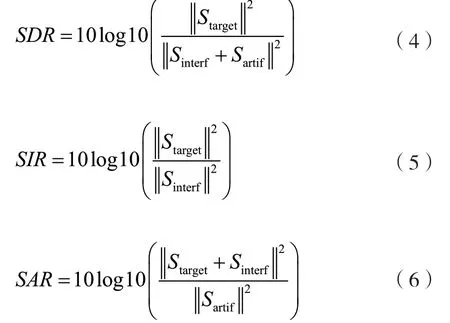
式中:Starget表示混合信号中的目标信号,Sinterf表示混合信号中的干扰信号,Sartif表示混合信号中除去目标信号和干扰信号剩下的部分,是分离算法所引入的噪声。
不同的音乐信号有不同的源失真比,为了更公平地比较分离性能,使用归一化源失真比(Normalization Signal Distortion Ratio,NSDR)。NSDR 表示预测信号相对于原始混合信号在SDR上的提升,如公式(7)所示。
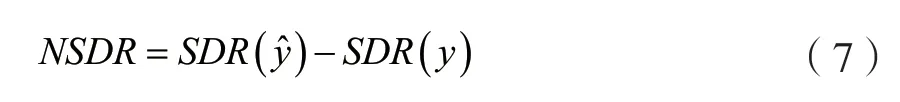
为了评测分离算法在整个数据集的分离性能,引入全局N 归一化源失真比(Global Normalization Signal Distortion Ratio,GNSDR)、全局源伪像比(Global Signal to Artifact Ratio,GSAR)以 及 全局 源 干 扰 比(Global Signal to Interference Ratio,GSIR),分别如式(8)、式(9)、式(10)所示。

式中:m表示歌曲的数量,wm表示每首音乐歌曲的长度。
2.3 实验结果及分析
分离模型的客观评测结果如表1 所示。相比于基线模型,改进模型的歌声和伴奏分离结果在GNSDR 上分别提升了4.344%和9.984%,改进后的模型可以更好地还原目标声源的频谱结构。图7为使用基线模型分离的歌声,基线模型的开头和中间出现伪影。图8 为使用跳跃连接注意力模型分离的频谱图,由图可知,改进的模型可以更好地恢复目标源频谱结构。

图7 基线模型分离出的歌声频谱图

图8 改进模型分离出的歌声频谱图

表1 分离模型客观评测结果
3 结语
为了解决卷积编解码瓶颈层丢失信息的问题,本文在分离模型的跳跃连接中加入注意力机制。注意力使编码器和解码器信息相互交流,从而指导解码器恢复目标源信息,保留影响预测的信息,解决瓶颈层信息丢失问题,从而提升了分离性能。
