基于改进MobileNetV2网络的涂层表面缺陷识别方法
2022-04-26陈宗阳赵辉吕永胜沙建军沙香港
陈宗阳, 赵辉, 吕永胜, 沙建军, 沙香港
(1.哈尔滨工程大学 信息与通信工程学院,黑龙江 哈尔滨 150001; 2.哈尔滨工程大学 智能科学与工程学院,黑龙江 哈尔滨 150001)
涂层是用物理、化学或者其他方法,在金属或非金属基底表面形成的具有一定的强化、防护或特殊功能的覆盖层。具有热障、防腐、吸波及生化防护等特种功能的涂层在现代机械设备上得到了广泛的使用[1]。然而在实际喷涂和使用过程中,涂层极易出现各类缺陷,如流挂、橘皮、露底、龟裂等,进而降低涂层整体的防护性能、缩短使用寿命。因此,对涂层表面缺陷的快速精准识别,对保证涂层质量和生产速度具有重要意义。在实际的缺陷检测识别过程中,依据人眼进行识别的方式具有较高的准确率,但存在着主观性强、速度慢、劳动强度大等问题,难以保证生产效率。传统的机器视觉技术多以手工提取特征的图像处理方法为主,并结合机器学习方法进行分类识别,其在缺陷检测领域的应用已十分广泛。Samarawickrama等[2]设计了一种基于图像处理的瓷砖自动检测系统,实现对瓷砖表面颜色变化和缺陷的检测。Aghdam等[3]提出了一种基于局部二值算子提取特征的决策树分类方法,用于钢材表面缺陷检测。基于手工提取特征的图像处理方法有效避免了人工检测中的各类缺点,提升了缺陷检测的自动化水平,但当缺陷种类多样复杂时,传统方法难以对缺陷特征进行完整的建模和迁移,复用性低,对工况要求较高。
作为机器学习领域中的研究热点,深度学习在特征提取、目标检测与识别等方面取得了非常好的效果,在缺陷检测领域也显现出巨大的潜力。Lian等[4]设计了一种木制品表面微小缺陷检测网络,Tao等[5]提出了一种弹簧线插座缺陷识别网络,Liu等[6]设计了一种焊接缺陷分类网络,Liu等[7]提出了一种输电线缺陷检测网络。因缺陷种类的多样性和成因的复杂性,可直接使用的缺陷数据相对较少,且随机初始化训练的网络具有一定的不稳定性,因此研究人员往往会使用迁移学习[8]来对网络进行训练,以获取更好的分类检测效果。Ferguson等[9]利用迁移学习提出了一种基于掩模区域卷积神经网络的铸造缺陷识别系统。Gong等[10]提出了一种深度迁移学习模型,对X图像特征较少的航空复合材料缺陷实现了准确的检测。Pan等[11]通过迁移学习训练有效地加快了网络收敛速度,提高了分类网络对焊接缺陷的泛化能力。
本文将深度学习技术应用于涂层表面缺陷识别中。考虑到工业检测过程对准确率和速度的要求,选取识别速度较快并可在嵌入式设备上进行部署的MobileNetV2网络。在网络的顶部重新设计了分类器以增强缺陷特征识别能力,在网络的骨干中加入了跨局部结构,用于增加网络中的基础特征并丰富特征的尺度信息。在网络训练上,将交叉验证和迁移学习相结合,以提升网络对缺陷识别任务的适应能力并显著加快训练速度。
1 MobileNetV2网络改进
1.1 MobileNetV2网络介绍
MobileNetV2网络[12]结构如表1所示,其中Conv2d为2维卷积操作,Bottleneck为反向残差块组成的瓶颈块,Avgpool为全局池化操作,t为通道扩展因子、c为输出通道数、n为块重复次数、s为步长。
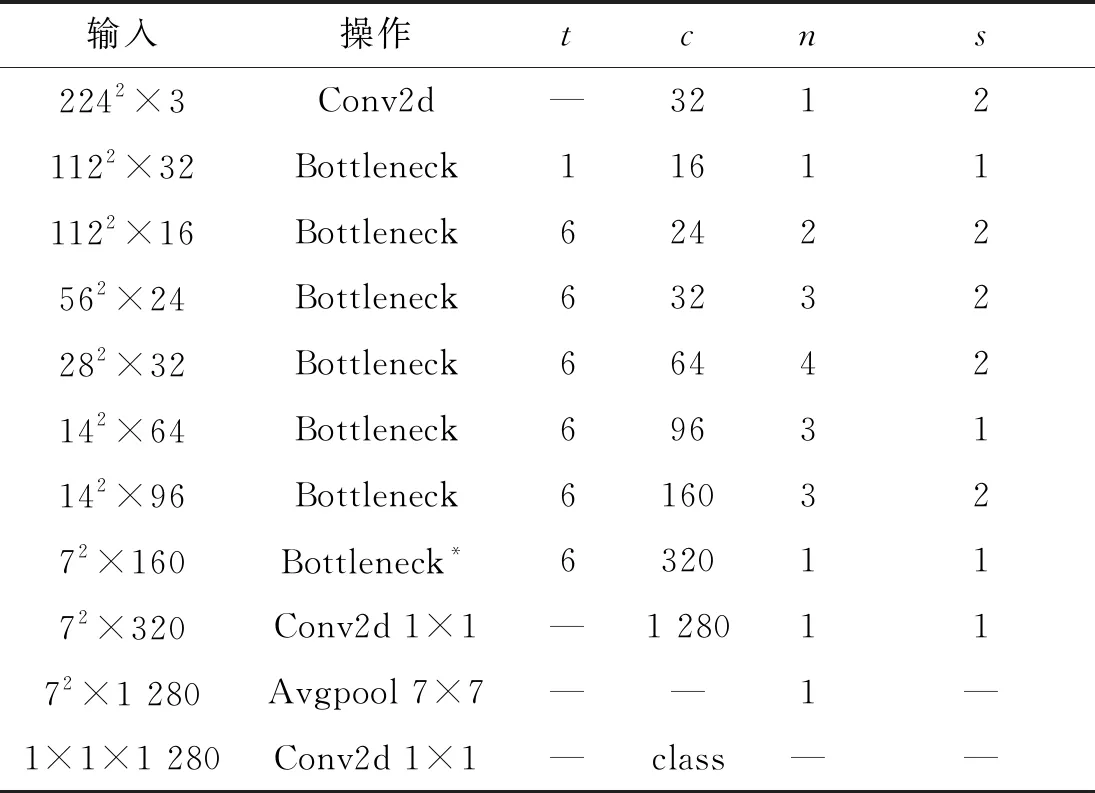
表1 MobileNetV2网络结构
除去顶部和底部少量的卷积和全局池化操作,MobileNetV2网络通过大量反向残差块结构对输入图像进行特征提取,其延续了MobileNetV1网络[13]中利用深度可分离卷积加速网络运行速度的思想并做出2点改进,即反向残差块和线性瓶颈。反向残差块由原始的先做深度卷积、后做点卷积转变为先做点卷积、后做深度卷积、最后再做一次点卷积的运算方式。如此转变使网络能够更好的提取有用信息且不会增加过多的运算量。此外,在深度卷积步长为1的反向残差块中输入和输出的维度相同,此时输出为最后一次点卷积结果和输入的求和。反向残差块的结构如图1所示。

图1 反向残差块的结构
线性瓶颈在反向残差块最后一次点卷积中,使用线性卷积替代原始卷积与ReLU函数的组合,该方式更有助于信息的保留,此外,先前的2次卷积操作(点卷积和深度卷积)也将激活函数调整为了ReLU6。
1.2 改进网络设计
为增强网络对涂层缺陷识别任务的适应性、充分提取缺陷特征,本文设计了递进式分类器和跨局部连接的网络骨干以提升网络对涂层缺陷的识别能力。
1)改进网络分类器。
MobileNetV2网络利用网络骨干快速提取目标特征,并利用顶部分类器对最后一个瓶颈层(表1中Bottleneck*)的输出进行分类识别。在具体的使用中,对于不同的分类任务通过修改分类器最后一层神经元的个数便可对特定数量的目标进行分类识别,这是较为简单直接的使用方法。但不同任务中目标的数量势必存在差异,仅调整最后一层神经元数量使之与当前任务匹配难以高效的发挥神经网络的特征识别能力,如原始的MobileNetV2网络主要是为了应对ImageNet数据集[14]上的1 000多类目标而本文仅针对5类涂层目标。因此,为更好的利用网络骨干提取的涂层特征、提升网络对涂层缺陷的识别能力,本文重新设计了网络的分类器,共包含2个卷积层、1个全局池化层和1个输出层(卷积层),具体参数如表2所示。

表2 改进后分类器的参数
分类器的主要任务是将骨干提取的缺陷特征高效的转换为具体的分类结果,考虑到本文的分类目标数量与骨干输出的特征图维度差距较大,因此选取了2种不同尺度的卷积核替代原始分类器中的单个卷积核来进行特征图的压缩转换操作。其中第1个卷积核的大小为1×1,主要负责特征图的通道数压缩,为避免较大压缩率造成有用特征的大量丢失,保留了原有通道数的3/5,即192层。第2个卷积主要用于特征图的尺寸压缩,以避免后续的全局池化在较大特征图上进行时出现波动,同时为使特征图通道数进一步向本文缺陷种类数量过渡,将通道数压缩至上一层的1/3,即64层。最后2步得到最终分类结果,其中,全局池化操作提取每张特征图上最为明显的特征点,最后一层输出识别结果。
2)改进网络骨干。
在神经网络中,底层的网络结构中多提取的是较为通用的基础特征,如亮度、边缘、颜色等,Bottleneck中虽存在残差结构但整个网络骨干全部使用Bottleneck依旧会使得其深度过深以至于网络中保留的基础特征较少,进而对小目标或特征较为单一的目标的识别效果造成影响。因此,为更好的提取涂层的基础特征,增强网络对各类涂层缺陷的识别能力,本文设计了跨局部连接的网络骨干。该网络骨干对原始骨干中的第4和第6个Bottleneck进行了修改,其中第4个Bottleneck被替换为了卷积和池化操作,第6个Bottleneck处额外添加了一个跨局部连接结构,具体的网络结构如图2所示。在图2中第1个Bottleneck上×3表示共有3次Bottleneck操作,在每一个具体操作下面的数据是其输出特征图的尺寸,Conv2d框内的a×a表示卷积核的大小。
在前3个Bottleneck之后,为扩大网络的感受野、丰富基础特征的种类和数量,利用卷积和池化2条支路分别提取前层的基础特征,并将2者所提特征进行合并,然后传递给第4个Bottleneck。将第5个Bottleneck的输出通道数由160降低至128,并将其输入特征经过单个卷积计算后与输出进行合并,形成局部连接结构,使最后一个Bottleneck中输入的特征具有不同的尺度信息,以进一步增强网络对不同尺寸的目标的识别能力,具体如图2所示。

图2 改进的MobileNetv2网络结构
1.3 交叉迁移训练
在复杂任务中深度神经网络的优异表现需要大样本数据和高算力作为支撑,但工业应用中更多的是诸如本文涂层缺陷检测一类的小众检测识别任务,样本数据通常不够丰富,且具体网络模型训练过程中设备算力资源和训练耗时是实际应用时需要考虑的问题。因此,除了对网络自身结构的优化调整,合理高效的训练方法对于实际应用同样显得重要。
传统的训练方法多从随机分配的初始权重出发,这种训练方式不需要太多的先验知识,在数据量足够的情况下便可取得良好的训练结果。当数据量有限,同时想要进一步提升网络性能时,采用迁移学习训练是一种十分有效的方法[15],可以使网络继承原有的先验知识从而达到加快网络训练速度、提升网络性能的效果。然而,迁移学习方法也存在一个较为严苛的限定条件,即用于迁移的先验知识需和当前的学习任务具有一定的相似性,越相似则性能越好,反之则起不到提升效果甚至会有负面效果。
另一种常用于应对小样本的网络训练方法是交叉验证训练[16-17],能够使得网络从数据中充分学习目标特征,有效避免训练过程中发生过拟合、欠拟合等问题,同时还有助于提升网络泛化性能。但其缺点在于内存消耗过大,且需要花费大量时间,此外,由于每一次验证的测试集(或验证集)中数据太少,故很难得到准确的识别效果。
由上述可知,迁移学习和交叉验证2种训练方式各有优缺,为充分发挥二者自身的优点以实现一种训练速度快、性能提升好、数据量要求低的网络训练方法,本文将二者进行结合组成交叉迁移训练,具体的训练过程和识别过程如图3所示。
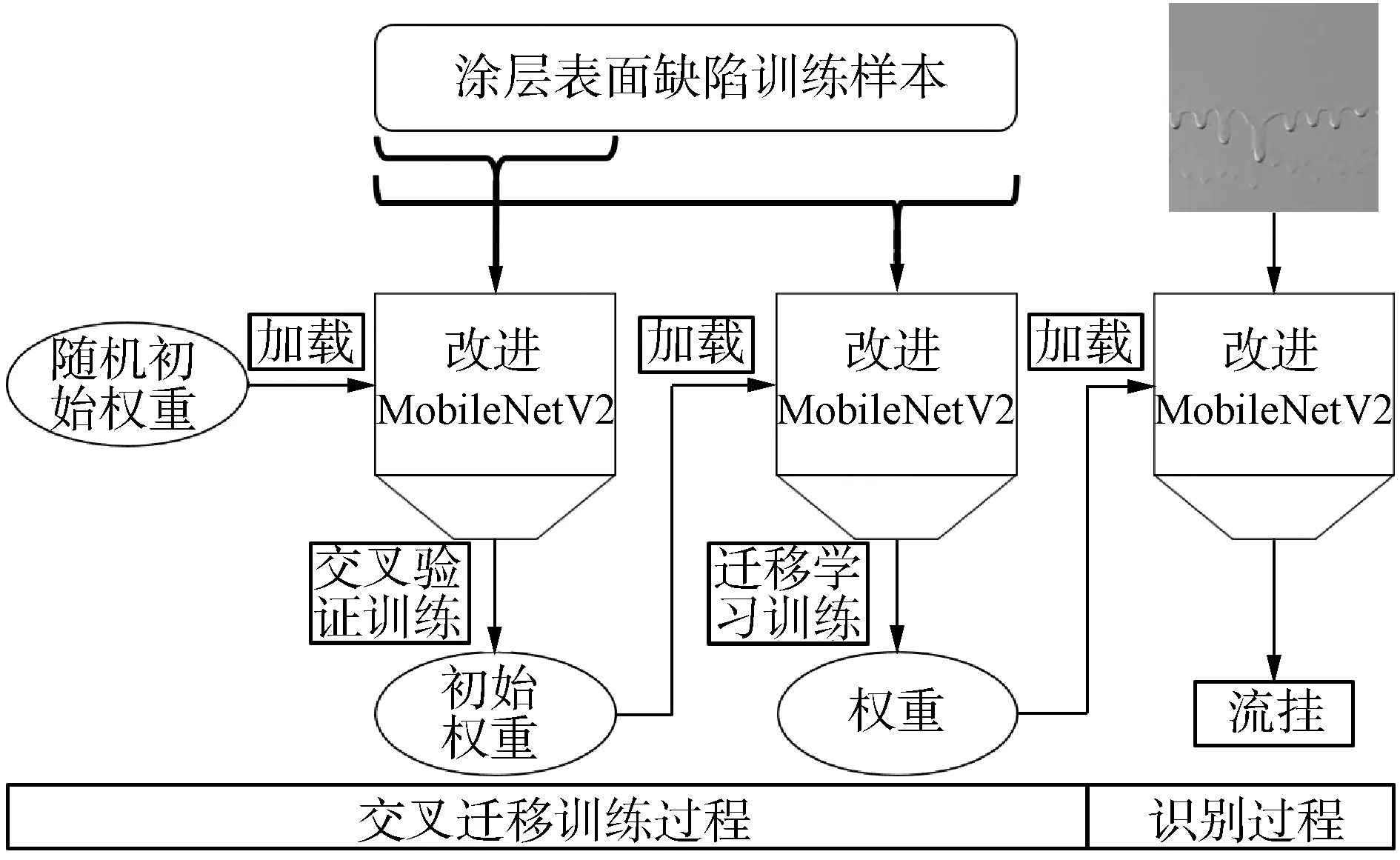
图3 交叉迁移训练过程和缺陷识别过程
从图3中可以看到,网络的训练共分为2个阶段,第1阶段仅在部分缺陷训练样本上进行有限的交叉验证训练,一方面避免了交叉验证训练方法对内存和时间的较大开销,另一方面也充分挖掘有用特征使网络损失快速下降,为迁移学习提供相对理想的初始状态;第2阶段利用全部样本通过迁移学习训练,有助于网络损失处于下降速率更快的损失曲面,更加接近全局极值点,使网络可以更好的适应当前的缺陷识别任务。除此之外,由于第1阶段仅在少量样本上进行训练,因此进行同样的训练步数,本文的训练方法将会有更短的耗时。
2 缺陷识别实验设计与分析
本文实验平台主要配置为:Intel Core i7-10875H CPU,16GB RAM,Nvidia GeForce RTX 2060 6G GPU,Win10 专业版操作系统,Python 3.6.12语言,CUDA 10.1并行计算架构,cuDNN 7.6.5深度神经网络加速库,Tensorflow2.0深度学习框架。
2.1 涂层表面缺陷数据集
由于基于计算机视觉的涂层表面缺陷检测研究较少,可以直接使用的涂层表面缺陷数据有限,因此本文构建了一个涂层表面缺陷数据集,所有图像均来源于实际生产和使用过程中存在问题的涂层缺陷板件。
图像采集参照实际的检测场景,将涂层缺陷板件水平或竖直放置,并在其垂直方向上架设电荷耦合器件工业相机(DALSA M2020,320万像素工业黑白相机)和光源,通过调整成像环境(如光源的亮度、入射角度,成像距离等)采集得到不同成像条件下的涂层缺陷图像。
本文共对105块涂层缺陷板件进行图像采集,各涂层缺陷板上至少存在一处或多处缺陷,将采集图像中的正常涂层区域和缺陷区域进行裁剪,并标记缺陷类型,构建初步数据集。值得注意的是:在数据集中添加正常涂层样本是为了将其用作“负”样本,以此来提升模型对缺陷样本的识别精度,并在一定程度上提升模型的鲁棒性;利用信噪比高的工业黑白相机可以更好的获取涂层表面缺陷特征,如视觉上呈现的点、线、纹理、形状等形式,而颜色信息对于缺陷识别并未起到直接作用,因此直接采集灰度图像,一方面降低了数据容量,另一方面也避免了颜色信息对缺陷识别的干扰。
在初步数据集制作完成后,将数据集中所有数据经由专业的涂料施工人员进行判定和筛选,剔除其中存在问题和争议的数据,利用剩余的完好数据构建涂层表面缺陷数据集。整个数据集共包含4 000张图像,涉及5类涂层目标,1类正常涂层目标和4类涂层缺陷目标,其中4类涂层缺陷分别为橘皮、露底、龟裂、流挂,每类目标800张,按照5∶2∶1的比例进行训练集(2 500张)、测试集(1 000张)、验证集(500张)数据划分,5类涂层目标的部分图像如图4所示。

图4 5类涂层目标图像
2.2 实验设置
本文采用准确率和精确度作为网络性能评判的依据,对比分析不同分类网络在进行涂层表面缺陷识别过程中的效果优劣以此评判本文方法的有效性,准确率和精确度分别为:
(1)
(2)
式中:TP(真阳性)为正样本被分类为正的样本数;TN(真阴性)为负样本被为分类为负的样本数;FP(假阳性)为负样本被分类为正的样本数;FN(假阴性)为正样本被分类为负的样本数。
实验所有分类网络每次均在训练集上训练350个周期,且均为随机初始权重。交叉迁移训练方式第1阶段交叉验证训练时采用5折交叉验证训练方式[18],每一折训练30个周期,共计150个周期,第2阶段迁移学习训练200个周期。所有训练优化器均为Adam[19],交叉验证训练时学习率为0.001,其他情况下学习率均为0.000 1。交叉验证时使用750图像进行训练,均是从训练集样本中随机抽取得到,且每类样本150张。在所有训练过程中batch_size均为32,网络输入图像尺寸皆为224×224,实验结果均为5次独立实验取平均。
2.3 实验结果与分析
2.3.1 本文方法实验结果与分析
表3中给出了本文不同方法对涂层缺陷的识别效果以及训练时间,其中交叉迁移训练的时间同时包含了150个周期的交叉验证训练耗时(使用本文分类器时耗时9′29″,使用本文分类器和骨干时耗时8′48″)和200个周期的迁移学习训练耗时。具体方法为:
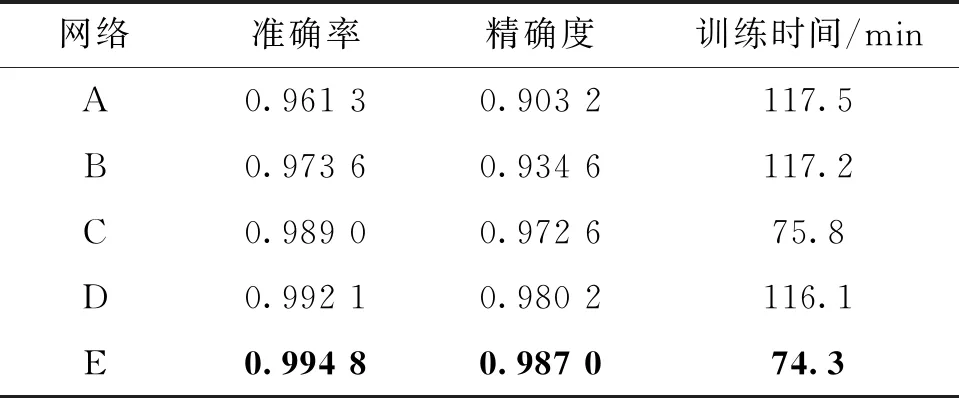
表3 不同方法的识别效果和训练时间
A:原始MobileNetV2网络;
B:使用本文分类器的MobileNetV2网络;
C:使用本文分类器并交叉迁移训练的MobileNetV2网络;
D:使用本文分类器和骨干的MobileNetV2网络;
E:使用本文分类器和骨干并交叉迁移训练的MobileNetV2网络;
A→B:在使用本文的分类器后,MobileNetv2网络对涂层缺陷的识别准确率提升了1.23%、精确度提升了3.14%、训练时间有较小的缩减,由此说明新的分类器能够更好的利用网络骨干提取的缺陷特征,可以更加高效的识别涂层表面缺陷。
B→C:使用本文分类器的MobileNetV2网络进行交叉迁移训练后,识别准确率和精确度分别进一步提升了1.54%、3.80%,同时网络的训练时间缩短了35.32%。由此可知,本文的训练方法在大幅度减少网络训练耗时的同时,较好的保留了交叉验证和迁移学习2种训练方法自身的优点,使得网络对涂层缺陷的识别精度得到进一步的提升。
B→D:在同时使用本文提出的分类器和骨干后,改进网络较B相比准确率和精确度分别进一步提升了1.85%、4.56%。与原始网络相比,准确率提升了3.08%,精确度提升7.70%,同时训练时间也有小幅度的缩减。由此可知,新的网络骨干可以增加网络中的基础特征,提升特征的尺度信息,促进网络对不同尺度下的涂层缺陷的识别效果。
D→E:在进行交叉迁移训练后,改进网络达到了最佳识别效果,而且网络的训练时间得到较大幅度缩减,最终使用本文方法的MobilenetV2网络较原始网络相比准确率提升3.35%、精确度提升8.38%、训练时间减少36.77%。
表4给出了不同网络的参数量、模型大小(网络结构和参数)以及识别耗时,其中识别耗时仅统计全部测试集数据(1 000张图像)在网络中的推理耗时不包括图像的预处理等操作,所有分类网络在进行识别时batch_size均为1,由于交叉迁移训练并不会影响网络的上述属性,因此仅给出了A、B、D 3类网络的结果,C、E的结果与B、D相同。
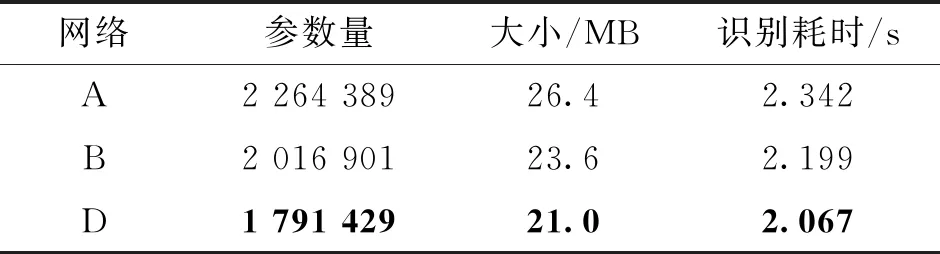
表4 不同网络的参数量、模型大小以及识别耗时
从表4中可以看到,新的网络分类器和骨干均能起到压缩网络大小、提升运行速度的效果,在使用新的分类器后网络的参数量降低10.93%、模型大小降低10.61%、识别速度提升6.11%;当同时使用本文提出的分类器和骨干后网络的参数量降低20.89%、模型大小降低20.45%、识别速度提升11.74%。
图5是利用交叉迁移训练得到的改进网络E在部分测试集数据上的识别结果,可以看出改进网络对5类涂层目标具有较高的识别精度。
综上可知,改进后的MobileNetV2网络能够提取不同尺度下的涂层缺陷特征,且对特征的利用率更高、识别效果更好;交叉迁移训练方法能够在保证网络精度提升的同时,大幅度减少算法训练耗时,在实际应用过程中具有较大价值。
2.3.2 本文方法与其他方法对比实验
为进一步验证本文方法的有效性,分别选取了Xception[20]、Resnet-50[21]、DenseNet-121[22]3种典型的分类网络与本文方法进行对比,其中Xception网络充分发挥了Inception模块提取目标多尺度特征的优点,Resnet-50中的残差单元可以有效解决深层网络梯度消失或者爆炸的问题,DenseNet-121提升了神经网络对特征的传播效率和利用效率,以上3种网络在图像识别领域均具有出色的性能表现,且多数改进算法也以此为基础,因此与上述方法进行对比可以较好地反应本文方法的缺陷识别能力。本文方法与上述方法在进行涂层表面缺陷识别时的性能表现如表5所示。

表5 不同方法的性能表现
从表5可以看到,本文方法在涂层表面缺陷识别的准确率和精确度上明显优于DenseNet-121和Resnet-50,与Xception相比准确率仅低了0.29%、精确度仅低0.72%。而在网络的训练时间上,本文方法的训练耗时仅为Xception的28.90%,与DenseNet-121和Resnet-50相比也减少了一半以上。在网络参数量和模型大小方面,本文方法也具有明显优势,与Xception、DenseNet-121、Resnet-50 3种分类网络相比本文方法的参数量分别为其各自的8.58%、25.44%、7.59%,在模型大小方面也得到了相应的优势体现。在识别速度方面,本文方法比Xception、DenseNet-121以及Resnet-50均快3倍以上。
综上可知,与所用3种典型网络相比,本文方法仅在识别精度上略低于Xception,但在训练时间、参数量、模型大小以及识别速度上均具有较大的优势。其中,Xception的准确率仅高出0.29%,但其速度不及本文方法的1/3,且参数量也是本文方法的十倍以上。由此可见,在综合考虑识别速度和精度的情况下,本文方法具有最佳表现,同时较短的训练耗时也使得本文方法更加符合实际的工业应用需求。
3 结论
1)本文提出的改进MobileNetV2网络,对其训练方法进行优化了调整,实现了对涂层表面缺陷的快速精准识别。递进式分类器能够充分学习缺陷特征并转换为低维分类结果,在提升识别精度的同时加快了识别速度。
2)跨局部连接网络骨干可以丰富网络中基础特征并增加特征的尺度信息,在提升特征提取速度的同时增强了网络的特征学习能力。
3)交叉迁移训练能使网络具有较好的初始性能和更快的性能提升速率,可有效解决小众分类任务中理想预训练权重难以获取的问题,能够在数据有限的情况下训练得到检测识别效果更好的神经网络模型并且大幅度缩减训练时间。
4)本文提出的改进网络在参数量远小于Xception、Resnet-50和DenseNet-121的情况下具有更强的特征利用和识别能力,在缺陷识别准确率和速度方面的良好表现,更加符合实际的工业应用需求。
由于涂层表面缺陷种类并不止本文所讨论的5种常见类型,实际检测场景中可能会有其他因素影响缺陷特征。因此,后续可在实际应用过程中搜集扩充缺陷数据,对网络进行训练优化,以更好地满足工业生产过程中的涂层缺陷检测任务。
