融合语义信息的时空关联位置隐私保护方法
2022-04-26左开中谌章义陈付龙
左开中,刘 蕊,赵 俊,谌章义,陈付龙
(1.安徽师范大学 计算机与信息学院,安徽 芜湖 241002;2.安徽师范大学 网络与信息安全安徽省重点实验室,安徽 芜湖 241002)
21世纪之后,空间定位技术、无线网络通信技术和移动互联网络的发展速度越来越快,手机等智能设备的计算能力、存储能力、通信能力也有了显著的提高,手机用户的数量也处于不断上升的趋势。中国互联网络信息中心在2021年2月发布的《中国互联网络发展状况统计报告》[1]表明:截至2020年12月,我国上网人数高达9.89亿,约占全国总人口的70.4%。其中,使用手机上网的人数为9.86亿,占比高达99.7%。因此,基于位置的服务(Location Based Service,LBS)得到了广泛的应用。
但是,用户在享受便捷服务的同时也受到了相应的威胁[2]。2017年8月,“微信发送原图导致位置隐私泄露”的帖子迅速刷爆各大信息平台。智能数码设备和手机在拍照时会主动收集拍摄的精确位置信息是导致位置隐私泄露的根本原因。同时,拍摄日期、时间、手机型号等内容一览无遗。热心的网友经过测试还发现无论是使用微信、邮件、微博或者其他的信息传输工具都存在位置隐私泄露的问题。这对于喜爱游山玩水又乐于向朋友时刻分享动态的人来说,无疑是一颗重磅炸弹。
为了使用户可以安全地使用基于位置的服务避免位置隐私泄露,国内外学者针对自由空间、路网空间等环境提出了匿名、假位置、混合区域以及加密等多种技术手段[3]。其中,基于假位置的隐私保护技术是常用位置隐私保护手段之一[4-8]。它是指通过构建假位置替代用户真实位置发出服务查询请求或者构建多个假位置和用户真实位置构成匿名集发出查询请求,以达到保护用户实际位置的效果。从假位置方法的原理和实现两个层面来讲,它都属于易理解、操作性强的隐私保护方法。而假轨迹方法是在假位置方法的基础上形成假轨迹来降低攻击者识别真实轨迹的概率。但是,在连续请求服务中,传统的假轨迹隐私保护方法往往生成多条假轨迹混淆用户真实轨迹,但是假轨迹中语义位置的移动不符合用户行为规律,增加了真实轨迹暴露的概率。
如图1所示,假设某公司职员Bob于17:30从A公司出发与朋友在L影院有约,然后途径B超市购物后回到家庭住址C小区。因此Bob有一条从A公司→L影院→B超市→C小区的移动轨迹,通过假轨迹方法构建了一条从G银行→F餐馆→H医院→M学校的移动轨迹。但是M学校开门时间为8:00—16:30,且攻击者挖掘用户Bob的轨迹信息得知该用户从H医院移动到M学校的概率为0,从而推测出从G银行→F餐馆→H医院→M学校的移动轨迹为一条假轨迹,导致用户Bob的真实轨迹很容易被攻击者识破。

图1 用户真实轨迹和假轨迹
针对上述问题,笔者提出融合语义信息的时空关联位置隐私保护方法。首先,将用户历史移动数据规律与用户当前位置语义信息相结合构建用户行为模型;然后,根据该模型构建假轨迹并充分考虑相邻时刻位置间的时空关联性。笔者的贡献在于:
(1) 综合考虑了时空关联性、位置语义信息和用户的行为规律,提出了时空关联匿名集生成算法;
(2) 基于真实的数据集,将笔者提出的算法与现有的算法进行比较,表明笔者提出的算法有效地降低了隐私泄露的风险。
1 相关工作
考虑攻击者挖掘用户的历史请求信息,NIU等[5]提出了最大化熵和匿名区域的多目标优化算法,使得假位置尽可能地分散来保护用户位置隐私。夏兴有等[9]设计了一种基于半可信第三方服务器的隐私保护体系结构,利用历史查询概率选择假位置,同时采用博弈模型对生成的假位置候选集进行博弈,从而得到最优匿名集。
针对攻击者掌握位置的语义特征信息,CHEN等[10]通过构建位置语义树使用树节点之间的跳数来量化语义间的距离,同时考虑了位置的语义多样性和物理分散性。MA等[11]挖掘语义信息并引入距离公式计算语义相似度,利用可调整余弦相似度计算用户间相似性使得攻击者无法识别出真实用户的同时有效地抵御语义推断攻击。LI等[12]为解决语义同质攻击问题提出一种语义感知模型,并设计了一种在服务质量和隐私要求之间取得平衡的贪婪算法。
在此基础上,王洁等[13]综合考虑上述问题,提出了基于位置语义信息和查询概率的假位置选择算法,避免了攻击者结合背景知识过滤假位置,同时保证了假位置之间语义差异性和查询结果的精确性。
在连续请求服务的场景下,李洪涛等[2]基于路网拓扑关系对路段的敏感程度进行等级划分,提出了差分隐私位置保护机制实现了对用户位置隐私的保护。周长利等[14]针对连续查询过程中面临用户位置隐私和查询内容隐私的双重问题,设计了以道路顶点为中心的兴趣点结构,降低查询次数,提高查询准确率。郑磊等[15]通过马尔科夫模型对用户位置进行预测,提出了一种基于缓存的位置匿名选择算法来构建匿名区域,从而抵御利用背景信息造成的推断攻击。
针对攻击者掌握的位置可达性背景知识,TAKBIRI等[16]针对用户个性化的隐私需求,通过跟踪分析用户真实位置的时间相关性,提出与之匹配的用户匿名和数据模糊尺度。李维皓等[17]考虑到空间和时间之间的关联性,选取与伪位置关联的伪查询内容,提出了基于伪位置生成的时空关联隐私保护方案,在保护用户的位置隐私的同时能够更好地保护查询隐私。WANG等[18]基于用户隐私要求和实时位置信息,采用贪婪策略生成安全的匿名区域,然后计算不同时间匿名用户集的交集,利用动态假名机制更新用户身份信息。
另外,刘海等[19-20]考虑到连续查询请求中相邻位置集的时空关联性,设计了连续合理性检查算法筛选假位置,然后从单点的隐私保护程度进行二次筛选,以确保假轨迹的真实性。周佳琪等[21]针对攻击者掌握的时空可达、位置语义特征、用户历史请求特征等背景知识提出了一种基于时空关联和位置语义的三重假位置筛选方案——位置是否可达、语义是否相近、与用户历史请求特征是否接近,从而降低假位置被识别的概率,提升隐私保护程度。但是上述方法中假位置构成的假轨迹不符合用户行为规律,增加真实轨迹暴露的概率。
综合考虑时空关联性、位置语义信息和用户行为规律,笔者提出了时空关联匿名集生成算法,可有效地降低攻击者在拥有用户行为规律等背景知识情况下用户真实轨迹被识别的风险。
2 预备知识
首先介绍了相关定义和系统架构,然后根据用户历史轨迹和地图数据介绍如何构建用户行为模型,最后对时空关联性进行描述。
2.1 相关定义
定义1(查询请求) 查询请求是指用户向位置服务器发送的消息内容。表示为{id,(x,y),t,cont},其中,id为用户身份唯一标识,(x,y)为用户位置信息,t为用户查询时间,cont为查询内容。
定义2(隐私要求) 用户个性化的隐私需求,表示为req(K,L),其中,K和L分别是用户可接受的移动用户和路段的最小值。
定义3(匿名集) 匿名集是指满足用户隐私需求的基本前提下可隐蔽用户真实位置的集合,表示为AS。
定义4(语义轨迹) 语义轨迹是指用户在连续查询时间段内曾到达的语义位置所组成的路径。换句话说,语义轨迹实际上是一个按照时空序列连续采样的语义位置的集合,表示为
T={(x0,y0,t0),(x1,y1,t1),…,(xn,yn,tn)} ,
其中,T[i]表示用户在ti时刻所处语义位置的坐标,i∈(0,1,…,n)且t0 定义5(用户行为模型) 用户行为模型是指中心匿名服务器根据用户历史语义轨迹统计用户在语义位置之间的转移概率所创建的矩阵。表示为 其中,mij表示由第i个语义位置转移到第j个语义位置的概率(1≤i≤n)。 图2 系统架构 如图2所示,采用由可信的中心匿名服务器来连接移动终端和基于位置的服务器的中心匿名服务器架构。中心匿名服务器结构由移动终端、中心匿名服务器和基于位置的服务器组成[22]。它是移动终端和基于位置的服务器之间传递消息的加工者。正是由于中心匿名服务器的可信性,用户不用担心其位置资料的泄露。其主要工作流程如下: 步骤1 中心匿名服务器初始化路网数据库、语义位置数据库、用户历史语义轨迹数据库,统计用户在语义位置之间的转移次数以构建用户出行模型; 步骤2 移动终端将用户隐私需求和查询请求发送至中心匿名服务器,其根据用户隐私需求、时空关联匿名集生成算法生成假轨迹点构建匿名集,并判断相邻时刻匿名集是否满足时空关联性;若满足,则直接将匿名请求发送给基于位置的服务器;若不满足,则计算延迟发送时刻,将匿名请求延迟发送给基于位置的服务器; 步骤3 基于位置的服务器对匿名请求进行查询操作,然后将候选结果集全部返回给中心匿名服务器; 步骤4 中心匿名服务器利用查询结果求精处理器对候选结果集进行处理,得到精确结果后发送至移动终端。 充分考虑用户历史语义轨迹中包含的用户行为规律信息,构建用户行为模型。使用中心匿名服务器统计用户历史移动数据构建融合语义信息的用户出行模型,即中心匿名服务器分析用户从一个语义位置转移到另外一个语义位置的频率。使用一个矩阵N来记录用户从一个语义位置loci到另一语义位置locj的次数Qij,则Qij=N[i][j]。 表1是用户出行统计表。表格的第1列代表出发地,第1行代表目的地。例如,用户从商场出发的轨迹条数为200条,其中到达商场10次,学校40次,住宅20次,公园30次,医院60次,公司40次。 表1 用户出行统计表 次 根据这些数据创建语义位置转移矩阵N,表示为 P(i|j)=Qij/∑Qij,表示用户从语义位置loci到达语义位置locj的概率。例如用户从商场到达学校的转移概率为P(商场|学校)=40/200=0.2。因此,基于语义位置转移矩阵N,可以分析出用户出行概率矩阵M,表示为 连续查询场景下,用户相邻时刻的查询请求具有时空关联性,即用户需在请求时间内到达下一位置点。 图3为描述时空关联性的实例。ASi-1={A,B,C,D},为用户A在ti-1时刻提交的匿名集,而用户在ti时刻提交的匿名集为ASi={A′,B′,C′,D′}。其中A→A′为用户真实移动轨迹。攻击者根据用户进行查询请求的时间间隔Δt=ti-ti-1和用户最大移动速度推测出轨迹D→D′为虚假移动轨迹,因此用户真实位置和真实轨迹被推测出的概率明显增加。 图3 时空关联性的实例图 Max(Dis(ASi-1,ASi))/vmin≤Δt, (1) 其中,Max(Dis(ASi-1,ASi))表示某条移动轨迹的最大移动距离,vmin为用户最小移动速度,Δt为查询时间间隔即Δt=ti-ti-1。 如果不满足式(1)的要求则延迟发送查询请求,延迟发送的的时间为 ti=Max(Dis(ASi,ASi-1))/vmin+ti-1。 (2) 详细介绍融合语义信息的时空关联位置隐私保护算法(Spatiotemporal Correlation Location Privacy Protection algorithm with semantic information,SCLPP),即时空关联匿名集生成算法和连续时刻匿名集生成算法。 算法1为时空关联匿名集生成算法,主要解决如何根据用户查询状态构建匿名集的问题。 在该算法中如果用户是首次发出连续查询请求(②),根据用户隐私偏好L找到用户所在路段的L-1条相邻路段(③~⑦),在这L条路段上找到K-1个不同的语义位置并在其附近生成假位置作为假轨迹的起点,即产生匿名位置集AS0(⑧~);否则,根据用户位置坐标、路网、用户出行模型调用算法2构建匿名位置集ASi()。 算法1时空关联匿名集生成算法。 输入:用户坐标(x,y),隐私需求req(K,L),路网G。 输出:ASi 。 ① AdjecentEdgeset=Ø;ASi=Ø;S_loc=Ø; ② ifti=t0then ③ assign the edge where userulocated toe; ④ AdjecentEdgeset=AdjecentEdgeset∪e ⑤ if |AdjecentEdgesset| ⑥ edge=FindEdge(e);//随机查找e的一条相邻路段 ⑦ AdjecentEdgeset=AdjecentEdgeset∪edge ⑧ end if ⑨ put the semantic location where user u located to AS0 ⑩ if |AS0| 算法2为连续时刻匿名集生成算法,主要解决为非首次查询用户如何构建匿名集的问题。 首先得到用户前一时刻的匿名位置集Asi-1(①),根据用户隐私偏好L找到用户所在路段的L-1条相邻路段(②),当位置匿名集中位置个数小于L时,将L条路段上的语义位置分别存放在L个集合中,同时构建一个Total_set集合存放前面所述的L个集合,即Total_set={set1,set2,…,setL}(③~⑧)。 然后,从用户出行模型中将前一时刻匿名位置集Asi-1[i]转移到Total_set集合中所有位置的转移概率放在集合Moveset中,并在转移概率最大的语义位置附近产生假位置作为当前时刻的第i个假位置,将Moveset置空,同时将该位置从所属集合seti中删除,然后将seti从Total_set集合中删除(⑨~)。但是,当位置匿名集中位置个数大于L时,将set1,set2,…,setL中剩余的位置从新组成一个集合Movenew,然后依次找出ti-1时刻剩余假位置到Movenew中转移概率最大的K-L个语义位置并在附近产生假位置(~)。 最后,利用式(1)检查相邻时刻匿名位置集是否满足利用连续查询的时空关联性(),否则,利用式(2)计算延迟发送匿名集的时间(~)。该算法的伪代码如下。 算法2连续时刻匿名位置集生成算法。 输入:用户坐标(x,y),隐私需求req(K,L),路网G,用户出行模型user_matrix 。 输出:ASi。 ① get Asi-1 ② 重复算法1的③~⑧ ③ put the semantic location where user located to ASi ④ if |ASi|<=req.Lthen ⑤ fori=1:Ldo ⑥ put the semantic location in AdjecentEdgeset[i]into seti;//将位于同一路段上的语义位置放在同一集合中 ⑦ Total_set={seti} ⑧ end for ⑨ fori=1:L-1 do ⑩ put transition proability from Asi-1[i]to Total_set use user_matrix into Moveset 从空间数据库(http://www.cs.utah.edu/~lifeifei/SpatialDataset.htm)中下载加利福尼亚州的城市道路网络和语义位置作为实验数据。使用移动对象生成器[23]模拟移动对象在加利福尼亚州的地图进行活动,共计生成100 000个移动对象,并为每个移动对象设置50个位置点作为用户历史移动数据。同时,从中随机选取20 000个用户的25个位置点模拟发出连续查询请求。 为了验证SCLPP算法的有效性,选择Enhanced-DLS算法[5]、TTcloak算法[24]为连续发送查询请求的用户生成假位置集合从而构建假轨迹。上述算法是假位置技术中比较经典的算法,考虑查询概率等辅助信息,避免用户生成如位于湖泊中心或位于十字马路中心等不合理的假位置。同时,为了验证现有面向路网环境的快照查询隐私保护算法无法直接迁移到连续查询中,选择LSBASC算法[25]进行对比。上述算法均采用JAVA语言编程,在Microsoft Windows 10 Professional的Intel(R)Core(TM)i5-9400 CPU @ 2.90 GHz和16 GB主内存的电脑上运行。 4.2.1 时空关联性分析 图4 时空关联性通过比例 连续查询场景下,用户相邻时刻的查询请求具有时空关联性。基于时空关联性对所有算法生成的假位置进行检验,统计假位置能够通过筛查的比例。由图4可知,SCLPP算法通过筛查的比例为100%,这是因为它在生成匿名集时已经充分考虑了时空关联性。而Enhanced-DLS算法、LSBASC算法、TTcloak算法未考虑时空关联性,导致产生的匿名集中通过筛选的平均比例分别为25%、28%、27%。Enhanced-DLS算法在K=4时通过筛查的比例最高为32%,但也有78%的位置点被识别出来。LSBASC算法在K=5时通过筛查的比例最高为39%,但也有61%的位置点被识别出来。TTcloak算法在K=4时通过筛查的比例最高为30%,但也有70%的位置点被识别出来。因此可以得出这样一个结论:时空关联性是极为重要的考虑条件。 4.2.2 轨迹相似度分析 轨迹相似度与轨迹暴露风险是一种相反的数量关系,即轨迹相似度越高说明轨迹暴露风险越小,反之,则轨迹相似度越低导致轨迹暴露风险越高。由图5可知,SCLPP算法的轨迹相似度最高,暴露风险最低,LSBASC次之,Enhance-DLS算法暴路风险较大,TTcloak算法暴路风险最大。与其他算法相比,SCLPP算法的轨迹暴露概率平均降低了17.6%。这是因为SCLPP匿名算法与LSBASC算法在单个时刻生成匿名集时总是优先考虑相邻路段上的语义位置点,所以轨迹相似度偏高。而Enhance-DLS算法与TTcloak算法都是通过查询概率选择位置集合,所以轨迹相似度较低。 4.2.3 系统开销分析 使用匿名位置集构成的匿名区域的平均大小来度量系统开销,平均匿名区域面积越大,查询时间消耗越大,系统开销也越大。由图6可知,SCLPP算法的系统开销最小,LSBASC次之,TTcloak算法较小,Enhance-DLS算法最大。这是因为SCLPP匿名算法与LSBASC算法在构成匿名集时通过考虑相邻路段上的语义位置点使得匿名区域面积较小。而TTcloak算法设定了匿名区域大小使得平均匿名区域面积比Enhance-DLS算法要低。 图5 轨迹相似度 图6 系统开销 攻击者挖掘背景知识(用户行为规律、移动数据等)可对用户行为轨迹中包含的语义信息进行推断攻击,导致用户习惯、宗教信仰等信息的泄露。针对该问题,笔者方案利用用户行为模型提出一种融合语义信息的时空关联位置隐私保护算法。首先根据用户隐私偏好L找到用户所在路段的L-1条相邻路段,将L条路段上的语义位置分别存放在L个集合中,同时构建一个Total_set集合存放前面所述的L个集合,即Total_set={set1,set2,…,setL}。然后,从用户出行模型中将前一时刻匿名位置集Asi-1[i]转移到Total_set集合中所有位置的转移概率放在集合Moveset中,并在转移概率最大的语义位置附近产生假位置作为当前时刻的第i个假位置,将Moveset置空,同时将该位置从所属集合seti中删除,然后将seti从Total_set集合中删除。但是,当位置匿名集中位置个数等于L时,将set1,set2,…,setL中剩余的位置重新组成一个集合Movenew,然后依次找出ti-1时刻剩余假位置到Movenew中转移概率最大的K-L个语义位置并在附近产生假位置。该算法生成的假轨迹中单个时刻位置点之间的转移概率大于真实轨迹中单个时刻位置点之间的转移概率,实现了保护真实移动轨迹的目的。因此,可抵御推断攻击。 攻击者分析相邻时刻匿名位置集能否在用户正常移动速度内达到,排除不能按时到达的假轨迹,增加真实轨迹的泄露概率。针对时空可达性攻击,笔者提出的方案计算相邻时刻匿名位置集之间所需的最大移动时间,判断是否延迟发送匿名查询请求,从而实现时空关联性。假设用户在ti-1时刻和ti时刻上传的匿名位置集分别为ASi-1和ASi,判断它们满足时空可达性条件Max(Dis(ASi-1,ASi))/vmin≤Δt,则正常发送查询请求,否则延迟发送匿名请求的时间为ti=Max(Dis(ASi,ASi-1))/vmin+ti-1。因此,可抵御时空可达性攻击。 针对连续查询中攻击者利用背景信息对用户轨迹进行攻击的问题,笔者提出了一种融合语义信息的时空关联位置隐私保护方法。该方法不仅生成假轨迹增加用户真实轨迹的保护力度,并且单个时刻的位置隐私保护也随之增加。生成的假轨迹中单个时刻位置点之间的转移概率甚至大于真实轨迹中单个时刻位置点之间的转移概率,而且判断相邻时刻匿名集之间时空可达性,若不可达则延迟发送用户匿名请求,真正的实现了保护真实移动轨迹的目的。最后通过模拟实验验证算法的有效性。2.2 系统结构

2.3 用户行为模型



2.4 时空关联性

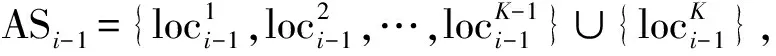
3 融合语义信息的时空关联位置隐私保护算法
4 实验及结果分析
4.1 实验设置
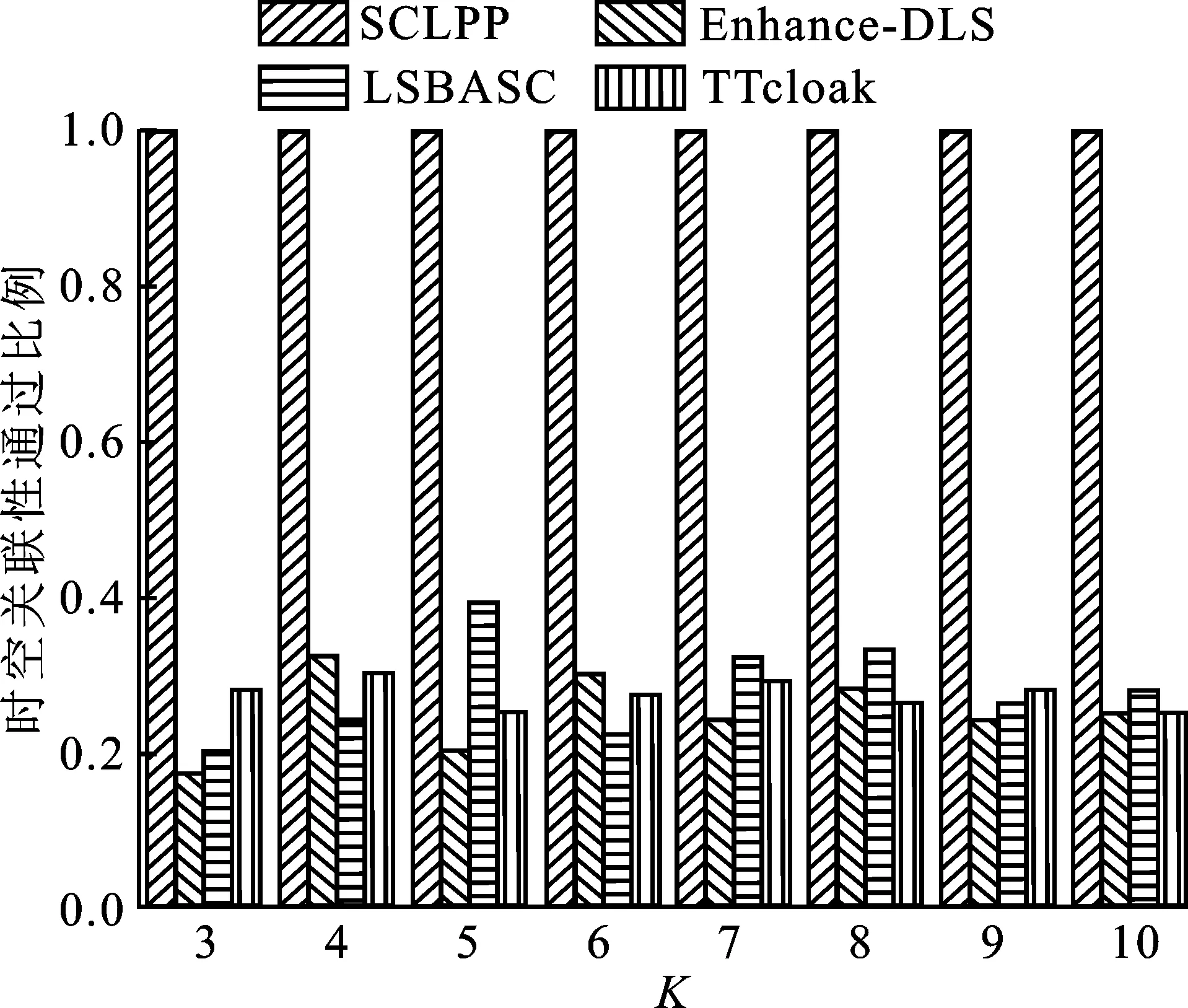
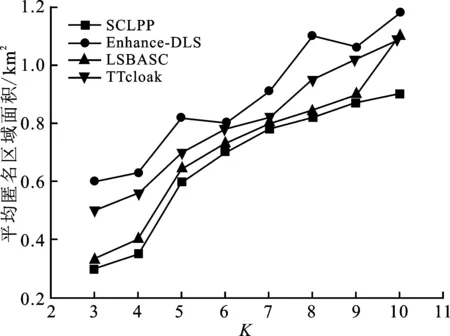
4.2 实验结果分析

5 安全性分析
6 结束语
