一种支持属性撤销的top-k多关键词密文检索方案
2022-04-26王凯文王树兰王海燕
王凯文,王树兰,王海燕,丁 勇,3
(1.深圳技术大学 大数据与互联网学院,广东 深圳 518118;2.鹏城实验室 网络空间安全部,广东 深圳 518000;3.桂林电子科技大学 计算机与信息安全学院,广西 桂林 541010)
随着计算机领域的飞速发展,数据量日益剧增,人们越来越倾向于使用第三方数据库云服务来进行存储。但在云服务的数据存储过程中,会面临数据丢失、恶意窃取数据或者篡改数据等安全隐患。因此,确保云服务中数据保密和操作安全是云安全领域中的重大挑战之一。当前,一种行之有效的方法是在上传之前对数据进行加密,把加密后的密文信息存储在服务端。而加密数据的检索成为一个迫切需要解决的问题,申请查询指定内容,会要求先解密后确定文件,导致搜索代价极大。因此,如何既能保护云端数据安全又能支持高效数据处理能力成为新的难题。
最早的可搜索加密是从单个关键字的搜索起步,文献[1]在2000年采用伪随机函数和流密码对单关键字进行对称加密,但是方案遍历时要检索全文,安全性低;而文献[2]在此基础上提出了安全性索引模型,采用Bloom Filter伪随机函数,实现高效搜索;CAO等人提出加密云数据上的多关键字排序搜索方案[3],使用了KNN算法向文档向量中添加虚拟尺寸和随机参数以保护数据隐私;MIAO等人通过利用{0,1}编码来支持可比较的属性机制,实现保护隐私的方式的关键字搜索方案[4]。但上述方案都只局限于针对文件集的加密搜索研究,没有实现对密文的细粒度访问控制和权限管理,没有考虑嵌合云服务,而且无法实现对云端数据的高效检索。
另一方面,在细粒度访问控制的可搜索加密方案中,常用的属性基加密技术[5-6]适用于基于用户属性而不是用户列表授予访问权限。因此,在对属性基加密技术的深入研究中,属性撤销机制越来越受到关注。特别是在实际应用中,多个用户可以共享属性,一旦共享的任何一个属性被撤销,必然会影响到其他拥有撤销属性的用户。在传统解决方案中,数据需要重新加密,并且用户密钥需要更新。但是,这种方法的缺点是当云端数据量规模大或者多用户授权时,需要大量的计算开销。因此,研究支持高效率、访问控制的多关键字可搜索加密方案具有较高的理论价值和实践意义。
为了解决这些问题,笔者使用属性基加密、同态加密技术和语义空间模型,提出一种支持属性撤销的top-k多关键词密文检索方案(A Top-kmulti Keyword ciphertext Retrieval Scheme supporting attribute revocation,TKRS)。主要贡献如下:① 支持多关键字高效搜索。基于属性基加密搭建属性-文件索引表,实现对密文的细粒度访问控制和权限管理,允许多关键字检索,top-k排序。② 支持属性撤销。引入同态加密模糊数据,确保数据隐私,低开销同态加操作实现撤销,满足大规模数据下多用户属性授权管理。③ 标准模型下的安全性。通过安全分析,文中方案能够实现前向和后向安全性,并且能够抗共谋攻击。
1 相关知识
1.1 CP-ABE算法
属性加密在实际中有广泛的应用场景,比如分布式文件系统的访问控制,安全在线社交网络,高效广播加密等。此外,目前大部分身份基加密的扩展均可看作属性基加密的特例,已被用来解决身份基加密中的身份撤销问题以及用来构造负责身份基加密方案。2011年,文献[7]提出了密文策略的属性基加密(Ciphertext-Policy Attribute-Based Encryption,CP-ABE)算法。在此基础上,研究者通过对访问树的优化,混合加密的操作和隐藏策略等的方式,提出了各类改进方案[8-10]。而在该方案中,用户的属性撤销和数据完整性仍有待研究。因此在改进算法过程中,切实把握算法安全性和功能性的平衡是重点。
1.2 全同态加密技术
全同态加密能够在不知道密钥的情况下对密文进行任意计算[11-13],这种特殊的性质使得全同态加密有广泛的应用需求。2009年,文献[11]首次基于“理想格”提出全同态加密方案,在条件下的任意运算函数进行设定的同态操作,并且满足操作后的密文解密出的明文是预设值。因为每次同态计算将引起密文噪音的增长,当噪音超过正确解密所允许的界限后,将无法执行同态操作。因此,必须设置大的参数使得密文有足够的空间容纳噪音,这直接导致了密文尺寸的剧增。参考相关文献[12-13],笔者提出一种n-bit压缩数据同态加密算法,通过模交换技术控制噪声,将密文大小限定在范围内,同时保证其全同态性质。
1.3 语义空间模型
语义向量空间模型(Vector Space Model,VSM)是解放计算机分析和处理文本能力的开端。VSM的思想是把文档集合表示为空间的点阵,用户的一个查询被表示为同一空间里的一个点,文档按照和该查询的距离递增排序。然而语义向量空间模型还有很多的不足,比如文档的主题分类、关键字、同义词等,会造成搜索效率低,精度误差高的问题。这里根据参考文献[14],选用潜在语义向量空间模型(Latent Semantic Analysis,LSA),可以刻画同义词,同义词集合会对应着相同或相似的主题。SVD降维可去除部分噪声,更具有鲁棒性,充分利用冗余数据,完全自动化。
2 系统模型
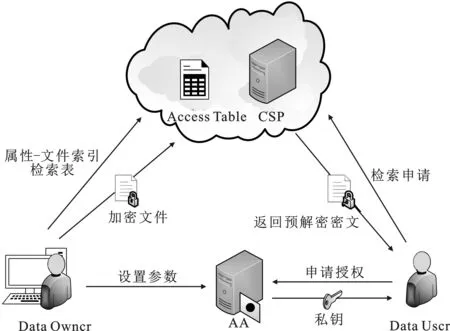
图1 系统模型图
TKRS方案如图1所示,由4个部分组成,在该方案模型中云服务器被认为是诚实且好奇。下面对各个实体在该方案中的详细介绍:数据所有者(Data Owners,DO),数据用户(Data User,DU),权限认证中心(Attribute Authority,AA),云服务(Cloud Service Provider,CSP)。图1方案模型流程:DO将加密的密文集合发送到CSP,再基于词频-逆文本频率指数技术(Term Frequency-Inverse Document Frequency,TF-IDF)[15]的潜在语义向量空间模型搭建一个属性-文件索引的检索表发送到CSP端,将设定的访问权限传输给AA,之后的DU将申请搜索认证发送到AA,获取认证结果(包含私钥),构建搜索令牌,发送CSP请求搜索。CSP执行搜索,通过检索表得出预解密密文传输给DU,解密出明文。
3 系统设计
该方案主要解决了以下3个问题:① 高效的多关键字检索;② 密文细粒度访问控制;③ 用户属性撤销[16-20](基于同态算法3.2实现)。下面对算法进行详细描述。
3.1 方案流程算法
(1) 初始化算法Setup(λ)→(PK,MK):算法构建G0是一个以素数p为阶的双线性群,并且p∈[2η2-1,2η2],η为随机值。设g为生成元,双线性映射e:G0×G0→Gr,定义了两个哈希函数:H0:{0,1}*→G0和H1:{0,1}*→Gzp。在群Gzp中选择三个随机数a,b,c∈Gzp。
公钥:PK={G0,Gzp,e,H0,H1,g,h1=ga,h2=gb,h3=gc,h4=g1/b,e(g,g)ab} ,
主密钥:MK={a,b,c} 。
(2) 密钥生成算法KeyGen(PK,MK,SID)→SK(S,ID):私钥生成由授权中心AA运行。该算法输入公钥PK、主私钥MK、申请用户属性集合SID(属性包含身份信息),然后输出搜索方的属性私钥SK(S,ID)。取随机数r∈Gzp,并对属性集S中的每个属性∀j∈S选取随机数tj∈Gzp。计算得:
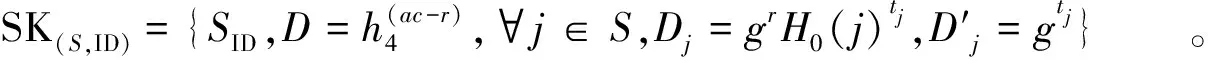
(3) 索引生成算法Indexgen(PK,S,W)→(Inw,L):将DO的属性集合S构建成对应权限的访问向量L,而将对明文集合中的关键字W集合搭建一个基于TF-IDF的潜在语义向量空间(LSA),通过SVD公式计算降维,分解成对应明文的文档向量集,并将两者构建成属性-文件索引表,经过同态模糊数据上传云端CSP,并将索引相关参数上传到AA授权中心,此处的参数用于DU向AA申请检索向量组时参与计算。
(4) 加密算法Encrypt(PK,M,A)→CT:输入明文M、访问策略A和公钥PK,生成密文CT。算法实现如下:

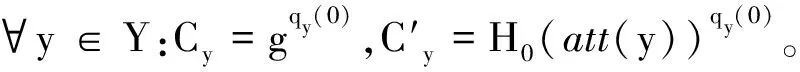
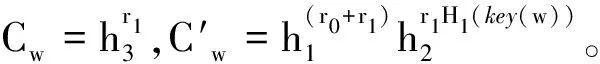

(5) 令牌生成算法Trapdoor(w,SID,R)→TR:搜索令牌生成算法由DU的本地服务器运行。该算法输入关键字集w、DU的属性集合SID、可搜索关键字树R,然后输出搜索令牌TR后发送至CSP。
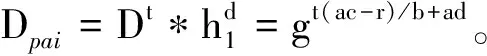

③ 先取随机值tj∈Gzp,对属性集合SID进行计算,有∀j∈SID:Dj=grtH0(att(j))tj*t,Dj′=gtj*t。
④ 此处根据关键字集w生成申请向量,向AA申请生成访问向量组V(ID,SID);该向量组内包含用户属性授权向量I(ID,S)和关键字搜索向量IID。

(6) 搜索算法Search(CT,TR,L,Inw)→(1/⊥):搜索算法由CSP运行。该算法使用上传搜索令牌TR中的访问向量组V(ID,SID)与CSP中的属性-文件索引表进行验证(3.2节具体实现),确定用户的权限和搜索密文的范围,进行文档相似度向量计算,得出该文档的相似度,通过对余弦计算相似度度量的筛选,选取对应的密文,生成待解密密文集合。在进行密文筛选过程中,根据DU的设定参数,可以选择top-k的匹配密文集合。若搜索出满足要求的密文返回1,否则返回⊥。
(7) 预解密算法Pre-Decryt(CT,TR)→M′:将检索到符合要求的密文进行计算,CSP将返回密文中间值给搜索方服务器。
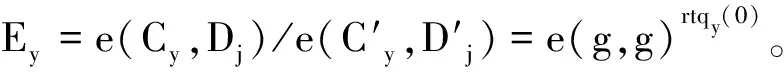
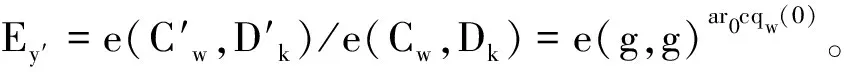
③ 根据两个值ER和ER′进行相对应公式运算:E=e(C,Dpai)ER/ER′=e(g,g)abdr0。则最后返回:



3.2 n-bit压缩数据同态算法

图2 数据压缩示意图
基于文中方案的需求,提出了一种n-bit压缩数据同态算法:设为明文,由于初始同态算法是取二进制明文加密的,即m={0,1}。笔者使用比特压缩折叠理念,如图2所示,将二进制化的明文切割后压缩到0~255的映射表中,通过字符映射的方式来减少二进制转化数据增大的弊端,通过这样的压缩折叠方式生成的待加密明文会比原明文小。并且根据切割的压缩指数,对应地进行同态加密,这里进行二次压缩,极大地降低了同态加密生成的密文大小。而且为了避免多次同态操作增噪的问题,使用了模交换技术来降低噪声,控制密文中噪声的增加。
根据安全参数λ生成私钥p和大素数整数q。c为密文,r是加密过程中的随机生成的噪声整数,k为一次加密的比特数,表示比特的缩减程度。加密时要求k的值保持一致,要求q>r,p/2>m+2kr,取得:加密算法:c=m+2krq+pq和解密算法:m=(cmodp)mod 2k(满足全同态定义)。
3.2.1DO的申请与检索表的匹配操作
属性-文件索引表和访问向量组V(ID,SID)都是同态加密密文,可以使用同态性质进行判断,这里取随机r′p和N=pq作为公钥,参与匹配计算:
Value=((hm.CTattr-hm.CTDU)r′p)modN=(Mattr-Mtoken)r′p。
可见,由于不为0,因此,如果Value为0,则表示匹配成功,即访问向量组的类存在于云服务器的检索表内。此外,生成明文为0的密文集合:{xi:xi=2nri+pqi},在加密时随机从其中选取子集加入加密算法中,加进去的是0的密文,对解密并没有影响,同时通过引入最大公约数问题,证实方案是安全的。
3.2.2 密文细粒度访问控制与属性撤销
在方案中,DO将属性-文件索引表同态上传,输入指定的访问向量组或者Data,通过DO发送的对应同态操作的函数f(upfdate),可以实现对云服务器CSP上索引表上同态加密数据的加同态或乘同态计算,实现属性撤销(此处授权中心AA的属性撤销直接发送请求即可)。通过同态计算控制属性-文件索引表实现对密文的细粒度访问控制,精确到具体用户身份属性识别访问授权,并且通过对索引表上的参数进行同态操作,能够实现云上的文件刷新和删除功能。由于函数运行在云服务器上,充分利用了云的强大算力,能够以低开销同态操作实现撤销,满足大规模数据下多用户授权管理。
由于DO使用的同态操作是针对拥有文件的处理,不共享同态解密密钥,所以云端无法获得解密私钥,只能依照申请发送的函数对同态模糊数据进行操作,从而保证云服务器数据的保密性和安全性。
4 方案分析
4.1 安全性分析
4.1.1 前后向安全性
在设计方案属性管理机制中,当用户的属性发生变动时,DO可以对授权机构AA和云服务器CSP发送同态操作的函数,利用简单的加/乘操作计算出新的数值,并实现对没有被撤销属性的用户私钥的更新。依据同态算法的大素数困难问题,即使在知道原参数值的情况下也无法推算出新属性参数值的定义。同理,用户无法通过更新后的属性值推算出更新前的属性值。因此新方案满足前向后向安全性。
4.1.2 近似最大公约数问题
对该方案的同态密文,任何攻击都可以转换为近似最大公约数问题的解决方案,因此该方案是安全的。
4.1.3 抗共谋攻击
DO对数据文件的加密方式是参照自己的意愿选定属性集合来设定访问结构,并且将利用此访问结构来加密文件。因此只有满足访问结构的用户才能计算出e(g,g)abdr0。假设多个未授权用户的属性集合并在一起才能满足访问结构,由于不同用户的身份属性不同,生成属性私钥组件不相同,所以无法计算e(g,g)abdr0,从而无法恢复出明文。因此方案具有抗串谋攻击性。

表1 方案对比
4.2 性能分析
参考相关文献,针对Jin的多关键字的CP-ABE方案[16]、CAO的可搜索加密方案[17]、Fateh的反向索引的CP-ABE方案[18]以及文中提出的TKRS方案,进行了理论分析和仿真测试。
4.2.1 理论分析
针对评估设计方案在云计算系统中的安全性和实用性,从3个方案与设计方案的功能上进行对比。通过表1可以看出,笔者提出的TKRS方案功能更加强大,更加适用于实际应用。表2给出了相关符号的定义。

表2 符号定义
如表3所示,算法IndexGen、Token的存储开销对比,TKRS方案要明显小于其余3个方案。另外Jin的方案的|SK| 要小于其他的方案的|SK|,因为Jin方案中简化私钥构造,降低对密文的访问策略的控制,这点是通过引入第三方机构实现弥补,但会不可避免地造成传输过程的复杂及其他步骤的数据冗余,而TKRS方案和Fateh方案生成|SK|是依据安全性进行设计的,多了一次用户U的属性量的群上的运算操作值,存储开销在考虑范围内。

表3 存储开销

表4 计算开销
根据表4的分析可以得到,在通信过程中计算传输开销,Jin方案因为算法简化的原因,Keygen计算量比TKRS方案减少接近|Au|G,但同之前存储开销分析的原因一样,Jin方案的其他步骤的计算开销要远远大于TKRS方案不止|Au|G的计算量。另外,算法Search和Update对比中,TKRS方案计算开销最小。关于Dec算法数据解密过程,即数据文件访问解密阶段的开销,分为云端计算DecCloud和本地计算DecDu两部分,云服务器的算力高,不能做参考点,与参考文献方案对比,TKRS方案明确体现了将云端算力和数据处理相结合的特点,能以低本地计算开销保证数据安全。综上所述,TKRS方案通过牺牲一点存储代价换取方案的安全和高效率是值得的,所提方案就综合性能而言,是4种方案中最好的。
4.2.2 仿真测试
对笔者所提方案的实际性能进行仿真实验,是在具有2.30 GHz Intel®CoreTMi7-10875H CPU和8 GB内存的Windows机器上执行的,运行环境为JDK 1.8.0_271、eclipse和JPBC库支持。文件数据集源自于英文维基百科的部分历史数据,text格式。
(1) 加密索引大小。这里首先测试生成文件索引的大小,由于内存的限制,选用500份文件进行测试。联系图3和图4分析,Jin和CAO方案生成索引的开销程度一致,而索引加密的开销程度不同。下面对比统一取500 文件数的节点为标准,Jin和CAO方案从780 MB加密至35 465 MB和22 152 MB,相当于分别增加了约44.5倍和27.4倍。笔者提出的TKRS方案能够有效控制密文增长,根据算法来调节压缩比例。与Jin和CAO方案对比,生成索引7.65 MB,压缩到约0.98%,加密索引645 MB,压缩到约1.8%和2.9%。Fateh方案的生成索引23.55 MB,压缩到Jin和CAO方案的3%,加密索引2 072 MB,压缩到5.8%和9.3%,性能明显低于TKRS方案。此外,笔者提出的方案存储规模的加密指数不依赖于文档索引大小,而是依赖于安全级别,是在安全性和性能之间选择适当的平衡。

图3 生成索引大小对比

图4 加密索引大小对比
(2) 检索效率。为了检测搜索密文的效率,针对笔者提出的密文检索模型和参考方案进行对比,该次检索测试5 000份文件矢量。对比方案的模型结构和检索算法,图5中Jin和CAO的基于矢量的遍历检索时长随着数量增长而增长,总耗时要比主题模型高。图6中 Fateh方案和TKRS方案基于主题模型,提取语义关键字建立主题类,两个方案检索方式都是先确定检索密文范围再遍历匹配,测试取限定密文文档范围为预估最大值(109)进行遍历的效果进行对比。根据图中遍历效率对比,TKRS方案模型主题指标的构建较Fateh方案是趋于稳定的,而且使用的计算量要低于Fateh方案近3倍的耗时差。

图5 矢量模型遍历检索效率

图6 主题模型遍历检索效率
(3) 检索精度。这里对TKRS方案和参考方案进行对比测试分析,取5 000个文档矢量进行实验。图7中是使用了定长的多关键字申请矢量进行检索,5 000份文件的分段检索,针对各个方案的匹配反馈文件数进行对比,可以明显看出Jin方案和CAO方案反馈密文数量接近于50%,而Fateh的方案和TKRS方案提供top-k的筛选功能,能够有效地控制匹配密文的反馈数量。图8针对5 000个文档矢量进行重复多关键字搜索,取均值(取60~100关键字区间,准确率波动小)。Fateh方案多次进行检索得出精度在38.76%左右。而TKRS方案更为高效,准确度接近44.26%,因为方案使用的LSA语义模型在低维空间刻画同义词,充分利用冗余数据提取主题,当查询关键字数量越多时,越能有效确定检索文档。

图7 方案检索密文匹配对比

图8 方案命中文档准确率对比
5 结束语
笔者提出了一种支持属性撤销的top-k多关键词密文检索方案,使用了属性基加密、同态加密和语义空间模型技术,并相对应地进行优化,构建属性-文件检索表来提高检索效率,实现了多关键字检索和属性撤销功能。并且该方案支持前后向安全性和云端数据操作的隐私保护,抗共谋攻击。对该方案进行了理论分析,与参考方案进行了实验对比,证明了该方案性能的优越性。最后,随着可搜索加密的理论和技术不断进步,使用的加密算法和语义模型都有很大的创新潜力,增强性能和安全性,可以结合云平台进行相关探索研究。
