基于关联规则的铁路信号设备故障诊断方法
2022-04-24张振海张湘婷
张振海,张湘婷
(兰州交通大学自动化与电气工程学院,兰州 730070)
引言
铁路信号设备在保障列车运行安全、提高铁路运输效率等方面有着关键性作用。随着我国铁路快速发展,列车运行速度的提升,铁路信号设备的重要性日益凸显,使电务段对信号设备的维修管理变得更加严格。传统的铁路信号设备故障诊断主要靠人工经验,且设备故障原因有明显的随机性和模糊性,因此,对人员专业水平要求高[1]。与此同时,铁路信号领域的历史故障维修成功案例大多以文本形式储存,使得许多知识和经验难以被充分利用。针对这一现状,如何合理的运用这些文本故障信息辅助故障诊断,是一个亟待解决的问题。
故障诊断是利用现代检测系统确定是否有故障发生,并确定故障发生的位置和类型等,故障诊断方式大致分为基于定性分析的故障诊断方法,基于信号处理的故障诊断方法,基于人工智能的故障诊断方法[2]。王兰勇[3]根据铁路信号设备发生故障现象、原因和处理方案设计专家系统;LEE等[4]运用声学分析法对道岔系统进行故障探测分析;张娟[5]采用神经网络BP算法解决铁路信号设备多故障处理顺序问题。随着人工智能技术的成熟,通过人工智能方法将故障文本数据作为数据源的故障诊断方式,是当前研究的热点之一。上官伟等[2]针对车载设备的故障日志,引入改进主题模型(Labeled-LDA),通过支持向量机算法进行故障诊断;盛春东[6]根据案例推理建立铁路信号设备维修决策模型;ZHAO等[7]结合PLSA模型和贝叶斯网络的方法对高速铁路车载设备进行故障诊断。以上这些学者并未深入挖掘出故障信息内的隐藏规律,同时缺少考虑铁路领域先验知识的影响。关联规则是数据挖掘的重要领域,通过算法在海量数据中挖掘出潜在未知的规律,建立两种或两种以上事务数据之间的联系。朱兴动等[8]将关联规则运用在飞机维修记录上,查找出飞机故障与其他因素的联系;张宏[9]提出基于Apriori算法的汽车运行数据采集设备故障诊断方法。
为此采用基于关联规则的故障诊断方法,首先采用TF-IDF算法[10-11],对以往的铁路信号设备故障案例进行故障特征提取。由于故障特征词可能出现的文本不同,相互之间隐藏某些关联规律。需建立基于关联规则的故障诊断模型,进而用改进FP-Growth算法[12-13]进行数据挖掘,计算项的权重使之表示支持度,依据频繁1-项集划分数据库进行挖掘,在减少运行时间的同时可挖掘出更具有实际意义的关联规则,从而提供维修辅助决策,简化故障处理流程,保障列车运行安全。
1 基于故障文本信息挖掘的故障诊断流程
铁路信号设备故障案例库按照信号设备分成不同子库,为道岔故障、轨道电路故障、信号机故障、电源屏故障、控制设备故障、移频发送设备故障和移频接收设备故障等[6]。为更好地描述故障设备信息潜在的关联规则,以道岔故障为例,部分故障维修记录如表1所示。

表1 故障维修记录
由表1可知,铁路信号设备故障维修案例总结主要是以文本形式记录,存在故障数据不规范性,如“2013年3月21日18时45分,29/30号道岔瞬间断表示”,其中,与道岔故障有关的信息只有“道岔瞬间断表示”,无关信息的冗余会造成有实际意义的规律信息无法挖掘出来,故将铁路信号设备故障诊断主要分为两步:故障特征提取和故障诊断。铁路信号设备故障诊断首先采用TF-IDF算法处理所采集的故障数据,提取关键故障特征词,使其具有区分文本的能力。再用改进的FP-Growth算法,挖掘铁路信号设备故障特征数据库,得到关联规则,结合专家相关经验对其故障诊断,整体流程如图1所示。
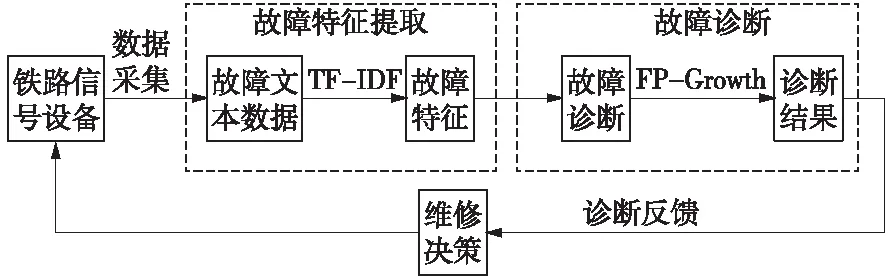
图1 故障诊断整体流程
2 故障特征提取
铁路信号设备维修成功案例是以故障文本数据为基础,且故障文本数据是非结构化数据,需转换成计算机可识别和处理的结构化数据,而且有效的文本特征提取可降低数据冗余度和维度,在故障诊断中占有重要的位置。故障特征项须具有以下特点:①可以真实反映文本内容;②具有良好的区分其他文本的能力;③特征项数量不能过多,否则会导致算法复杂度太高;④特征值之间需要有区分度[14]。主要步骤如下。
(1)使用NLPIR-ICTCLAS系统将收集的历史故障文本信息进行分词,并且删除无关词,转化成以词语组成的文本数据。
(2)将文本数据用VSM模型表示,采用TF-IDF算法计算每个词语在文本的权重,删除权重小的词语。
(3)最终建立故障诊断模型。
2.1 文本表示
NLPIR-ICTCLAS是由中科院张华平团队开发的一款汉语分词系统,结合铁路信号专业词库和停用词,对故障文本数据进行预处理,去除如“故障发生地址”和“时间”等无关词语,保留关键词。
分词后的结果,依旧是非结构化的数据,需将文本转化为结构化数据,目前常用的文本表示方法有:布尔模型(Boolean Model)、概率模型(Probabilistic Model)、向量空间模型(Vector Space Model)[15-16]。目前使用最广泛的是向量空间模型VSM。
向量空间模型VSM旨在把文本内容转换特征词-特征权重的向量并保存。把特征项t1,t2,…,tn看作是一个n维坐标系,权值w1,w2…,wn表示其对应的坐标值,文本di映射为该向量坐标空间中的一个特征向量V(di)=(t1,wm1;t2,wm2;…;tn,wmn),文本总体的VSM表示见表2。
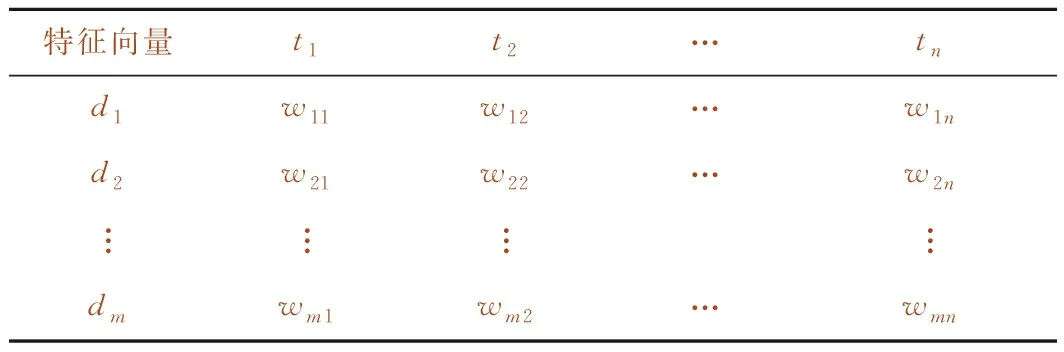
表2 文本的向量空间模型
2.2 TF-IDF算法
TF-IDF算法是一种经典的基于向量空间模型计算特征项重要程度的方法,通过考虑词语在文本中出现的频率和在文本集中的分布,计算词语权重[10],其中,TF为词频,IDF为逆向文档频率。核心思想:假设某个词在某条文本中出现频率较高(TF较高),但在剩余文本中频率低(IDF较高),则该词有很好地类别区分能力。TF-IDF方法计算公式如下
Wt,d=tft,d×idft,d
(1)
式中,Wt,d为特征值t在文本d中的权重;tft,d为词频;idft,d为逆文档频率。
tft,d词频为特征值t在文本d出现的次数与文本d中所有特征值之比,计算公式如下
(2)
式中,nt,d为特征值t在文本d中出现次数;∑knt,d为文本d中所有特征值的个数。
逆文档频率idft,d是文本数量与特征值t在文本集中出现的次数比值,计算公式如下
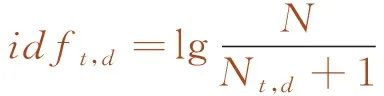
(3)
式中,N为文本数据库中文本总数;Nt,d为文本含有特征值t的文本数量。如果某词不在样本中,会导致分母为0,因此,分母加1是为避免该情况。
将NLPIR系统处理后文件加入TF-IDF算法,计算权重Wt,d。
2.3 故障诊断模型
由于铁路信号设备种类繁多,遇到的故障多种多样。通过对铁路信号故障数据总结,结合铁路信号专家的经验知识,建立基于关联规则故障诊断模型,如图2所示。故障诊断模型分为3层:故障特征层、故障类型层(一级故障层)和故障原因层(二级故障层)[17]。故障特征层是故障文本进行预处理后得到的故障特征,故障类型层是根据第1节铁路信号设备分类结构细分得到的设备名称如“转辙机相关故障”“整流匣相关故障”,故障原因层是相对于类型层更加具体的故障部位如“继电器”“补偿电容”等。本次研究认为导致故障现象发生的原因是单一的,因此,根据故障传播原理,对故障诊断模型层进行以下说明。
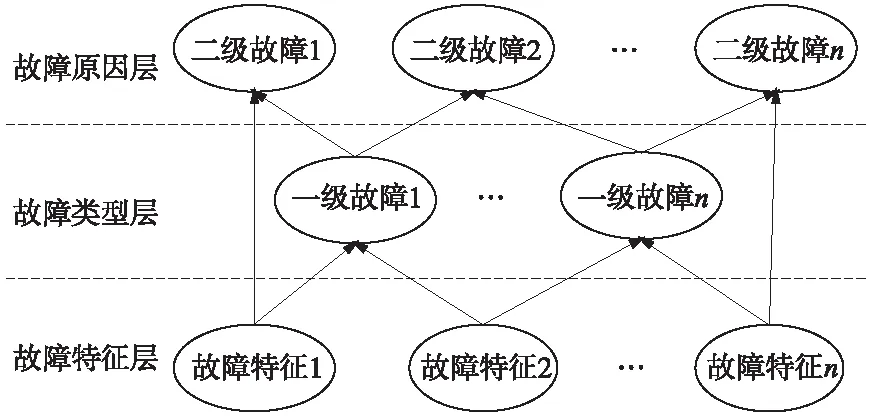
图2 故障诊断模型
(1)二级故障是一级故障出现的原因。
(2)一级故障和二级故障均是故障特征出现的原因。
(3)一级故障之间相互独立,每次只能推导出1个一级故障。
(4)二级故障之间相互独立,每次只能推导出1个二级故障。
根据故障诊断模型,对各属性进行编号,表1的处理结果如表3~表5所示,如表1中的维修记录5,根据故障诊断模型可得出F7(表示时有时无)→T5(整流匣相关故障)→R4(整流匣电阻内部开路),从中可看出,故障特征层、故障原因层与故障类型层3层之中具有因果关系。

表3 故障类型

表4 故障特征

表5 故障原因
3 基于关联规则的故障诊断
关联分析是发现隐含于大数据中具有实际意义的规律信息,描述为关联规则或频繁项集[18]。采用改进FP-Growth算法挖掘出隐含在故障特征的关联规律,得到故障特征、类型和原因之间关联关系,作为铁路信号设备故障诊断的重要依据。
3.1 FP-Growth算法
FP-Growth算法优势是只需遍历2次事务数据库,运行效率高。首次遍历数据库D,目的是删掉小于最小支持度的项,建立频繁项集,第二次遍历用于建立FP-Tree,具体步骤如下。
(1) 遍历事务数据库,计算每项支持度并除去多余项,获得频繁1项集L,按照支持度降序排列得到有序频繁1项集P,然后对事务数据库D重新调整。
(2) 创建根节点root和频繁项目头表,再次遍历事务数据库D,根据频繁1-项集P调整每条事务,扫描每条事务建立分支创建FP-Tree。
(3) 根据FP-Tree找到单项的条件模式基,递归挖掘条件FP-Tree,最终依据频繁项集从中得出关联规则。
3.2 改进FP-Growth算法
3.2.1 支持度计算
传统FP-Growth算法中每个项的支持度等于项在事务数据库中出现的频率,但忽视每个项在事务数据库D的重要程度,以至于挖掘出大量无用的关联规则[19-20],因此,提出基于权重的支持度计算方法。为体现项对事务的重要性,同时保留发生频次低但一旦发生会产生重大事故的故障特征。人为对每个故障特征进行危险性评估,分为轻度危险、中度危险、重度危险和极重度危险,将评定为重度危险和极重度危险项,自动保留且支持度设为0.3,其余项按照所提出的基于权重的支持度计算,计算方法如下。
设I={I1,I2,…In}为事务数据库D的项集,n为表示项的个数,设置项Im在事务数据库中的权重为w(Im),表示项Im在数据库出现的次数与数据库中总体事务数量之比,计算公式为
w(Im)=l/k
(4)
式中,l为项Im在数据库中出现频率;k为数据库中事务总数。
事务Ti为事务数据库中第i条数据,该事务的权重是事务本身含有全部项的权重的平均值,记为wt(Ti),即对第i条事务的所有项的项权重w(Im)求取平均值,其中,m=1,2,…,n。计算公式为
(5)
项Im的支持度是含有该项的全部事务权重和数据库中全部事务权重之比,即sup(Im),计算公式为
(6)
式中,f为包含项Im的事务个数;wt(Tx)是包含项Im的事务权重;k为事务数据库中所有事务数量;wt(Ty)为事物数据库中每条事务的权重。
3.2.2 关联规则挖掘
传统FP-Growth算法遍历数据库时,需建立FP-Tree实现频繁项集挖掘,当事务数据库过于庞大时,建立的FP-Tree占用内存大,导致运行速率低,降低挖掘效率[21-22]。另一个改进地方是根据频繁1-项集划分数据库的思想挖掘数据,构建各项的数据库子库并直接构造每项的条件FP-Tree,在减小内存占用,同时提升挖掘效率。具体算法描述如下。
(1)遍历事物数据库D,按照3.2.1节的支持度计算得到每项支持度确保项的重要性,去除小于最小支持度的项,降序排序得到频繁1项集L,设L={T1,T2,…,Tn},调整事务数据库按照频繁1-项集排序得到有序的事务数据库D′。
(2)再次遍历事务数据库D′,找到包含项Tm所有的事务,删除小于项Tm支持度的其他项,得到包含项Tm的数据子库DT。
(3)采用FP-Growth算法对项Tm的数据子库进行关联规则挖掘,具体步骤如下。
①根据包含项Tm的数据子库DT建立FP-Tree,创建项头表N。其中,项Tm排在最后,当已有分枝存在,判断新来节点是否属于该分枝节点,属于重合计数加1,否则重新建立分枝,最终得到数据子库DT的FP-Tree。
②只挖掘项表头N最后一项的信息,即只挖掘包含项Tm的频繁项集,找到项Tm的条件模式基,建立条件FP-Tree,递归调用树结构,得到包含项Tm的数据子库DT频繁项集UT。
③重复步骤①②,把频繁1-项集L内所有项的频繁项集UT全部挖掘出来,取并集得到频繁项集U,为事务数据库D的所有频繁项集。
3.3 基于关联规则的故障诊断
通过对铁路信号设备故障特征进行挖掘得到关联规则,保存到历史故障文本数据的知识库KB,从知识库中提取规则进行故障诊断,步骤如下。
(1)将信号设备故障现象进行故障特征提取,再与知识库KB中的已有规则进行匹配,如果匹配成功,直接输出诊断结果。
(2)若只有部分匹配,将其放入知识集KS中,选择包含此故障特征置信度大的规则,得出最优解。
(3)若KS为空,则询问用户是否加入新规则,若不加入,系统失败进入人工诊断,若加入,即此时用户添加了新的知识,则根据新的知识库,重新进行诊断,流程如图3所示。
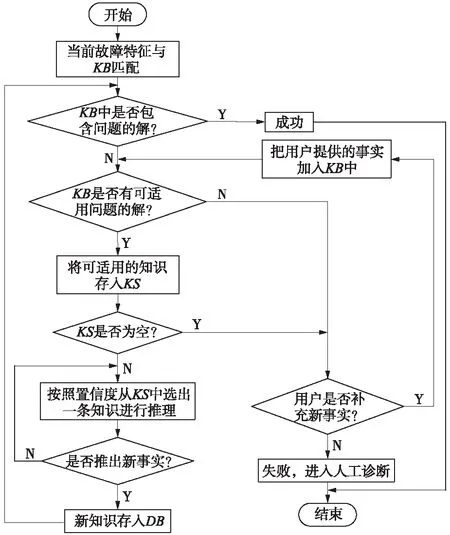
图3 基于关联规则的故障诊断流程
4 实验结果分析
4.1 实验环境
实验使用的硬件为Intel(R)酷睿I5-42210U,2.70 GHz处理器,8 GB内存,操作系统是Windows 7旗舰版64位;软件为eclipse3.4-jee-ganymede开发运行平台,JDK7.0版本。
4.2 算法比较
本实验以2013年~2018年的某铁路局电务段的铁路信号设备故障案例库为数据源,包括道岔、信号机、轨道电路等。
图4(a)表示在数据库中,随机选择1 000~6 000条事务对其挖掘,分别计算每个故障案例子库中项的支持度,根据现场经验,设置最小支持度为0.02。由图4(a)可知,事务数据库越庞大优化算法的优势越明显,因为传统算法是针对数据库构造整体FP-Tree,数据越多FP-Tree所占内存越大挖掘效率也越低。
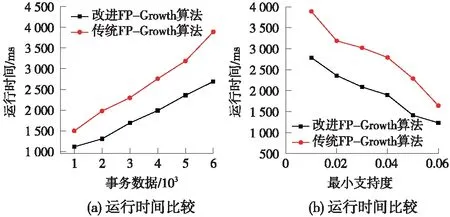
图4 实验结果比较
图4(b)表示随机从数据库中选取5 000条数据进行实验,设置不同最小支持度min_sup,比较两种算法的运行时间。由图4(b)可知,在相同规模下的数据库和不同最小支持度的条件下,改进算法要比传统算法的运行时间要短,并且最小支持度设置越小改进算法的优势越明显。
4.3 故障诊断应用及分析
从铁路信号设备故障案例库中,随机选取其中10 000条数据进行实验,其中,75%作为训练集,25%作为测试集,分别计算每个故障案例子库中项的支持度,设置最小支持度为0.02,置信度为0.6,得到的关联规则有3578条,其中符合最小置信度和故障诊断模型的关联规则有2281条。因篇幅有限,仅列出道岔故障相关的10条具有代表意义的关联规则,如表6所示。

表6 关联规则
根据对铁路信号设备故障挖掘关联规则再结合专家经验,根据诊断结果选择维修方案。例如,根据规则9中故障特征词道岔无表示与道岔扳不到位可推出是转辙机相关故障,即从故障特征层推到故障类型层,如果推理正确,再根据规则8中转辙机相关故障推出转辙机减速器抱死,即从故障类型层推到故障原因层,如果原因正确,推出解决方案更换减速器。如果推理不正确换一条规则重新推理,直到推出最终结果。
为验证本文算法的有效性与实用性,同时避免重要故障原因的遗漏,将P@N(N=5)作为评价指标[23],将最可能出现的5条原因作为输出结构,具体公式如下
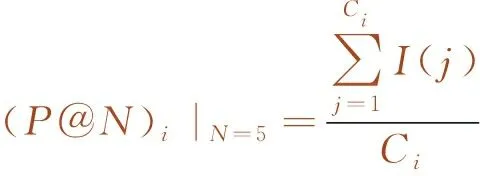
(7)
式中,i为第i类故障;Ci为第i类故障的个数;I(j)为以第i类的故障数为基础,输入测试集的故障现象通过故障诊断算法输出的5个故障原因是否包括实际的故障原因,如果包括I(j)取1,反之取0,若实际故障原因单一,且推理出的原因包括实际原因,则P@N=1。
选择本文算法、文献[6]基于案例推理的故障诊断(CBR算法)、文献[7]基于PLSA模型和贝叶斯网络的故障诊断(BNPLSA算法),根据第1节的对铁路信号设备分类,进行P@N(N=5)的比较,所得结果如图5所示。
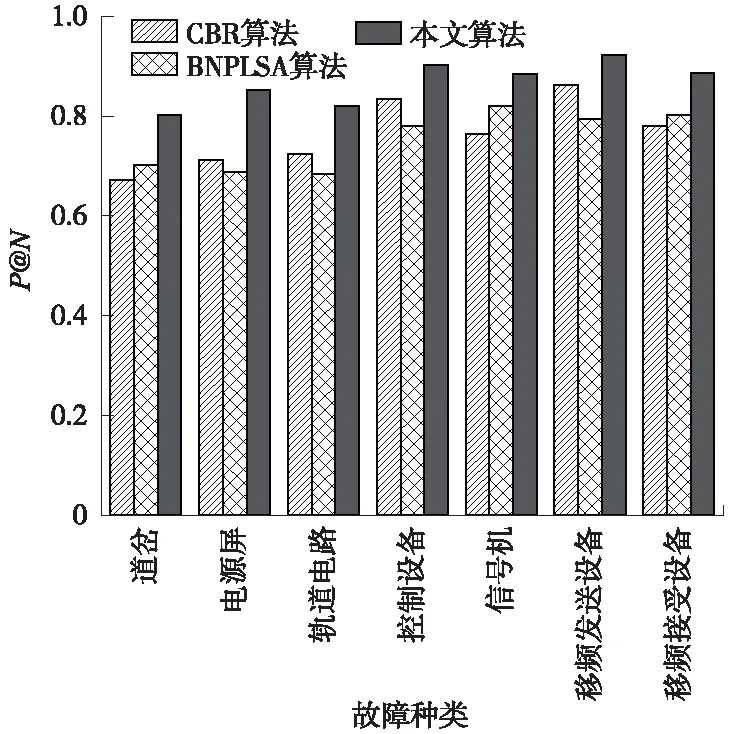
图5 各类故障的P@N比较
由图5可知,本文算法的P@N均高于其他两种算法,且平均诊断准确率86.77%,比其他两种算法分别提高10.35%和11.44%。基于案例推理的故障诊断采用的VSM模型的余弦相似度和BTM模型的相似度,该方法仅考虑当前故障现象与历史案例的相似度,并未综合考虑到故障维修文本数据的潜在规律。基于PLSA模型和贝叶斯网络的故障诊断,采用PLSA模型进行主题分类,但PLSA模型为无监督学习,缺少考虑铁路领域的先验知识,导致取得的故障特征较少。因此,本文算法提取故障特征词,通过改进FP-Growth算法,挖掘出故障文本数据的潜在规律,最终通过故障诊断流程,能够更加精确的推出故障原因,辅助现场维修人员快速处理故障设备。
5 结论
(1)通过分析当前铁路信号设备维修所存在的问题,利用大量历史维修文本记录,提出铁路信号设备故障诊断流程;采取TF-IDF算法提取历史维修记录的故障特征词,按照故障诊断模型进行分类;最终通过改进的FP-Growth算法,发现具有维修指导意义的关联规则。
(2)实验证明,计算每项权重来确定支持度,依据频繁1-项集对其进行分块挖掘的改进FP-Growth算法比传统FP-Growth更具有优势。该方法可以挖掘出铁路信号设备中的故障特征、类型和原因之间的关联关系,为铁路信号设备维修提供帮助。通过对比实验分析,本文方法可提高故障诊断的效率,为铁路安全运行提供保障。
(3)由于文中最小支持度是根据现场经验人为设定的,会影响频繁项的数量,当数据库不断扩大时,频繁项数量的增多导致会挖掘出大量冗余的关联规则。如何根据事务数据库中的事务数量动态设定最小支持度,是下一步研究的重点。
