基于PSO优化的叶节点加权随机森林算法
2022-04-24胡明祺张森昶
胡明祺,张森昶
(郑州大学网络空间安全学院,郑州 450000)
0 引言
随机森林(random forest)由加利福尼亚大学的Leo Breiman提出,后来经过YL Pavlov的改善, 提高了随机森林算法的基本性能,并在研究和工业等各领域得到广泛应用。传统随机森林算法的随机性来自于两个随机化过程:一是从原始数据集中随机生成若干训练集,二是用来分支的最优特征属性是从随机生成的部分特征属性中选择的,最终其输出结果为一个包含分类能力各不相同的决策树的集合。由于传统的随机森林算法随机程度高且对每棵决策树的分类能力不做评估,因此极易出现同一集合中同时存在权重相同的、分类能力较强和较弱的决策树分类器,使随机森林的整体性能下降。这也导致传统随机森林算法准确度不高,易出现过拟合现象。
目前,对随机森林中的决策树加权以区分不同决策树的投票性能成为提高随机森林算法分类精度的一个研究方向。本文提出了一种基于PSO 优化的叶节点加权随机森林算法,通过bagging 算法进行抽样和特征选择,并在每棵树的叶节点上进行加权,从而赋予每个叶节点不同的投票权重,提高分类的精确度。此外,我们引入粒子群算法(PSO)对权重向量进行优化,使加权不再由人工设置,提高算法的科学性与合理性,在整体上改善了算法的性能。
1 相关工作
近年来,大量学者从各个方面对传统随机森林算法进行了许多优化。林枫等提出了用果蝇算法进行优化的随机森林算法, 解决了传统参数选择方法存在主观干扰性的问题, 该算法有利于较大数据集的提取,但无法作用于较小数据集且未对随机森林算法的重要问题,即投票问题,进行优化。庄巧蕙对随机森林算法的泛化能力进行提升,使其能够参与实际应用,但是仅仅提高泛化能力会在某些情况下降低随机森林算法的准确性。杨彪使用基于误判率比较的二次训练的方法对决策树的叶结点进行加权,提高了随机森林算法的性能,但在权重优化方面仍有提升的空间。
2 粒子群算法
自适应优化算法可以根据当前数据的处理特征,自动调整模型参数或处理办法,以达到增强模型分类性能的目的。粒子群算法是一种性能较好的自适应优化算法。本文采用粒子群算法对随机森林进行叶节点权重优化,使权重向量更加科学合理。
粒子群优化算法可以处理连续优化问题和组合优化问题。在传统粒子群算法中,模型会初始化一群随机解,将这些潜在的解称作粒子,这些粒子通过跟踪两个极值来更新自己。


此时,每个粒子的优劣性可以由目标函数来得到,将第个粒子的“飞翔”速度记为

将第个粒子的个体极值记为

第个粒子的全局极值记为

更新每个粒子为
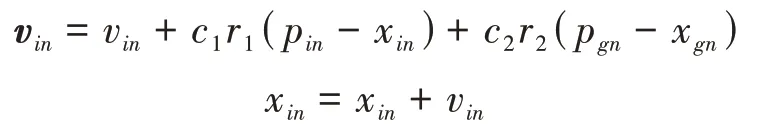
其中= 1,2,…,,= 1,2,…,;和为非负的常数;和是介于[ 0,1] 之间的随机数。v∈[ -,];是常数。以上操作迭代进行直至满足迭代终止条件。
3 加权的随机森林算法
3.1 随机森林算法
随机森林是一个以若干决策树为其基分类器的组合分类器,传统的随机森林算法主要由三步组成:①采用bootstrap抽样的方法从原始数据集中随机生成若干训练集。②用各训练集分别训练决策树,并不进行剪枝,其用来分支的最优特征属性是从随机生成的部分特征属性中选择的。③各个决策树分类器的集合构成一片随机森林,此随机森林的模型输出为:

其中为测试集,为类别数,为随机森林模型的规模,f()表示第棵决策树的分类结果,(⋅)是一个判断函数,当基分类器的输出结果满足条件时为1,不满足时为0。
对于随机森林中决策树的生成算法,我们选择CART决策树算法,此算法递归地在每个内部节点处进行基于基尼指数的特征分割,最终生成一棵二叉树。CART决策树对特征值的选取及特征取值的数目有很好的适应性,因此被广泛使用。
3.2 基于PSO优化的叶加权随机森林算法
作为一种分类器的组合方法,随机森林算法在训练数据集选取和特征值选取时的随机化可以有效避免决策树易于过拟合的缺点,增强模型的泛化能力。但实际上,正是由于决策树生成算法的两个随机化过程,各个决策树甚至同一决策树的每个叶节点的分类精度都有较大的差异。在传统随机森林模型中,每棵决策树的投票权重都是相等的,这就导致一些性能较差的决策树或叶节点的投票会影响整个随机森林分类器的最终分类结果。因此,本文提出基于PSO 优化的叶加权随机森林算法,对随机森林中每棵决策树的每片叶节点加以不同权值,并使用PSO 算法进行自适应优化,进而达到提高随机森林分类器整体性能的目的。
此外,针对随机森林分类器在某些噪声较大的分类或回归问题上会出现过拟合的问题,我们通过bagging 算法对特征集和训练集进行特征选取,以此来训练分类器,并提升算法在特征选取方面的准确性。在特征选取之后,我们为每个子叶随机分配初始可信度,构成可信度向量,并使用PSO 算法对可信度向量进行优化,直至其性能达到预先设置的完成阈值。最后,我们记录叶节点可信度向量,并将其作用于测试中最终得到的叶节点,以此来对子叶加权,最终采取投票法得出随机森林的结果。
算法步骤如下:


其中为测试集,为类别数,为随机森林模型的规模,f()表示第棵决策树的分类结果,(⋅)是一个判断函数,当基分类器的输出结果满足条件时为1,不满足时为0。
4 实验结果与分析
为了检验此算法的性能,我们使用标准UCI测试数据集对算法进行测试。选择的数据集详细信息如表1所示。

表1 数据集
为了测试算法的可靠性,我们在每一个数据集中加入30%的随机噪声,随后用上述数据集对随机森林算法和加权随机森林算法分别进行了十折交叉验证,以达到对比效果。测试结果如表2所示。
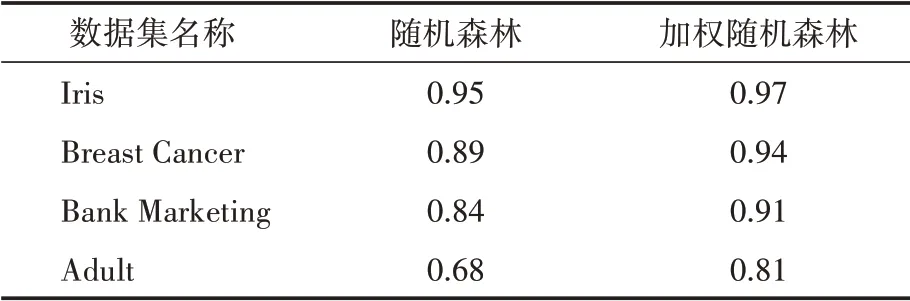
表2 分类精度
可以看出,相较于原本的随机森林算法,PSO 优化的加权随机森林算法在各数据集上的分类精度都有明显的提升。通过对比可以发现,PSO 优化的加权随机森林算法对于大数据集的适应性更好,性能提升度可达19.1%。
此外,为了测试PSO 优化过程对本算法分类精度的影响,我们尝试改变PSO 算法的种群数量和最深迭代次数两个参数,并进行了多次对比实验,测试选用的数据集为Bank Marketing数据集。在Python 环境下测试的输出结果如图1所示。

图1 Python环境下测试的输出结果
其中,var 表示最深迭代次数iter=60+2×pop 的情况;cons 表示iter=150 的情况。从实验结果可以看出,pop 和iter 对PSO 性能并无明显影响,PSO 优化的加权随机森林算法有较好的适应性和稳定性。
5 结语
本文提出了一种基于PSO 优化的叶加权随机森林算法。这种算法针对决策树生成算法的两个随机化过程,对随机森林中每棵决策树的每片叶节点加以不同的权值,使各个叶节点的投票权重与其分类精度达到平衡。利用PSO 算法全局搜索能力强、收敛速度快的优势,我们对叶节点权值进行优化,以此提高分类性能较强的叶节点的投票权重,降低分类性能较弱的叶节点的投票权重,有效避免决策树易于过拟合的缺点,增强模型的泛化能力,进而达到提高随机森林分类器整体性能的效果。
理论分析和实验结果表明,基于PSO 优化的叶加权随机森林算法是可行的。与传统的随机森林算法相比,该算法在分类精度及模型稳定性上都有明显提升,且对于大数据集的适应性更好,性能可比传统的随机森林算法提升19.1%,有一定的研究和应用价值。
目前,本文算法在提高模型适应性方面还存在改进的空间,在降低算法时间复杂度方面仍需作进一步的研究。
