云边环境下的任务调度算法研究综述
2022-04-24靳紫薇郭会明
靳紫薇,郭会明,焦 函
(1.中国航天科工集团第二研究院,北京 100039;2.北京航天长峰股份有限公司,北京 100039)
0 引言
随着物联网及相关技术的发展,海量终端设备加入互联网,形成万物互联的网络空间。面对终端和用户的海量请求,云计算难以满足终端低延迟与及时响应的要求。边缘计算应运而生,文献[1]首次正式定义了边缘计算:允许在网络边缘对代表云服务的下游数据和代表物联网服务的上游数据进行处理的新型计算范式。
云中心与边缘设备的硬件异构性、地理位置差异性导致了二者适用任务不同。传统云计算具有强大的集中式计算能力和存储能力,比较适合长周期,非实时性的数据处理。边缘计算与用户地理位置更为接近,但受限于计算和通信能力、续航能力,边缘计算更适合短周期、实时性的数据处理。在云边计算模型下,“如何协同”成为当下研究人员谋求突破的一大难点。在云边环境下,合理分配用户任务能够实现硬件资源与用户需求的高效映射,能够提高整个系统的性能与效率、降低成本与能耗、满足用户服务质量。然而,任务调度本身是一个NP-难问题,同时,云-边、边-边资源异构性、虚拟化技术的发展也为任务调度优化问题提出了严峻的挑战。资源管理与任务调度作为云边协同计算模型至关重要亦是不可回避的关键环节,成为当下研究的重点与难点。
1 调度问题优化目标
缩短执行时间和降低成本是大多数调度算法重点关注的两种优化目标,除此之外,调度算法的研究通常也考虑了其他一些性能指标:负载均衡、能耗等。
1.1 执行时间
云边环境下,任务的执行时间是指节点提交任务请求至收到云边系统的任务执行结果的整个过程所需的响应时间。任务的执行时延取决于任务本身的量级和任务被分配的资源容量,文献[4]通过实验比较了纯云、纯边缘和云边混合处理执行MapReduce 任务集种不同应用的性能,分析得出不同的应用适用于不同的处理方式,而合理的调度方案能够实现任务与资源的高效映射,缩短执行时延。
对计算时间和云边通信时间的优化是缩短执行时延的有效手段,也是当前研究的热点。文献[5]考虑到云边节点处理速度差异,将云边环境下的任务调度问题执行时间最小化问题抽象为将基于逻辑的Benders 分解(LBBD)原理与混合整数线性规划(MILP)模型相结合的求解,实现任务到异构计算节点的映射。由于云边架构的地理位置、带宽差异等特性,任务卸载至不同位置的服务器将带来不同的通信开销。相比于传统云计算,这种通信差异在云边环境下导致了不可忽略的执行时间的影响。文献[6]考虑了边缘计算和云计算的数据分布特点,与云边之间的数据带宽、边缘端数据中心数量和边缘数据中心的存储容量等影响因素,提出了一种混合遗传算子的自适应粒子群优化算法,有效减小工作流调度在云端与边缘端之间的数据传输时延。
1.2 成本
成本取决于能耗与执行时间,同时也与设备损耗相关。其他一些研究还考虑了云边的设备状态差异、结构差异等因素,如文献[7-9]使用动态电源管理、动态电压频率缩放、松弛回收、资源休眠等技术有效减少了计算资源的能耗。
文献[10]通过电压动态调整技术,在满足任务截至时间约束的前提下,达到系统能耗最小化。文献[11]通过分析计算节点功耗与设备资源利用率之间的关系,推断出作业执行能耗和最佳资源利用率,通过感知资源利用率,提出具有能源感知的启发式调度算法,将贪心策略与搜索优化方法相结合,提出了混合粒子群优化算法,作用于任务调度,提高了该算法的全局优化能力,降低了工作的平均能耗。
1.3 负载均衡
云边环境下,负载均衡表示系统内不同节点负载的均匀程度,可通过公式(1)表示。其中,u表示第个节点的资源利用率,-表示系统内设备平均资源利用率,表示系统内设备数目。
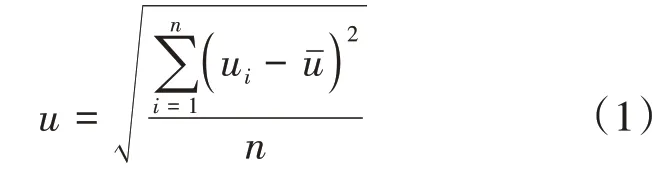
文献[12]针对异构云环境,提出了具有物联网感知的多资源任务调度算法,主要针对计算资源负载均衡和时间均衡。文献[13]针对云计算的复杂能耗问题,提出了一种基于云雾计算的能源感知型调度算法,从软件定义网络架构和云雾计算负载均衡算法入手,一方面分散了雾节点和云计算系统的异构计算数据,另一方面,定义了网络的的集中信息和分布式调度程序,以椭圆分割区域为对象,实施部署数据共享和异构云雾计算任务的最佳分配。
2 任务调度算法
本节针对云边环境,按以下分类方法梳理了当前任务调度算法的发展历程与研究现状,介绍了各类算法的策略思想与优缺点。
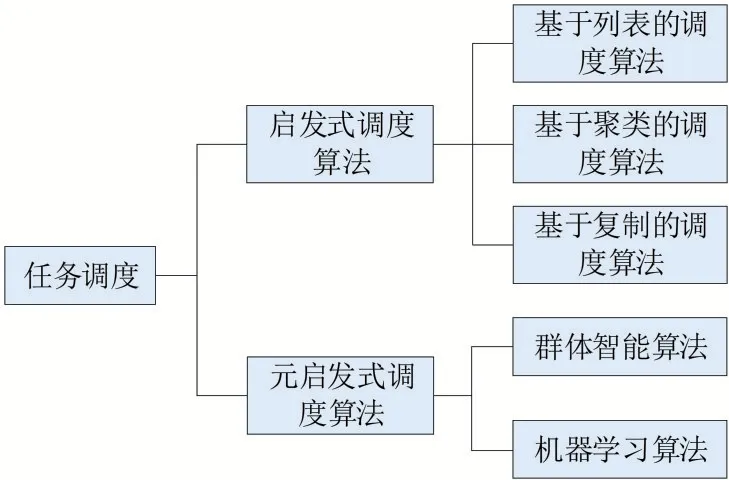
图1 任务调度算法分类
2.1 启发式算法
启发式算法的算法思想比较简单直观,它基于经验,在可接受时间内中给出待解决问题的一个可行解。启发式任务调度算法大致分为三类:基于列表的算法、基于任务复制的算法和基于聚类的算法。
2.1.1 基于列表的调度算法
基于列表的调度算法是当前研究最广泛的启发式算法,通常基于列表的调度算法包含两个主要阶段:第一阶段是列表优先级排序,基于优先级度量为每个任务分配优先级;第二阶段是任务映射,按照优先级和约束条件为每个任务匹配适当的物理资源。
其中最著名的就是异构最早完成时间算法(HEFT), 该算法思想对后来基于列表的调度算法产生了深远的影响。HEFT 首先计算各任务的优先级,然后按优先级进行排序并依次分配任务给最早空闲的实例上。传统HEFT算法通常考虑调度时延作为优先级排序的标准,但目前也有学者研究将HEFT 算法扩展到多目标空间,应对复杂的云边环境异构资源管理场景。文献[16]提出了FDHEFT 算法,将模糊优势排序机制作为优先级计算方式,实现了云雾环境中调度成本和完成时间的联合优化,但是对云雾节点间的通信和存储开销等考虑不够充分。传统的列表调度算法准确度高度依赖于任务基于硬件的执行前估计,而云边计算允许设备自由接入接出,硬件环境频繁改变,使得估计难以实现。当前研究对这一缺陷也有突破,文献[17]提出了SHEFT 算法,考虑资源数量可以根据服务请求弹性扩展,允许在调度过程中动态变化,实现了工作流的弹性调度,满足了实际云边环境下资源按需分配、弹性伸缩的应用场景,但是未能考虑云边异构的通信能力和边缘设备的管理。
除此之外,基于列表的调度算法研究的另一重要成果是处理器上关键路径算法(CPOP),该算法也对后续研究产生了深远影响。文献[18]对CPOP算法进行改进提出了新的调度算法CPOC,为关键路径任务分配一个硬件集群,更细粒度的资源分配进一步缩短了关键路径处理时间,但同时引入了任务间的数据通信开销,导致该算法不适用于云边下通信能力存在差异的场景。
2.1.2 基于复制的调度算法
为解决边缘节点计算资源、网络带宽、电池寿命受限问题,计算迁移技术应运而生,极大扩充了任务分配方案的选择:将终端的计算任务迁移到资源更为丰富的设备上、将云中心的计算下沉至边缘节点、对任务进行细粒度拆分并使用多个资源协同计算,计算迁移使得相互依赖任务在不同设备间的数据传输时延问题愈发严重。基于复制的调度算法通过冗余计算的方法来减少此类开销,优化调度。其主要方法是将具有数据依赖的任务分配给相同的实例单元来避免文件传输,从而减少任务间通信开销。
基于复制的调度算法分为两类:部分复制的调度(SPD)和完整复制的调度(SFD)算法。SPD 算法只允许复制关键路径上的任务,因此具有较低的时间复杂度,但是对于数据流较大的系统该方法并不适用。SFD 算法可以复制联接节点的所有父任务,并且可以将任务复制到包含联接节点的所有VM实例。这使得该算法具有更好的性能,但同时也提高了任务的复杂度。文献[19]提出了一种LSTD 算法,在不增加整体时间复杂度的情况下,引入任务复制策略,尝试在最早空闲的两个节点上插入任务,保障任务调度的可靠性,但是插入节点的选择可能会导致任务整体的执行时延增加。文献[20]提出了一种基于任务复制和插入的调度算法(DILS),结合动态完成时间预测,将部分任务复制到不同节点,并插入空闲时隙,以加快后续任务的执行。在不影响整体调度时延的前提下降低任务间通信时间,但是插入时隙的选择依赖于任务的预先估计,且会带来更高量级的时间复杂度。
2.1.3 基于聚类的调度算法
云边环境中,常常存在云、雾、边的设备差异性与地理位置差异性,各节点实例间存在通信开销差异。为了提高各数据中心内聚性、降低不同数据中心之间的耦合性,基于聚类的调度算法通过将存在大量通信的任务组合到同一个集合中并进行统一分配,从而实现云与边缘设备的低传输延迟,在多个数据中心之间保持负载平衡和有效的资源利用率。
文献[21]提出了一种基于任务聚类(HTTSC)的混合调度算法,巧妙地将任务聚类的方法与任务复制相结合。该方法首先根据任务间通信开销将任务聚类为多个簇,将任务复制的对象由单个任务转变为任务簇,缩短了通信开销,并提前了后续任务的开始时间,但是多种调度方法的结合也增加了调度算法的复杂性,在云计算实时调度场景下应用效果不佳。文献[22]提出使用显性序列聚类(DSC)将任务划分为不同的簇;使用内核函数均值漂移聚类(MSE)对虚拟机进行实例聚类,之后根据硬件权重和负载情况匹配节点簇与任务簇,该算法创新性地将任务和节点都进行聚类,减少了通信开销,但是每个任务均需要调用MHEFT 算法计算权重,导致该算法时间复杂度提高了一个量级。文献[23]提出了一种基于三路决策的聚类权重算法(TWCW),使用三向K-means 聚类将任务划分多个簇,并包含核心区域、边缘区域、模糊区域,根据聚类中心的属性偏好进行调度,使任务簇尽可能执行在适合的设备上,该方案显著提高服务质量(QoS),降低能耗。由于其简单的任务适配在多任务场景下导致负载不均,降低系统资源利用率,使得QoS下降。
2.2 元启发式算法
元启发式算法是随机算法与局部搜索算法相结合的产物。元启发式任务调度算法主要包括群体智能算法和机器学习算法。
2.2.1 群体智能算法
与基于贪婪的局部最优选择思想的启发式任务调度算法不同,群体智能算法是随机初始化和局部搜索算法相结合的产物,它规避了启发式算法针对不同问题实例产生不一致结果的问题,这类算法很大程度上参考了生物特性,具有很强的适应性。许多著名的元启发式算法已经得到了广泛应用,包括遗传算法(GA)、粒子群优化(PSO)、布谷鸟搜索(CS)等。但是,元启发式算法的搜索过程随问题的不同而变化,并且具有随机性大,全局搜索效率低以及后期迭代收敛过早的缺点。许多专家学者为改善这一不足进行了深入研究。文献[24]考虑了数据中心之间的带宽、边缘数据中心的数量和存储容量等传输时延影响因素,提出了一种带有遗传算法交叉和变异算子的自适应离散PSO 算法(GA-DPSO),避免了传统粒子群优化算法的早熟收敛,增强了种群进化的多样性,有效压缩数据传输时延,提高了系统服务质量。该方法通过固定部分任务与节点的映射关系规避了种群多样性多带来的搜索效率下降问题,但是该策略存在一定缺陷,限制了解空间,影响了调度结果。文献[25]提出了一种改进的多目标灰狼优化算法(IMOGWO),该方法维护一个非最优解外部存档,通过网格机制改进非最优解,领导者选择机制更新和替换外部存档,并且引入了个体密度和细胞支配概念动态调整自适应参数,并且以高斯扰动的经营学习策略缓解过过早收敛问题,该方法在执行时间和负载均衡指标上均有显著提升,但是该方法局限于独立任务调度,难以适用云计算多任务调度场景。
除此之外,亦有诸多研究人员考虑云边环境下的其他影响因素,在算法工程化过程中贡献出智慧。文献[26]针对云-雾环境下大规模异构并行结构资源利用率低、数据传输消耗网络带宽、终端请求对资源需求不同的特点,提出了一种改进的烟花算法(I-FASC),量化任务与资源并分类为计算、存储、带宽敏感型,将云边系统内各设备负载均衡作为优化目标,通过引入烟花爆炸半径检测机制,设置爆炸半径最小阈值及半径参数自适应的方式,提高算法局部搜索能力,改善算法整体效果。但是该算法以独热编码表示解空间,以欧式距离作为烟花间距忽略了任务-节点对的差异性,影响了算法的效果。
群体智能算法相比于启发式算法具有更高的时间复杂度,导致其很难适应于云边环境下实时调度场景。随着云边环境下虚拟化技术的发展,任务调度问题常常与虚拟机或容器的创建紧密相关。文献[27]在Kubernetes框架的基础上,研究了为Pod选择虚拟实例时的资源使用成本问题,将蚁群算法和粒子群算法相结合,对Kubernetes 调度模块进行了Pod 的节点部署优化。但多容器环境下任务存在资源竞争,许多学者为了研究的方便,对调度模型进行简化,常常忽略资源争用导致的执行结果干扰,导致群体智能算法研究中构造的适应度函数难以准确反应实际调度方案的真实性能。
2.2.2 机器学习算法
机器学习算法由于其时间复杂度问题,在云边环境下的任务调度领域的应用存在一些限制,但也取得了诸多成就。机器学习算法常用于预测应用执行情况,进一步指导调度算法,从而提高云边系统的资源管理能力与调度效率。
文献[28]将任务分类为CPU、Web、IO 密集型,使用主成分分析与回归分析提取、筛选并评估任务不同特征指标对系统总能耗的贡献,针对异构环境下不同设备的硬件信息,进行云边数据中心设备实例的能耗建模,为指导资源供应和虚拟机迁移做出参考。该论文考虑了多类任务在异构硬件上运行对能耗的不同贡献,对动态任务调度有重要意义,但是该方法要求预先获取大量任务特性,难以满足云计算实时性要求,具有一定的局限性。文献[29]中提出了一种基于ANN 的机器学习算法以实现高吞吐量的异构系统调度,该调度模型使用不同计算资源及其当前负载的统计信息预测下一个调度间隔中的任务行为,获得资源实例的服务能力最大化,并为每个资源实例训练两个模型提高预测算法的准确度。根据预测结果预先分配资源,并根据任务行为进行对应处理,显著提高系统的吞吐量,但是任务行为难以预测,模型预测准确度不高。文献[30]中作者通过在线学习的隐马尔可夫链模型,对工作流任务进行预测,并将筛选部分特征参数和预测结果进行在线训练,以此提高任务调度的精度,该算法在预测精度上有明显提升,改善了文献[29]预测精度差的问题,但引入了在线学习的时间开销,增加了调度模块的时空复杂度。
机器学习算法不但在任务估计中发挥重要作用,其中的分类算法亦可直接应用于任务调度。该类算法凭借其极强的适应性且具有在线学习能力等特点,在云边系统下的调度过程中,能够不断完善算法准确度,从而提高云边计算系统服务质量。虽然机器学习算法的时间和空间复杂度问题,限制了该算法在任务调度领域的表现。但是随着硬件算力的提升,这些问题正得到逐步缓解。机器学习仍然是当前云边环境下的任务调度研究的一大热点。
3 挑战与展望
诸多研究人员在调度算法领域取得了诸多成果,但是当前研究还存在多种问题。
3.1 虚拟化技术为调度算法带来诸多不确定因素
随着容器化技术的发展,为云计算带来轻量化的部署和资源管理的同时,也对任务调度提出了动态化要求,容器的迁移使得调度模块必须能够动态修改调度策略,此外容器化技术隔离性差的特点,也会导致当多个容器部署在同一虚拟机(VM)内,任务间存在相互干扰。虚拟化技术使得云边环境下的任务调度研究更加艰难。
3.2 云边环境下的调度策略难以实际验证
当前研究通常只通过模拟验证调度策略的有效性,例如使用CloudSim、iFogSIm 等软件建模和模拟整个云计算环境。调度策略通常是为管理大型云边环境中的大量应用程序而设计的,实际环境下的验证成本高昂、耗时过久。当前研究受限于研究环境,难以对调度方案进行频繁测试。
3.3 无服务器执行模型的兴起
无服务器计算是一种事件驱动的新兴云执行模型,其中云用户提供代码,云提供商管理该代码执行环境的生命周期。该执行模型提供更细粒度的资源分配,能充分利用分配的资源。同时也为任务调度带来了极大困难,细粒度的资源分配往往会导致当前基于任务与节点映射关系的传统调度算法研究失效。
云计算和边缘计算领域新技术的发展为任务调度带来了更多可能性,结合当前需求和技术发展进行分析,云边调度算法的后续研究可以从以下几个方面寻求突破。
(1)云边环境下自适应和智能化任务划分和任务调度。云边环境上应用的自适应划分和分配是未来一大发展方向。为了实现这种细粒度划分,需要感知与预测云边系统中的节点特性和运行状态。与当前基于完整任务的任务调度相比,自适应的细粒度任务划分能进一步降低用户的操作难度,提高任务执行效率并提升系统的负载均衡,是未来的一大研究热点。
(2)跨云环境下的任务调度算法研究。随着云用户数量和任务计算规模的急剧增加,在大型跨云服务环境中向用户提供资源将成为未来的重要方向。跨云环境为资源管理带来了更大的挑战,当前针对跨云环境满足服务质量(QoS)、负载均衡等调度目标的研究相对匮乏,特别是针对大规模计算密集型任务的调度研究尚处于起步阶段。
4 结语
本文叙述了云边环境下,任务调度算法的发展历程及未来挑战,其中,以启发式和元启发式算法为划分详细介绍了任务调度算法的研究现状, 在此基础上,对比和分析了当前各类算法的优势与不足,总结了当前云边环境下任务调度算法面临的挑战及未来发展方向,以期为该领域学者的后续研究提供参考。
