基于改进Deep LabV3+的图像篡改检测技术
2022-04-22刘旭
刘 旭
(四川大学网络空间安全学院,成都 610207)
0 引言
随着图像处理软件的广泛应用,人们可以在不需要专业技能的情况下对图片进行美化与修饰。这类软件在给人们生活带来便利和乐趣的同时,也带来了一个问题:图像篡改。现有的常用图像篡改方法有:复制粘贴、拼接和移除。复制粘贴是指篡改者复制图像中的某一特殊区域,然后粘贴到这幅图像的另一个区域。由于同一幅图像中的色彩、亮度等不会有明显变化,因此复制粘贴篡改一般很难被人眼察觉。拼接是指篡改者剪切图像中的某一区域,然后粘贴到其他图像中。由于两幅图像间色彩、亮度等的差异,因此拼接篡改区域和非篡改区域会存在明显的差异,通常篡改者会使用模糊,压缩等后处理方式消除这些差异。移除是指篡改者删除图像中的某一区域,然后利用区域周围的像素对删除区域进行填充。它和复制粘贴一样,都是操作同一张图像,因此篡改区域很难被人察觉。
针对网络中篡改图像泛滥问题,学术界进行了大量的研究。现有的检测方法主要分为两类:基于手工特征提取的传统检测方法和基于深度学习的检测方法。基于手工特征提取的检测方法依赖于人工选择和提取特征,耗费大量的人力、物力和时间,并且得到的特征向量鲁棒性也不够健壮。深度学习不仅能自适应从图像中提取特征,解决了特征工程的局限性,而且提取的特征向量具有更好的表征性,从而能实现更好的分类效果。现有的基于深度学习的方法虽然在模型的鲁棒性和准确性上有一定程度的优化,但深层网络中篡改特征丢失,导致现有方法对小尺度篡改区域检测性能不佳,存在较高的漏报率,并且连续降采样使得特征图分辨率不断减小,篡改区域边缘特征丢失,导致现有方法无法精确定位篡改区域。
针对现有主流图像篡改检测方法存在的问题,本文提出并实现了一种改进DeepLabV3+算法的图像篡改检测模型。首先基于约束卷积层设计了一个可学习多种篡改特征的特征提取器,用于自适应提取多种篡改特征;其次使用不同步长的可分离卷积代替池化层和利用空洞卷积在不改变特征图大小的同时,扩大感受野,提取更有效的篡改特征;利用多级跳层结构融合低级特征和高级特征,精细化定位区域;最后利用CBAM关注篡改特征抑制非篡改特征,减少篡改特征在深层网络中消失并且利用ASPP模块融合不同采样率的空洞卷积提取的特征,提取多尺度特征,改善了现有模型对小尺度篡改区域检测不佳的问题,提高了检测的准确率。
1 算法实现
本文提出了一种基于改进DeepLabV3+的图像篡改检测模型,如图1所示,模型主要由可学习的特征提取器,ASPP模块和特征融合模块组成。首先利用可学习的特征提取器捕获由篡改操作导致的相邻像素之间关系的变化特征,其次利用ASPP模块提取多尺度特征以增强对不同尺度篡改区域的检测性能,然后特征融合模块融合多级特征以增强全局特征表示,最后使用SoftMax分类器进行逐像素分类,定位篡改区域。

图1 基于改进Deep LabV3+的图像篡改检测模型结构
1.1 可学习的特征提取器
为了抑制图像的语义信息并自适应学习丰富的篡改特征,本文基于约束卷积层、空洞卷积和CBAM模块设计了一个可学习的特征提取器。约束卷积层通过提取像素残差特征抑制图像语义信息,将像素残差输入到主干网络自适应学习由篡改操作导致相邻像素之间关系的变化特征;空洞卷积在不改变特征图分辨率大小的前提下,扩大感受野,保留了更多细节特征;CBAM模块从空间和通道两个不同的维度计算注意力权重,关注篡改特征抑制非篡改特征,强化对篡改特征学习能力,缓解篡改特征在深层网络中的消散问题。
约束卷积层位于特征提取器的第一层,用于提取像素残差特征抑制图像语义信息。特征提取方法公式(1)所述:

其中上标表示CNN的第一层,下标表示层内的第个卷积核,卷积核的中心点值为-1,其余所有值之和为1。
尽管约束卷积层能捕获丰富的篡改信息,但在DCNN中为了增加感受野并降低计算量,需要进行连续降采样操作,这就使得特征图分辨率降低,损失了一部分细节特征,导致现有方法无法精确定位篡改区域。为了解决这个问题本文使用空洞卷积在不改变特征图分辨率大小的前提下,扩大感受野,提升了模型的定位精度。在二维空间上对于位置,在输入上使用卷积核进行卷积,输出为:

其中是卷积核大小,速率在采样点之间引入-1个零,将感受野从扩大到(+(-1)×(-1)),而不增加参数和计算量。
随着网络结构的深入,篡改特征在深层网络中的弱化问题导致模型漏报率较高。为了降低漏报率本文引入CBAM模块沿着空间和通道两个不同的维度依次推断出注意力权重,然后与原始特征图相乘来对特征进行自适应调整,把更多的权重分配给篡改特征,达到关注篡改特征,抑制非篡改特征的目的,有效缓解了特征弱化问题。如图2所示,其中⊗表示逐元素相乘。

图2 CBAM体系结构
1.2 ASPP模块
为了检测出多尺度篡改区域降低漏报率,本文利用ASPP模块来提取多尺度特征。ASPP模块采用不同比例的并行空洞卷积来挖掘不同尺度的篡改信息,如图3所示。ASPP模块由四个并行的空洞卷积和一个全局最大池化组成,其中四个并行的空洞卷积分别为1个1×1的空洞卷积,3个3×3的空洞卷积,膨胀率分别为(1,6,12,18)。最后将不同尺度的特征图合并后输入到特征融合模块。
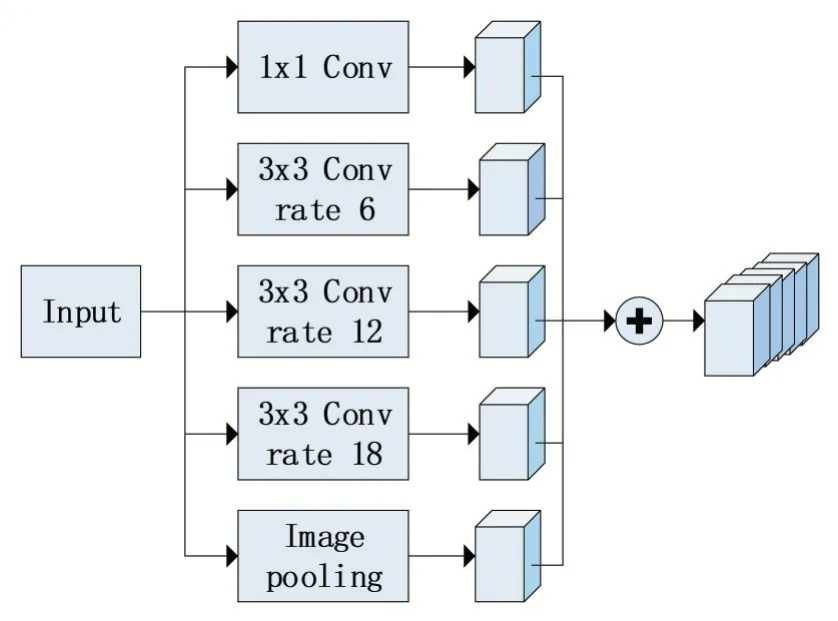
图3 ASPP体系结构
1.3 特征融合模块
为了捕获到更丰富的细节特征,实现更精确的定位,本文对主干网络的最后三个模块都进行跳跃连接。网络输入一张(512,512,3)的图片,三级跳层和ASPP模块的输出分别为:(128,128,256)、(64,64,256)、(32,32,728)和(32,32,1280)。融合模块如图4所示,由于这些特征中包含大量的通道,使网络训练变得更加困难,所以分别对这四个特征进行1×1的卷积降低通道数。然后对后面三个特征分别进行2倍、4倍和4倍双线性上采样得到相同的特征大小,接着将这4个相同大小的特征图拼接在一起。拼接后,使用3×3的卷积来细化这些特征,然后进行4倍双线性上采样还原回输入特征图大小。最后使用SoftMax逐像素进行分类。

图4 特征融合模块结构
2 实验
2.1 实验环境
为了使网络具有较强的泛化能力,本文选择四个公开数据集大约50 K篡改图像作为网络训练集,每个数据集都提供篡改图片和二进制掩码,具体细节如表1所示。

表1 训练数据集信息
表1中篡改方式一列中C表示复制粘贴篡改,S表示拼接篡改。表二中R表示移除篡改。
为了证明提出的篡改检测方法的通用性,本文选择了四个公开可用的数据集作为测试数据 集:NIST16、CASIA、COLUMBIA和COVERAGE数据集,具体细节如表2所示。

表2 测试数据集信息
表2中CASIA数据集是指:CASIA 1.0数据集有921张图片,CASIA 2.0有5123张图片。
为了在测试数据集上微调模型,本文参考[1]对测试数据集进行划分。CASIA 2.0用于训练,CASIA1.0用于测试,COLUMBIA仅用于测试,具体细节如表3所示。

表3 四个标准数据集训练和测试集划分
本文在tensorflow平台上实现了基于改进DeepLabV3+的图像篡改检测模型。在模型中,首先将所有图像调整为512×512×3的标准尺寸作为网络的输入,然后使用均值为0,方差为0.01的高斯分布初始化网络权重,接着使用Adam优化器进行训练,初始学习率为1e-3,使用交叉熵记录模型的损失,在训练过程中测试集损失两次不下降就将学习率降低为原来的0.1倍。本文的所有实验均在NVIDIA GTX 1080 Ti GPU上进行。
2.2 实验结果分析
本文在像素级别使用查准率(precision)、召回率(recall)和1分数来评估实验性能,将提出的方法与现有的基准模型进行比较,这些基准模型包括传统的无监督方法ELA和NOI1和最 新 的 基 于DNN的 方 法:HLED、Man⁃TraNet和RGB-N。实验结果如表4所示。

表4 四个标准数据集上precision比较
表4、表5和表6分别展示了本文方法与基准方法在四个标准数据上precision、recall和1的比较,其中DLV3+表示基于DeepLabV3+的篡改检测方法。上述结果中ELA、NOI1、HLED和ManTraNet是运行代码后的到的结果,RGB-N是直接从原文复制而来。
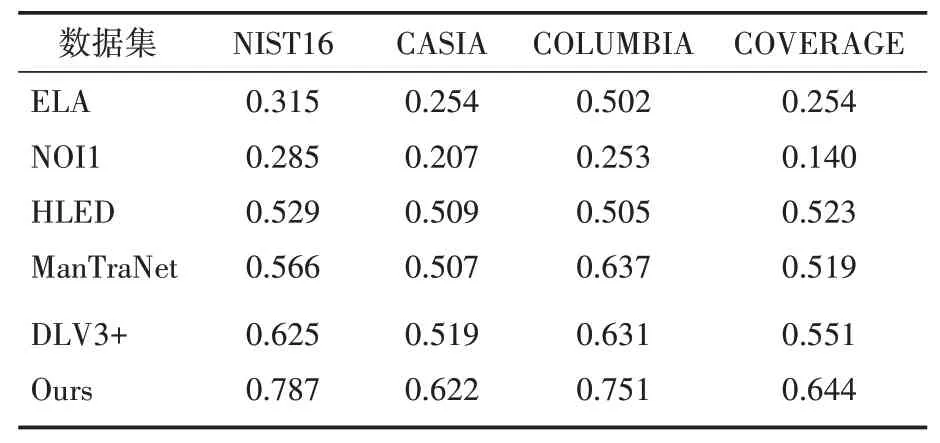
表5 四个标准数据集上recall比较

表6 四个标准数据集上F1分数比较
从实验结果可以发现,基于深度学习的检测方法明显优于基于手工特征的传统检测方法,如ELA,NOI1。这是因为传统的检测方法需要人工选择和提取特征,这些特征都倾向于检测单一篡改类型,并且模型的准确率依赖于特征工程。本文提出的模型优于现有的基于深度学习的方法,如:HLED,RGB-N和ManTraNet。这是因为HLED利用重采样特征、RGB-N利用噪声域特征捕获篡改区域和非篡改区域不一致,这些手工设计特征和传统检测类似都倾向于检测单一篡改类型。与RGB-N相比本文提出的模型在四个公开数据集上1分数提高了0.092、0.234、0.091和0.238,增长率分别为12.7%、57.4%、13.1%和54.5%。
图5展示了本文提出的方法与基准方法在部分测试数据集上的篡改区域定位图。其中R表示移除篡改、S表示拼接篡改、C表示复制粘贴篡改,图像中黑色像素表示真实区域,白色像素表示篡改区域。从实验结果可知本文提出的方法不仅能有效检测出移除、拼接和复制粘贴三种篡改类型的图像,而且能更精确定位篡改区域,最后一组图像说明了本文提出的方法适用于小篡改区域和多篡改区域的检测。

图5 测试数据集上篡改区域定位图
3 结语
本文提出了一种基于改进DeepLabV3+的图像篡改检测模型。首先可学习的特征提取器能自适应从图像中提取多种篡改特征;其次利用CBAM模块关注篡改特征抑制非篡改特征,缓解深层网络中篡改特征消失问题,利用ASPP模块提取多尺度篡改特征;最后利用特征融合模块融合低级特征和高级特征获得更精细化的定位结果。在几个公开数据集上结果表明,本文提出的方法优于现有的主流方法。
