基于RoBerta-BiLstm-Attention模型的机器生成新闻检测
2022-04-22徐宇,杨频
徐 宇,杨 频
(四川大学网络空间安全学院,成都 610065)
0 引言
随着深度学习技术的快速发展,NLP的研究取得了长足的进步,GPT2、Ctrl、Bert和RoBerta等预训练语言模型得到了广泛的应用。在文本生成的研究中,逐步将预训练语言模型融入其中。现在预训练模型生成的文本已经可以做到与人工撰写的文本极其相似,甚至可以生成逻辑清晰的新闻报导,这有利于新闻的快速生成和及时传播。同时,恶意攻击者也可能采用同样的技术生成具有攻击性的虚假新闻报道,以实现网络舆情的控制。为了防止文本生成的预训练模型用于网络媒体攻击,机器生成新闻的检测是必不可少的。
现在人工检测机器生成新闻无论是从费用还是时间来说都是十分昂贵。通过自动机器生成新闻的检测,可以减少人工检测的压力同时也可以提高检测机器生成新闻的效率和准确率。
1 相关研究
文本生成语言模型和算法在近几年的快速发展,基于GAN和VAE的算法不断改进用于文本生成,比如SeqGAN、LeakGAN,以及基于transformer的大型预训练语言模型已经能够生成效果很好的文本,甚至生成逻辑清晰的新闻报导,比如Grover称已经能够生成比人工虚假新闻更加可信的假新闻。
机器文本生成检测模型已经发展了很多年,早期研究人员主要针对的是无人工校对的机器翻译文本以及使用同义词或者混淆技术生成的文本。使用的方法都是基于传统机器学习,分析机器文本和自然文本之前不同的特征。比如词频计数,通过机器文本与自然文本之间的词分布进行检测;语言特征通过虚词密度、语句长度等语言特征进行检测;短语分析通过短语沙拉现象对机器翻译文本的检测。
但是近两年大型语言模型日益强大,机器生成的文本越来越逼真,导致研究人员对于其检测有了很多不同想法。Gehrmann很精确的找到了GPT2模型根据前面单词预测下一个词的特点。采用统计学的方法将文章中的每个单词的topK概率进行标注统计来协助专业人员检测机器生成新闻。但它的检测准确率可能会受到生成模型解码策略和生成模型训练样本来源的影响。这在Ippolito的实验中得到了很好的证明。当检测的自然文本与训练生成模型的文本来自同一分布时,Gehrmann提出的方法检测准确率就接近于随机概率。Ippolito主要的方法是微调的Bert对生成文本进行检测,在通过核采样生成的文本下实验准确率从接近随机的55%增加到大约81%。对于解码策略的影响,Holtzman分析了人工撰写文本和机器文本分布的差异,并指出传统解码方式的会出现不连贯和陷入重复循环。为了解决这个问题他们提出了核采样(topP)的解码方式。但是我们的实验结果中表明在长文本的生成过程中表达不连贯并没有得到很好的解决。
目前一些研究人员认为检测机器生成文本最好的方法是文本生成模型自身,比如GROVER通过生成模型对自身生成的新闻进行检测并和微调的Bert-large模型进行对比,得出了单向transformer模型精确度高于双向trans⁃former模型精确度的结论。但是Solaiman等人认为同等大小的双向transformer模型比单向的transformer模型检测的准确率更高,并通过微调的RoBerta模型对不同解码策略的生成文本进行实验,得出了不同的结论并发现核采样(topP)的生成文本更难以检测。
2 检测模型
本文提出一种基于RoBerta-BiLstm-Attention的机器生成新闻的检测模型,如图1所示。
RoBerta相对于Bert做了一些调整。将Bert的静态masking调整为动态masking,直到每一次将训练样本输入到模型时,才进行随机的掩码。将Bert的wordpiece分词算法调整为BPE算法,从相邻子词中选取频数最高的两个子词合并。使用更多的数据和更大的批次训练,可以更好的提高词嵌入的质量,有利于我们提取出高质量的语义信息。我们将输入样本前后都加入了[cls]和[seq]两个特殊的标志,如图1所示。

图1 RoBerta-BiLstm-Attention模型结构
BiLstm层中包含了一个前向Lstm和一个后向的Lstm,分别用于学习RoBerta词嵌入后的上下文信息。Lstm通过遗忘门、记忆门和输入门计算隐藏信息。在时刻,遗忘门和记忆门计算公式如下:
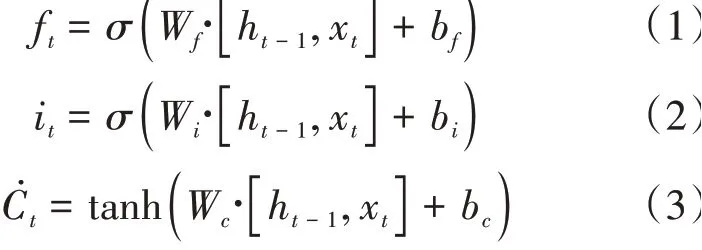
h是前一时刻的隐藏状态,x是当前时刻输入的词嵌入信息,输入是遗忘门的值f,记忆门的值是i,临时结点状态值̇。再计算当前时刻结点状态信息。计算公式如下:

其中f是遗忘门,i是记忆门,̇是临时结点状态,C是上一时刻的结点状态信息。最后计算当前时刻的隐藏信息,计算公式如下:
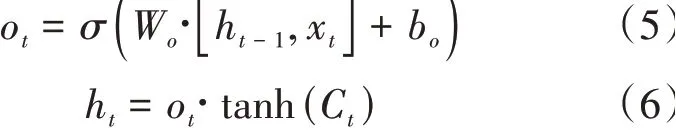

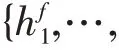
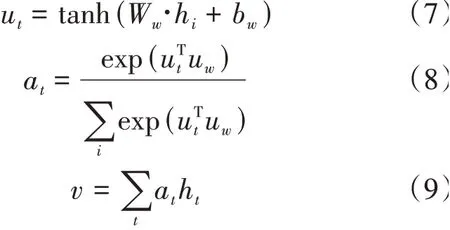
3 实验及分析
3.1 数据集
由于缺乏公开可用的机器生成新闻数据集,我们爬取了CNN、ROUTER和BBC的200M的新闻数据集对GPT2-large预训练模型进行了微调来生成新闻数据集FakeNews。生成模型中我们分别采用了topK=40结合topP=0.96以及topP=0.96解码方式生成新闻,生成新闻中各选取了32000条。为了让生成新闻与真实新闻满足同一分布,我们按照1∶1的比例在训练GPT2-large的语料中选取了真实新闻文本。本文使用了3∶1∶1的比例划分训练集、验证集和测试集,如表1所示。

表1 机器生成新闻数据集的划分
3.2 对比实验
我们使用的主要方法是RoBerta-BiLstm-Attention,并在两个不同解码方式生成的数据集上进行了测试。每一篇新闻的最大长度是510,我们将RoBerta-BiLstm-Attention与其他一些基线分类模型进行了对比。
RoBerta-BiLstm将RoBerta获取新闻的词向量结果,同时输入到Bilstm网络中,最后的结果获取前向最后结点和反向第一个结点的隐藏状态拼接值,输入线性层得到最后的预测结果。
Fine-tuned RoBerta将RoBerta-base模型进行了微调,模型同样被训练了10个epoch,batchsize设置为32。
Bert-BiLstm-attention将roberta模型换成了bert进行了实验测试,参数设置和RoBerta-Bilstm-attention模型完全一致。
BiLstm将新闻数据集使用scapy进行分词词嵌入(维度300),训练了一个基于BiLstm的二分类模型。
对比实验还做了常用分类算法FastText、TextCnn和TextRnn。
3.3 实验分析
本文以广泛使用的准确率(Accuracy,)、召回率(Recall,)和1值(F-score)作为评价标准。准确率是正确预测的新闻数量与所有新闻数量的比值;召回率是机器生成新闻中被预测为机器生成新闻的比例;1值是指精确率和召回率的调和平均数。实验结果如表2和表3所示。与传统的深度学习算法相比,RoBerta-BiLstm-Attention在解码策略是核采样(top)时准确率、1值和召回率都提高了13%以上。同时传统的深度学习算法受识别序列的长度影响很明显,当解码策略是核采样(topP)时且长度减少到125时,检测的准确率和1值不到80%,但是RoBerta-BiLstm-attention准确率和1值都在95%左右。

表2 top K生成新闻实验结果(A是准确率、F是F1值、R是召回率)/(%)

表3 核采样生成新闻实验结果(A是准确率、F是F1值、R是召回率)/(%)
与同类型深度学习模型相比,在序列长度为510和250时,我们发现RoBerta-BiLstm-Attention框架的提升不明显,在topK生成的样本下存在轻微劣势。于是我们对于机器生成新闻进行了人工分析,发现GPT2-large在生成序列过长的新闻时,会出现一些很明显的特征。比如前后文主题性出现偏差、有重复的语句以及一些比较明显的语法错误。这些错误很容被捕捉,所以模型的提升不会很明显。如图2所示。

图2 语句重复和前后语义偏差
在序列长度为125时,GPT2-large生成新闻的错误更加难以捕捉,所以检测的准确率、1值等会出现下降趋势。但是Roberta-Blistm-Attention相比于目前最强大的Roberta,在top生成的样本下1值和准确率都提升了近2%,召回率提升了5.56%。在top生成的样本下1值和准确率都提升了4%以上。如图3所示。

图3 机器生成新闻的检测准确率(%)
为了验证Attention机制对机器生成新闻检测性能的提升.我们对比了未引入Attention层的RoBerta-BiLstm模型和引入了Attention层的RoBerta-BiLstm-Attention模型的检测效果。在加入了Attention机制、解码策略为topP和序列长度为125时,模型的准确率和1值分别提升了0.95%、0.84%。在序列长度为250时,模型的准确率和1值分别提升了1.21%,1.16%。实验结果表明,引入了attention后模型的检测性能都得到了提升。
为了验证RoBerta对于识别机器生成新闻性能的提升,对比了使用同等规模大小的Bert的识别效果。如图4所示,无论序列长度为多少,在样本采样方式为topP时,加入Roberta层后,模型的准确率、召回率和1值都提升了5%左右。实验结果表明,引入Roberta模型后能够识别出更多的机器生成新闻。

图4 RoBerta-BiLstm-Attention和Bert-BiLstm-Attention数据对比(top P)
4 结语
本文针对目前可能存在滥用的机器生成新闻,提出了一种Roberta-BiLstm-attention模型,用于自动检测机器生成新闻。区别于传统的深度学习检测方法,我们使用了Facebook最新的模型RoBerta做词嵌入,能够有效的消除歧义,提高词嵌入的表达质量。相比于同等类型的Bert,RoBerta的使用让模型的各个指标都得到了很高的提升。同时引入了BiLstm捕获文本的前后向语义表达和注意力机制选择性捕获序列的关键信息,以提升机器生成新闻的检测效果。实验结果表明目前大型语言模型生成文档级文本时,仍然存在着很多不尽人意的表现,这对于大规模滥用来说是一个很好的现象。但是对于NLP的文本生成的发展来说,仍然是一个难以解决的难题。同时我们提出的模型各个指标都比目前的方法更高,但是模型的结构也是越来越复杂。在未来的研究工作中,我们将进一步简化模型结构,提高模型的检测质量。
