一种融合多层次卷积的视频压缩伪影去除方法
2022-04-21汤博文吴晓红何小海陈洪刚熊淑华
汤博文,吴晓红,何小海,陈洪刚,熊淑华
(四川大学 电子信息学院,四川 成都 610041)
0 引言
传统的编解码标准如H.264和H.265通过去方块滤波和样点自适应技术对压缩视频质量有一定提升作用,但实际取得的视觉提升效果却很有限。
超分辨率技术可使图像呈现更好的观感,即展现更多细节信息。基于卷积神经网络的超分辨率方法[1-3]可以实现较传统方法更高质量的图像超分辨率。VRCNN[4]创新性地采用视频帧连续性的特点,通过输入多帧图像对当前视频帧进行超分辨率。
传统的图像去噪技术大多采用线性或非线性的滤波器如高斯滤波器[5]或域变换加权[6],难以实现多种噪声同时去除。基于学习的噪声去除方法[7-8]却能很大程度上规避这一缺点,具有一定泛化性。基于自适应分割块的变换神经网络ASN[9]和多帧视频质量增强网络MFQE[10]先后被提出,其中前者利用H.265中块编码的CU分块信息来增强对压缩伪影的去除效果,而后者则利用视频帧间相关性的特点,实现多帧输入的质量增强。
大多数的视频质量增强方法存在一定局限性,一些方法聚焦于单帧的视频增强方法,强调采用图像的质量增强手段,而忽略了视频帧之间的时间相关性和空间相关性;同时,有方法考虑将CU信息融合进质量增强部分,但效果仍不理想;还有一些方法利用了帧间相关性的特点,但是却忽略视频解码帧的低质量特点,未考虑不同尺寸压缩伪影的影响,使得特征提取不符合分布特性,导致最终的增强帧效果不明显。本方法考虑到以上因素,提出了一种多帧注意力质量增强网络MLAN,主要创新点如下:① 采用从全局到局部的层层递进的4层运动补偿网络,使得多尺寸压缩伪影被感知,从而增强运动匹配的准确度,使得补偿帧的分布特性更符合后续网络要求;② 同时引入空间注意力和通道注意力机制加强对特征图的全方面特征提取,将各个维度的关键部分进行强化,从而达到更充分的特征提取效果;③ 利用残差学习和密集连接的特点,在对特征进行深层映射的同时避免了梯度消失,加快训练速度,进而实现压缩伪影的强抑制,并极大地保留视频帧原有细节信息,改善视觉观感。
1 多帧注意力质量增强网络
压缩视频中主要存在量化噪声,所以本文所提方法旨在对HEVC压缩解码视频进行质量提升。考虑到视频帧之间存在强相关性,采用多帧输入的结构实现去除当前帧中存在的压缩伪影的目的。图1所示为本文的卷积神经网络框架,将首先对压缩伪影产生的原因进行分析建模,进而解释本文对压缩伪影去除所采用的主要方法。
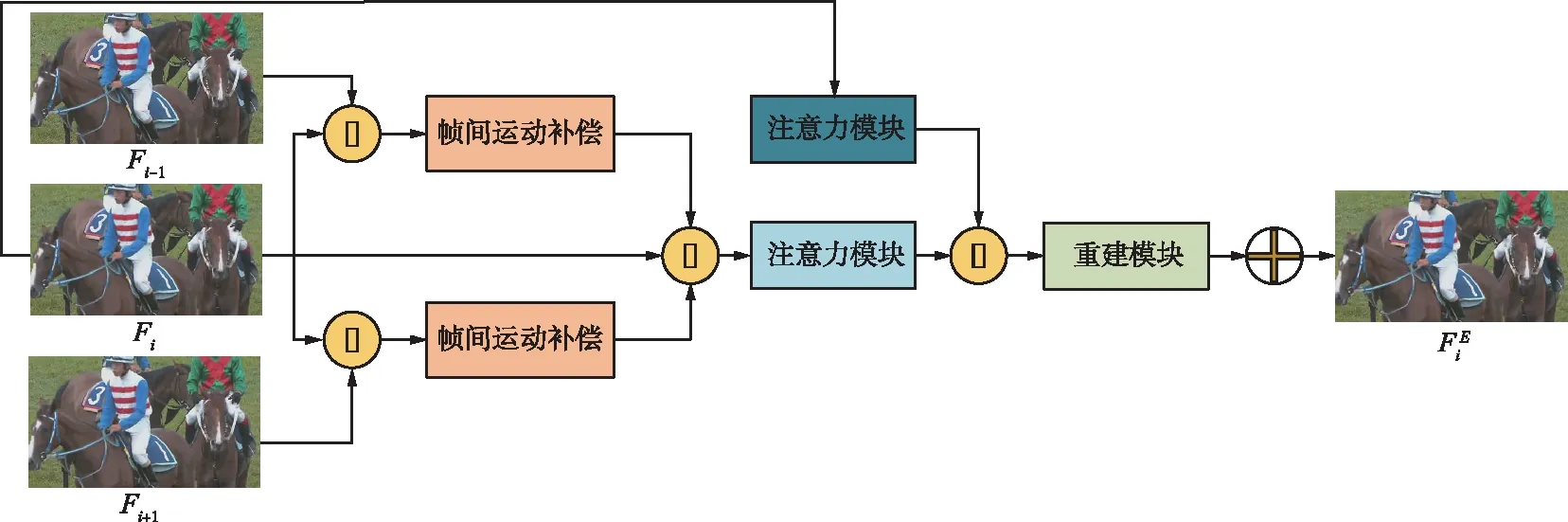
图1 多帧注意力质量增强网络框架
1.1 任务框架
压缩伪影的产生是因为在压缩过程中需要对视频用设定的量化步长进行数据压缩,故产生量化误差。在解码端,由于量化误差的存在,还原图像时甚至会放大量化误差,使图像产生压缩伪影导致失真。视频压缩过程可表示为:
(1)
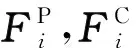
(2)
1.2 帧间运动补偿网络
如图1所示,由于输入为当前帧及其前一帧和后一帧,所以需要采用一种帧间信息提取网络来获得帧间的运动矢量信息,进而对前一帧和后一帧进行补偿得到当前帧的2帧运动补偿帧,进而扩充质量增强部分的输入数据量。一些基于卷积神经网络的光流计算方法如FlowNet[11]和FlowNet2.0[12]可以较准确地将图像内的连续视频序列间的光流信息提取出来,而这种光流信息的提取同运动信息提取有很大的相似性,但是一般的光流网络又不能很好地满足运动矢量提取的准确度要求,所以本文设计了一种如图2所示的针对HEVC压缩视频的帧间运动补偿网络。通常的运动矢量提取由单层卷积神经网络组成,但是由于HEVC压缩视频帧质量较低并且受到方块效应等影响,块大小随着图像区域质量不同而不同,所以利用单层卷积神经网络的效果不佳,而金字塔型运动补偿网络STMC[13]则利用由全局到局部的特征提取思想实现更精准的运动补偿效果。
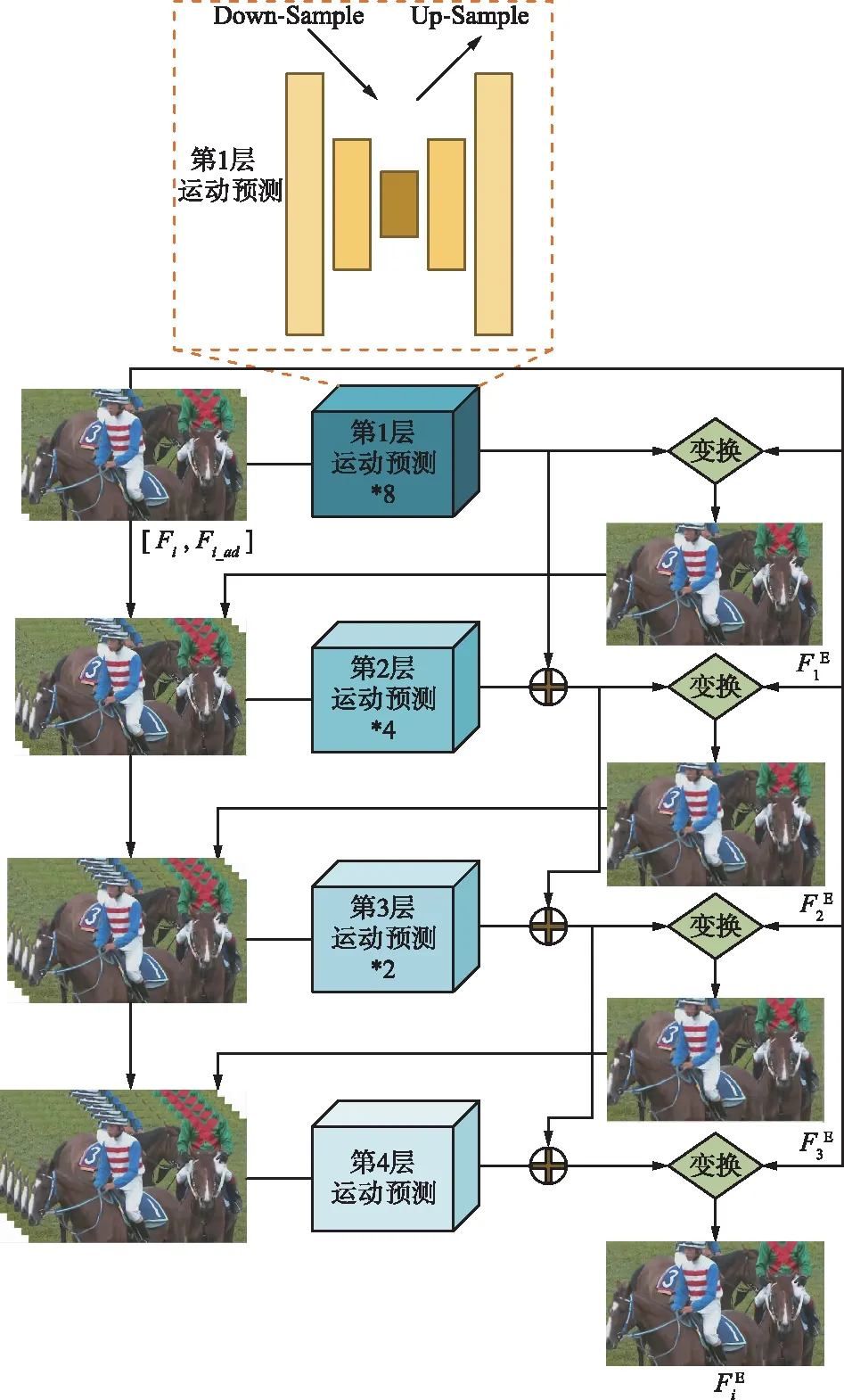
图2 多层次运动补偿网络
考虑到HEVC压缩视频的低质量重建视频帧,本文将金字塔型运动补偿网络的特征提取深度提高,使得全局信息的提取效果更佳,并能更好地克服方块效应的影响。为了避免梯度消失还通过残差学习的思路将全局提取学习到的运动矢量结果不断添加到之后的更局部的特征提取部分,从而融合学习局部和全局的像素分布情况,更好地克服压缩伪影大小的影响,运动补偿网络计算过程可表示为:
(3)
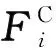
(4)
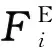
,
(5)
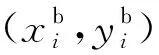
第1层运动预测部分的具体构造如图2所示,每层下采样由2层卷积层组成,分别起到特征提取和下采样的作用,均为3×3大小卷积核。该部分将当前帧以及当前帧的相邻2帧分别输入2个运动补偿网络得到2个补偿帧作为之后部分的输入数据。
1.3 融合注意力机制的特征提取与重建
注意力机制是一种有效的特征提取手段,主要分为通道注意力[15]和空间注意力[16]2种。通道注意力机制将卷积过程聚焦到特征图的通道上,通过对各个通道采取基于学习的加权方法,在特征图中比重较大的通道赋予更大权值,比重较小的通道赋予更小的权值,可以表示为:
(6)
式中,X表示某一通道的特征图;xi为该特征图内任一点;P为本网络通道特征提取强化部分;δ为Sigmoid函数;Y为通过加权后的特征图。Sigmoid函数表达式为:
(7)
通道注意力可以很好地区分通道和通道之间的重要程度,但是单个特征图中特征点之间的区别度和相关性并不能很好地被表示,而空间注意力机制可以很好地解决这一问题。通过专注于对特征图内的特征点的加权,将对损失影响更大的特征点赋予更大权值,对影响较小的赋予更小权值,可以表示为:
(8)
式中,X为某一特征图;xi为各个通道特征图上相同位置的特征点;xmax为各个通道特征图上相同位置的最大值特征点;cat是级联操作;P为本网络的空间特征提取强化部分;δ为Sigmoid函数;Y为通过加权后的特征图。因为通道注意力机制和空间注意力机制针对的作用维度不同,所以先进行一种注意力操作后的特征图在其他维度上的概率分布并不会改变。考虑到空间与通道维度作用域的独立性,采取串联注意力机制对视频帧进行特征提取,该部分配置如表1所示。考虑到网络任务是针对当前帧进行质量提升,所以对当前帧进行额外的像素分布学习,采取同样的串联机制,使得两部分训练阶段具有相似性。融合注意力机制如图3所示。
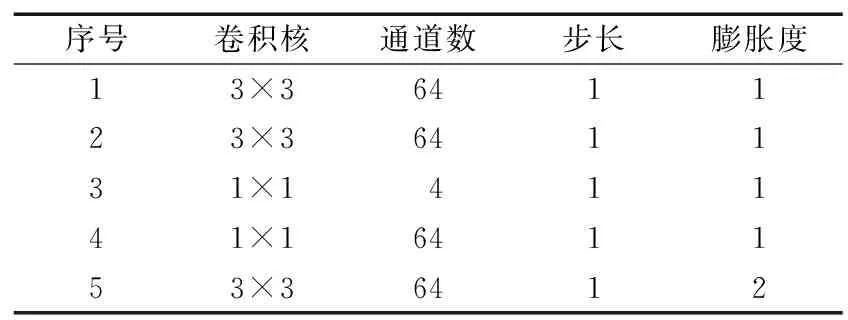
表1 融合注意力机制卷积层参数
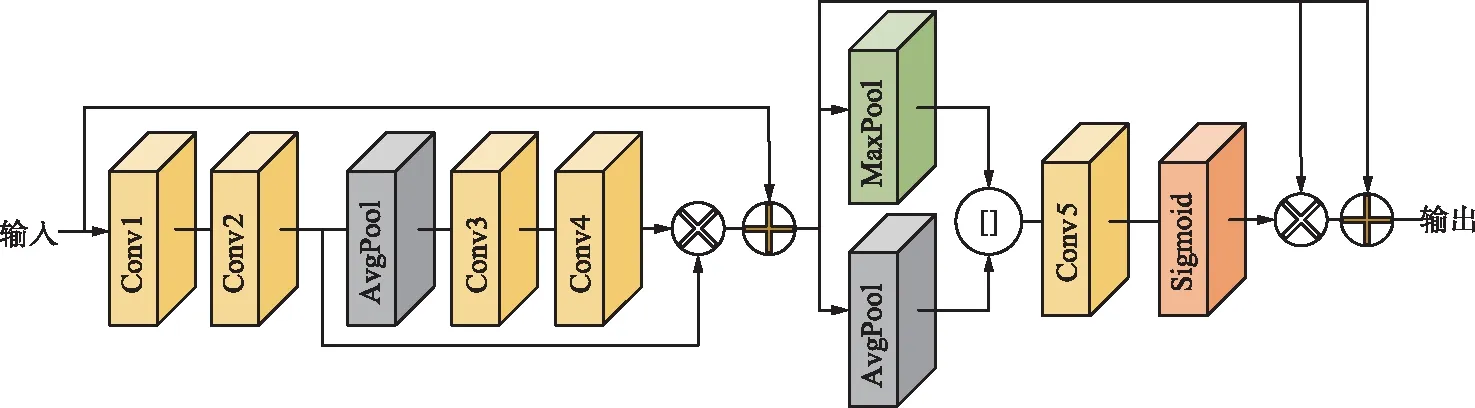
图3 融合注意力机制
在获得融合注意力机制的输出特征后还需要对特征进行映射和重建,考虑到残差学习[17]在抑制梯度弥散方面的优势,以及DenseNet[18]在特征融合方面的优点,选择在此部分构建如图4所示的密集和残差连接,其中所有卷积核均为3×3,且激活函数均为ReLU。该部分每一层的输出特征图都将在级联融合后作为最后2层卷积层的输入,将图像重建为目标通道数量。
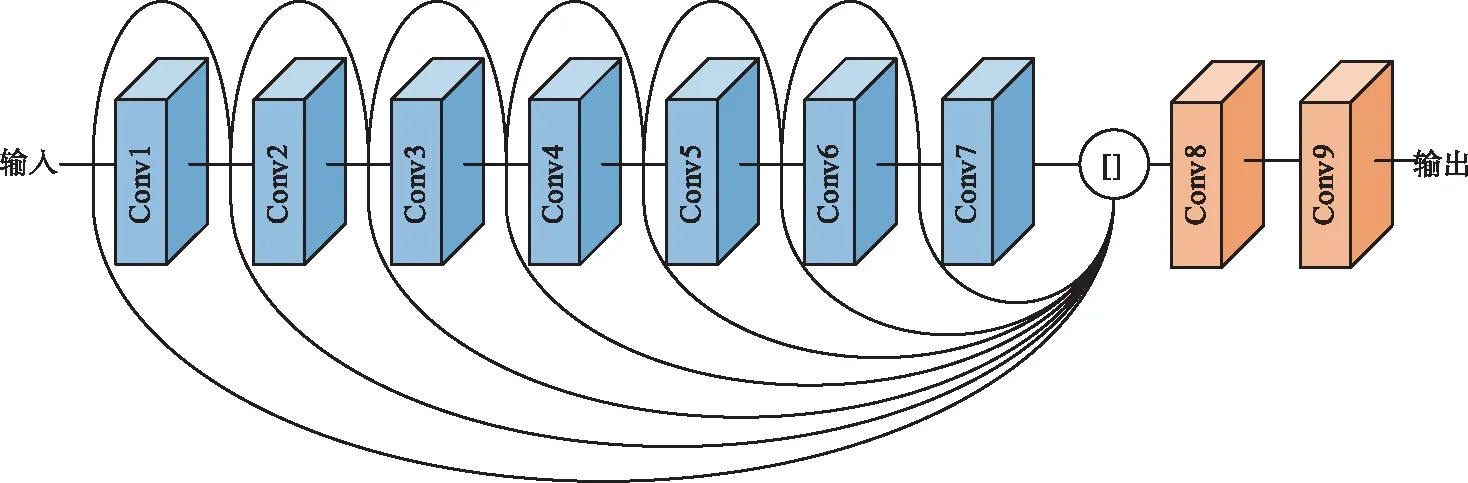
图4 特征映射与重建
1.4 损失函数
损失函数对于卷积神经网络非常重要,其收敛特性关系着网络参数的学习速度和效果,本文方法参考文献[19]中对于损失函数的结论,因平均绝对误差损失在细节边缘表现上更具优势,同时均方差损失有利于学习速度,故分别选取平均绝对误差损失(MAELoss)和均方差损失(MSELoss)作为损失函数,可表示为:
Lp=λ1LMAE+λ2LMSE=
(9)
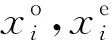
2 实验结果与分析
2.1 训练环境与配置
本网络的训练集采用Vimeo90K[20]数据集,数据集内均为7帧连续视频序列。为得到压缩视频训练集,本文将Vimeo90K所有连续视频序列图像处理为YUV格式序列后采用HM16.0进行编解码,包含环路滤波步骤。为了方便网络数据输入和后期主观效果观察,将压缩后的视频序列分解为RGB格式,所有的图像视频转换均遵循ITU-R和BT.601标准。实验模型均在英伟达GTX 1080Ti显卡上运行。训练选用Adam优化器,学习率为1×10-5,训练后期下降为5×10-6,单个训练组为6个视频序列(即包含42个视频帧)。
2.2 客观质量分析
本实验中采用客观评价指标峰值信噪比(PSNR)和结构相似度(SSIM)作为评价标准,PSNR和SSIM越大越好,且SSIM取值为-1~1。验证集选取视频编码联合小组(JCT-VC)发布的视频序列[21],同时选取DCAD[22],DS-CNN[8],MFQE[10]和MFQE2.0[23]作为实验效果对照。通过参考文献[19]对损失函数的权值进行调整,本文将权重调整为大权值的平均绝对误差损失及小权值的均方差损失。
本文方法与其他方法的性能比较如表2所示,通过本方法进行增强的视频帧质量在PSNR评价指标下,当QP=37时,平均增加约0.68 dB,在序列FourPeople上达到约为1.08 dB的最高提升。在与其他方法对比时,本文方法较DCAD,DS-CNN,MFQE和MFQE2.0分别提升0.37,0.39,0.24和0.14 dB。在BQSquare视频序列上较MFQE2.0最高提升0.58 dB。在SSIM评价指标下较标准HEVC编解码后视频平均提升0.011 1,获得较其他方法更大的提升量。
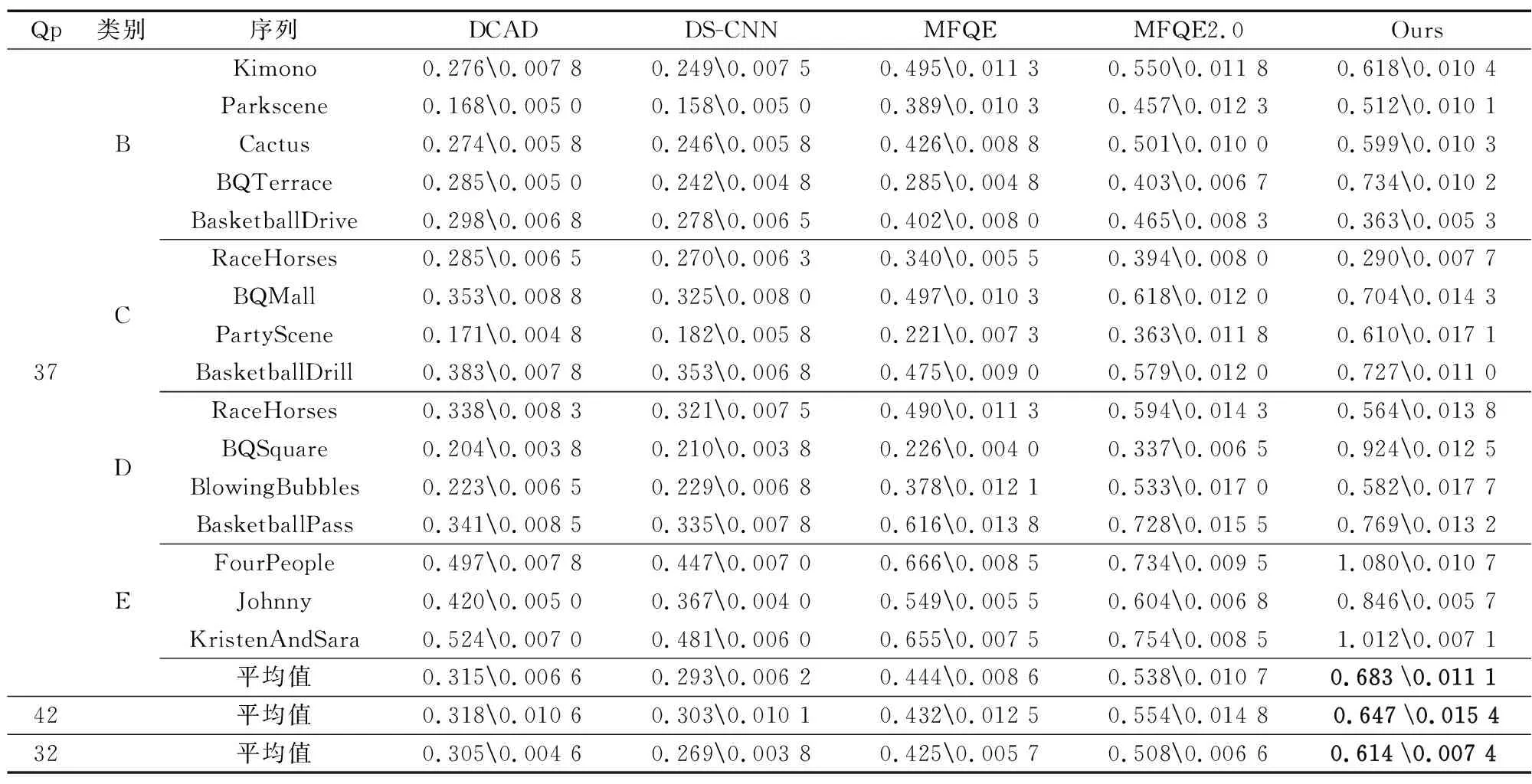
表2 本文方法与其他方法的性能比较(ΔPSNR/dBΔSSIM)
当QP取42,32时,本文方法同样可以将HEVC标准解码帧质量分别提升约0.65,0.61 dB,较DCAD,DS-CNN,MFQE,MFQE2.0分别提升约0.33,0.34,0.22,0.09 dB以及0.31,0.34,0.19和0.11 dB。这说明本文方法具有一定的鲁棒性,具有迁移到不同压缩指标下的视频质量增强任务的可能性。
2.3 主观质量分析
HEVC标准编解码后的视频帧质量在人眼观察下是有明显下降的,尤其是一些压缩伪影,即在压缩过程中由于基于块的编码与量化引入的噪声,通过环路滤波后一些噪声得到抑制,但是由于去方块滤波和样点自适应补偿的局限性,去噪效果并不理想。
本文方法视觉效果对比如图5所示,在通过本方法处理后,可以看到图中的压缩伪影得到明显去除,细节部分得到还原,之前难以识别的局部信息也变得更易辨别。高频边界也得到补偿,边缘在处理后过于平滑的情况较少,对于图像景深的还原比较充分。通过对运动状况不同的视频进行分析可以发现,对于运动较为平缓的视频序列如图5(a)所示,其客观评价指标增加较大,在视觉感受方面压缩伪影得到有效抑制,其背景区域几乎不存在变化,在增强后并未受到影响。运动区域的细节在解码帧中有较大的损失,而通过本文方法增强后有相对较大的提升。当像素位移矢量较大,即如图5(b)中运动较剧烈时,在编码端的信息丢失就更严重,所以在解码端的重建结果也就更差。由于存在这种大量的数据丢失,本文中的增强效果在较运动平缓区域相对更弱,但依然能将大多不利于观感的压缩伪影去除,呈现出更丰富的图像细节和层次感。
2.4 消融实验分析
为达到更好的实验效果,还进行了相关消融实验分析,结果如表3所示。
类别1为对当前帧是否进行独立注意力特征提取,实验结果表明对其进行额外注意力提取可以获得更好的实验效果;类别2为是否设置更深的特征映射单元,结果表明更深的特征映射有利于更好的结果呈现;类别3为是否设置更高层的运动提取网络,实验证明更高层的运动提取网络对增强结果有积极作用。
3 结束语
数据压缩的需求使得HEVC解码视频帧的质量较原始视频帧大幅下降,大量的压缩伪影导致细节信息大量损失,使得人眼观感较差。本文方法采用基于多帧的多层次、多维度的深度卷积神经网络实现了端到端的视频质量提升。
通过本文所提方法增强后,视频序列在PSNR和SSIM均取得了非常良好的效果,并且在人眼主观感知下也明显观察到对解码帧中存在的压缩伪影的去除作用,同时还对视频帧中细节部分得到清晰保留,极大地改善了视觉观察效果,实现仅利用解码视频流就对视频序列本身的质量增强。
