基于生成对抗网络的可见光与红外图像融合
2022-04-21刘锃亮吕恒毅
刘锃亮,张 宇,吕恒毅
(1.中国科学院长春光学精密机械与物理研究所,吉林 长春 130033;2.中国科学院大学 光电学院,北京 100039)
0 引言
图像融合属于图像增强技术,目的是为了将不同的图像融合在一起生成信息丰富的图像,从而方便进行进一步处理。为了满足人们生产生活中在各种复杂环境下的需要,多源图像的融合引起了广泛的重视。红外图像可基于辐射差异将目标与背景区分开来,同时可见光图像可提供符合人类视觉感知的具有高空间分辨率和清晰度的纹理细节[1]。为了取得令人满意的融合效果,关键是有效的图像信息提取和合适的融合原则。
图像融合算法目前已经发展多种不同的方案,包括多尺度变换[2]、稀疏表示[3]、神经网络[4]、子空间[5]、混合模型[6]和其他方法[7]。现有方法通常在融合过程中对不同的源图像使用相同的变换或表示,然而它不适用于红外和可见光图像,因为红外图像中的热辐射和可见光图像中的细节纹理是2种不同现象的表现。此外,大多数现有方法中的图像信息提取和融合规则都是手工设计的,并且变得越来越复杂,受实现难度和计算成本的限制[8]。
受最近两年在CVPR会议上香港科技大学李铎、陈启峰团队[9]提出的一种多尺度卷PSConv和天津大学王启龙团队[10]改进的轻量级注意力模块ECA-Net的启发,在融合生成对抗网络FusionGAN[11]的基础上,在其残差网络中引入了PSConv,以提升特征提取的细粒度与深度,再经过ECA网络增强对有用信息的收集,从而使最终融合后的图像具有更丰富的细节特征和纹理信息。
1 算法与改进
1.1 FusionGAN原理
FusionGAN的原理是将红外与可见光融合的过程公式化成一个对抗的过程,其结构包括生成器G(Generate)和辨别器D(Discriminator),训练过程与测试过程如图1和图2所示。训练时,首先将红外图像Ir与可见图像Iv叠加在一起传送给生成器G,融合后的图像既包含了红外的热辐射信息,又保留可见光图像的梯度信息;再将生成融合后的图像If与可视图像Iv一同发送给辨别器D,让其区分二者;最后将辨别的结果形成一个反馈,输送回生成器G,形成一个对抗的反馈网络。经过大量的训练之后,当辨别器无法辨别Ir与Iv时,说明生成的融合图像已经达到了好的效果,训练完成。再进行测试时,只需要用到已经训练好的生成器G即可。

图1 训练过程

图2 测试过程
1.2 损失函数
FusionGAN的损失函数主要包括生成器G的损失函数与辨别器D的损失函数两部分。
1.2.1 生成器损失函数
生成器损失函数为:
(1)
其主要由2个部分组成,VFusionGAN(G)代表生成器与辨别器之间的对抗损耗,即:
(2)

(3)
式中,‖·‖F为矩阵范数;H和W为输入图像的高度和宽度;为梯度算子;为保留红外图像的热辐射信息;为保留可见光图像的梯度信息;ξ为控制2项之间权衡的参数。
1.2.2 辨别器损失函数
辨别器基于可见图像中提取的特征来区分融合图像和可见图像,使用最小二乘作为损失函数使训练过程更加稳定,损失函数收敛速度更加迅速:
(4)
式中,a和b为融合后图像和可见图像的标签;D(Iv)与D(If)为可见图像和融合图像的分类结果。
1.3 算法的改进
虽然FusionGAN算法能很好地平衡红外与可见图像中的有效信息,与其他方法相比图像融合的质量更高,但是在细节纹理和深度特征提取上还不够,因此新增加了一个即插即用卷积PSConv与一个超轻量级的注意力模块ECA Module。改进后的算法网络结构如图3所示。输入的红外图像与可见图像分别经过各自的3层卷积和1层残差网络后,在第2层残差块中引入上述2个模块,加深了网络的深度,有利于深度特征的提取,最后再经过3次反卷积生成最后融合的图像。虽然增加了2个模块,但是由于都是轻量级网络,使整个模型增加的运算量不大,接下来将分别介绍这2个模块。

图3 改进后的算法结构
1.3.1 PSConv
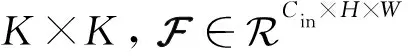

图4 PSConv示意
(5)
扩张卷积则可描述为:
(6)
而PSConv则可描述为:
(7)
从上述卷积计算公式可以看出,PSConv将多尺度卷积归入同一个计算过程中,且不同尺度卷积计算按通道交替执行,是一种更细粒度的多尺度操作。
1.3.2 ECA-Net


图5 SE与ECA结构对比
(8)
式中,|t|odd表示离t最近的奇数;γ和b在本文中取2和1;K取5。相比之下,ECA-Net结构更加轻量化增加可以忽略不计的参数量的同时,带来性能明显的提升。
2 实验结果与评价
2.1 数据集
为了增强实验结果的准确性与可靠性,选用公开并且校准好的红外与可见光数据集TNO与INO。其中TNO数据集包含军事场景和其他一些不同场景下的近红外和长波红外或热红外夜间图像与可见光图像,适用于复杂场景下的图像融合算法研究。INO数据集来自加拿大国家光学研究所,包含了许多在不同天气条件下拍摄的不同的城市道路街景。
2.2 结果
选取来自TNO和INO数据集中的1 200张红外图像与可见光图像作为训练集,为了验证算法的性能,再从TNO数据集中单独挑选出20对可见与红外图像作为测试集。训练集融合的结果如图6所示,模型训练好之后测试集融合的结果如图7所示。

图6 训练集结果

图7 测试集结果
2.3 评价
本实验将几种目前比较常用的先进的图像融合方法与本文的方法进行比较,其中包括曲波变换(CVT)[14]、双树复小波变换(DTCWT)[15]、加权最小二乘优化法(WLS)[16]和原融合生成对抗网络FusionGAN等图像融合方法,并且采用主观评价与客观评价相结合的方法,使实验结果更具有真实性和可靠性。
2.3.1 主观评价
选取了5对红外与可见图像的融合结果作为主观评价指标,上述不同的融合方法对来自TNO数据集中5对图像的融合结果如图8所示。为了体现改进的算法与FusionGAN的不同,在图8(f)和(g)中加入了一些方框用于细节的比较,并且将其放大,放在原图的右下角。通过融合后的结果可以看出,上述方法均能对红外图像与可见图像进行成功融合,融合后的图像均能包含红外与可见图像的特征信息。虽然CVT和DTCWT方法融合的结果含有足够的细节特征,但红外的目标不够显著。而与CVT和DTCWT方法相比,WLS方法具有更强的目标追踪性,但在背景部分损失了较多的红外信息。FusionGAN方法在目标追踪和细节纹理特征保留之间取得了较好的实现,但是背景信息中的细节特征仍不够丰富。与上述方法相比,本文采用的方法既保留了红外目标的显著性,又在背景中包含了足够的细节纹理与边缘信息。

(a)源红外图像
2.3.2 客观评价
为了增强实验的准确性与客观性,采用多种评价指标进行定量分析。选取熵(EN)[17]、平均梯度(AG)[18]、空间频率(SF)[19]和结构相似指数(SSIM)[20]这4种常用评价指标。EN主要是度量图像包含信息量多少的一个客观量,熵值越大,表明融合图像中的信息越丰富,而噪声也会对EN的结果造成影响,一般不单独使用。AG度量融合图像中包含的梯度信息,反映了细节和纹理,AG值越大,表明融合图像中所含梯度信息越多。SF可以有效衡量图像的梯度分布,SF越大,融合的图像具有更丰富的边缘信息和纹理特征。SSIM是用于模拟图像畸变和失真的一种评价方法,SSIM越大,说明融合算法的效果越好,失真与畸变越小。4种指标下不同方法的平均性能如表1所示,20对图像的数据结果用Matlab绘制成折线图,如图9~图12所示。从表和图中可以看出,在上述4种评价指标下,5种方法在客观的定量分析上有差距,本文所用的方法在AG,SF,SSIM这3种指标上取得了不错的效果。结果表明,本文方法的试验结果中包含了更多的细节纹理与梯度信息,得到的融合图像与源图像之间的畸变小于CVT,DTCWT和WLS,FusionGAN虽然能包含更多的信息熵,但在空间频率信息与结构相似性上远不如改进后的方法。

表1 5种算法在指标下的平均性能

图9 EN指标下对TNO数据集中20对图像对的试验结果

图10 AG指标下对TNO数据集中20对图像对的试验结果

图11 SF指标下对TNO数据集中20对图像对的试验结果

图12 SSIM指标下对TNO 数据集中 20对图像对的试验结果
3 结束语
针对可见光与红外图像融合中所存在的问题,提出了一种改进的FusionGAN方法。分析了FusionGAN的原理和2个引入模块PSConv与ECA-Net的架构。PSConv对图像细节处理更好,ECA-Net能更好地提取图像中的有用信息,使用了数据集验证了新算法的可行性与效果,加入的模块使改进后的算法与原算法相比在AG上提升了6.2%,在SF上提升了14.4%,在SSIM上提升了18.6%。本文引入注意力机制模块与插入式卷积,为图像融合算法的改进与提高提供了新的思路,更适用于复杂场景下的红外与可见图像融合,为今后继续研究深度神经网络用于图像融合打下了基础。
