基于特征图集合的遥感影像深度学习地物分类研究
2022-04-21楚博策王士成陈金勇于卫东
楚博策,高 峰,帅 通,王士成,陈 杰,陈金勇,于卫东
(1.北京航空航天大学 电子信息工程学院,北京 100191;2.中国电子科技集团公司第五十四研究所,河北 石家庄 050081)
0 引言
近年来,Landsat、高分、Geoeye和Quickbird等军用、民用、商用各类对地观测卫星逐步升空并投入使用[1-2],同时伴随着微纳卫星、星群和星座的概念提出与规划建设,后续的遥感影像数据,特别是高分辨率影像数据,将呈爆炸式增长。同时,各类用户对自动化地表覆盖提取的需求显得越发紧迫。随着遥感影像分辨率的不断提高,遥感影像中各类地物的成像细节以及边界轮廓逐渐清晰,各应用部门对遥感影像解析结果中地物覆盖提取精度的要求也逐步提升。高分辨率影像中包含丰富的细节信息,较多的噪声或信息冗余也同时存在,对机器实现自动、高精度的地表覆盖提取产生了更多干扰,这又对高分辨率的遥感地物覆盖分类流程设计以及模型设计提出了更高要求。面对如此庞大的遥感影像数据如何快速、自动、高精度地完成地表覆盖类型分类是当前需要重点攻关的一项关键任务[3-4]。随着深度学习、强化学习等人工智能技术的进步,目前已有较多科技工作者完成了基于传统机器学习[5]以及深度学习[6]的遥感影像地表覆盖分类任务的研究。
深度学习在地物分类方面的研究一部分集中在利用超像素方法对原始图像进行了初始分割,利用卷积神经网络和深度置信网络等神经网络对分割后的块图像进行分类,从而达到像素级地物分类的目的[7-8]。然而,该方法的分类效果不仅受到分类器效果的影响,而且受到分割效果的制约,特别是由于高分辨率遥感图像的内容比较复杂,很难达到较好的分割效果。另外一部分研究人员采用FCN[9],SegNet[10]等语义分割网络进行端到端的地物分类[11],虽然在一定程度上避免了分割与分类的叠加误差,但由于该方法受限于网络结构的优化水平,其分类效果仍然具有很大的提升空间。
为此,本文将人工特征工程与深度神经网络相结合,提出了一种新的针对地物分类任务的深度学习模型设计思路。首先提取多尺度的图像纹理、结构等人工特征描述图,将多尺度特征描述图与原始三通道遥感图像相结合,生成高维通道图像合集作为神经网络输入,最大程度在网络训练前期增大对分类任务有利的信息输入占比。为了更好地对高维通道图像合集进行特征描述,本文借鉴了当前业内公认效果较好的DeepLab v3[12-14]深度全卷积网络模型,实行了端到端的地物分类。同时,根据训练过程的分类效果对其结构进行改进,取得了良好的分类效果。通过与FCN,SegNet等语义分割网络进行地物分类效果对比,可以看出,与传统的机器学习方法、深度学习方法和早期的全卷积网络设计方法相比,本文设计的基于多尺度特征图集合的深度语义分割网络在地物分类应用中具有更好的实验效果。
1 基于多尺度特征图集合的深度学习地物分类架构
本文设计了一种基于多尺度特征图集合的深度学习地物分类架构,其流程如图 1所示。
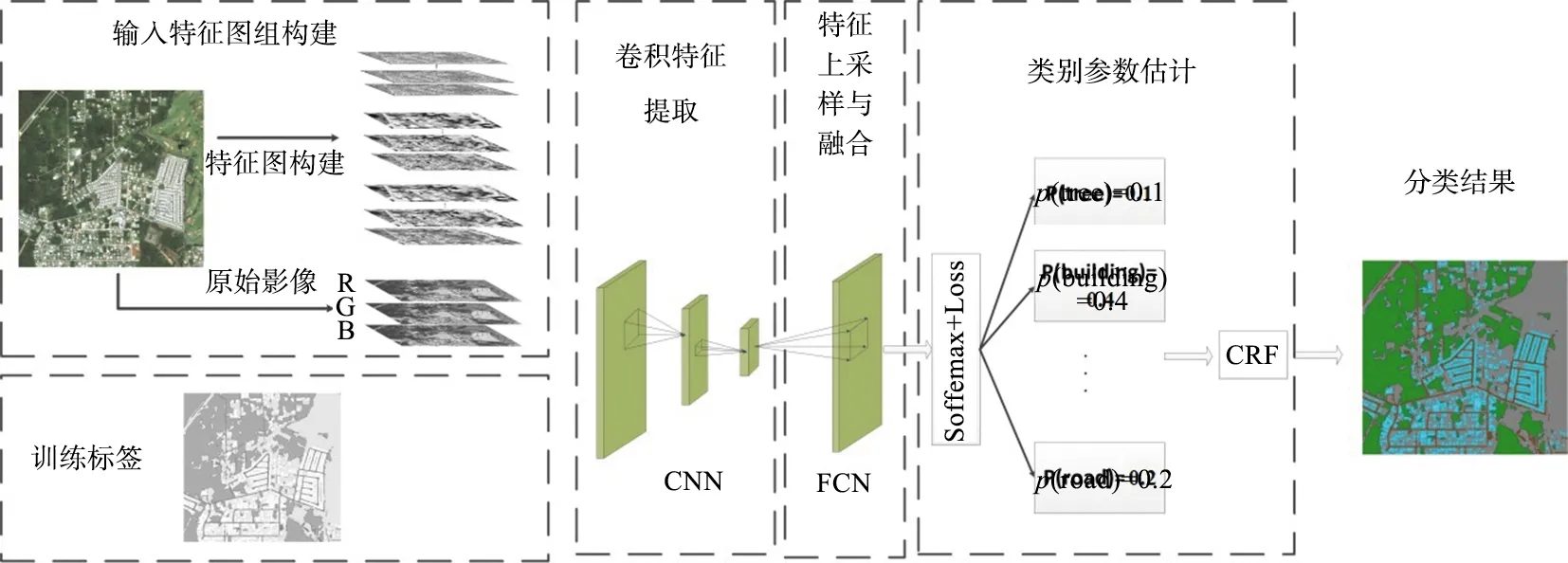
图1 基于多尺度特征图集合的地物分类流程
首先,从高分辨率遥感图像中提取特征图,包括纹理特征和结构特征。利用不同的窗口大小构造多尺度特征映射组,然后将原始图像和特征映射组进行融合,形成多尺度特征图集合作为神经网络的多维输入。对神经网络中的输入数据进行孔洞卷积、Relu激活和pooling操作,获取地物热度分布图。随后通过自底向上采样得到原始图像中每个像素的概率。最后,利用条件随机场[15-16]对分类结果的边缘进行细化。
2 多尺度纹理与结构特征图集合生成
由于高分辨率影像细节信息(其中较大部分为冗余信息)过多、地物特征较为复杂,仅利用影像直接进行深度网络特征提取容易受到冗余信息干扰,导致网络训练不彻底,甚至出现训练偏差,最终导致特征描述力较差,影响分类效果。仅利用影像图像进行分类时结果往往并不理想,因此需要利用其多元化特征对深度学习特征进行合理补充,甚至对深度学习特征训练方向进行引导。
地物之间显著的区别主要集中在纹理和轮廓结构中,例如:房屋纹理较为平坦,轮廓多为规则多边形[17];森林纹理较为密集,轮廓多为不规则多边形[18];道路纹理相对平坦,轮廓多为长条形等[19]。为提高特征描述的能力,本文对地物进行纹理与结构特征提取,形成多尺度特征图集合,并与原始图像合并形成高维图像作为深度神经网络输入。
2.1 多尺度纹理特征图
本文考虑不同地物在某些纹理特征(例如:方向性等)中差异性不明显,而在某些纹理特征(例如:密集度、复杂度、光亮变化等)中差异性较大的特点,设计采用二维熵、粗糙度、对比度作为纹理特征。其中二维熵主要是对纹理密集程度的描述,粗糙度主要是对纹理复杂程度的描述,对比度主要考虑纹理特征光亮变化程度的描述。除此之外,考虑纹理特征受窗口大小的变化,对全局和局部的描述能力会受到影响,本文采用多尺度窗口对特征进行提取,行成多尺度特征图集合,保证特征描述力的全面性。
(1)二维熵特征计算方法
本文提取二维熵特征作为纹理特征图集合的第一维特征,特征提取公式如下:
Pi,j=f(i,j)/n2,
(1)
(2)
式中,H表示二维熵特征;n表示图像大小;i表示当前像素的灰度值;j表示n范围邻域内点的像素值;f(i,j)表示特征二元组出现的频数;Pi,j表示i像素和j像素二元组出现概率。可以看出,图像二维熵可以突出反映图像中像素位置的灰度信息和像素邻域内纹理分布的综合特征,数目越大表示纹理越复杂。
(2)粗糙度特征计算方法
本文提取局部图像粗糙度特征并形成特征图,首先选取窗口N,窗口N内局部图像计算粗糙度,粗糙度计算公式如下:
(3)
En,h=|Dn(x+2n-1,y)-Dn(x-2n-1,y)|,
(4)
En,v=|Dn(x,y+2n-1)-Dn(x,y-2n-1)|,
(5)
En=max(E1,E2,…,En),
(6)
(7)
以窗口为N,步长为1遍历整幅图像,计算窗口内局部图像的粗糙度作为局部图像中心点的粗糙度特征,把所有粗糙度特征按照坐标位置组合,最终形成粗糙度特征图。
(3)对比度特征计算方法
对比度表征图像区域内明暗变化差异范围,差异越大表示对比度越大。遥感图像中不同地物的明暗度之间具有较大区别,采用对比度特征对于地物分类任务具有较好的区分性。计算方法如下:
(8)
式中,δ表示图像中灰度标准方差;α4表示图像灰度值峰态,通过α4=u4/δ4定义,u4表示四阶距均值,代表图像灰度值方差。
(4)特征图构建方法
本文设计采用特征图来描述整幅遥感影像的特征,特征图中每个像素值的意义是以该像素为中心,一定范围内局部图像的特征值,构建特征图的公式:
(9)
式中,Feature((i,j),N)为特征图中坐标(i,j)的特征值;a(m,n)为坐标(m,n)的像素灰度值;N为局部图像的尺度;f为特征计算函数(本文中分别代指二维熵、粗糙度、对比度特征计算函数),不同特征构建特征图集合方法只需替换对应的f为该特征图集合的特征求取公式即可。
本文以图像熵、粗糙度、对比度作为深度神经网络的部分输入,一维特征图如图 2所示。
(a)原始影像
(5)特征图集合构建方法
为保证特征描述的全尺度能力,设计采用多窗口特征提取形成多尺度特征组,通过改变N值取值范围,对原始图像进行多尺度特征图提取,最终构建特征图集合。本文初步设计窗口大小为N=(2,4,6,8,10,…)。特征图集合示意如图 3所示。

图3 特征图集合示意
2.2 多尺度结构特征图
在结构特征方面,本文没有对结构进行特征化,而是把图像中的地物边缘提取出来,用以突出结构信息在网络输入影像集中的信息比重,可以很好地避免结构特征在深度学习训练过程中被冗余信息所掩盖,可引导后续的深度网络特征训练过程中提升抽象结构特征的提取概率。考虑到Canny算子[20]可以较大程度标识出地物精细边缘信息[21],对复杂地形中边缘细节漏检率低,而且算法不易受噪声影像导致边缘偏离,因此本文采用Canny算子提取边缘特征进而构建结构特征图,提取结果如图 4所示。

(a)原始影像
3 全卷积深度神经网络结构设计
3.1 常规全卷积神经网络
早期遥感地物分类方法大多采用分割和分类的串联模式。分类结果不仅取决于分类模型的准确性,还取决于分割结果的准确性。随着全卷积神经网络能够在像素级对图像进行分类,实现了从原始图像到分类结果的端到端直接生成,完整解决了语义分割问题,因此全卷积网络更适合应用于地物分类任务。
传统的卷积神经网络通常在最后连接多个全连接层,将原始的二维矩阵(图像)展平成一维,丢失空间信息,最后训练输出一个标量,即分类标签。在特征分类任务中,不仅需要知道图像中的特征类别,还需要对不同特征的位置进行分割。与其他卷积神经网络相比,本文采用的全卷积网络的不同之处在于去除了传统分类网络中最后的全连接层,利用反卷积层对最后一个卷积层的特征映射进行上采样,使其恢复到与输入图像相同的大小。最后,逐像素计算softmax分类损失,相当于每个像素一个训练样本。因此,可以为每个像素生成预测,并且保留原始输入图像中的空间信息。具体网络结构如图 5所示。

图5 常规全卷积网络结构
直接对卷积结果进行上采样是非常粗糙的。由于高分辨率遥感图像具有非常详细的信息,低分辨率的语义特征直接应用于分类会产生明显的误差,因此全卷积过程将上采样层和对应同尺度的下采样层的结果进行组合,形成优化输出,再上采样得到最终的分类结果。
3.2 改进的DeepLab网络结构设计
本文参考DeepLab思想自行设计深度学习全卷积语义分割模型。DeepLab是全卷积网络的一个变种,主要特点在于采用带孔卷积的方法实现了感受野范围的增加,而且后端增加了条件随机场(CRF),解决了全卷积网络边界模糊的问题。本文的网络模型可以分为:对应于DeepLab中向下(采用多孔卷积进行特征提取并逐步降采样,同时提取语义特征)和向上(逐步上采样特征恢复细节信息)2段通路。向下的通路,以VGGnet为基础进行改进;向上的通路,将不同池化层的结果进行上采样之后,和向下通路输出结果并上采样至原图大小后相结合得到最终输出结果。为解决梯度消失问题,该网络引入了Relu激活函数,同时保留卷积操作,较大程度提升了训练效率。模型结构如图 6所示。
本文通过对多通道影像和特征图集合进行多孔卷积操作,经过6层卷积和池化之后得到特征热度图Fc7(16 pixel×16 pixel的图像),其中每个像素代表类别概率。为实现对原始尺寸影像进行分类,对Fc7进行上采样恢复至原始尺寸,通过插值方法将低分辨率图像转为高分辨。在此过程中,为恢复特征至原始输入尺度,网络中进行反池化操作。由于池化操作有信息损失,过程是不可逆的,因此反池化只是一种近似逼近的方法,通过记录池化过程操作的位置信息,按照该记录复现即可。除此之外,网络中针对激励函数还存在反向激励过程,不同于反池化,激励函数Relu是可逆的,反向激励过程可以通过转置实现逆过程。
为了获取遥感图像中有关地物类型的细节信息,本文利用卷积神经网络的多尺度层构造分类器。通过从卷积神经网络具有高分辨率的较低层选择性提取细节特征,利用自下而上的通道逐层产生分类结果。如图 6所示,Fc7进行上采样后与Dilated_Conv_5+Relu_5的输出融合生成Fc8,Fc8进行上采样后融合Dilated_Conv_6+Relu_6生成最终分类结果Fc9。
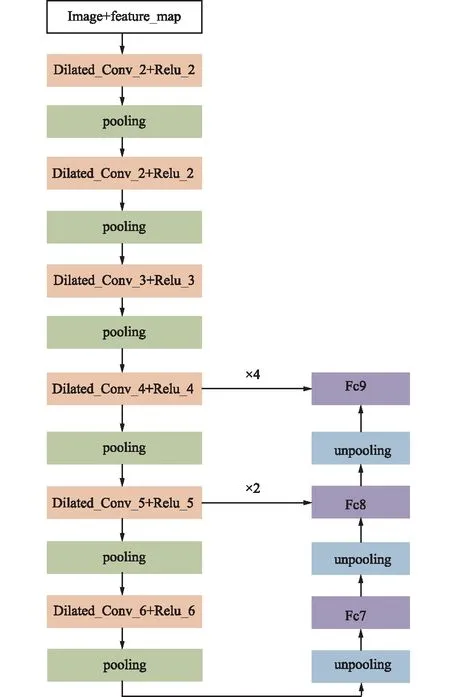
图6 本方法网络结构
4 实验与分析
4.1 实验数据集制作
本文涉及的训练和测试数据为关岛全区域(144°37′34.8″E~144°56′56.6″E,13°14′32.59″N~13°38′54.33″N)的可见光影像,主要包括高分系列卫星影像数据以及从Google Earth等软件中截取的数据。随后将宽幅影像裁切成大小为1 024 pixel×512 pixel的标准影像块进行标注,总共包括约2 000幅影像块,影像空间分辨率为0.3 m,如图7所示。该区域地物类型主要包括林地、道路、裸地、草地、水体及建筑等。

图7 Google Earth的高分辨率影像
在进行样本选取时,考虑不同地物分布的密集度不同,为保证模型训练过程,可以学习不同地物的区分性特征,废除较多单幅中单一地物全覆盖的影像。综合考虑并统计不同地物在影像集中的占比,选择2/3样本进行训练,1/3进行测试,其中训练样本和测试样本中各类地物分布较为均衡。
在生产多尺度纹理特征图集合的过程中,选取特征窗口N=(2,4,6,8,10)共5种窗口尺度,输入神经网络的影像图组中图像的数量S为:
S=N×f+C+RGB,
(10)
式中,f为选取的纹理特征种类;C为结构特征图数量;RGB为3,表示RGB三个通道。由式(10)可得本文输入网络的影像数为5×3+1+3=19。
4.2 网络参数设置
本实验将学习率的初始值设为0.000 1,并设计了触发函数,可根据训练误差的变化趋势动态调整学习率。由于输入图像维数和卷积网络的高内存消耗,将样本集设置为小样本集,对10个样本进行分批训练。实验中使用不同的网络结构来比较分类精度,如图 8所示。对比实验中分别使用vgg16,resnet50,resnet101,resnet152的卷积部分进行全卷积改造。随着网络层数的增加,精度没有增加。实验表明,本文设计的网络在当前情况下分类效果最好。
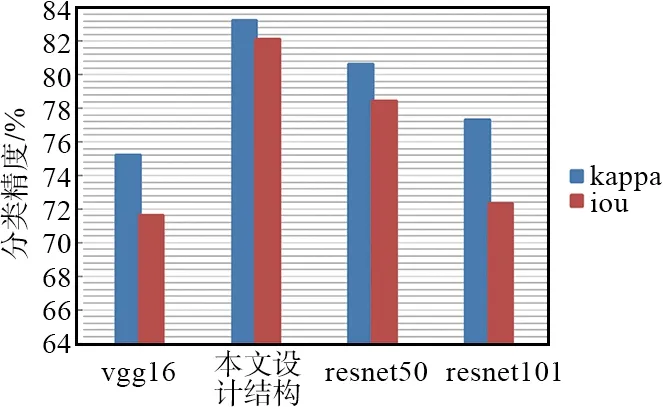
图8 不同网络结构分类精度
4.3 实验结果与分析
4.3.1 采用特征图集合方法的前后对比
实验分别对600余幅1 024 pixel×512 pixel的影像作为测试样本进行测试。为验证本文提出的输入特征图集合实现神经网络特征提取的有效性和针对性,实验中分别对直接输入RGB影像和输入特征图集合进行对比实验,实验结果如表 1所示。
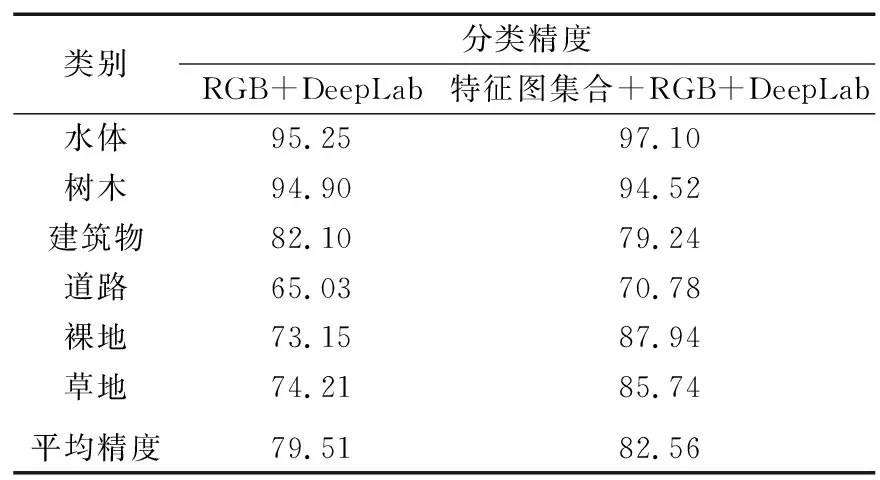
表1 不同网络输入分类效果对比
由表1可以看出,特征图集合的加入对分类精度具有较好的提升效果。其中,水体、树木和建筑物的分类精度较高,裸地与草地在标注时难以主观界定标注标准,经常出现一些区域为裸地与草地交错出现的情况,在一定程度上影响标注精度进而影响模型学习的精度。道路分类容易受到各种因素(标注界限模糊、树木遮挡等)的干扰,且由于道路的线状结构,分类结果容易出现道路的截断,导致分类精度较低。后续研究将针对道路进行拓扑结构后处理进行道路块的连接,在一定范围内改进深度学习分类后的效果。
4.3.2 不同深度学习算法实验结果对比
实验分别对全卷积网络的各种衍生算法进行分类实验,由于全卷积网络为像素级地物分类网络,因此网络的直接输出分类图中容易出现类别斑点和地物碎片,本文对神经网络输出后的结果进行了平滑、膨胀、腐蚀等后处理,实现分类结果中像素级类别斑点进行过滤,同时将分属同一地物的临近碎片进行分类标签合并,使最终结果中各类地物具有较好的完整性和展示性。不同网络的实验分类结果如图 9所示。
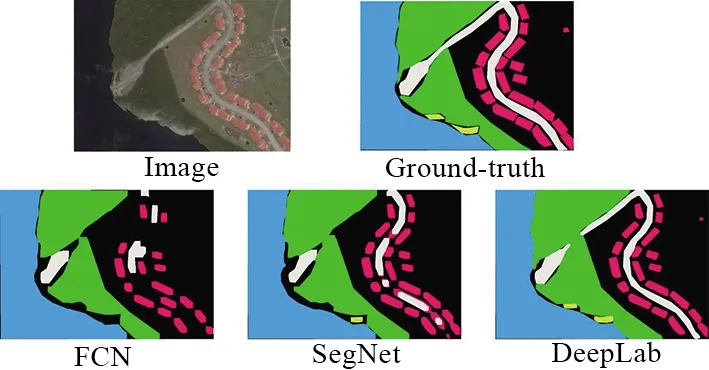
图9 不同方法分类结果
具体的实验分类结果如表 2所示。可以看出,相比其他算法,本文改进DeepLab中多孔卷积结构增强感受野和CRF的边界增强在大多数地物类别中具有较好的应用效果。在树木和草地的分类实验中,本文的方法稍逊于SegNet和RefineNet等方法,考虑不同地物在尺度、纹理等方面对网络的适用性不同,后续将对不同地物适用的网络结构特点进行研究。

表2 不同算法分类精度对比
4.3.3 宽幅影像分类结果
实验对宽幅影像进行裁切和合并处理从而实现宽幅影像的分类,其中按照交叠裁切的方法将原始影像切分为若干1 024 pixel×512 pixel尺寸的影像。交叠率设置为影像窄边尺寸的1/2,即256 pixel,最终合并后的分类结果如图 10所示。

(a)宽幅影像图
本文采用Tensorflow架构和Python脚本语言进行算法实现,GPU采用NVIDIA Quadro P5000,显存为48 GB。通过测试,基于该GPU算法运行速率可达到0.3 秒/幅(1 024 pixel×512 pixel影像),一景10 000 pixel×10 000 pixel的影像的处理时间为分钟级,用时远低于传统方法。
5 结束语
本文将特征图集合方法与深度全卷积网络相结合,采用深度语义分割网络进行端到端的高分辨率遥感地物分类。通过采用特征图集合方法前后进行对比实验,可以看出特征图集合可以有效地对网络的特征提取方向提供引导,从深度网络输入的角度提升特征提取的有效性。此外,本文将语义分割的全卷积深度神经网络与遥感地物分类任务相结合,通过对比不同网络模型方法的分类精度,训练得到较为优秀的深度模型来进行像素级地物分类。
通过研究发现,深度全卷积网络在遥感影像分类领域具有较大潜力,将逐步取代传统的分割、分类多步骤串联的分类方式。但是作为一种新兴的技术,仍有很多的工作需要研究,主要表现在不同地物适用的网络结构特点仍然未进行总结梳理。现有网络模型多针对常规图片的特性进行设计,多适用于正视角、大目标、集中性强的分类任务,相比而言,本文提出的网络模型是一种真正适合遥感影像俯视角、小目标、多分散特性的网络模型结构。下一步,将研究不同地物特性与不同深度学习网络结构之间的关系,进而通过融合多种网络结构,最终实现不同地物采用同一网络实现最优的分类结果。
