基于改进YOLOv4-Tiny的FPGA加速方法
2022-04-21曹远杰高瑜翔杜鑫昌涂雅培吴美霖
曹远杰,高瑜翔*,杜鑫昌,涂雅培,吴美霖
(1.成都信息工程大学 通信工程学院,四川 成都 610225;2.气象信息与信号处理四川省高校重点实验室,四川 成都 610225)
0 引言
近年来,随着神经网络的快速发展,目标检测领域的要求越来越高。深度学习算法从AlexNet[1]到VGG[2],GoogLeNet[3],再到后来出现的ResNet[4]和DenseNet[5]。这些算法在性能提高的同时,效率也变得越来越低。由于存储空间、算力以及带宽资源限制,神经网络模型在移动设备和嵌入式设备上的存储与计算仍然是一个巨大的挑战。
在算法方面,为了降低算法所需资源,有模型压缩和设计轻量级主干网络2个方向。模型压缩方式有知识蒸馏、剪枝[6]、量化等。例如Han等人[7]提出对网络迭代剪枝,获得一个精简模型,最终在没有精度损失的前提下AlexNet参数量减少了9倍。段杰等人[8]提出将BN层融入卷积层,可以加快前向推理速度。但仅仅依靠模型压缩来实现轻量化还是不够,还有一种方式是设计轻量级模型,例如SqueezeNet[9],MobileNets[10],Xception[11]等轻量级算法。许多轻量级算法并没有考虑硬件实现等问题,计算量虽然有所降低,但硬件实现的效率依然很低。例如FPGA处理器遵循Roofline模型,根据算法的不同,瓶颈也不同。这种轻量级的模型计算量低,但是层数增加导致访存量也增加,计算效率依然很低。为解决以上问题,提出了一种访存量、参数量、计算量较小且采用Ghost残差结构所构建的轻量级主干网络(YOLO-GhostNet)[12]。
在硬件方面,由于卷积大部分时间在计算上,普通CPU无法满足深度学习算法的实用性,用并行架构的处理器能够更好地适配神经网络,因此硬件平台转向GPU和FPGA等并行处理器。GPU虽然效率很高,但是功耗太大,FPGA相比于GPU能够更好地定制可重构卷积IP[13-14]。例如Shen等人[15]提出对不同层设计多个加速器。Zhang等人[16]提出针对通信密集型通过增大突发传输长度来高效利用带宽。Li等人[17]提出将输出通道以及卷积核宽三维展开的并行架构,这些都只适用于资源较多的FPGA。
本文针对在较少资源FPGA上部署深度学习算法主要有以下几点创新:① 针对部署资源问题对算法进行轻量化设计和压缩;② 针对内存空间问题对算法进行动态定点数量化以及分块处理,设计高效数据传输模块;③ 针对算法算子设计传统卷积、通道卷积、池化等流水线架构加速器。
1 YOLOv4-Tiny算法优化
YOLO[18-19]是近年来比较受欢迎的图像识别分类深度学习算法,Tiny版YOLO算法在精度范围内检测速度快、效率高,但是针对嵌入式平台还略显笨重。
1.1 YOLOv4-Tiny结构改进
改进网络(YOLO-GhostNet)如图1所示。
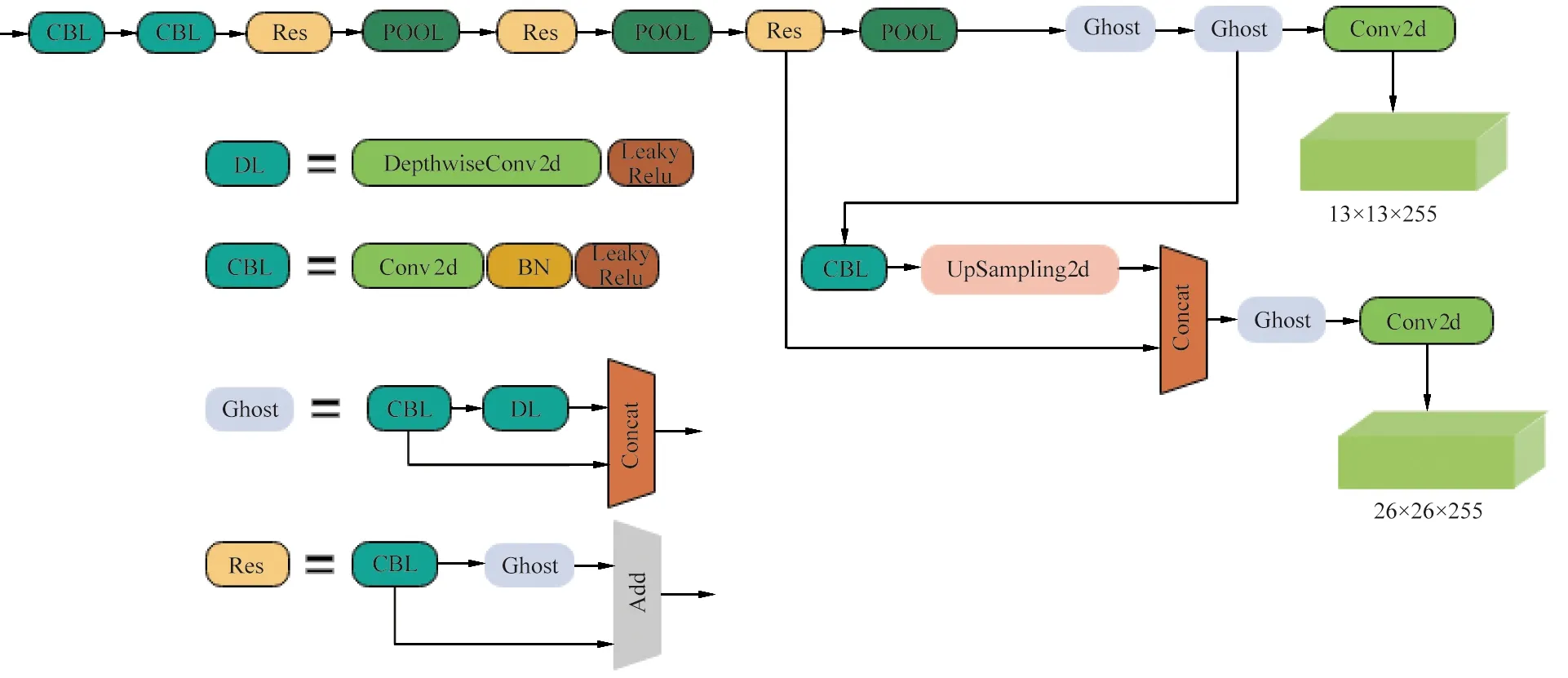
图1 YOLO-GhostNet算法结构
改进结构采用图1中Res残差结构代替YOLOv4-Tiny的残差结构,将网络大部分3×3标准卷积采用由一个点卷积和一个5×5的通道卷积替代。图1中Ghost模块为传统卷积和通道卷积所构成;Res为以Ghost卷积所构建的残差结构;DL,CBL分别为通道卷积和传统卷积层。
1.2 基于结构剪枝的模型压缩
Batch Normalization[20]层用以加快深度学习训练收敛等问题。假设该BN层输入为x,则输出为:
(1)

由于深度学习网络针对检测种类、卷积深度、卷积层数的不同,冗余的参数也会不同。本文首先通过对BN层缩放系数γ和平移系数β添加L1正则化约束进行稀疏训练。再通过式(2)对每个通道筛选:
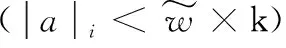
(2)
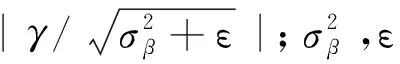
1.3 动态定点数量化
深度学习有很强的鲁棒性,数据的细微变化对整体结果不会有太大的影响。依据这个特性,可以对网络进行动态定点数量化[21]以降低资源占用。实验表明,采用16 bit动态定点数量化可以获得更好的精度与速度平衡。
本文采取的定点数量化如下:
yint=Round(xfloat×2n),
(3)
式中,yint为量化后数据;Round()为四舍五入函数;xfloat为需要转换的浮点型数据;n为量化系数,依据每层数据的分布变化而变化。
对网络量化步骤如下:
① 根据每层权值的分布找到最优的小数位位宽n,n≤(m-1),m大于等于该层权值最大值的整数位位宽。由于采用的数据为有符号类型,所以最高位为符号位,在16 bit量化模式下,只有15 bit分布给整数位和小数位。
② 依据式(3)对每层权重和偏置进行16 bit量化。输入输出特征图依据式(3)和式(4)对其量化与反量化:
yfloat=xint×2-e,
(4)
式中,yfloat为反量化后输出;xint为需要反量化的数据;e为特征图量化系数。
③ 中间特征图量化,如式(5)所示,为了减少计算,依据指数计算的特性,将2层量化系数通过式(6)对特征图直接量化:
Inmapi=yint(yfloat(Outmapi-1,ei-1),ei)
(5)
Inmapi=yint(Outmapi-1,ei-ei-1),
(6)
式中,Inmapi为该层输入特征图;Outmapi-1为上一层输出特征图;ei,ei-1为本层和上一层的特征图量化系数。
针对神经网络中的激活函数的量化,由于网络采用LeakyRelu激活函数,对于小于0的像素点需乘0.1。所以将激活函数改为:
yLeakyRelu=max(x×0xccc>>15,x),
(7)
式中,yLeakyRelu为激活层输出;max为返回最大值函数;x为输入数据;>>为移位操作。
采用不同位宽设计卷积加速器消耗资源对比如表1所示。
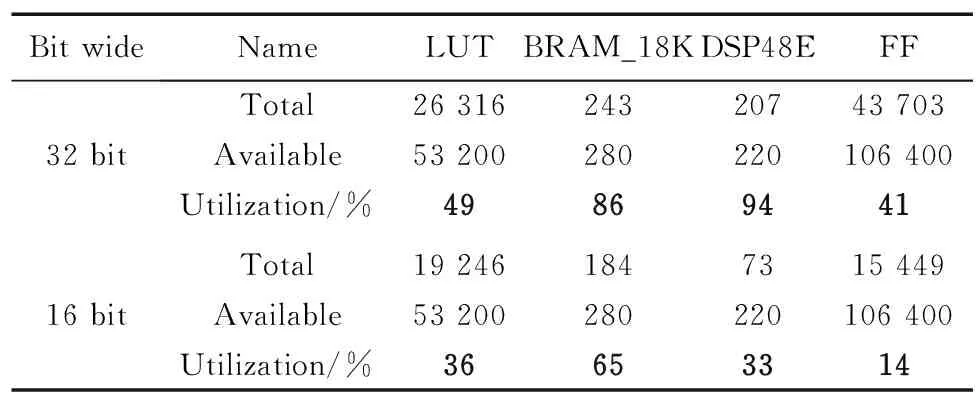
表1 卷积加速器在不同精度消耗资源对比
表1对比了2种位宽精度在相同结构下的各FPGA资源消耗。可以看出,使用32 bit位宽类型的加速器很快就用满了DSP资源,瓶颈也会被DSP资源所限制。采用16 bit位宽类型在各资源上都降低了许多,可以利用更多的DSP资源对计算并行处理。
2 硬件设计
本文加速算法YOLO-GhostNet中包含尺寸为1×1和3×3、步长为1和2的传统卷积层、尺寸为5×5的通道卷积层、最大池化层;上采样层和路由层。其中,路由层特征图叠加部分计算量很小,在PS端实现,其他算子均在PL端设计。为了减少计算,本文设计在算法层面将BN层融入到卷积层中。
2.1 加速算子介绍
(1)传统卷积与通道卷积
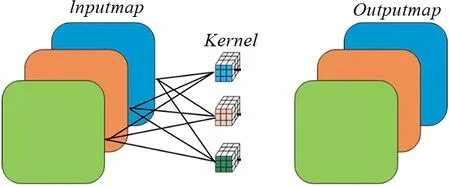
传统卷积是将所有输入特征图通过卷积核计算后生成输出特征图,通道卷积是分组数等于输入通道数的特殊分组卷积。2种卷积的卷积过程如图2所示。
(a)传统卷积
由图2可以看出,传统卷积与通道卷积输出特征图一样,卷积计算过程不一样,所以针对2种卷积分别定制了不同的卷积IP核。
(2)上采样与下采样
深度学习运用了图像金字塔原理,其中不同尺寸的特征图交互时需要用到上采样或者下采样。本算法中上采样将每个像素点复制成4倍,生成2倍的长宽特征图。下采样采用最大池化层。最大池化层通过对周围4个像素点的筛选,获取像素值最大的点,从而将尺寸下采样为原来长宽的一半。
(3)路由层
本算法中路由层包含Add和Concatenate层。由于Concatenate可以使用一些高效的函数库实现,而Add操作在PS端实现对整体效率有影响,所以将其在PL端实现。
Add层依据式(8)将各特征图对应像素点相加:
(8)
式中,yadd表示相加后的特征图;c表示有c层特征图需要相加;h,w,chout表示特征图对应的长宽通道数坐标。
2.2 加速器构建
加速器大致可分为输入模块、计算模块和输出模块。几种算子的加速器的不同在于计算模块。由于片上资源有限,只能将一部分特征图和一部分权重等参数加载计算输出后再计算下一部分。分块卷积如图3所示。图中,Tn,Tm,Th,Tw分别为分块输入通道数、输出通道数、分块长和高,ksize为卷积核长宽。
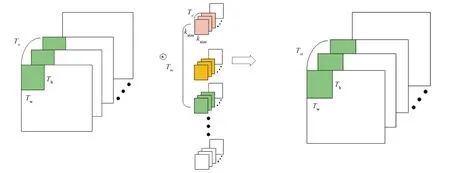
图3 分块卷积过程
(1)输入模块
算法数据传输的接口都设计为AXI4 master接口。每次卷积输入分块特征图大小为Tn×Tm×Tw。数据读入分为2个部分协同合作,第一部分为计算地址偏移,时延为Latencyinaddr和从DRAM读取数据到行缓冲(Line_buf),时延为Latencyline;第二部分为从行缓冲读取数据到计算输入缓冲(IN_buf),时延为Latencyinbuf。读取一个特征块的时延如下:
Latencyinmap=Tn×Th(Latencyinaddr+Latencyline+Latencyinbuf),
(9)
式中,Latencyinmap为特征块输入时延;Tn×Th为特征块所需要传输的次数,一次传输Tw长度的数据量。
然而第一部分和第二部分是可以同时工作的,为了将输入数据流水线起来,输入模块设计了2个行缓冲,如图4所示的Line_Buf0和Line_Buf1,由于HLS中2个函数所操作的数据没有关系会自动综合为并行执行,所以可以将数据从DRAM读取到行缓冲和将行缓冲中的数据写入到计算缓存并行执行,降低时延。
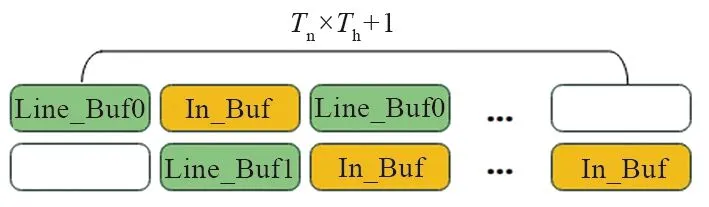
图4 输入模块时序
一个分块大小的数据需要读取总次数为Tn×Th+1。特征块传输时延降低为:
Latencyinmap=(Tn×Th+1)·
max(Latencyinaddr+Latencyline,Latencyinbuf)。
(10)
默认特征图排序为长宽和通道数,通道数上内存连续。为了提高带宽利用,将特征图序列改为通道数、长和宽的顺序。特征图长宽在本算法中为416,分块Th和Tw大小设置为可以被416整除,可使资源利用率更高。根据式(10),输入通道一定时,特征块高度越小,特征块传输时延越小。实验表明,当Th=14,Tw=52时能够更好平衡带宽利用和计算。
(2)计算模块
依据算子的不同,计算模块有卷积模块、通道卷积模块和池化模块。池化模块由于计算量较小,直接采用串行计算筛选最大值方式。主要对传统卷积和通道卷积计算模块进行优化。
卷积计算是整个算法中耗时最大的部分,为了提升运算效率,本设计采用多输入输出通道并行计算方式,而VIVADO HSL软件可以用PIPELINE指令设计通道并行和流水线处理乘加运算。并行处理方式有多种,可以是卷积核内并行、特征图块的长宽并行以及输入输出通道并行。由于算法卷积核尺寸有很大一部分为1×1,所以卷积核内并行效率很低。对于分块长宽并行方式还涉及资源利用率和数据读取效率等问题。最终在通道方向进行并行处理,传统卷积块计算时延如下:
(11)
式中,Latencycompu为计算模块时延;Const[22]为初始时钟;Freq为时钟频率。
(3)输出模块
数据输出接口都设计为AXI4 master接口,模块也分为两部分,和输入模块相反,一部分是将输出缓存中的数据搬运到行缓冲中,时延为Latencyoutbuf;第二部分为计算地址偏移和行缓冲中数据突发写入DRAM中,时延为Latencyoutaddr和Latencydram。设计双缓冲流水化后时延如下:
Latencyoutmap=(Tm×Th+1)·
max(Latencyoutbuf,Latencyoutaddr+Latencydram),
(12)
式中,Latencyoutmap为特征块输出时延;Tm,Th分别为输出特征图层数与输出特征图高度。可以看到,流水化后的输出模块将第一部分和第二部分的时延重叠了,时序与图4类似。
设计双缓冲情况下,各模块可以同时进行,重叠时延,增大效率。每计算输出一个特征块大小数据时延如下:
(13)
式中,Latencymap为计算输出一个数据块的时延;Chin为输入特征层数;Tn为特征块输入通道数;Latencyinweights为加载权重延时。可以看出,将各模块流水化设计后可以实现加载特征数据延时、加载权重数据延时、计算延时、数据输出延时的重叠,进一步提高整体效率。
加速器整体架构将输入和计算模块、计算和输出模块两两进行乒乓流水化。传统卷积各模块时序如图5所示,其他算子加速器类似。
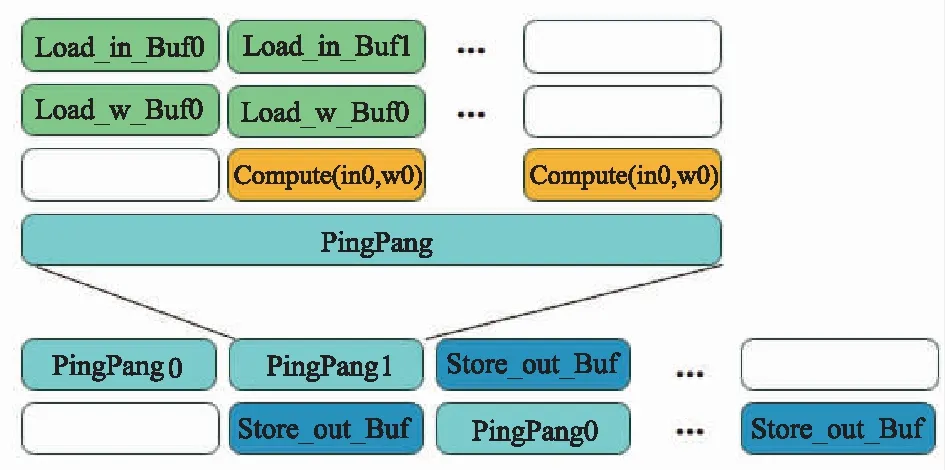
图5 卷积加速器各模块时序
图5中,Load_in_Buf为特征图输入模块,Load_w_Buf为权重加载模块,2个模块时序如图4所示。Compute()为计算模块,pingpang模块将输入通道计算部分打包后与数据输出模块(Store_out_Buf)进行乒乓流水线输出。各个模块内部还进行并行与流水线设计,提高整个加速器效率。
根据图5和式(13),每计算Tm个输出通道都需将输入通道方向所有层数全部计算完毕。每输出一个特征图块,需要读取Chin×Th+1次数据,写入Tm×Th+1次数据,当Chin比较大时,读取数据和输出数据的时延重叠部分较少,会降低整体效率。实验证明,设置Tn=4,Tm=32(Tm>>Tn)可以在时延重叠和资源占用方面获得更高平衡。
通道卷积由于输入通道等于输出通道(Tm=Tn),每输出一个特征块时需要读取Tn×Th+1次数据,写入Tm×Th+1次数据,读取数据与写入数据时延差不多,所以设计Tm=Tn=16方式并行。
2.3 基于ARM的卷积设计
本次实验分别在ARM和FPGA+ARM情况下对比算法效率。为了提高计算效率,采用im2col+GEMM(矩阵乘法)方式完成卷积设计。步骤如下:
(1)im2col
img2col是将输入特征图按照每次需要卷积的部分展平转换为矩阵,转换过程如图6所示。图中Input为输入特征图,以滑窗的方式将每次需要进行计算的部分存为内存连续的一列。每列大小为卷积核的大小,图中只展示了输入通道为1的示意图,多通道类似。Kernel为卷积核,也需要将每个卷积核展平方便计算。
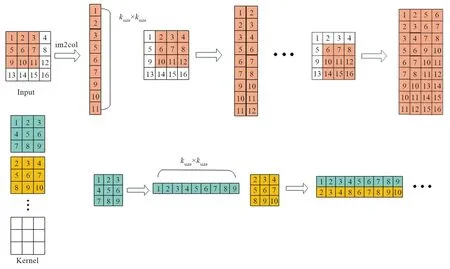
图6 特征图和卷积核转换到矩阵过程
(2)GEMM(矩阵乘法)
输入和权重转换为矩阵后,可以通过一些矩阵运算库进行加速。从运算次数上看,虽然和滑窗方式没有太大区别,但是转化为矩阵后,数据在内存上变成连续的,大大提升访问效率,从而加快运算,速度上也可提升数倍。
3 结果分析
3.1 软硬件环境
3.1.1 软件环境
分别对比了YOLOv4-Tiny和改进算法YOLO-GhostNet两种算法。2种算法均在Windows10操作环境下,PyCharm软件中使用Keras 2.24和Tensorflow1.14框架进行训练,剪枝和量化部分均在该环境中完成。为提高效率,各加速器IP均在vivado HLS软件下编写完成。
数据集采用10 097张饮料数据集,其中包含4个种类饮料,每种2 500张,测试集908张,训练集8 281张,验证集908张。
3.1.2 硬件环境
为了验证算法性能,分别在CPU,ARM工作频率和FPGA+ARM三种硬件上对算法进行评估。其中CPU为6-Core 的R5 3500X,工作频率为3.6 GHz,内存为16 GB(3 600 MHz);ARM为ARM Cortex-A9,工作频率为667 MHz;FPGA+ARM为ZYNQ7020,工作频率为180 MHz。
3.2 各加速器资源消耗情况
各加速器资源消耗情况如表2所示。
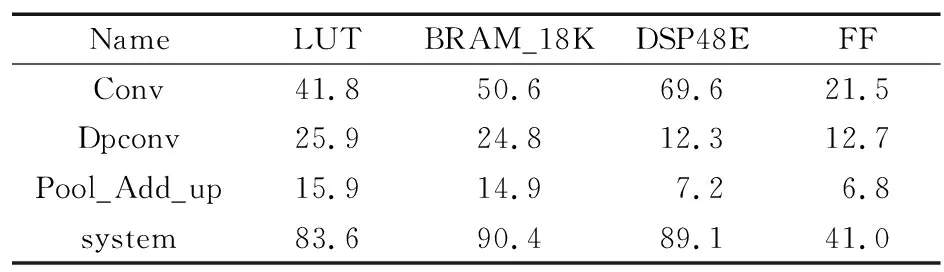
表2 各加速器及系统资源消耗
由表2可以看出,有3种加速器:Conv,Dpconv,Pool_Add_up,其中Conv为传统卷积加速器,Dpconv为通道卷积加速器,Pool_Add_up将池化层、路由层和上采样层打包成一个加速器。所构建的系统资源消耗了大量的DSP,LUT和BRAM资源。资源利用率较高。
YOLOv4-Tiny和YOLO-GhostNet算法参数及在不同处理器上性能对比如表3所示。

表3 YOLOv4-Tiny和YOLO-GhostNet算法各参数及性能对比
表3中,mAP为算法平均精度,在精度上基本无损失;速度分别在3种处理器上运行测试,改进后的算法在FPGA+ARM工作频率180 MHz时相对YOLOv4-Tiny算法在ARM单独工作时性能提升35.2倍,在FPGA+ARM工作时性能提升2倍;相对本算法在ARM单独工作性能提升20倍。BFLOPs为算法计算量,即:
BFLOPs=ksize×ksize×Chin×Chout×Win×Hout×2,
(14)
式中,BFLOPs为计算量;ksize,Chin,Chout,Win,Hout分别为卷积核尺寸、输入通道数、输出通道数和输出特征图尺寸。
YOLOv4-Tiny和YOLO-GhostNet算法在3种处理器下的功耗与能效如表4所示。
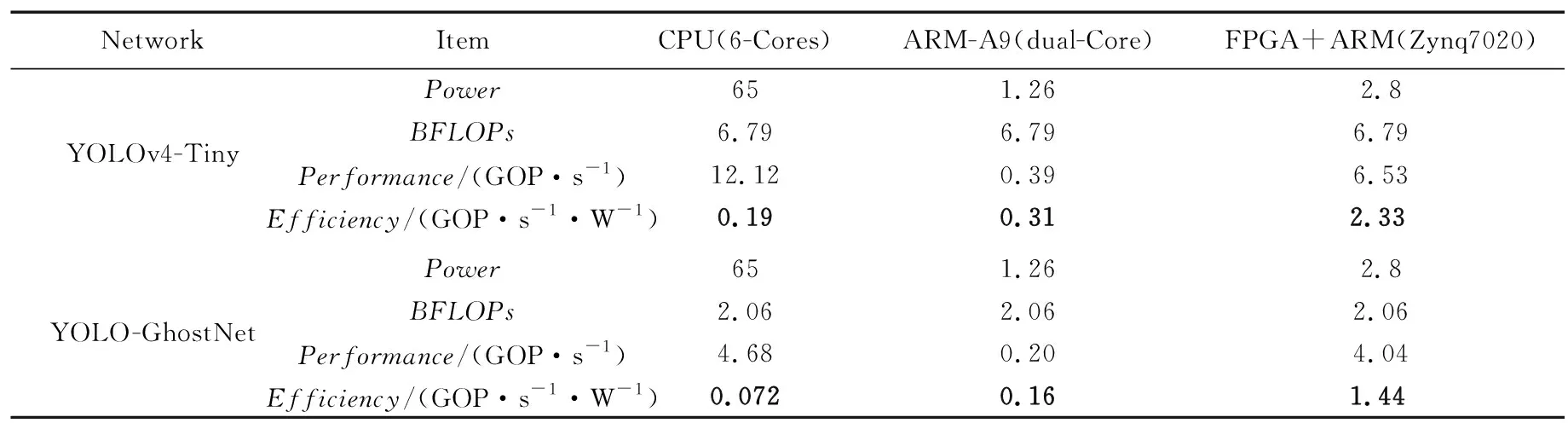
表4 YOLOv4-Tiny和YOLO-GhostNet算法功耗及其能效对比
由表4可以看出,对比能效方面,YOLOv4-Tiny算法在Zynq平台能效是在CPU和ARM平台能效的12.26倍和7.5倍。相较于改进后的算法,在Zynq平台下的能效是在CPU和ARM平台下能效的20倍和9倍。但是改进后的算法能效不论在哪个处理器下都低于 YOLOv4-Tiny。根据Roofline模型中的计算强度(计算量/访存量)分析,YOLO-GhostNet算法计算强度是要低于YOLOv4-Tiny算法的,性能瓶颈受限于带宽,不能完全利用处理器计算资源。
4 结束语
本文实验以YOLOv4_Tiny算法为基础,为了部署方便等问题将算法进行GhostNet模块设计、剪枝算法压缩、动态定点16 bit量化。再根据芯片资源和算法类型设计神经网络卷积专用IP核,更进一步地提高算法推理效率。但是由于算法类型和板子总线带宽利用率等问题,无法更进一步优化,导致能效较低等问题。未来进一步改进主要有以下2点:① 使用带宽更大的实验平台;② 对计算模块进行更近一步的高效优化,例如Winograd卷积等。
