基于BERT-GCN-ResNet的文献摘要自动分类方法
2022-04-21林丽媛刘玉良
郭 羽,林丽媛,刘玉良
(天津科技大学电子信息与自动化学院,天津300222)
文献分类是图书情报学科的重要研究方向.当前的文献分类主要以《中国图书馆分类法》为依据[1],使用题名、摘要、关键词、刊名、作者和机构等信息进行分类[2].从科技文献检索的角度来说,摘要中存在文献内容的显性特征,包含着文献的观点和价值,因此,相比使用题目、关键词、刊名等文献信息,使用摘要信息进行文献分类能提高文献分类的准确率,对图书情报学科的发展具有重要意义.
文献摘要分类方法分为传统的人工方法以及机器学习和深度学习[3-4]的方法.机器学习模型的不足之处:一是贝叶斯分类器[5]在属性个数比较多或者属性关联性较大时分类效果不好;二是支持向量机算法(support vector machine,SVM)[6]对大规模训练样本难以实施,不适于解决多分类的问题.除此之外,决策树系列模型和随机森林[7-8]等方法需要足够的词语共现信息完成模型训练,而这些信息恰好是文献摘要文本所缺少的.对原始文本数据进行特征处理后,为了让计算机更好地理解自然语言,需要将处理后的数据转换为文本表示.常用的文本表征方式包括词袋模型[9]、N元模型(N-gram)、词频逆文档频率(term frequency inverse document frequency,TF-IDF)[10]、Fasttext等[11].文本表示之后,利用网络模型将获取的有效信息拟合并计算模型参数.在过去的几十年中,短文本分类技术迅猛发展,分类性能明显提升.论文摘要是一类极具研究价值的短文本数据,所以利用摘要对论文进行分类与推荐具有重要意义.但是,目前可检索到的摘要自动分类的研究却很少.
随着深度学习技术[12-15]的广泛应用,为了解决当前文献分类领域存在的问题,将短文本分类方法迁移到摘要自动分类中,希望能够提升摘要自动分类性能.以文献数据库中已广泛存在的大规模摘要数据集为训练语料,实现文献自动分类效果的提升.其中,基于预训练语言模型的方法在这些文本分类任务中取得较大突破,比如Word2vec[16]和One-hot[17]编码等.但是,这些预训练模型对短文本中词与词的关联性把握不准,不能获得关联紧密的边和节点的特征信息.转换器的双向编码器表示模型(bidirectional encoder representation from transformers,BERT)[18]用预训练中的双向表示和自注意力机制模块进行训练,得到上下文语义特征,在短文本分类任务中获得了显著提升.图卷积神经网络(graph convolutional networks,GCN)可实现节点特征和边特征的端到端学习.但是,用于短文本分类任务的多层GCN会导致节点特征过度平滑,使局部特征收敛到一个近似值,导致分类性能下降.Yao等[19]提出了文本图卷积网络模型(Text GCN),可根据词共现和文档词关系建立一个文本图的语料库,可学习单词嵌入和文档嵌入.但Text GCN不能快速生成嵌入向量,对无标签文档的预测效果不好.
为了改善模型的分类效果,本文提出一种基于BERT-GCN-ResNet的文献摘要自动分类方法,该方法利用BERT得到待分类短文本的词向量初始特征,进而构建边和节点的特征并将其输入GCN,然后在图卷积层之间加入ResNet结构,最后将利用图卷积层和ResNet层得到的短文本表示输出至softmax[20],得到最终的分类结果.同时,为了防止过拟合,在图卷积层引入了Dropout技术,旨在有效提高短文本分类的准确率,得到较好的分类效果.
1 BERT-GCN-ResNet模型设计
1.1 模型算法
在数据输入BERT-GCN-ResNet模型前,构建词节点和文档节点的异构图.根据词频逆文档频率(TF-IDF)和点互信息(PMI)分别计算文档节点、词节点之间的边的权重和两个词之间的权重:

式中对于PMI值定义为

其中:#W(i)为语料库中包含单词的滑动窗口的数目;#W(i,j)为滑动窗口的数目,同时包含单词i和j的窗口;#W为语料库中滑动窗口的总数.PMI值为正数时,表示语料库中单词的语义相关性较高,反之则表示语料库中单词的语义相关性较低或者没有相关性.因此,只需要在PMI值为正数的词之间添加边.
在BERT-GCN-ResNet模型中,使用标识矩阵H作为初始节点特征,在BERT预训练模型中得到特征节点表示向量为

GCN是一个多层神经网络,适用于任意拓扑结构的节点与图,可同时学习节点特征与结构信息.这种特殊的拓扑结构通过一次卷积可使每一个节点都拥有其邻居节点的信息.因此,在节点分类与边预测任务中,GCN效果远远优于其他方法.将其应用于文本处理,并根据节点的邻域属性进行节点嵌入向量.第i层GCN层输出特征矩阵计算式为

为特征向量的维度;ρ为激活函数Tanhshrink.本文模型为两个GCN层,计算式为


损失函数为多分类合页损失函数
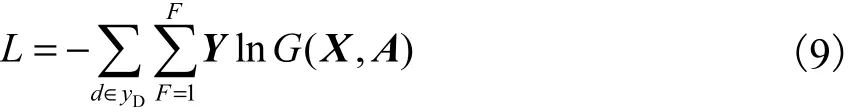
其中:G为BERT-GCN-ResNet模型经过softmax后的最终输出表达式,yD为具有标签的文档索引集合,F为输出特征的维度,Y为标签矩阵.权重参数W0和1W可以通过梯度下降训练.
1.2 网络结构
本文提出的基于BERT-GCN-ResNet文本多分类模型由BERT、GCN和ResNet[21]组成.首先,在文本输入之前,对需要的文本进行数据清洗,去除无用的停词和错误的数据,目的在于提高数据准确率和节约计算成本;其次,使用BERT-base对数据处理后的短文本中每个词进行初始特征表示.BERT使用MaskedLM可实现深层双向联合训练,使其更易于理解文中上下两个句子之间的联系.因此,将BERT生成的词向量添加到模型中,提升模型分类性能.在特征表示层中,为有效提高分类性能,构建了文本图卷积网络GCN,根据词共现和文档词建立单个文本图的语料库,同时学习单词嵌入和文档嵌入.为了充分学习上下文的更多语义信息,提高模型分类性能,引入ResNet模块.在分类输出层中,使用多分类合页损失函数MultiMarginLoss作为训练模型的损失函数,通过softmax函数生成每个类别的概率,并根据概率值进行短文本类别预测.
BERT-GCN-ResNet整体网络结构如图1所示,其中左半部分为子结构BERT模型网络结构.首先将数据清洗后的短文本处理成词向量的形式[ H1,… ,Hn]T,然后经过12个Multi-layer Transformer模块得到新的词向量文本表示[ X1,… ,Xn]T,最后构建图数据结构P.Multi-layer Transformer由Multi-head self-Attention模块和Layer Normalization模块构成,并且引入了残差模块R.将BERT处理得到的图结构数据输入到GCN-ResNet Layers模块,如图1右半部分所示.在图卷积层之间引入 ResNet模块,这种跳跃连接方式将有助于解决梯度消失和爆炸问题;在训练网络时,可保证良好的性能,进而提高网络的提取特征能力和模型的分类性能.通过softmax函数得到最终的输出结果Z,生成每个类别的预测值,并根据预测值的大小进行短文本类别判定.
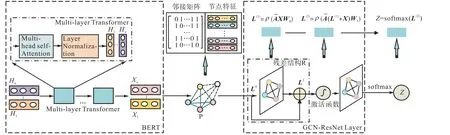
图1 BERT-GCN-ResNet网络结构Fig. 1 BERT-GCN-ResNet network structure
2 实验设计
2.1 实验环境
实验在Win 10(64位)操作系统上进行,以深度学习框架Pytorch 1.6.0为基础,编程语言采用Python 3.7.实验使用的GPU为NVIDIA GeForce RTX 2080 Ti,其显存为11GB,CPU为 Intel Xeon CPU E5-2678 v3 六核,其内存为62GB.
2.2 数据集
本文在5个基准短文本数据集R8、R52、AGNews、TagMyNews、Abstext上进行实验.
R8是Reuters21578数据集的一个子集.R8[19]有8个类别,被分为6906个训练文件和768个测试文件.
R52是Reuters21578数据集的一个子集.R52[19]有52个类别,训练集中文件8190个,测试集中文件909个.
AGNews[22]是由2000多个不同的新闻来源搜集的超过100万篇新闻文章构成的.实验从中随机挑选7600条新闻并分为4类,其中训练集中文件6840个,测试集中文件760个.
TagMyNews是Vitale于2012年[23]发布的基准分类数据中的新闻标题数据集.该数据包含7类,实验从中随机挑选9794个数据并分为7类,其中训练集中文件8814个,测试集中文件980个.
Abstext是使用网络爬虫技术在爱思唯尔数据库自动获取的英文文献摘要数据集[24],经过数据处理后得到3557条数据,分为3个类别,其中训练集数据3200个,测试集数据357个.
对上述数据集进行预处理,标记文本数据,删除在NLTK(natural language toolkit)库中定义的停词以及在R8、R52、AGNews、TagMyNews、Abstext中出现小于5次的低频单词.预处理后数据集的统计数据见表1,其中平均长度指单词个数.
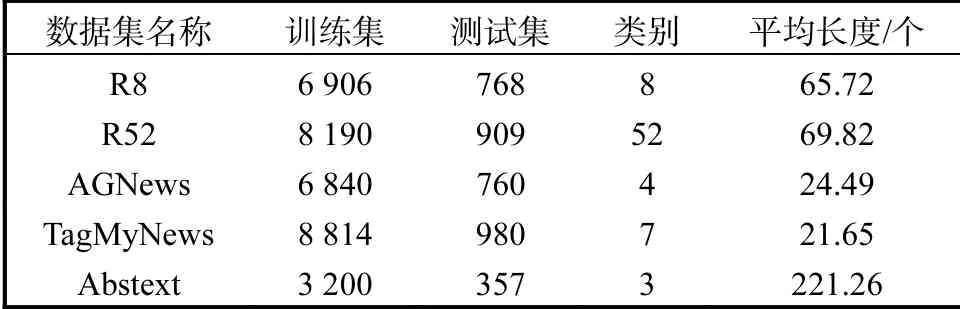
表1 数据集的统计数据结果Tab. 1 Statistical results of the data sets
2.3 实验结果与分析
实验均采用Adam[25]优化器优化损失,epoch为200,学习率为 0.1,在 R8、R52、AGNews、TagMyNews短文本数据集上进行短文本分类准确性检测,并按照训练集与测试集比例为9﹕1进行划分数据集.按照图1所设计的网络模型进行训练,将预处理后的短文本转换为BERT词向量并输入到BERT-GCN-ResNet网络.实验对比朴素贝叶斯(naive Bayesian,NB)、决策树(decision tree,DT)、随机森林(random forests,RF)、SVM、Fasttext、卷积长短时记忆网络(convolutional long short-term memory,CLSTM)[26]、卷积神经网络(convolutional neural network,CNN)、门控循环单元(gated recurrent unit,GRU)、长短时记忆网络(long short-term memory,LSTM)、双向长短时记忆网络(bidirectional long short-term memory,Bi-LSTM)和GCN短文本分类的平均准确率,实验结果见表2.

表2 短文本分类任务准确率Tab. 2 Accuracy of short text classification task
由表2可知,BERT-GCN-ResNet模型的分类准确率在R8、R52、AGNews、TagMyNews数据集上分类性能表现良好,其中在R8数据集上准确率高达97.01%,比GCN模型有所提高,说明本文改进的模型具有更加理想的短文本分类性能.本文模型在R52、AGNews、TagMyNews数据集分类效果也明显优于其他方法,尤其在TagMyNews数据集上. TFIDF+NB、TF-IDF+DT和TF-IDF+SVM等传统的分类模型的分类效果不理想,在数据集R8和R52分类准确率较低,特别是在数据集R52上,本文模型分类准确率比其提高15%.相比于GCN模型,本文模型分类性能最高提升31%,即使是在CNN、Fasttext、CLSTM等其他基准模型分类效果表现不好的数据集TagMyNews上,也能够表现出良好的分类性能,准确率为85.54%.实验结果表明,本文提出的BERTGCN-ResNet网络模型在短文本数据集上的分类效果显著.
为了验证本文提出BERT-GCN-ResNet网络模型的有效性,采用上述评价指标对各模块进行消融实验,并计算在每个数据集上的准确率,实验结果见表3.与GCN相比,本文模型加入BERT模块后,在数据集AGNews和TagMyNews上的准确率分别提高18.96%和30.22%;在数据集R8上,准确率略微提升;在数据集R52上,准确率略微下降.这表明BERT可获取上下文相关的双向特征表示,在分类任务上优势明显.引入ResNet模块,本文模型在数据集AGNews和TagMynews上,准确率分别提高19.62%和29.71%;在数据集R52上,准确率略微提升;在数据集R8上,准确率略微下降.实验结果证明,引入ResNet可以提高网络提取特征能力,提升分类效果.由于个别短文本语义相近,在文本预训练时出现文本表示相同的情况,造成语义混淆,导致在单独引入BERT或ResNet模块时,在数据集R52和R8上的准确率会略有下降;同时引入BERT和ResNet模块后,在所有实验数据集上准确率均有所提高.由此可见,本文模型融合了BERT、GCN和ResNet的优势,增强了文本语义特征提取能力,又凭借GCN适用于任意拓扑结构的独特优势,在节点分类任务中效果明显优于其他模型,因此,BERT-GCNResNet模型能够使短文本分类性能提升.
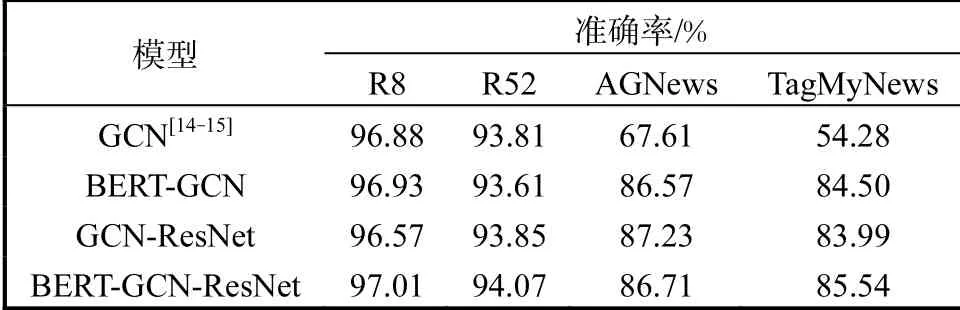
表3 BERT-GCN-ResNet模型消融实验Tab. 3 BERT-GCN-ResNet model ablation experiment
将该模型在短文本摘要数据集Abstext上进行验证,结果见表4.
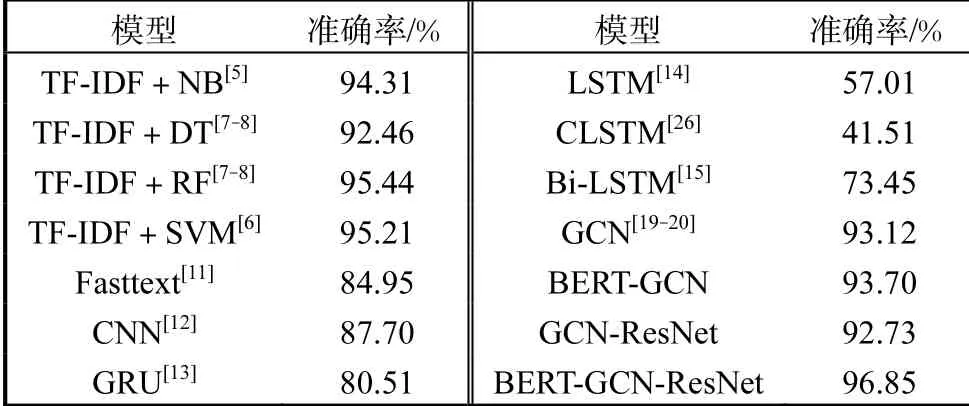
表4 Abstext实验结果Tab. 4 Abstext experimental results
同TF-IDF+NB、TF-IDF+DT、TF-IDF+RF、TF-IDF+SVM、Fasttext、CNN、GRU、LSTM、CLSTM、Bi-LSTM、GCN等基准模型对比,本文模型的文献摘要自动分类结果准确率为96.85%,比GCN提高了3.73%,比TF-IDF+DT网络的准确率提高了4.39%,明显优于其他基准模型,表明该模型具有良好的泛化能力.由于BERT和ResNet模块可以提取短文本更多特征信息,进而提高短文本分类的准确率.实验结果表明,引入BERT预训练模型到GCN和ResNet融合网络中对于短文本分类效果的提升具有一定优势,尤其是在语义较为稀疏的短文本中表现出更好效果.例如在AGNews和TagMyNews数据集上,BERT-GCN-ResNet网络模型比GCN的实验结果分别提高了19.10%和31.26%. 这表明该模型可以充分地学习文本中包含的长距离依赖和上下文信息,能够获得更加丰富的语义表示,可以极大促进短文本文献摘要分类性能的提升.
3 结 论
本文提出一种基于BERT-GCN-ResNet的文献摘要自动分类方法.将文献摘要分类问题转化为短文本节点分类问题.BERT可以完成深层双向联合训练的任务,获得上下文相关的双向特征表示,因此,该方法利用BERT模型获得预训练的词向量,进而构建边和节点特征信息,将其输入融合了ResNet模块的两层GCN网络中,进一步提高网络对文本语义特征的提取能力,实现浅层网络训练,即可达到深层网络训练的效果.将GCN和ResNet层得到的短文本表示输出至softmax分类器,得到最终分类结果.该方法在4种不同短文本数据集上进行准确性验证,准确率最高为97.01%,优于基准模型.在本文构建的文献摘要数据集Abstext上进行验证,结果表明该模型具有良好的泛化性能,提高了文献摘要自动分类的准确性.
在未来的研究工作中,本文将从如何构建更富含语义信息的图特征出发,进一步提升模型提取语义特征信息的能力.同时,本文是将多标签数据处理成单标签进行多分类,具有一定的局限性,后续将探索在面对多标签的分类问题上,如何实现较好的分类效果.
