一种融合长尾系数的混合电影推荐算法
2022-04-21董云薪
董云薪,林 耿
(1.福建农林大学计算机与信息学院,福建 福州 350002;2.闽江学院数学与数据科学学院(软件学院),福建 福州 350108)
随着信息技术的快速发展与广泛应用,信息资源量呈螺旋式增长。当前信息传播方式相较于过去更加多元化,人们可以通过手机、电视、电脑、书籍等方式来获取信息,且随着互联网传播技术的快速发展,人们也可以更加快捷地获取信息,使得信息更具有时效性,但与此同时也使得“信息过载”问题的产生[1]。“信息过载”问题是人们获取大量信息的同时,依靠自身能力无法从大量信息中及时有效的提炼出真正所需的信息[2]。因此,研究学者们提出了“推荐系统”来应对这一问题,“推荐系统”可以帮助用户在大量信息中及时地提炼出用户所需信息,为用户节省信息检索时间,帮助用户提高对于信息的使用效率[3]。
推荐系统主要依托于推荐算法,其中协同过滤算法是应用最为广泛的推荐算法[4]。目前大多数推荐算法主要是以提高算法精度为目的,而忽略了算法的多样性。为了提高算法精度,推荐结果往往会集中于一小部分的热门头部产品,而缺乏对于大部分尾部产品的推荐[5]。从用户角度出发,若推荐算法单纯以提高算法精度为目的,推荐结果绝大部分将会为常见的热门产品,而这类产品用户通常已经表达过喜好了,再为用户推荐这类产品,可能无法满足用户对于推荐系统多样性的需求[6]。从商户角度出发,推荐系统的多样性偏低,使得大部分尾部产品缺乏推荐,商家无法提高商品的总销售额[7]。因此,提高推荐算法的多样性,帮助尾部产品获得有效推荐,应成为今后推荐算法的关注焦点之一。
推荐算法多样性有着许多方向的研究,其中如何平衡算法精度和算法多样性的关系,是研究的重要方向之一。算法精度和算法多样性是相互对立的,在提高算法多样性的同时,算法精度会相对降低,提高算法多样性则意味着要牺牲一定的算法精度。因此,如何在提高算法多样性的同时又确保算法具有较高精确度是一个重点研究方向。
针对此问题,本文提出一种融合长尾系数的混合电影推荐算法,利用混合协同过滤推荐算法来提高算法精度,然后通过用户观影行为来计算电影项目的长尾系数,用以改进预测评分公式,以此来提高推荐算法的多样性。
1 相关研究
对于推荐算法多样性不足的问题,许多学者从不同研究角度提出了改进。文[8-9]主要是通过缓解长尾问题的角度出发来对算法进行改进。秦婧等提出一种关于长尾问题的推荐算法,首先在深度学习的基础上构建一个推荐系统中长尾物品的推荐框架,其次在该推荐框架中的推荐算法层,计算推荐物品中被频繁推荐的热门头部物品和未被频繁推荐的冷门长尾物品,然后用冷门的长尾物品替换被频繁推荐的热门头部物品来达到推荐系统中指定的长尾比例的阙值,达到缓解长尾问题的目的,从而进一步提高推荐结果的多样性[8]。邓明通等提出一种基于用户偏好和动态兴趣的多样性推荐方法,先根据用户历史行为数据得到用户的偏好数据,结合时间函数因子调整原始用户项目评分,然后结合受长尾分布影响的项目疲劳因子,最后利用聚类函数为新用户寻找最为信任的近邻用户,通过解决冷启动和长尾问题,提高算法的多样性[9]。
文[10-13]通过研究用户潜在行为来提高算法多样性。李卫疆等提出了一种多样化推荐算法,通过挖掘用户群间的潜在兴趣,来对用户项目中未评分的项目进行预测评分,将含有用户潜在兴趣的用户评分矩阵进行奇异值分解,在保证算法精确率的同时,提高了算法的多样性[10]。黄继婷等提出一种融合偏好度与网络结构的推荐算法。先根据用户的历史观影行为得到用户的偏好度,再将用户偏好度与基于二部图随机游走推荐算法相融合,得到含有用户偏好度的初始项目推荐列表,再根据用户标签挖掘用户的潜在喜好,得到含有用户潜在喜好的项目推荐列表,最后将两个推荐列表相结合,为用户进行最终项目推荐,提高算法多样性[11]。Nima Joorabloo等提出了一种基于概率图谱的推荐系统,先通过对用户进行调查研究等,得到用户的偏好,再将研究所得的用户偏好融入基于概率图的推荐系统中,用以提高算法的多样性[12]。田维安等提出了基于相似用户好奇心的多样性推荐方法,通过计算用户的异常评分值,来计算用户的好奇心评分,将所得到的好奇心评分融入用户项目评分中,用以提高推荐算法的多样性[13]。
文[14-16]通过将项目信息融入推荐算法,用以提高算法多样性。Tommaso Di Noia等提出一种自适应多属性的多样化推荐系统,首先通过项目属性来计算项目多样性,然后利用项目多样性重新排列TOP-N推荐结果项目列表,提高推荐结果的多样性[14]。Anupriya Gogna等提出了一种基于单阶段优化的解决方案,在协同过滤的矩阵分解模型中,通过挖掘用户潜在信息作为算法多样性的约束条件[15]。叶锡君等提出一种基于项目类别的协同过滤推荐算法多样性研究,在基于项目的协同过滤推荐算法的基础上,利用项目类别信息来构建项目类别贡献函数,用以改进预测评分公式[16]。
以上这些研究通过研究长尾问题、用户潜在行为、项目信息等来提高算法多样性,没有充分考虑到用户潜在行为与长尾问题之间的联系对推荐结果的影响。本文提出融合长尾系数的混合电影推荐算法,首先通过用户的原始评分行为来计算电影项目的长尾系数。然后在基于项目的协同过滤算法基础上融入长尾系数因子,改进预测评分公式来计算项目的预测评分,用以填充项目的评分数据。最后,将填充过后的项目评分应用于基于用户的协同过滤算法上,为用户进行推荐。
2 融合长尾系数的混合推荐算法
2.1 协同过滤算法
协同过滤算法中包含有基于用户的协同过滤算法(user-CF)以及基于项目的协同过滤算法(item-CF)。主要是通过用户对项目的评分来计算用户间或项目间的相似度,再计算用户未评分项目的预测评分,最后根据预测评分结果为目标用户推荐评分前N项的商品[19]。
2.1.1 评分矩阵
在协同过滤算法中,构建用户评分矩阵是计算未评分项目与用户间或项目间相似度的一个重要步骤,评分矩阵R公式为

(1)
其中,rmn表示用户m对于项目n的评分。
2.1.2 用户/项目间相似度
用户或项目之间相似度计算是推荐算法中极其重要的步骤,相似度计算对于最终的推荐结果起着决定性作用。相似度是通过用户对项目的评分来进行计算的。
用户间的相似度sim(u,v)的计算公式为

(2)

项目间的相似度sim(u,v)的计算公式为

(3)

2.1.3 预测评分
预测评分是通过用户或项目间的相似度,以及目标用户的近邻用户,来计算数据集中未被用户评分项目的预测评分,预测评分P′的公式为
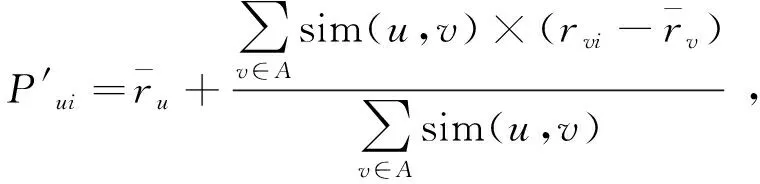
(4)
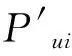
2.2 长尾系数
长尾问题是指推荐系统在为用户进行推荐时,为了追求推荐算法精确度,往往会忽略对于尾部产品的推荐,为用户集中推荐热门的一小部分头部产品,因此造成推荐结果缺乏多样性。目前推荐系统中存在着长尾问题,如在MovieLens1M数据集中存在近200部电影作品无人观看与评分的现象[17]。
因此针对长尾问题,文[18]提出一种HEF方法用于描述长尾分布现象,HEF长尾分布函数公式为

(5)
其中,x为项目被评价次数,λ和pj为常数,C为常数。
文[19]对式(5)进行比对实验,经实验得当n=2时,该长尾函数公式达到最优,则长尾分布最优公式为
P(x)=p1e-λ1x+p2e-λ2x+C,
(6)
将优化后的公式映射在[0,1]之间,作为长尾系数,缓解长尾问题,提高尾部产品推荐率,因此长尾系数公式为

(7)
其中,θi(x)i表示项目i的长尾系数,xi表示项目i的被评分次数。
2.3 算法具体描述
本文提出的融合长尾系数的混合电影推荐算法,首先通过计算项目的频繁项集,结合长尾系数计算公式得到各项目的长尾系数,用以改进预测评分公式,以此来提高推荐算法的多样性。然后通过基于项目的协同过滤算法计算预测评分,用以填充原始数据,缓解原始数据存在的数据稀疏问题。最后通过基于用户的协同过滤算法得到推荐结果为用户进行推荐。
2.4 算法具体步骤
融合长尾系数的混合电影推荐算法具体步骤如下:
输入:原始评分数据列表
输出:用户推荐列表
1)将原始评分数据集处理为项目-用户评分矩阵

(8)
2)使用式(3)计算电影项目间相似度sim(i,j);
3)计算各电影项目的被评价次数xi;
4)使用式(7)改进项目预测评分公式
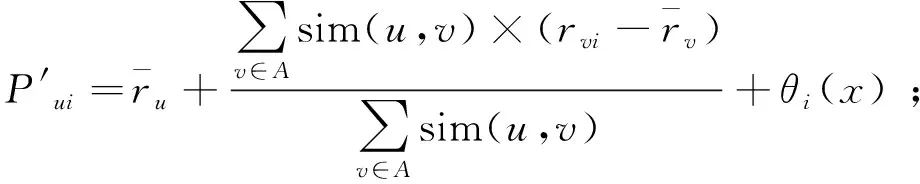
(9)
5)将填充过后的项目评分数据用于基于用户的协同过滤算法上;
6)根据上一步所得推荐结果为用户进行推荐。
3 实验结果与分析
3.1 推荐系统评价指标
本实验的推荐系统的评价指标采用准确率(precision)和召回率(recall),以及综合指标F来度量推荐算法精确度。用多样性(diversity)来度量推荐系统的多样性。
准确率又称查准率,是表示推荐给用户的项目中用户感兴趣的概率,准确率公式为
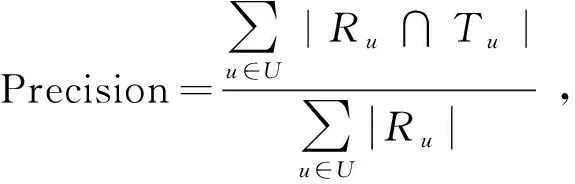
(10)
其中,Ru表示为用户推荐的电影项目,Tu表示数据集中用户喜爱的电影项目。
召回率又称查全率,表示推荐列表中的商品,推荐系统所推荐的商品为用户所喜欢商品的概率,召回率公式为
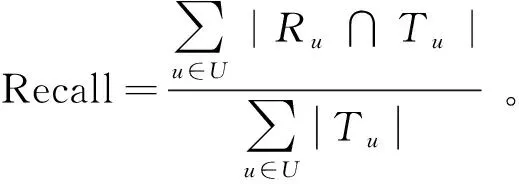
(11)
准确率与召回率是一对相反指标。二者为此消彼长关系,在推荐系统中准确率会随着推荐列表长度的增加而增加,召回率反之。因此将准确率和召回率两个指标相结合起来,构建一个综合指标F,可以更为全面地表示算法精度的高低,算法精度的综合指标F值公式为

(12)
多样性表示推荐列表中所推荐的商品种类占总商品总类的概率,多样性公式为[8]

(13)
其中,N表示推荐给用户的商品总数。
3.2 实验结果
3.2.1 实验数据集
本次实验基于MovieLens100K数据集与MovieLens1M数据集。MovieLens100K数据集共有943名用户对1 682部电影进行评分,共计10万余条评分。MovieLens1M数据集共有6 040名用户对3 883部电影进行评分,共计100万余条评分。电影评分从1~5分不等,取整数。分数越高表示用户对该电影越喜爱。本次实验采取80%数据集作为训练集,20%数据集作为测试集。
3.2.2 算法精度
在推荐系统中,设目标用户邻居数L=50,推荐电影数目n以5为单位逐步递增。在不同的电影推荐数量n下,文[4]所提及的基于用户的协同过滤算法和基于用户的协同过滤算法同本文算法(LTHCF)的算法精度综合指标F值(F-Measure)以及算法多样性指标在ML100K数据集上进行比对。
电影推荐数目n对算法F值的影响如图1所示。

图1 电影推荐数量n对F值的影响Fig.1 The effect of movie recommended number n on the value of F
由图1可知,本文所提算法LTHCF的算法精度综合指标F值在推荐数量大于25时,算法的F值会高于UserCF和ItemCF推荐算法,且之后一直保持上升趋势,而传统算法在推荐数量大于25时,F值呈现下降趋势,之后保持平稳。说明本文所提算法LTHCF较UserCF和ItemCF推荐算法,可以更好地应用于大型数据集上,且能够保持较高的算法精度。
3.2.3 算法多样性
在确保算法精度的情况下,将本文所提算法LTHCF同文[8]所提及的FLTI推荐算法及协同去噪自动编码(CDAE)算法,文[20]所提及的基于奇异值分解(SVD)算法,文[4]所提及的基于用户的协同过滤算法及基于项目的协同过滤算法进行算法多样性的比对实验。同时为保证推荐算法结果的可信度,对比算法的多样性实验将基于文[8]的MovieLens1M数据集。
电影推荐数量n对算法多样性的影响如图2所示。
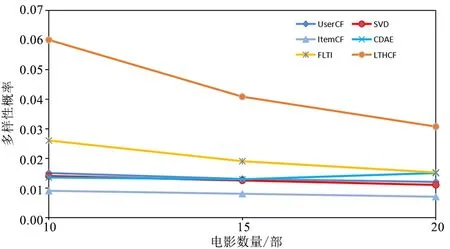
图2 电影推荐数量n对多样性的影响Fig.2 The effect of movie recommended number n on the diversity
由图2可知,本文所提算法LTHCF的多样性一直优于FLTI、SVD、CDAE、UserCF、ItemCF推荐算法,说明本文所提算法LTHCF较这5种推荐算法具有更好的算法多样性。
在确保算法多样性会优于其他对比算法多样性的情况下,将本文算法应用于具有不同数据稀疏度的数据集上进行对比,数据稀疏度是用以表示数据集中数据缺失的程度。以此来研究算法适用的数据集。将本文算法应用于MovieLens100K数据集与MovieLens1M数据集上进行比对,其中MovieLens100K数据集稀疏度约为93%,MovieLens1M数据集稀疏度约为96%。
电影推荐数量n对不同数据集算法多样性的影响如图3所示。
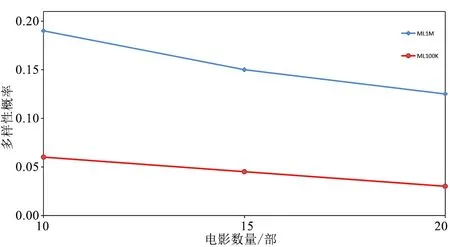
图3 电影推荐数量n对不同数据集多样性的影响Fig.3 The effect of movie recommended number n on the diversity of different data sets
电影推荐数量n对LTHCF算法较传统的UserCF算法所提高的算法多样性百分比的影响如图4所示。

图4 电影推荐数量n对不同数据集提高算法多样性百分比的影响Fig.4 The effect of movie recommended number n on improving diversity percentage of different data sets
可以看出相较于MovieLens1M数据集,本文算法LTHCF在MovieLens100K数据集上提高多样性的效果更好。这可能是因为MovieLens1M数据集的稀疏度更高,使得多样性算法的实验效果减弱,当算法所应用数据集的稀疏度较小时,算法可以更大幅度地提升推荐结果的多样性。
综合以上实验结果,本文所提算法LTHCF在确保算法精度的前提下,可以有效提高推荐算法的多样性,使得推荐系统可以具有更高的推荐质量。此外,数据集的原始稀疏度越低,越有利于本文算法提高推荐系统的算法多样性。
4 结论
实验结果表明本文算法在保证算法精确度前提下,可以有效提高推荐算法的多样性,在一定程度上提高了推荐系统的推荐质量,当数据集的稀疏度较低时,可以更大幅度地提高算法多样性。在未来的研究中,将考虑在本文算法的基础上,通过引入用户评分等间接数据来缓解数据集的数据稀疏问题,让多样性算法可以更好地得到应用,同时融合时间衰减函数进一步提高算法多样性,将时间因子融入用户评分中,充分考虑用户评分的时效性,使推荐结果更具可信度。
