融合术语信息的神经机器翻译参数初始化研究
2022-04-20张超轶张聚伟
张超轶,陈 媛,张聚伟
(1.河南科技大学 a.电气工程学院 b.外国语学院,河南 洛阳 471023;2.河南省新能源汽车电力电子与电力传动工程研究中心,河南 洛阳 471023)
0 引言
随着智能电网建设的全面展开,国与国之间电网的互联和电力技术的交互越来越密切,电气领域的机器翻译能够为电气工业的技术交流提供便利,节省许多人力物力。因此,对电气领域机器翻译的研究是十分必要的。
近年来,随着深度学习等人工智能技术的发展,词向量表示结合神经网络模型被广泛地应用于机器翻译任务中[1]。编码器-解码器模型[2]成为现在神经机器翻译的主流架构。其中,文献[3]提出的seq2seq模型、文献[4-5]提出的基于注意力机制的seq2seq模型应用最广。在此基础上,文献[6]提出的加入覆盖率机制的翻译模型在许多翻译任务上也取得了很好的效果。但是,在这些经典模型中,嵌入层参数均由随机初始化得到,模型仅利用双语语料获取词向量。然而,对于电气领域这样的低资源翻译任务,有限的双语语料规模限制了词向量对词本身所包含信息的学习,因此,需要通过词向量模型利用大规模单语语料训练得到好的词向量表示。对此,词嵌入模型应运而生,相关研究日益增多[7-9]。文献[10-12]对模型源端和目标端中的一端分别使用了预训练的Glove、Word2vec或Fasttext进行嵌入层参数初始化,另一端采用随机初始化方式进行实验,结果表明:词嵌入模型的应用对翻译效果起到了十分明显的提升作用。文献[13]采用ELMo神经网络来预训练源语言和目标语言的单语语料,从而在乌英翻译任务上取得了更好的效果。文献[14]将二次训练多语言BERT预训练模型与条件随机场(conditional random field,CRF)相结合,并采用两种子词融合方式,提出了一种新的蒙古文动态词向量学习方法。文献[15]引入了3种语言预训练模型:蒙面语言模型(masked language model,MLM)、因果语言模型(causal language modeling,CLM)和基于平行语料的翻译语言模型(translation language modeling,TLM),用于编码器或解码器的初始化节点,均提升了模型在蒙汉翻译任务上的效果。但是,对于使用通用语料训练的电气工程领域翻译模型来说,仅使用一种算法得到的词向量来初始化嵌入层参数是不够的,本研究希望引入多种词嵌入技术和术语词典来联合提升电气语料中高频常用词和低频专业术语的词向量表示,使翻译模型在提高泛化能力的同时更好地融合领域术语信息。
本文收集了与电气工程领域相关的中英文平行语料、英文单语语料及术语词典,利用Word2vec与Glove分别训练得到包含领域信息的术语词向量和包含通用文本信息的常用词向量,将两种词向量结合起来去初始化模型嵌入层矩阵中对应的参数,并利用术语词典进行文本分词和未登录词查找替换,以此来优化电气工程领域语料的翻译效果,为此后垂直领域的神经机器翻译提供一个可行的优化思路。
1 融合术语信息的神经网络模型
以文献[4]提出的基于注意力机制的神经网络模型为基线模型,利用领域内术语词典和单语语料来融合术语信息。首先,在数据预处理时利用术语词典对双语语料进行自定义分词,并使用大规模单语语料通过Glove和Word2vec分别训练得到包含通用文本信息和术语信息的词向量。其次,结合两者训练得到的词向量初始化模型的嵌入层参数。最后,针对翻译过程中由于领域内术语词造成的未登录词问题,利用外部术语词典对其进行查找替换。具体模型结构及框架流程如图1所示。
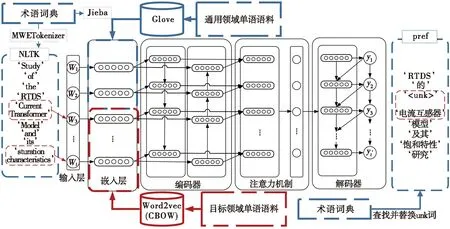
图1 融合术语信息的神经机器翻译框架图
1.1 词向量预训练
在自然语言处理中,词向量的表示方式由最初的独热(one-hot)编码发展到后来的分布式表示,将原本稀疏的巨大维度压缩到一个更小维度的空间中,并使得词表示包含了更多的语义信息[16]。本文使用两种预训练词向量方法:Glove[17]与Word2vec[18]。Glove 模型于2014年被提出,是一种基于全局信息的单词向量表示。该模型同时利用了全局的统计信息和局部上下文信息,经过预先训练可得到一套完整的词向量集。对于Word2vec,本文使用其中的一种——连续词袋模型(continuous bag-of-words model,CBOW)来预训练词向量。该模型从周围词预测中心词,使得训练的词嵌入较为集中,更容易学习源语言和目标语言中对应词的映射关系。其似然函数是由背景词生成任一中心词的概率[19],计算公式如式(1)所示:
(1)
其中:T为文本序列长度;w(t)表示时间步为t时的词;m为背景窗口大小。设vi和ui分别表示词典中索引为i的词作为背景词和中心词的向量,中心词wc在词典中的索引为c,则以wo为背景词的中心词wc的出现概率P(wc|wo)可以通过softmax函数求得:
(2)
其中:V为所有词语组成的词汇表;vo为背景词向量的平均。由此可见,Word2vec虽然学习到了词的局部信息,但没有考虑到词与局部窗口外词的联系,也忽略了计算代价高昂的事实。Glove在Word2vec的基础上利用了共现矩阵,使得训练得到的词向量泛化能力更强。本文通过Word2vec利用大规模电气领域单语语料训练得到包含更多术语信息的词向量表示,结合Glove在大规模通用单语语料上训练得到的词向量表示,使得语料中的每个词都得到充分的向量表示。
1.2 嵌入层参数初始化
目前,对机器翻译的研究可以分为通用领域机器翻译和特定的垂直领域机器翻译。前者使用通用语料训练,其训练出的神经机器翻译模型在通用语义环境下翻译出色,而在特定的专业领域文本中表现很差。而后者大多只使用本领域有限的双语语料作为训练集,限制了词向量对词本身所包含信息的学习,导致训练出的模型泛化能力弱。本文利用Word2vec训练出包含术语信息的词向量,并与Glove训练出的包含通用语料全局和局部上下文信息的词向量结合,同时提升了模型在电气领域的翻译性能及泛化能力。
首先,使用Word2vec在大规模电气领域单语语料上预训练得到的词向量初始化模型的嵌入矩阵。利用Glove在大规模通用单语语料上预训练好的公开词向量集,与翻译模型生成的数据集词表对照,对于两者共同出现的常见单词,使用Glove词向量替换嵌入矩阵中对应的向量。数据集词表中的其他单词的词向量则保持不变,依旧使用Word2vec初始化的词向量。这样将两种方式结合起来,用Glove初始化常见词,用Word2vec初始化不常见的专业术语词汇,从而使得数据集词表中的所有词汇都得到了很好的表示,弥补了语料规模小、领域不匹配的问题。
1.3 未登录词查找替换
为了对电气领域语料中由于专业术语产生的未登录词(unknown words,UNK)进行查找替换,本文在中英文分词时将电气术语词典添加为自定义分词词典,把电气专业术语更好地分割为一个整体词汇。同时,将术语词典作为翻译系统的外部词典,对模型翻译出来的句子进行未登录词查找替换。在进行中文分词时,采用jieba分词的精确模式,并利用其自定义词典功能,将术语词典添加到分词词典中,在一定程度上保证了电气专业领域术语的专业性、完整性以及一些特殊词汇的组合性,提升了其在电气专业语料上的分词效果。为了与中文句子中电气专业术语的分词相对应,本文使用NLTK分词工具中的MWETokenizer短语分词器,将术语词典中的短语设置为自定义词语来对英文句子进行分词。这样就使得模型可以准确地学习到术语词典中短语的映射关系。当翻译第i个句子时,对该句子中每一个词判断其是否在术语词典中,以此来寻找句子中是否存在专业术语。若存在,则将该句子中的术语词加入到临时的专业术语列表中。当解码过程中出现未登录词时,使用列表中对应的术语词对其进行替换。这样的做法,在一定程度上从侧面解决了识别句子中电气专业术语的问题。与训练并使用命名实体词识别模型来识别专业术语的方法相比,本文提出的方法更加简洁有效,省去了许多麻烦,并最终使得翻译模型在电气领域中的翻译效果得到了提升。
2 实验
2.1 数据集及术语词典获取
鉴于目标领域语料的特点,本文选择UM-Corpus[20]中与其相近的关于科技论文主题的30万个句子对作为训练语料。将收集到的电气专业领域语料作为验证集和测试集。其中,验证集为20 000句对,测试集为12 000句对。这些电气领域语料的来源主要有:公开专业文献资料、电气方面的中英对照书籍[21~23]、词典中包含电气术语的例句、官方组织发布的权威标准以及互联网中一些与电气相关的技术论坛、官方网站等,确保了语料的权威性、专业性和准确性。除此之外,本文还收集了包含电工学、电机工程、电力工程、电气自动化以及机械工程专业共471 945条相关术语作为外部术语词典。
2.2 实验设置与方法
2.2.1 实验数据及参数配置
本文使用Pytorch复现了Attention_nmt模型[4]以及其他3个经典的神经机器翻译模型(Seq2seq模型[3]、Luong_nmt模型[5]、Coverage_nmt模型[6])作为对比模型,来验证改进方法的有效性。在4个模型中,编码器和解码器的隐藏层单元个数均设置为256,批大小为32。由于本文所针对的电气专业领域语料多来源于科技论文,具有长难句多的特点,因此实验将训练模型所用语料的句子长度均限制在100个单词以内,长度大于100个单词的句子将被过滤掉。中文端和英文端词典大小均设定为40 000。用单词“UNK”取代其他不在词表中的低频词。实验中其他参数的设定均保持一致,学习率设置为0.000 5,并使用随机梯度下降算法和Adam算法训练模型。模型翻译结果通过双语互译质量评估辅助工具BLEU以及准确率进行评估。
2.2.2 翻译系统评价指标
BLEU算法[24]是目前业界公认的机器翻译质量评估方法。该方法认为,机器翻译的结果与人工翻译的结果越接近,机器翻译的质量越高。因此,BLEU算法的实质就是计算机器翻译句子与人工翻译句子的相似度。首先,统计两者同时出现n-gram的次数,并取较小值作为最终匹配个数,再除以机器译文的总n-gram数,从而得到修改后的精度得分pn,计算公式如式(3)~式(4)所示:
Countclip(n-gram)=min{Count(n-gram),MaxRefCount(n-gram)};
(3)
(4)
其中:Count(n-gram)为n元词在翻译结果中出现的次数,MaxRefCount(n-gram)为n元词在一个句子的参考翻译结果中最大出现的次数。对pn求对数的算术平均并加入长度惩罚因子BP,就得到了评价结果BLEU值,计算公式如式(5)~式(6)所示:
(5)
(6)
其中:c为实际机器翻译句子的长度;r为人工翻译的参考译文的长度。BLEU-1值为单独的1-gram分数,即当前一元组权重为1,其他元组的权重均为0 时的BLEU值。
除了计算BLEU值之外,本文还进行了测试集准确率的计算,将机器译文与参考译文中的词进行对比计算,得到翻译模型的准确率,从而对机器翻译结果的忠诚度进行评测,其计算公式如式(7)所示。
(7)
其中:T为机器翻译的句子;Wright为每个机器译文中翻译正确的词数量;Wnum为每个机器译文中翻译词的总数量。
2.3 实验结果及分析
2.3.1 未登录词查找替换对比实验
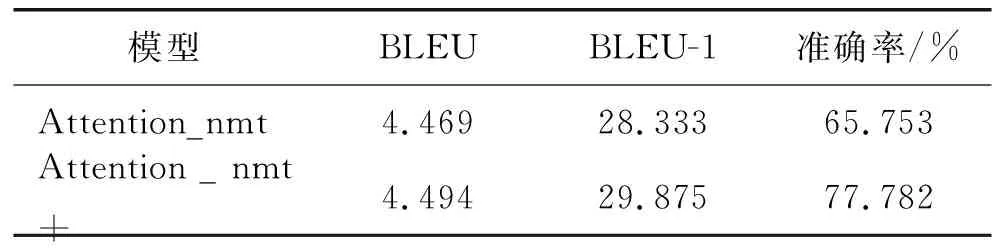
表1 未登录词查找替换实验效果对比
本文以Attention_nmt模型为基线模型,对未登录词查找替换的改进效果进行实验验证。实验结果如表1所示(表1中,“+”表示改进后的模型)。改进后得到的BLEU-1值较原模型提高了1.542,准确率提高了12.029%,整体BLEU值也有所提升。证明改进后,更多的词被单独翻译出来,提高了翻译的忠诚度。
分析整体BLEU值提升较低的原因可能有两点:一方面,Attention_nmt模型在注意力机制的作用下已经能够很好地学习到句子的上下文信息,而本文的改进只是针对提高语料中电气术语词的翻译,并不能对模型整体翻译的流畅性以及长距离依赖问题起到很好的提升作用。另一方面,本文针对电气领域翻译对中英文分词做出的改进,在一定程度上增大了切分粒度。在源端和目标端均将电气术语词的特殊组合看作一个整体来处理,将电气术语的粒度从词语变成了词组,因而可能会对模型的学习优化产生影响。
2.3.2 嵌入层参数初始化方法对比实验
对于Word2vec初始化方式,实验使用大约各95万条中文和英文混合单语语料对其进行训练得到词向量,并初始化模型的嵌入层参数。这些混合单语语料大约包含了65万条电气领域语料和30万条通用语料。对于Glove初始化方式,实验使用其官方网站[17]公开的预训练好的词向量文件,其中包含词数840 B,词表大小2.2 M,词向量维度为300。本文以添加未登录词查找替换后的Attention_nmt模型为基础,对不同嵌入层初始化方法进行对比。不同嵌入层初始化方法结果对比如表2所示。
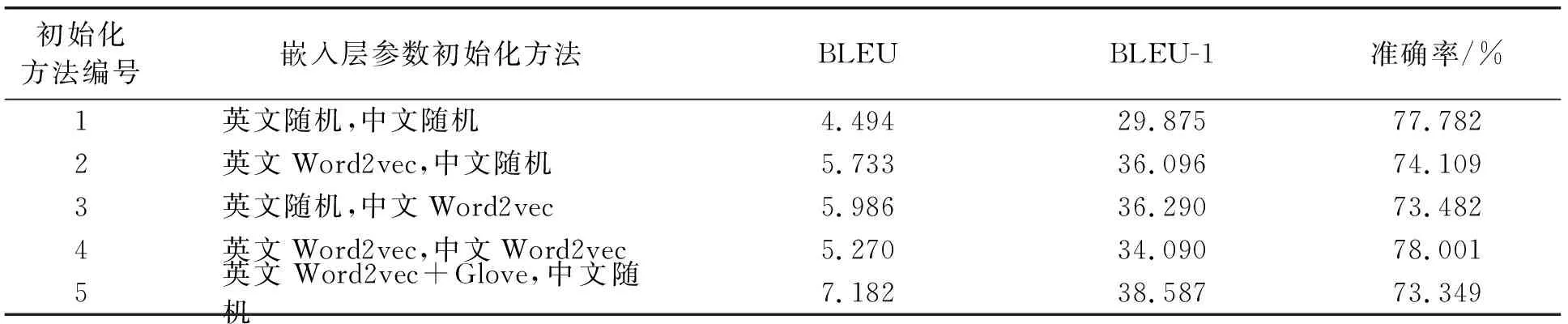
表2 不同嵌入层初始化方法结果对比
分析表2可知:
(1)对比初始化方法1、2、3,在模型源端或目标端中任一端采用Word2vec预训练词向量去初始化嵌入层参数,均能使模型的性能得到大幅度的提升,尤其是BLEU-1值,方法2和方法3较方法1分别提高了6.221和6.415。证明对于小型数据集及跨领域机器翻译,预训练词向量的必要性和有效性。
(2)对比初始化方法2、3、4,在模型源端和目标端均采用Word2vec预训练词向量去初始化嵌入层参数,虽然与方法1相比BLEU值也得到了大幅度提升,但与任一端保持随机初始化的方法2、3相比,方法4的BLEU值提升的幅度减小了很多,方法4的BLEU-1值较方法1也仅提升了4.215。分析其原因可能是由于在翻译任务中,源端和目标端是两种不同的语言,需要使用两套在不同语言的语料集上预训练的词向量,而在不同的数据集上训练的词向量并不能很好地契合,导致在源语言和目标语言中表示同一意思的词在词向量上会有很大的差异,这一差异对模型性能产生了一定的影响。
(3)对比初始化方法1、2、5,将Word2vec与Glove结合起来去初始化模型嵌入层参数的方法较其他初始化方法得到了更好的翻译效果,其BLEU-1值较方法1提高了8.712,较方法2提高了2.491。分析其翻译效果提升的原因有两点:一方面,该方法的本质是使用Glove预训练的词向量去初始化数据集词表中出现的常用单词,同时使用Word2vec预训练的词向量去初始化数据集词表中出现的罕见单词,即专业术语词汇。因为Glove预训练的词向量表示是在大规模通用语料上训练得到的,Word2vec预训练的词向量是在大规模电气领域单语语料上训练得到的,所以数据集词表中的常见词和专业术语词都能得到很好的词向量表示。另一方面,Glove在Word2vec的基础上,添加了全局的基于词语共现频率的统计信息,训练得到了泛化能力更强的词向量。用这些词向量来初始化常见词的表示,也更有利于电气领域语料的翻译。
表3是采用随机初始化的基线系统和改进嵌入层参数初始化后模型的翻译结果对比。由表3可知:改进后的翻译质量相比于基线系统都有了明显的改善。相比于采用随机初始化的翻译结果,本文提出的嵌入层参数初始化方法,在一定程度上减少了未登录词的数量,提高了语料中电气术语词翻译的准确性,使得训练得到的翻译结果语义更为完整,句子更为流畅,更加符合汉语的语言习惯。

表3 翻译结果比较
2.3.3 整体改进效果对比
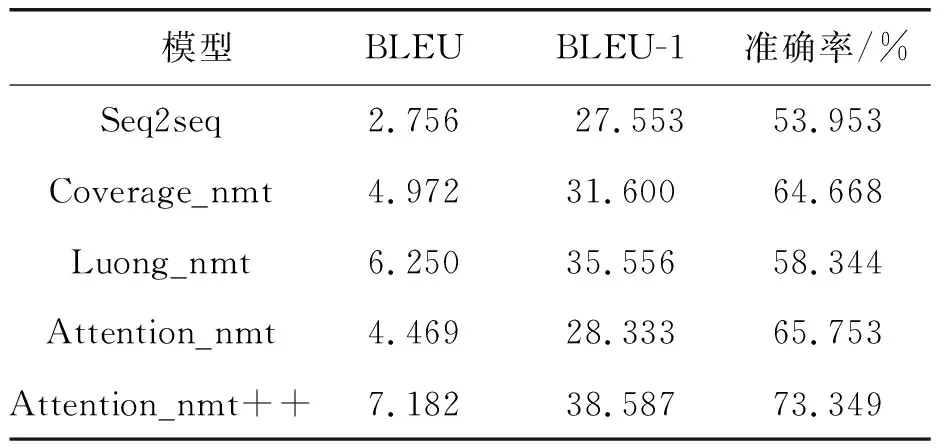
表4 不同翻译模型的BLEU值对比
为了评估嵌入层参数初始化方法的有效性,实验选取了3个经典的_nmt模型作为对比。实验结果如表4所示(表4中,“++”表示使用方法5初始化的Attention_nmt+模型),其中Luong_nmt模型采用其论文中表现最好的local_p(predictive alignment)局部注意力机制进行训练。实验中对比模型的源端和目标端词向量均使用随机初始化。由表4可以看出:整体改进后模型Attention_nmt++在电气领域语料上的翻译效果不仅明显优于自身原模型2.713个BLEU值点,同时也优于其他3个对比模型。与表现最优的Luong_nmt基线模型相比,改进后模型Attention_nmt++的BLEU值提升0.932个百分点,BLEU-1值提升了3.031个百分点,准确率提升15.005个百分点,在电气领域的翻译任务上取得了更好的翻译效果。
3 结束语
本文针对神经网络模型在电气领域英汉翻译任务上的不足,提出了一种融合领域术语信息的嵌入层参数初始化方法,并利用术语词典对未登录词进行查找替换。缓解了由于训练文本缺乏针对性而导致的专业词汇错漏等问题,有效地提升了翻译模型在电气领域内的翻译效果,同时也降低了对领域内平行语料的依赖。最终将电气领域测试集的译文BLEU值提高了2.713个点。在下一步的工作中,将尝试对神经网络模型本身进行改进,来提升模型在电气专业领域翻译上的整体性能。
