改进深度Q学习的燃料电池混合动力汽车能量管理
2022-04-20王浩聪付主木孙昊琛陶发展宋书中
王浩聪,付主木,b,孙昊琛,陶发展,b,宋书中,b
(河南科技大学 a.信息工程学院; b.河南省机器人与智能系统重点实验室, 河南 洛阳 471023)
0 引言
传统内燃机汽车造成的空气污染和能源危机问题引起人们对新能源汽车的关注,燃料电池混合动力汽车以其零污染、低噪音、续航能力强等优点被认为是最具广阔前景的新能源汽车[1-2]。能量管理对混合动力汽车的燃料经济性、能量源使用寿命以及整车动力性起着至关重要的作用[3-5]。近年来,在混合动力汽车研究领域中,多种能量管理系统被提出并应用[6-7],在实施方法上可分为基于规则[8-10]、基于优化和基于学习的能量管理策略[11]。基于规则的能量管理策略计算量小,鲁棒性强,但很难获得最优功率分配。为此,基于优化的能量管理策略被提出[12-15],其中,全局优化可以探索全局最优策略,但所需计算量大,不适合处理具有实时性的问题;局部优化具有实时性,但会受到精确车辆模型的准确性或未来行驶条件预测的影响。为解决上述能量管理策略存在的问题,基于学习的方法受到广泛关注。其中,强化学习作为一种无模型方法,被相关研究证明为适用于探索燃料电池混合动力汽车能量管理的最优策略,具有学习能力强、适应性强、计算资源消耗少的特点[16]。
在以三能量源燃料电池混合动力汽车为对象的研究中,文献[17]提出基于强化学习的分层能量管理策略,采用基于Q-学习与等效消耗最小策略的方法,兼顾全局优化与局部优化,在提高计算效率的同时获得更高的燃料经济性。Q-学习依赖查表矩阵存储每个状态-动作对的Q值,然而实际应用中通常需要连续或多维的状态变量,这导致矩阵的迭代计算量急剧增加,这种由高维数据引发的“维数灾难”成为Q-学习在复杂混合动力汽车能量管理优化中亟待解决的问题[18]。
针对上述问题,相关研究人员将神经网络结构与强化学习相结合,利用其强大的非线性逼近能力来拟合Q值,解决了高位数据带来的严重计算负担[19-20],然而深度强化学习在训练过程中的收敛性与学习效率通常难以保证。因此,本文提出一种基于功率分层与改进深度Q学习的能量管理方法,针对车辆急加减速时的峰值功率,首先采用基于模糊控制的自适应低通滤波器将峰值功率分离,并由超级电容提供或吸收;其次,设计基于深度Q学习的下层能量管理策略,采用等效消耗最小策略设计优化目标函数,为解决深度Q学习收敛性差的问题,引入基于求和树结构的优先经验回放法,提高对经验样本的学习效率;最后,进行仿真与试验验证。
1 能量管理系统
在本次燃料电池混合动力汽车试验平台中,燃料电池作为主要能量源,用于承担车辆的主要功率负载,超级电容与锂电池作为功率支持装置与储能装置,用于补偿瞬态输出功率并恢复制动能量,提升车辆的整体动力性,能量管理系统的拓扑结构如图1所示。
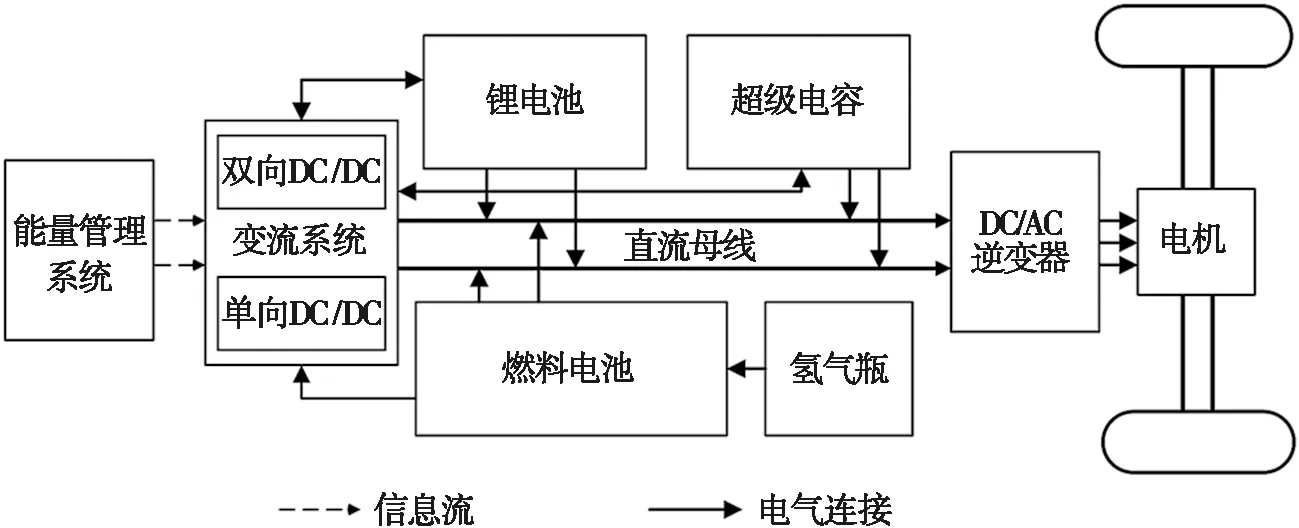
图1 三能量源燃料电池混合动力汽车的拓扑结构
燃料电池与直流母线通过单向直流/直流(direct current/direct current,DC/DC)变换器相连,保证燃料电池工作在高效率范围内,超级电容与锂电池经过双向DC/DC变换器与直流母线连接,辅助燃料电池为车辆提供需求功率。母线与DC/交流(alternating current,AC)逆变器连接,为电机提供所需功率。
2 基于功率分层与深度Q学习的能量管理策略
对燃料电池混合动力汽车能量管理策略的优化可以被视为对马尔科夫决策过程的求解,深度强化学习作为一种适于求解马尔科夫问题的无模型方法,通过探索与试错的方式来最大化累积报酬,从而搜寻在所有潜在状态下的最优动作。在完成离线优化后,生成最优策略集,可依据当前车辆状态的输入获得能量管理策略的输出。
2.1 基于模糊滤波的功率分层设计
质子交换膜燃料电池具有高能量密度的优点,但功率密度较低,更适合工作在相对稳定的输出条件下。为减少瞬时峰值功率的频率,延长燃料电池的使用寿命,提高其动态性能,本文采用功率分层结构分离车辆峰值功率,由具有高功率密度特性的超级电容来提供。
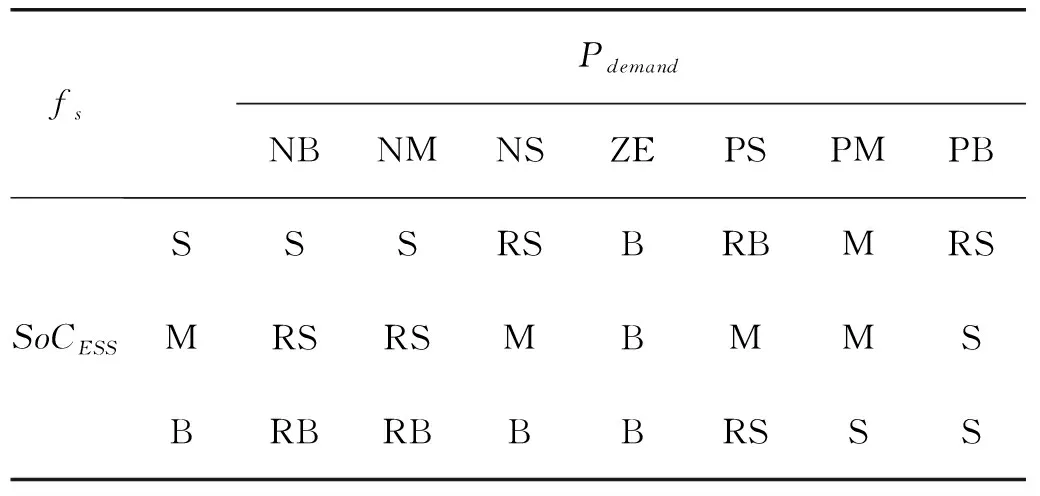
表1 模糊规则
利用基于模糊控制的自适应低通滤波器对燃料电池混合动力汽车所需功率进行分层处理,模糊推理系统的输入为车辆当前的需求功率Pdemand,以及综合电荷状态(state of charge, SoC)系数SoCESS[17]。模糊规则如表1所示,其中,fs为调节频率,通过模糊推理系统所得,N, P, S, M, B, Z分别代表(负,正,小,中,大,零)。
2.2 基于深度Q学习的能量管理策略
本文采用深度Q学习算法优化功率分层后的能量管理策略,在训练阶段采用数据驱动的方法对能量管理策略进行训练。车辆状态的数据通过汽车电控试验平台进行采集,并通过马尔可夫链将需求功率建模为具有已知概率密度函数的随机变量,采用最近邻法和最大似然估计法计算转移概率,根据当前时刻的功率和下一时刻的功率来构造需求功率的转移概率矩阵,转移概率由以下公式得出:
(1)
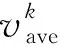
为了避免多目标优化带来的复杂计算问题,提出了一种基于等效消耗最小策略的奖励评价机制,以等效氢耗最小为优化目标构建奖励函数,等效消耗最小策略将锂电池和超级电容的瞬时电量消耗等效为燃料电池的化学能耗,具体表示如下[21]:
minCtotal(t)=kFCCFC(t)+kBATCBAT(t)+kUCCUC(t),
(2)
其中:minCtotal(t)为总瞬时最小氢消耗量,包括燃料电池的直接氢消耗量CFC(t)、锂电池的等效氢消耗量CBAT(t)和超级电容的等效氢消耗量CUC(t);kFC为使燃料电池以高效率水平运行的燃料电池效率惩罚系数;kBAT和kUC是根据锂电池和超级电容SoC计算的等效因子。考虑实际能量源的参数,等效消耗最小策略的具体约束如下[17]:
SoC与功率的约束:
(3)
其中:SoCref为锂电池的参考SoC;SoCBAT.ch与SoCBAT.disch为锂电池的充放电效率;PFC.min与PFC.max为燃料电池的最小与最大输出功率;-PBAT与PBAT为锂电池输出功率范围,所有约束边界均由燃料电池混合动力汽车试验平台所得[17]。
在以燃料电池混合动力汽车的燃料经济性与锂电池使用寿命为共同优化目标的前提下,所提出深度Q学习算法的奖励值r通过以下公式计算:
r=Ctotal(t)+κ×(ΔSoC)2,
(4)
其中:Ctotal(t)为瞬时的氢消耗量;ΔSoC为当前锂电池SoC与基准SoC的偏差;κ为调整系数,目的是使Ctotal(t)与(ΔSoC)2处于同一量级。
深度Q学习是一种离线训练-在线决策的算法,所提出能量管理策略的离线训练过程如下。
通过在所有潜在的车辆状态s下(包括:需求功率Pdemand,车速,锂电池与超级电容SoC,超级电容输出功率)利用贪婪策略ε-greedy选取动作(即能量源的功率分配),再以等效消耗最小策略为主体的奖惩机制中获得相应状态-动作下的奖励值r,并采用概率转移矩阵预测下一状态。
深度Q学习中Q值的更新方式如下:
Q(st,a;θ)←Q(st,a;θ)+α[TargetQt-Q(st,a;θ)];
(5)
(6)
L(θ)=E[(TargetQt-Q(st,a;θ))2],
(7)
其中:θ为深度Q学习的网络参数,Q(st,a;θ)为通过神经网络逼近的当前Q值;TargetQt为目标网络的Q值;α为学习率;γ∈[0,1]为折扣因子;估计网络的结构与目标网络的结构相同,且初始化权重相同,L(θ)为均方误差函数。在完成离线训练后,生成决策集,可实现对燃料电池混合动力汽车的实时能量管理。
2.3 基于优先经验回放的深度Q学习改进
针对深度Q学习中传统经验回放方法存在抽样随机性较大、学习效率低、大部分样本奖励值为0的缺点,采用了一种更有效的经验提取方法,通过引入求和树结构的优先经验回放机制,将每个经验的优先级值视为一个叶节点,两个节点作为一个组,向上叠加,树根的值是所有经验的优先级值之和。采样时,首先划分批次大小区间,从每个区间中随机采样,然后逐节点搜索采样的经验值,确定最终采样数据。这种采样方法可以在无需遍历经验池的情况下提取优先级高的样本,减少计算资源的消耗,提高模型的训练速度。经验样本(st,a,r,st+1)的优先级值由TD-error来表示,TD-error与经验样本提取概率pi由以下公式计算得出:
(8)
(9)
当|TD-error|较大时,意味着当前Q函数距离目标Q函数较远,应进行更多更新。同时采用概率的方式提取经验,确保即使TD-error为0的经验也能被提取,避免网络出现过拟合现象。
引入优先经验回放后,改进深度Q学习的离线优化过程如下:首先,对经验池容量、估计网络Q和目标网络QTarget的权重θ进行初始化;在迭代训练时,通过贪婪策略进行动作选择,并计算TD-error来更新估计网络与目标网络的权重;对于历史样本数据,采用基于求和树的方式处理,优先采样高概率的样本。
3 仿真实验及分析
3.1 算法收敛对比分析
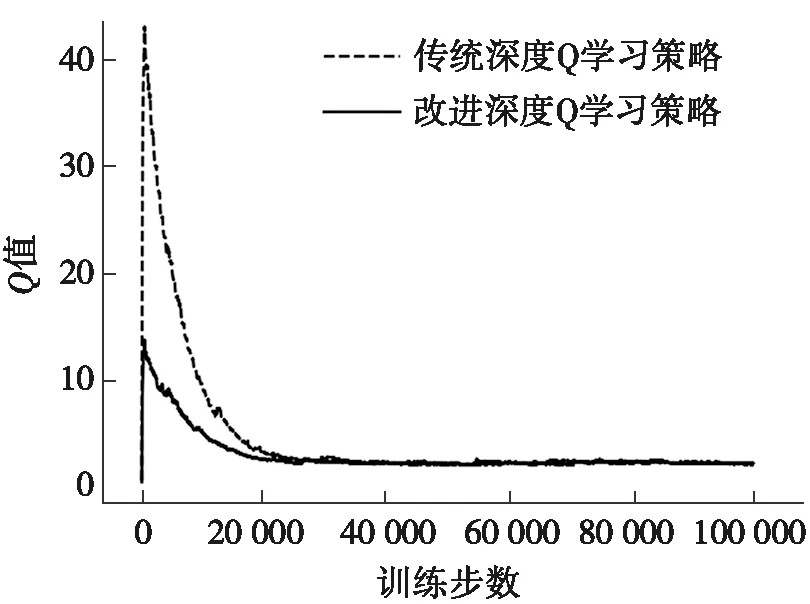
图2 Q值变化趋势对比
本节中,将基于优先经验回放深度Q学习与传统深度Q学习进行比较,通过在Q值变化趋势上的对比,表明所提出能量管理策略在离线优化过程中的优势。图2为两种算法下Q值的变化趋势对比图。由图2可以看出:在相同的训练步数下,传统深度Q学习算法下Q值的初始训练点较高,且收敛速率较为缓慢,引入优先经验回放机制后Q值的初始训练点降低,且收敛程度出现显著提高,经过10×104次迭代后趋近理想结果。这表明引入优先经验回放机制将提升深度Q学习的收敛性。
3.2 工况测试下仿真及分析
在本节当中,所提出的能量管理策略在世界轻型车辆试验程序(world light vehicle test procedure,WLTP)、城市测功机行驶计划(urban dynamometer driving schedule,UDDS)、新标欧洲循环测试 (new European driving cycle,NEDC)、西弗吉尼亚郊区循环工况(West Virginia university suburban cycle,WVUSUB)4类典型工况下进行仿真,并与传统深度Q学习进行对比以验证其有效性。在仿真中,锂电池和超级电容的初始值SoC被设计为0.7。
图3为WLTP能量管理策略下燃料电池、锂电池和超级电容的输出功率,以及锂电池和超级电容的SoC变化趋势。图3a是WLTP工况的速度变化图,整段工况约1 800 s。图3b为功率分配图,从图3b中可以看出:燃料电池工作于相对平稳的输出环境下,输出功率随着车速的提升而逐渐增加。当车辆的需求功率因急加减速而出现剧烈波动时,由超级电容主要承担或吸收这部分峰值功率,锂电池作为燃料电池与超级电容之间的缓冲能量源,其功率波动在可接受范围内。从图3c可以看出:每600 s锂电池的电量消耗约为5%。图3d为所提出能量管理策略与基于传统深度Q学习策略的燃料电池输出功率对比图,从图3d中可以看出:所提出策略可有效提升燃料电池的工作效率。
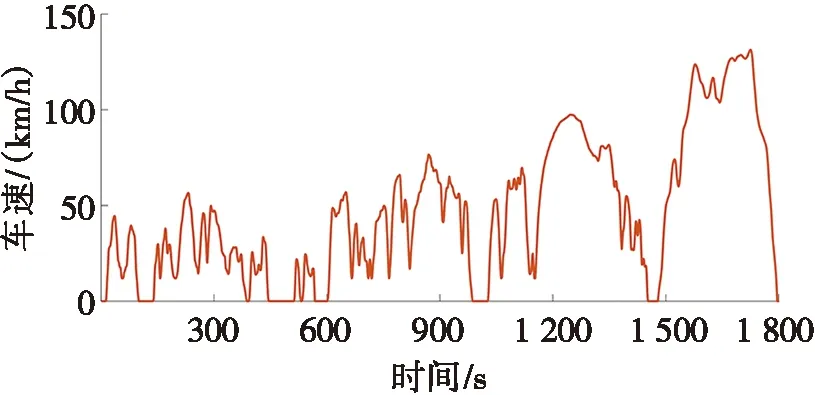
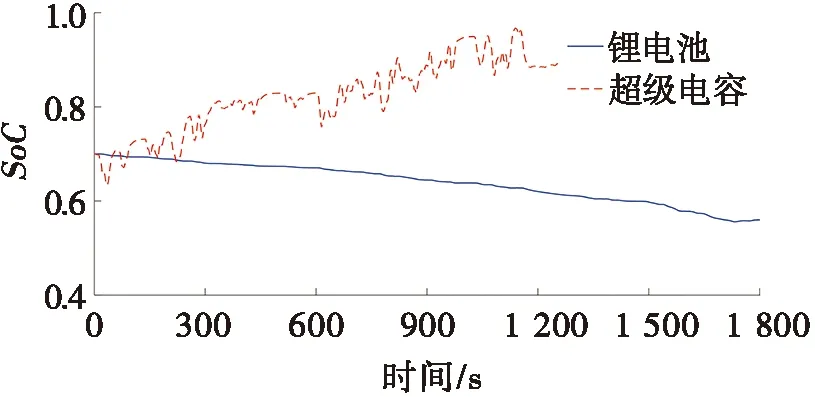
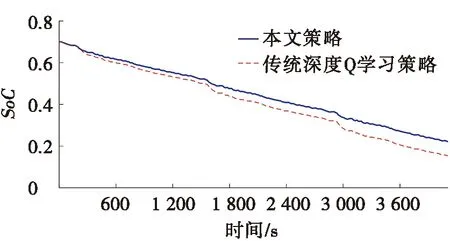
图4 UDDS工况下的锂电池SoC比较
此外,为验证所提出能量管理策略在延长锂电池使用寿命上的有效性,本文以基于传统深度Q学习的策略为对比。仿真结果如图4所示。在UDDS循环工况中,本文所提出能量管理策略的SoC变化更为稳定,在初始SoC为0.7时,最终SoC下降到0.26,平均电量消耗为每600 s消耗6.4%,而基于传统深度Q学习的策略最终SoC为0.16,平均电量消耗为每600 s消耗7.8%,所提出策略减少了电量消耗,有效延长了锂电池的使用寿命。
上述仿真结果充分表明,所提出的能量管理策略能够实现燃料电池混合动力汽车的能量管理,提高燃料电池工作效率,减少锂电池电量消耗。本文将传统深度Q学习策略作为对比方法,通过比较不同循环工况下的等效氢消耗,证明所提出方法在燃料经济性方面的提升。
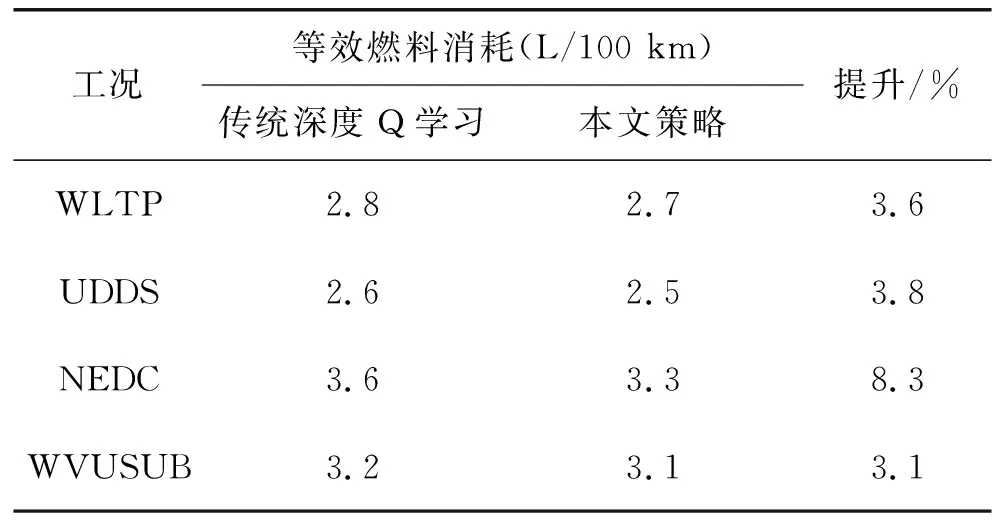
表2 燃料经济性比较
燃料经济性比较见表2。由表2可知:在WLTP工况条件下,本文所提出能量管理策略在燃料经济性上与基于深度Q学习方法相比提升3.6%,在UDDS、NEDC和WVUSUB这3种典型工况下平均提升5.1%,在NEDC工况下的提升最为明显,达到8.3%,表明本文的策略对各种工况条件都具有较好的适应性且优于传统深度Q学习的策略。
3.3 试验验证
为了进一步证明本文能量管理策略的实用性和实时控制性能,本次研究采用以工控机、三相交流电机、燃料电池、锂电池、超级电容、测功机等构成的试验平台进行台架试验。在基于LabVIEW的开发环境下,本文的能量管理策略设置在集控系统上。本次试验平台使用测功机模拟路面阻力,忽略空气阻力,通过油门和刹车踏板对车速进行控制。
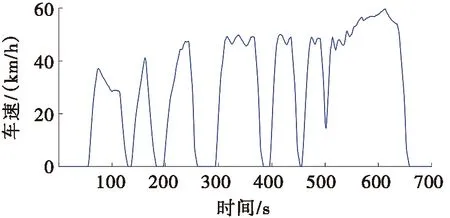
图5 试验工况的车速
图5为试验工况的车速。图6为3种能量源功率分配及SoC变化图。图6a为燃料电池、锂电池与超级电容的功率分配,由图6a可以看出:在所提出策略的指导下,燃料电池混合动力汽车大部分峰值功率由超级电容提供,燃料电池的输出平稳,且长时间工作于高效区间。而锂电池功率波动较超级电容相对平稳,负责补偿车辆剩余需求功率。图6b为所提出策略下锂电池与超级电容的SoC变化,其中,超级电容因提供或吸收峰值功率的缘故,导致SoC波动较大,而锂电池的SoC呈缓慢下降趋势,其电量消耗为每600 s消耗8.4%。
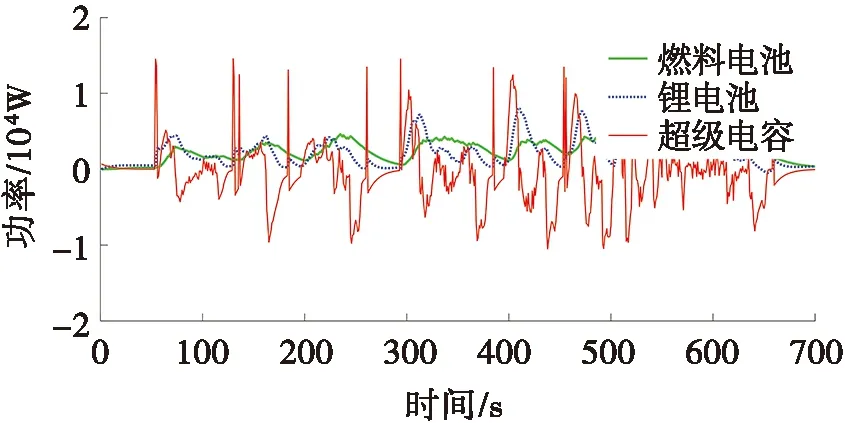
(a) 功率分配 (b) 锂电池与超级电容SoC变化
4 结束语
(1)考虑到燃料电池、锂电池及超级电容3种能量源各自工作特性的不同,设计基于功率分层与深度Q学习方法的能量管理策略,以等效消耗最小策略为基础构建多目标优化函数,并引入基于求和树结构的优先经验回放机制用于提升深度Q学习的离线学习效率与收敛性。
(2)与基于传统深度Q学习的能量管理策略相比,所提出的能量管理策略可提高燃料电池混合动力汽车的整车动力性,并有效延长锂电池使用寿命,使燃料经济性平均提升5.1%。
然而,本文设计的能量管理策略旨在满足车辆动态性能要求和提升燃料经济性的前提下,对3种能量源进行功率分配优化,但对能量源退化问题没有深入研究,这将是下一步工作的重点。
