基于粗糙集属性约简法的植烟土壤肥力评价分析
2022-04-20汪金玲李春顺杨雪彪邵长营
褚 旭,汪金玲,李春顺,赵 阳,杨雪彪,邵长营,王 飞,杨 康*
1.江苏中烟工业有限责任公司,南京市梦都大街30号 210019 2.云南省烟草农业科学研究院,昆明市圆通街33号 650021
土壤肥力是土壤诸多基本特性的综合反映[1],科学、实用的土壤肥力评价方法可为指导农业生产和土地利用提供依据[2-3]。土壤肥力评价是一个无决策属性的多属性决策过程,各属性权重分配的合理性对肥力评价将产生直接影响[4],综合主客观赋权方法,通过权重组合[5-6]探索更加合理的赋权过程也是目前的研究重点之一。
粗糙集是一种处理模糊和不确定知识的数学工具[7],基于粗糙集的权重确定方法目前被广泛应用于管理决策、专家系统和模式识别等领域[8]。作为一种客观赋权法,粗糙集权重的确定无需预先给定某些属性的数量描述,直接从给定问题的描述集合出发,通过确定给定指标的属性重要性,找出问题的内在规律[9-11]。鲍新中等[12]研究表明,基于粗糙条件信息熵的权重确定方法可提高指标权重的可解释性。丁守祯等[13]研究发现,基于粗糙集的权重确定过程可去除冗余信息,冗余信息的去除不仅不会改变方法本身的决策能力,反而会提高整个系统的清晰度。目前,将粗糙集中用于去除冗余信息的知识约简理论运用于植烟土壤肥力评价的指标赋权过程还鲜见报道。为此,以层次分析法[5]获取初始权重,并进一步构建决策表,通过计算最小近似约简对土壤肥力的不同指标进行属性约简和赋权,将粗糙集理论应用于植烟土壤肥力的综合评价过程,以期为土壤肥力的准确评价提供参考。
1 材料与方法
1.1 试验材料
土壤样品来自2018年江苏中烟工业有限责任公司云南某原料基地的15个植烟土壤采样点,采样点的选取遵循均匀性、代表性原则[14]。土壤取样于烤烟移栽前进行,每个采样点取12份样品,取样深度5~20 cm,按四分法取1 kg土壤进行检测,共计取样180份。不同植烟田块的地貌类型、农田水利设施和土地利用方式基本一致,所有采样点种植的烤烟品种均为云烟87,株行距为120 cm×50 cm,化肥施用量:N 100 kg/hm2、P2O5100 kg/hm2、K2O 250 kg/hm2,供试肥料为烟草专用肥和硫酸钾,其中,烟草专用肥和硫酸钾的70%作为基肥,剩余肥料在栽后30 d内追施,其他农事操作按照当地优质烟叶生产技术规范进行[15]。采样田块烟叶在正常成熟后采收烘烤并计算产量。
1.2 指标选取
选取对烟叶生长发育影响大的14项常规参数[有机质、碱解氮、全氮、水溶性氯、速效磷、速效钾、全磷、全钾、有效硼、有效钼、有效硫、有效钙和有效镁含量(质量分数)以及土壤pH]作为植烟土壤综合肥力的评价指标,鉴于不同采样点地貌类型、农田水利设施和土地的利用方式基本一致,对选取的14项指标采用多重比较方法[14]进行初筛。不同土壤肥力指标的具体测定方法见文献[16]。
1.3 决策表构建
1.3.1 离散化处理
由于粗糙集仅能处理离散化的数据,根据不同土壤指标的含量水平,并参考叶回春等[1]研究中土壤养分指标的区间划分标准,将各指标含量划分为“高”“中”和“低”3个等级。指标权重的初定采用层次分析法[5,17],以模糊评判中的加乘法原则[18]计算土壤综合肥力指数,各指标的等级划分和权重见表1。

表1 土壤肥力指标的等级划分阈值与权重Tab.1 Classification thresholds and weight coefficients of soil fertility indices
1.3.2 构建决策表
以土壤肥力指标为条件属性(C),综合肥力指数的等级为决策属性(D)构建决策表(表2)。条件属性集C={C1,C2,C3,…,C6},决策属性集D={d}。其中,C1为有机质含量,C2为碱解氮含量,C3为速效磷含量,C4为速效钾含量,C5有效镁含量,C6为水溶性氯含量,d为采用层次分析法初评得到的土壤肥力等级。

表2 土壤肥力评价决策表Tab.2 Decision table of soil fertility evaluation
1.4 指标集约简
1.4.1 属性重要性
定义S=(U,A,V,f)为一个信息系统,其中U表示对象的非空有限集合,称为论域;A是属性的非空有限集合,C∪D=A,C为条件属性集,D为决策属性集,集合V为属性集A的值域,f是U和A的关系集,也称信息函数集[1]。当D为非空集合时,信息系统S称为决策信息系统或决策表,否则称为数据表[19]。
对于信息系统S若有B⊆A,则定义属性集B上的不可分辨关系IND(B)为:
IND(B)={(Ux,Uy)∈U2|∀b∈B,f(Ux,b)=f(Uy,b)}
U/IND(B)称为对象集U在属性集B上的划分结果,其中的任意元素称为等价类[1]。
在决策表S中,若有U/IND(C)={C1,C2,C3,…,Cm},U/IND(D)={D1,D2,D3,…,Dk},则定义决策属性集D相对于条件属性集C的条件信息熵[12]为:

对于∀Cx∈C,属性Cx的重要性定义为:
Sig(Cx)=I(D|C)-I(D|C-Cx)
1.4.2 最小近似约简对于决策表S,定义条件属性集C的核为Core:
Core(C)={∀Cx∈C|Sig(Cx)≠0}
条件属性集C的初始核为空集。对于∀Cx∈C,当Sig(Cx)不为0,使CoreII=Core∪{Cx},最终得到的CoreII为条件属性集C的核[7]。
计 算I(D|CoreII),当I(D|CoreII)=I(D|C)时,CoreII称为条件属性集C的最小近似约简[7]。当I(D|CoreII)≠I(D|C),对指标∀Cy∈C-CoreII,计算其属性重要性Sig(Cy),按该值的大小顺序排列Cy,并依次并入核CoreII,即CoreIII=CoreII∪{Cy},直到I(D|CoreIII)=I(D|C),此时的CoreIII为条件属性集C的最小近似约简。
1.5 约简指标权重确定
对于最小近似约简中的任意元素Cn,重要性Sig(Cn)越大,指标越重要,该属性的权重也越大[20]。由此,属性Cn的权重为:

1.6 统计检验
作物产量作为土壤生产力的重要指标,通常视为土壤肥力的外部表征[21-22]。依据于寒青等[21]的研究,为验证赋权结果和评价结论的合理性和准确性,通过计算土壤综合肥力指数与采样田块当年烟叶产量的相关系数(r)、决定系数(R2)和均方根误差(RMSE)的大小,判断不同方法指标赋权的合理性和评判评价结论的准确性。
1.7 数据处理
利用式(3)进行标准化处理。式(3)中,D为土壤肥力指标的归一化值,D0为指标的原始值,Dmin为最小值,Dmax为最大值。

使用Matlab 2009b和SPSS 18.0软件进行数据分析,Excel软件进行统计并制表。不同采样点土壤样品的各指标得分为所有样品得分的平均值。
2 结果与分析
2.1 不同采样点土壤肥力状况
由表3可见,不同采样点土壤肥力状况差异较大。其中,采样点7的土壤样品pH和有效硼含量最高;采样点5的有机质、全氮和全钾含量最高;采样点6的碱解氮、速效钾和有效钼含量最高;采样点8的水溶性氯和速效磷的含量最高;采样点13的全磷含量最高;采样点4的有效硫含量最高;采样点1的有效钙含量最高;有效镁含量最高的为采样点10的土壤样品。与李卫等[23]的研究结果相比,不同采样点酸碱适中,碱解氮、全氮、全磷和有效镁含量丰富。多重比较分析的结果显示,不同采样点属同一原料基地,虽然其地貌类型、农田水利设施和土地的利用方式基本一致,但土壤肥力状况指标仍有差异。其中,不同采样点的全氮和全磷含量差异不显著,全钾、有效硼、有效钼和有效钙含量和土壤pH值5项指标差异较小,有机质、碱解氮、水溶性氯、速效磷、速效钾、有效硫和有效镁含量7项指标差异较大。各指标中,过量的硫素营养会降低烟叶的可用性[24]。所有采样点有效硫的指标含量均值范围为25.30~76.19 mg/kg,处于植烟土壤养分指标的最优范围内。
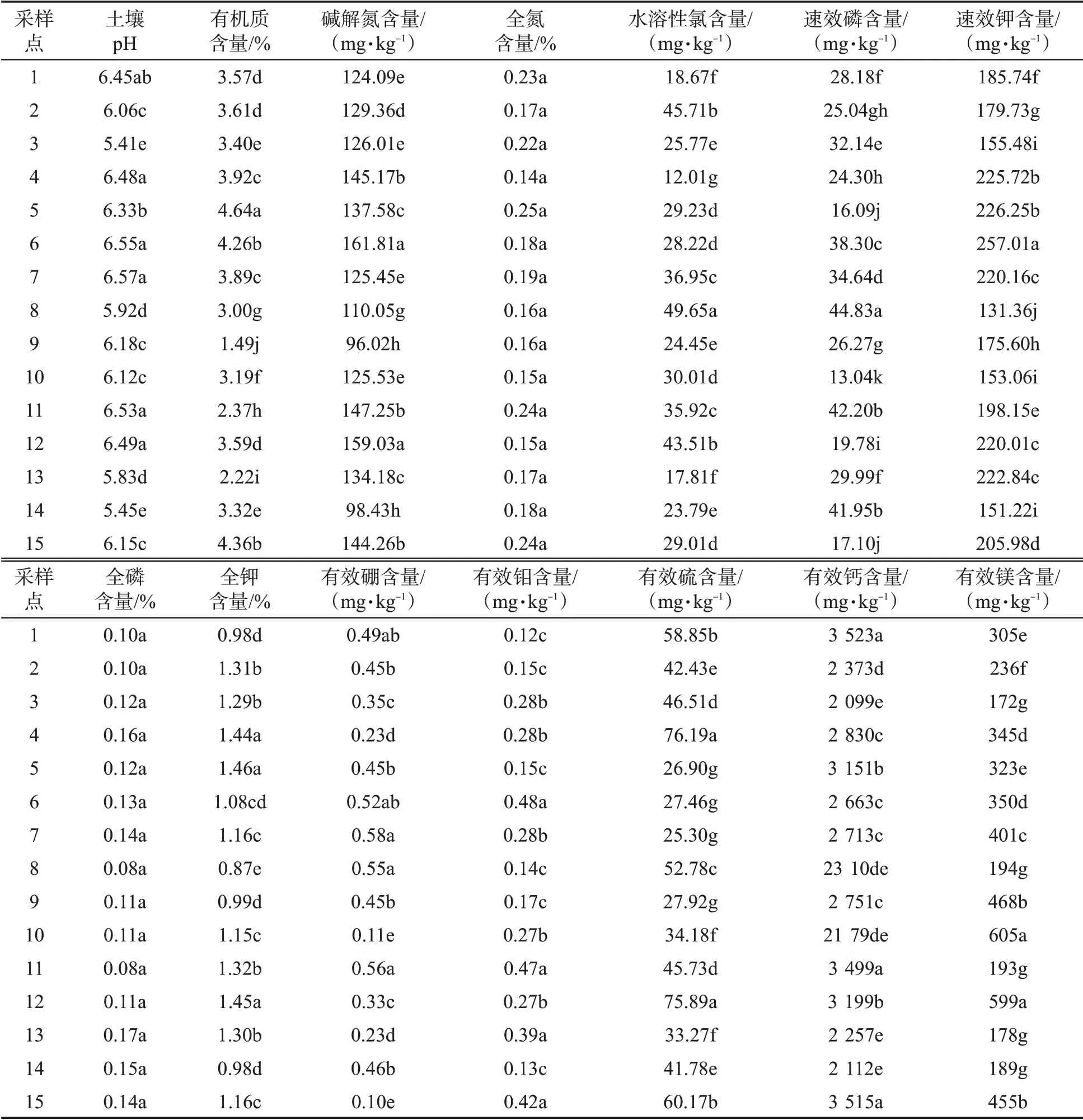
表3 不同采样点植烟土壤肥力情况①Tab.3 Fertility of tobacco-growing soil from different sampling sites
2.2 指标约简及权重确定
对表2中的数据论域分别按条件属性和决策属性进行等价类划分,并计算依次去掉一个条件属性后的论域等价类划分结果,并根据式(1)计算各条件属性的信息熵为:I(D|C)=0.000 0,I(D|C-C1)=0.000 0,I(D|C-C2)=0.000 0,I(D|C-C3)=0.066 7,I(D|C-C4)=0.066 7,I(D|C-C5)=0.000 0,I(D|C-C6)=0.066 7。

依据上述条件属性集核的算法定义,条件属性集C的核CoreII={C3,C4,C6},由于I(D|CoreII)≠I(D|C),依次计算指标∀Cy∈C-CoreII的属性重要性Sig,按重要性大小顺序并入CoreII,直到得到的CoreIII的I(D|CoreIII)=I(D|C),最后得到最小近似约简为{C1,C3,C4,C6}。属性指标经约简后,原有的6项土壤肥力指标缩减为4项(表4),分别为有机质(C1)、速效磷(C3)、速效钾(C4)和水溶性氯含量(C6)。碱解氮(C2)和有效镁含量(C5)2项指标被确定为冗余属性[1]。

表4 约简后的土壤肥力评价决策表Tab.4 Decision table of soil fertility evaluation after reduction
约简后各土壤肥力指标的属性重要性依次为:Sig(C1)'=0.133 3,Sig(C3)' 0.133 3,Sig(C4)'=-0.200 0,Sig(C6)' 0.155 6。
依据式(2)计算属性权重w(Cn),归一化后可得:w(C1)=0.214,w(C3)=0.214,w(C4)=0.321,w(C6)=0.251。
基于粗糙集的属性约简法在约简属性后剩余的4项指标及其权重分别为有机质含量(0.214)、速效磷含量(0.214)、速效钾含量(0.321)和水溶性氯含量(0.251)。与初评中层次分析方法确定的初始权重相比(表5),基于粗糙集的属性约简法提高了速效磷、速效钾和水溶性氯含量的权重系数,降低了有机质、碱解氮和有效镁含量的指标权重。其中,碱解氮和有效镁含量2项指标被约简,未分配权重,碱解氮和有效镁含量作为冗余信息被消除。由多重比较的分析结果可见,选取的有机质、碱解氮、速效磷、速效钾、有效镁和水溶性氯含量6项指标差异较大。此外,基于粗糙集的决策信息系统中每个条件属性的重要程度不同,该系统先去掉一个属性,再考虑没有该属性后等价类划分的变化情况[9]。碱解氮和有效镁含量2项指标的有无对后续试验田块等价类划分的结果不产生影响,而有机质、速效磷、速效钾和水溶性氯含量4项指标的影响较大,其中,又以速效钾和水溶性氯含量的重要性更高。

表5 不同决策方案的权重结果Tab.5 Weights obtained through different decision schemes
2.3 土壤肥力的综合状况
如表6所示,根据层次分析法得到的植烟土壤综合肥力指数最高的是采样点6的土壤样品,为9.49分;最低的是采样点9的土壤样品,为4.82分;采样点1~15的排名分别为8、5、7、4、6、1、3、11、15、9、10、2、13、14和12。基于粗糙集的属性约简法得到的综合肥力指数中得分最高的是采样点7的土壤样品,为9.36分,最低的是采样点9的土壤样品,为6.14分;其中采样点2和采样点11的两个采样点得分相同;采样点1~15的综合排名分别为14、4、9、10、8、2、1、7、15、11、4、3、12、6和13。

表6 不同评价方法的得分结果Tab.6 Scores obtained through different evaluation methods
综合比较不同评价方法计算得到的最高、最低以及排名情况发现,层次分析法和基于粗糙集的属性约简法计算得到的评价结果不尽相同,2种评价方法计算得到的综合肥力指数的最低分均为采样点9的土壤样品,利用层次分析法计算得到的最高分为采样点6的土壤样品,基于粗糙集的属性约简法中分值最高的为采样点7的土壤样品。2种评价方法差异较大的分别为采样点1、4、8、11和14的5份土壤样品,其中采样点14的土壤样品得分排名差异最大。
2.4 评价结果验证
为进一步比较不同评价方法的合理性,以当年不同采样田块的烟叶产量作为检验2种评价方法的直接依据。分析采样点当年的烟叶产量数据与不同评价方法计算得到的土壤综合肥力指数的相关性,并采用决定系数(R2)和均方根误差(RMSE)判断不同方法赋权的合理性与评价的准确性[21],不同评价方法计算得到的土壤综合肥力指数与当年烟叶产量的关系见图1。相关分析结果表明,层次分析法(图1a)和基于粗糙集的属性约简法(图1b)的评价结论与烟叶产量之间的相关系数检验均达到显著水平,r分别为0.65和0.92。其中,层次分析法的R2为0.42,RMSE为5.92(图1a),基于粗糙集的属性约简法的R2为0.86,RMSE为5.89(图1b)。相比层次分析法,基于粗糙集的属性约简法确定的各指标的权重系数更准确,赋权结果更合理,根据其计算得到的评价结果与当年烟叶产量的相关性更好、精度更高。

图1 不同评价方法计算的土壤综合肥力指数与当年烟叶产量的关系Fig.1 Relationships between tobacco leaf yields and comprehensive soil fertility index calculated by different evaluation methods
3 讨论
云南烟区植烟土壤主要的化学特征是酸碱适中,全氮含量丰富,钾含量较低[25],这与本试验结果类似。此外,不同采样点虽为同一原料基地,但土壤肥力指标有差异,不同指标属性权重的分配将直接影响土壤肥力综合评价的准确性。本研究中将权重的确定问题转化为粗糙集中属性重要性的评价问题[26]。利用粗糙集在知识约简方面的理论优势,对指标集合进一步优化,得到决定评价对象状况的关键性因素。与叶回春等[1,9]的研究相比,该算法的指标个数得以约简,评价的计算量也相应减少,并避免了线性或非线性极值问题的数值计算。就赋权结果而言,初评过程中采用的层次分析法作为一种多目标决策分析方法,是一种结合专家经验对复杂系统数量化的过程[17],较少考虑评价指标间的关系[5],而基于粗糙集的属性约简法的赋权结果相较层次分析法提高了对划分结果影响较大的属性的指标权重,降低了影响较小的属性的指标权重,充分考虑了各属性指标间的相关关系,克服了层次分析法在赋权过程中存在的主观性。此外,过去的土壤肥力评价研究往往通过计算评价结果的收敛性[18]和等级相关性[5]比较不同评价方法的优劣程度,而作物产量作为土壤实际生产力的外在表现,可用作土壤肥力评价结果的直接检验依据[21]。本研究中以取样烟田当年的烟叶产量为依据,对层次分析法和基于粗糙集的属性约简法确定的权重结果和评价结论分别进行检验,计算得出的土壤综合肥力指数与对应的烟叶产量间显著相关,表明评价结果较真实地反映了土壤肥力的实际状况。其中又以基于粗糙集的属性约简法的相关性更好,权重结果更加合理,评价结论的准确性更高。
值得注意的是,基于粗糙集的属性约简法依赖取样数据本身的差异,对于如何处理连续属性离散化问题,还需在更广泛的范围内对算法进行研究。此外,除烟叶产量外,还可考虑使用烟叶产值或烟叶质量等指标作为对评价结果验证的依据,进一步验证不同评价方法的合理性。
4 结论
借助粗糙集在知识约简方面的优势,利用层次分析法构建决策表,通过计算最小近似约简对土壤肥力指标进行属性约简,最终确定不同指标属性的重要性和权重系数,各指标按权重从大到小依次为速效钾含量(0.321)、水溶性氯含量(0.251)、有机质含量(0.214)和速效磷含量(0.214),得出各采样点土壤肥力综合评价结果。与层次分析法相比,基于粗糙集的属性约简法提高了速效磷和速效钾含量的权重系数,降低了有机质、碱解氮、有效镁和水溶性氯含量的指标权重,将碱解氮和有效镁含量2项指标作为冗余信息进行约简。不同评价方法计算得到的评价结果与当年烟叶产量均显著相关,其中又以基于粗糙集的属性约简法的相关性更好,精度更高,可更准确地评价不同植烟土壤的肥力水平。
