Relief-MRMR-SVM在煤矸图像分类的研究
2022-04-20张释如
张释如,朱 萌
(西安科技大学 通信与信息工程学院,陕西 西安 710054)
煤矸分选是将煤和矸石在采煤或洗煤过程中分选出来。传统方法有人工法、跳汰法、浮选法等。近几年陆续提出了基于射线和图像的方法,前者速度快,但难以控制且辐射强度大[1]。随着机器视觉技术成为矿物识别的研究热点,基于图像的方法得到了迅速发展[2],但仍存在一些问题。一方面利用煤矸图像空间域信息,在特定环境可进行有效分类,但模型稳定性有待改进;另一方面利用图像特征提取方法结合机器学习,一定条件下能解决煤矸分类问题,但有效的特征较难确定,且模型泛化能力较差[3]。
为改进这些问题,相关研究[4-7]采用深度学习的目标检测算法及图像分类方法实现了多目标图像中煤矸的自动分类。然而,在该领域已有的煤矸特征提取及选择方法仍存在一些问题[8,9]。DOU[10]等提取了19个煤矸图像特征,利用SVM识别最优特征构造分类模型,验证了模型的分类效果,但特征提取及选择工作上仍存在局限:提取的特征可能存在冗余而影响特征表达、消耗更多时间;特征选择只使用Relief,而单一特征选择算法不能得到最优子集[11]。故本文做出了改进。特征提取方面,引入了LBP(Local Binary Patterns,局部二值模式)局部纹理特征,并与GLCM(Gray Level Co-occurrence Matrix,灰度共生矩阵)全局特征结合能更好地表达图像纹理[12];特征选择方面,提出了一种结合Relief、MRMR(Max-Relevance and Min-Redundancy,最大相关最小冗余)及SVM的混合式特征选择方法。在两个煤矸数据集进行多次试验,验证了该方法的有效性。
1 特征提取
机器视觉的煤矸自动分选中,特征提取是后续工作的基础,故提取纹理和颜色特征为主要分类依据。
1.1 纹理特征
GLCM能较好地反映图像灰度关于方向和像素间隔的信息,但缺乏局部特征的描述,LBP从局部像素描述纹理,将二者结合能提高煤矸分类的准确性[13]。故共提取了4个GLCM和10个LBP纹理特征。采用4个间隔像素和角度的GLCM,提取了角二阶矩(ASM)、对比度(CON)、逆差矩(HOMO)、熵(ENT)的煤矸图像纹理特征,由式(1)-式(4)给出定义。
角二阶矩反映纹理粗细,值越大则纹理越粗。
(1)
对比度反映图像清晰度及纹理强弱,值越大则纹理沟纹越深、图像越清晰。
(2)
逆差矩是图像局部灰度均衡性的度量,值越大表示局部灰度变化越小。
(3)
熵反映图像纹理复杂度,值越大纹理越复杂。
(4)
式中,i,j表示图像中任意两点的灰度值;p(i,j)表示i,j同时出现的概率;L表示灰度最大取值。
LBP通过比较图像任意一点与周围点的灰度值大小表征局部纹理。圆形LBP的定义由式(5)给出。
(5)
式中,s(x)为单位阶跃函数;R为邻域半径;P为等间隔分布在半径为R的圆上的邻域像素点的个数,gc为邻域中心点的灰度值;gp是周围邻域点的灰度值。
对圆形LBP降维处理得到等价LBP,其使用较少的模式数可表达图像的大部分纹理,在特征提取中应用广泛。故采用了半径为1,邻域像素数为8的等价LBP,提取过程为:①将图像每个像素依次看作中心点,与周围8个像素点的灰度值比较,若大于中心点像素值,则标记该像素点为1,否则为0。经比较得到8位二进制数,即是该中心点的LBP编码值;②统计图像中所有LBP编码值出现的频次,并对编码区间等间隔量化成10段,得到LBP直方图,10个区间对应10个LBP特征。
1.2 颜色特征
采用HSV颜色空间的色相(H)、饱和度(S)和明度(V)分量的三阶矩,提取了9个颜色矩特征,由式(6)-式(8)计算。另外,灰度分量的三阶矩也可以作为颜色特征,式(9)给出计算。因此,共提取12个颜色特征。
(6)
(7)
(8)
Gary=0.2989R+0.5870G+0.1141B
(9)
式中,pi,j表示彩色图像的第i个颜色通道中灰度为j的像素出现的概率;N表示图像的像素个数。
另外,式(9)给出灰度分量的计算,提取它的3阶矩也作为颜色特征,因此共提取12个颜色特征。
综上,对煤和矸石图像共提取26个特征用于分类,其中包含14个纹理和12个颜色特征见表1。
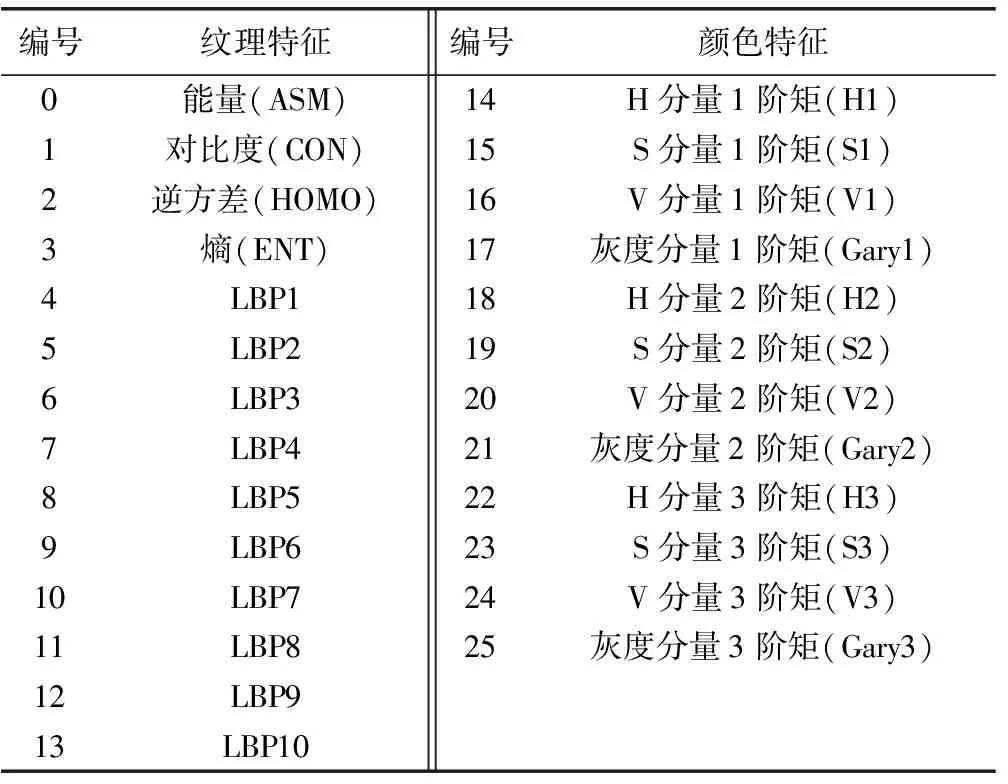
表1 煤和矸石图像表面特征提取
2 特征选择
特征选择通过剔除数据集冗余的特征,以减少特征数量、提高模型精确度。通常,特征选择方法分为两类[14]:过滤式方法,先按某种规则过滤初始特征,再用过滤后的特征训练学习器;封装式方法,使用学习器的性能作为特征选择的评价依据,选出最有利于学习器性能的特征子集[15]。
2.1 Relief算法
Relief算法是一种多变量过滤式特征选择方法。用于二分类实现特征选择的过程为:①从训练集随机采样一个样本M,并在与M同类的样本集寻找最近邻样本S,在与M异类的样本集寻找最近邻样本D;②根据该规则更新特征权重:如果M和S在某个特征的距离小于M和D的距离,说明该特征对区分同类和异类的最近邻样本有益,则增加特征权重,反之降低;③重复以上过程m次,求得每个特征的平均权重,其值越小表示特征的区分能力越弱。
2.2 MRMR算法
MRMR算法也是一种过滤式特征选择方法,通过在特征空间最大化特征与类别的相关性,最小化特征间的冗余性实现特征选择,由式(10)-式(12)表示。
(10)
(11)
maxφ(D,R)=D-R
(12)
式中,I(x,y)表示互信息函数;S表示特征集合,xi,xj表示各个特征;c表示目标类别。式(10)计算特征与目标类别间的相关性,式(11)计算特征间的冗余性,式(12)是目标函数。
MRMR是一种启发式贪心算法,不能保证特征子集全局最优。为解决该问题,可采用NICOLAS等提出的集成MRMR[16]。
2.3 Relief-MRMR-SVM混合式特征选择
Relief采用特征与类别间的关系赋予特征权重,没有考虑特征间的相关性。集成MRMR同时考虑特征与类别间的相关性及特征间的冗余性,但选出的每个特征对分类器的贡献是均匀的。将两种算法结合可有效弥补相互的缺陷,得到更优的特征子集。但两个算法都属于过滤式方法,分类准确率较低,因此需与封装式方法结合,利用分类器对特征子集进行评价得到最优特征子集,提高分类准确率[17]。
综合以上算法及两种特征选择方法的优缺点,本文提出了一种结合Relief-MRMR-SVM的混合式特征选择方法,工作流程如图1所示。
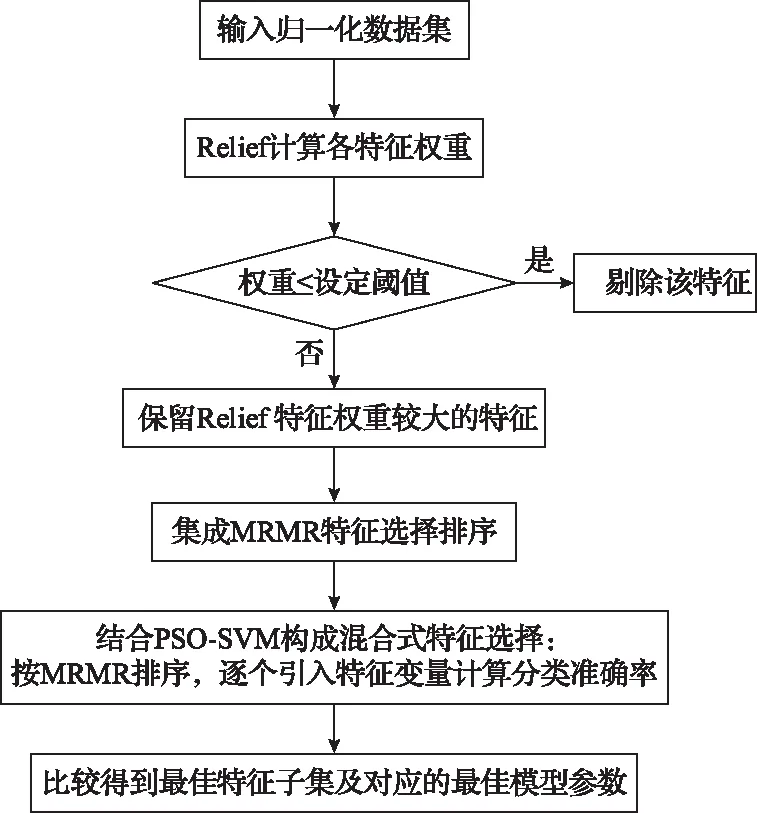
图1 Relief-MRMR-SVM混合式特征选择方法的工作流程
3 实验与分析
3.1 数据来源
本文采用的煤和矸石来自于铜川陈家山煤矿。首先在实验室固定光照和相机高度下,以胶带轮为背景采集煤和矸石的图像。按煤矸的大、小尺寸分别进行批量裁剪及预处理,经筛选保留了300张(煤130张、矸石170张)大尺寸(640×480)和400张(各200张)小尺寸(150×120)的图像,样例如图2所示;然后应用设计的特征分别对两组图片特征提取,得到对应含26个特征的数据集。为消除特征间的量纲误差,采用式(13)对数据集归一化处理。为便于区分,将大、小尺寸煤矸图像数据集分别记为数据集A和B。实验对两组数据集均按7∶3划分训练和测试集。数据集A中,210个样本为训练集,90个样本为测试集;数据集B中,280个样本为训练集,120个样本为测试集。

图2 煤和矸石样例图像(左为煤,右为矸石)
(13)
式中,x表示特征取值。
3.2 特征选择学习器的确定
在默认参数下使用支持向量机、K近邻、决策树、随机森林这4种常用分类模型,对数据集A进行分类评估得到PR和AUC曲线如图3所示,对比得最适宜该数据集的模型是支持向量机,其在未做任何特征处理情况下AUC值达0.92。
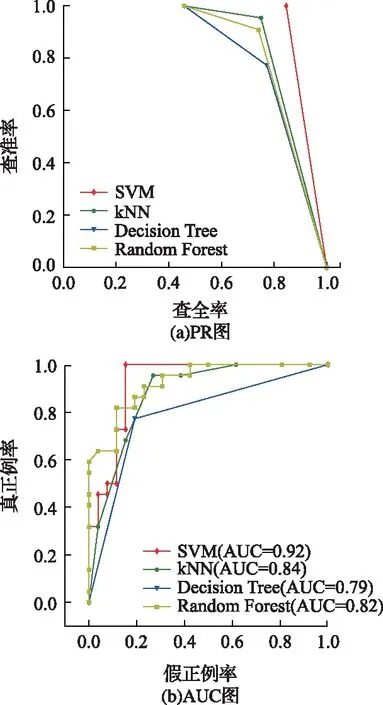
图3 分类学习器的对比
3.3 LBP纹理特征验证
随机抽样一组煤和矸石的图片,画出LBP直方图如图4所示,两者LBP特征之间存在显著差别,初步认为LBP可用作煤和矸石分类的重要纹理特征。
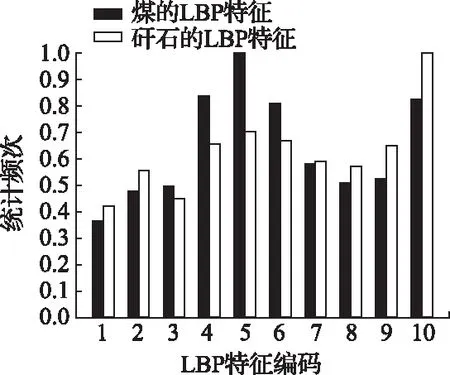
图4 煤和矸石的LBP直方图
在确定最佳分类模型SVM后,对去掉和保留LBP特征的数据集A分类结果见表2,可得在保留LBP特征时,准确率和AUC值均明显更高,再次验证了LBP特征对煤矸分类的重要作用。

表2 LBP特征对煤矸分类的影响
3.4 Relief-MRMR-SVM特征选择及模型训练
按图1特征选择的工作流程,进行如下实验。
1)输入原始归一化训练集,使用Relief算法计算各特征权重如图5所示,(a)和(b)对应数据集A和B。数据集A设置阈值0.07,剔除末尾7个特征,数据集B设置阈值0.06,剔除8个特征,得到各自候选特征子集。
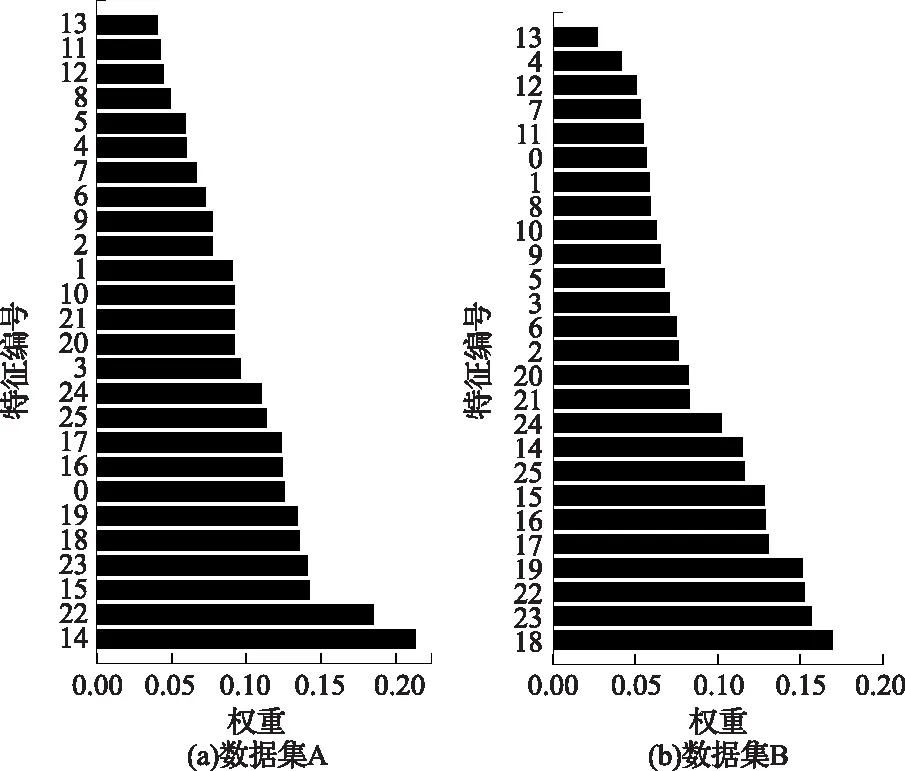
图5 Relief特征权重
2)采用集成MRMR算法对候选特征子集做进一步处理:对归一化数据集进行4次有放回重复抽样,利用MRMR算法分析得到的特征排序见表3。

表3 MRMR的4组特征排序子集
3)根据4组特征排序,结合构建的PSO-SVM模型,逐个引入特征变量计算分类准确率的结果如图6所示。通过对比,(a)中数据集A上特征排序2是最优的,(b)中数据集B上特征排序1是最优的。
由图6的最优特征排序,结合表1和3得,数据集A上前7个特征构成最优特征子集,即(V1、LBP6、V3、H1、ASM、H2、S2),最高准确率为96.6667%,此时PSO-SVM得到的最佳模型参数为C=2.5167,gamma=1.1884;数据集B上前9个特征(LBP6、V1、S3、H1、H2、V2、V3、ENT、Gary1)构成数据集B的最优特征子集,最高准确率为95.3571%,最佳模型参数为C=4.1821,gamma=1.2723。
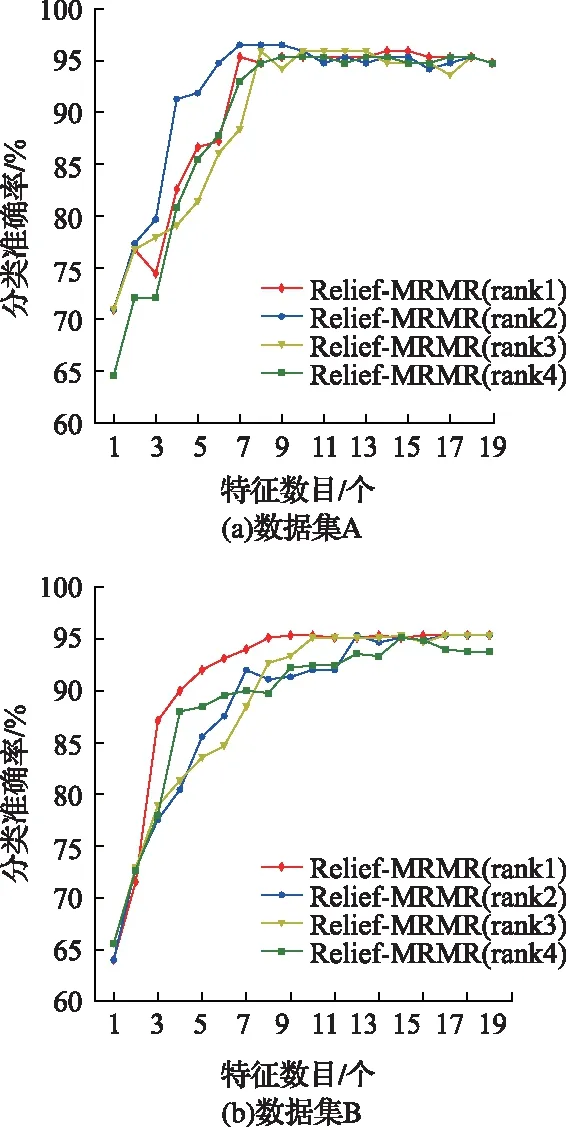
图6 不同特征子集下煤矸分类准确率的对比
4)为进一步验证本文特征选择方法的有效性,在两个数据集上,表4中将本文方法与文献[11]采用单一的特征选择方法进行了对比;图7对比了4种特征选择方法(不进行特征选择、只进行MRMR特征选择、只进行Relief特征选择、本文特征选择)对分类准确率的影响。

表4 与文献[11]所采用特征选择方法的对比
图7和表4的结果显示,采用本文特征选择方法能选出更优特征子集,即在选择出较少特征下能达到最高分类准确率;另外,该方法剔除了更多冗余特征,数据量减少,计算时间减少,从而提高了煤矸分类的效率。表4显示特征选择阶段用时较长,这是由于Relief算法本身计算权重所需时间长,但这并不妨碍模型的应用。在同一煤矿上,采集部分煤矸图像,提取特征并筛选后,事先训练得到最优特征子集和最佳分类模型,测试模型较稳定后,可直接使用训练好的模型进行分类应用,其仅需极少的时间,见表4中粗体显示。

图7 不同特征选择方法下煤矸分类准确率的对比
3.5 模型评估
将最佳参数模型与特征选择得到的最优特征子集排序应用于测试集进行分类评估,如图8所示。在测试集A上分类准确率达到95.56%,与未做特征选择及参数优化前的测试集分类准确率(91.11%)相比,提高了4.45%;在测试集B上分类准确率达到93.33%。
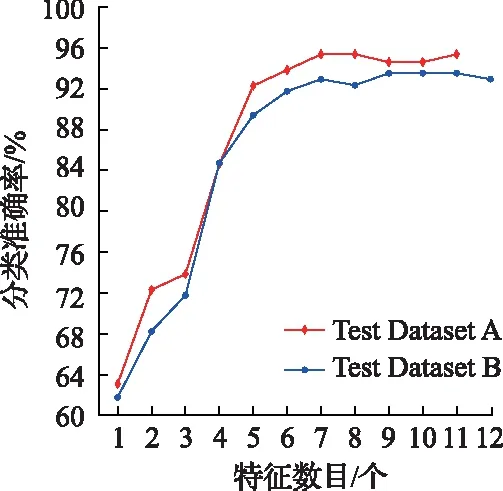
图8 测试集上分类准确率的评估
以上是随机选择训练集和测试集样本的单次试验,可能存在偶然性,因此对原始样本集分别进行3次随机取样得到测试集,依次进行分类评估,结果见表5,可得在数据集A和B上平均准确率分别达到96.12%和94.17%。
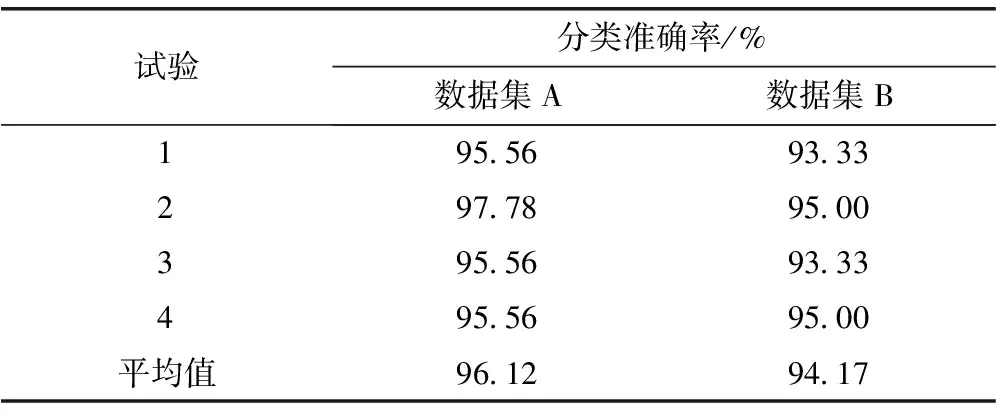
表5 基于最优模型和子集的4组随机煤矸分类试验
4 结 论
1)针对机器学习的煤矸图像分类领域已有的特征提取及选择方法仍存在的局限做出了改进。特征提取方面,引入了LBP局部纹理,共提取26个特征;特征选择方面,提出了Relief-MRMR-SVM混合式特征选择方法来识别更优的煤矸图像特征子集。
2)实验显示,该方法在两个数据集的平均分类准确率分别达到96.12%和 94.17%,与单一的特征选择方法对比,该方法在更少特征下达到最高分类准确率,有效剔除冗余特征,提高煤矸分类效率。
3)目前,该方法不能像基于深度学习的目标检测算法进行端到端的定位。受文献[4]启示,下一步将与目标检测算法结合对煤矸实时分类做进一步研究,即使用目标检测算法定位出煤矸在多目标图像中的位置,然后对定位区域使用本文方法提取并选出最优特征,进而实现准确且高效的煤矸分类。
