基于雨养指示线的灌溉概率指数计算与验证
2022-04-19朱秀芳
朱秀芳,刘 莹,徐 昆
(1. 北京师范大学遥感科学国家重点实验室,北京 100875;2. 北京师范大学环境演变与自然灾害教育部重点实验室,北京 100875;3. 北京师范大学地理科学学部遥感科学与工程研究院,北京 100875;4. 山东黄河河务局山东黄河信息中心,济南 250013)
0 引 言
粮食安全与能源安全、金融安全并称三大经济安全,是国家安全的重要基础。人口的增长以及城市的扩张给粮食供应带来了巨大的压力,而灌溉农业在提高粮食产量、保障粮食安全的过程中起着重要的作用。灌溉也是淡水资源消耗的主要方式,全球灌溉农业用水量约占淡水抽取总量的70%,在许多发展中国家,灌溉甚至消耗了超过90%的取水量。除了对淡水资源的消耗,不合理的灌溉还会对地下水环境、土壤、水质、社会经济甚至人体健康产生不利的影响。耕地的灌溉面积、分布、灌溉量以及灌溉时间等信息的提取对于粮食安全、经济发展和水资源管理等都十分重要,其中灌溉面积和灌溉分布是最基础的灌溉信息,可以通过灌溉耕地制图来获取。
目前常用的灌溉耕地制图方法有两种:一种是将行政单元尺度上灌溉面积的统计数据空间化到一定格网尺度,从而形成灌溉耕地分布图,另一种是基于遥感数据通过分类的手段得到灌溉耕地的分布。前者的核心在于建立合理的空间分配模型、找出与灌溉高度相关的某个或某些变量,且这些变量是比灌溉统计数据空间分辨率更高的栅格化的数据(比如1 km),然后依托这些变量建立分配规则。这种方法是目前全球灌溉耕地制图的主要方法,代表产品为全球灌溉耕地数字地图GMIA和MRICA。后者往往选择多个可以将灌溉耕地与雨养耕地进行区分的特征变量,比如波段指标(光谱反射率、植被指数、水体指数等)、物候指标(生长季起止时间、峰值等)、气候和环境变量(地表温度。蒸散发等)等,采用监督或者非监督的分类方法来提取灌溉耕地。例如,2003年有学者利用Landsat 7 ETM数据计算得到的归一化植被指数(Normalized Difference Vegetation Index,NDVI)作为分类特征对2002年美国内布拉斯加州的斯科茨布拉夫和卡尼两个县的灌溉耕地进行了提取,分别达到了87.98%和69.08%的分类精度。2019年Xie等利用现有的粗分辨率灌溉耕地分布图辅助形成了训练数据池,利用谷歌地球云服务平台(Google Earth Engine,GEE)以遥感特征和气候特征为分类特征,利用随机森林分类器进行了2012年美国本土30 m空间分辨率的灌溉耕地制图。同年,Deines等同样利用已有的灌溉耕地分布图以及其他研究者采集的地面数据作为训练样本,利用谷歌地球云服务平台结合Landsat遥感影像、环境变量和地面实况等数据,基于随机森林分类器制作了美国高原含水层1984—2017年的30 m空间分辨率的灌溉耕地分布图AIM-HPA。
无论是基于统计数据空间化的灌溉耕地制图还是基于遥感分类的灌溉耕地制图,选择合适的特征变量都是重要的环节。总体看来,目前用来反映耕地受灌溉可能性大小的特征变量主要分为两类:第一类参量主要通过描述灌溉引起的土壤水分或作物水分的变化来反映灌溉的效果;第二类参量关注于灌溉引起的植被长势的变化,如归一化植被指数峰值等。还有参量结合了植被因素和非植被因素来表征耕地的灌溉潜力。当前大部分的特征参量对于灌溉可能性的表征都比较间接,物理机理不够明确。
针对上述问题,考虑在相同的气象干旱条件下,灌溉会减缓或者阻止气象干旱向农业干旱的演变过程,导致灌溉农田的农业干旱程度轻于雨养农田。基于此原理,本文提出了雨养指示线的概念,利用雨养指示线构建了能够直接表征灌溉可能性大小的灌溉概率指数(Irrigation Probability Index,IPI),选择有良好灌溉数据基础的美国的内布拉斯加州作为研究区,对所提出的灌溉概率指数进行适应性分析与验证,拓展能够直接表征耕地受灌溉可能性的特征参量,以期为灌溉耕地制图相关研究提供更多可选参量。
1 基于雨养指示线的灌溉概率指数计算原理与方法
1.1 雨养指示线的提取原理
气象干旱是土壤干旱的主要诱因,当土壤含水率变少,作物根系难以从土壤中吸收到足够的水分来补偿蒸腾消耗的水分时,就会进一步诱发农业干旱。在没有灌溉补给时,气象干旱和农业干旱是高度相关的,而当灌溉发生时,气象干旱朝向农业干旱的演变过程就会受到阻碍。在作物的气象干旱情况一致的条件下,假设不同耕地间的农业干旱之间的差异大部分是由灌溉因素决定的,其他因素(比如作物品种、地形条件、土壤类型等)的影响可以忽略,则农业干旱更严重的作物是雨养作物的可能性更大,而农业干旱相对较轻的作物是灌溉作物的可能性更大。基于此原理,本研究定义了雨养指示线,并利用雨养指示线来构建灌溉概率指数。
1.2 雨养指示线的提取原则
雨养指示线的提取需要满足以下两条原则:1)用来提取雨养指示线的研究区需要同时包含足够多的灌溉像元和足够多的雨养像元;2)用来构建散点图的像元在时相上需要尽可能接近。第一条原则是为了能够充分展现出灌溉导致的灌溉农田的农业干旱与雨养农田的农业干旱之间的差异,第二条原则是为了保证所有的灌溉农田像元和雨养农田像元具有相似的气候条件,尽量减少除了气象干旱和灌溉以外的其他因素对农业干旱的影响。
1.3 雨养指示线的提取方法
1)利用降水量(Precipitation,Pre)、实际蒸散发(Actual Evapotranspiration,AET)和潜在蒸散发(Potential Evapotranspiration,PET)来计算气象干旱指数和农业干旱指数。本研究中将作物水分亏缺指数中的参考作物蒸散量替换为潜在蒸散量得到新的作物水分亏缺指数(Crop Water Deficit Index,CWDI)来表征作物的气象干旱情况,选取作物水分胁迫指数(Crop Water Stress Index,CWSI)来表征作物的农业干旱情况。两个指数的计算方法如式(1)和式(2)所示。对于CWDI和CWSI来说,均是数值越大,表示干旱越严重,数值越小,表示干旱情况越轻。
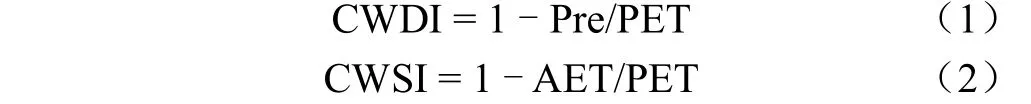
2)将CWDI作为横坐标轴,CWSI作为纵坐标轴,在气象干旱与农业干旱组成的二维特征空间中绘制所有耕地像元的散点。当气象干旱情况相似时,农业干旱情况越轻的耕地像元是灌溉作物的可能性越高;反之,农业干旱情况越严重的耕地像元是雨养作物的可能性越高。因此,对特征空间中散点的上包络线进行拟合,作为雨养指示线(图1)。雨养指示线的表达如式(3)所示。
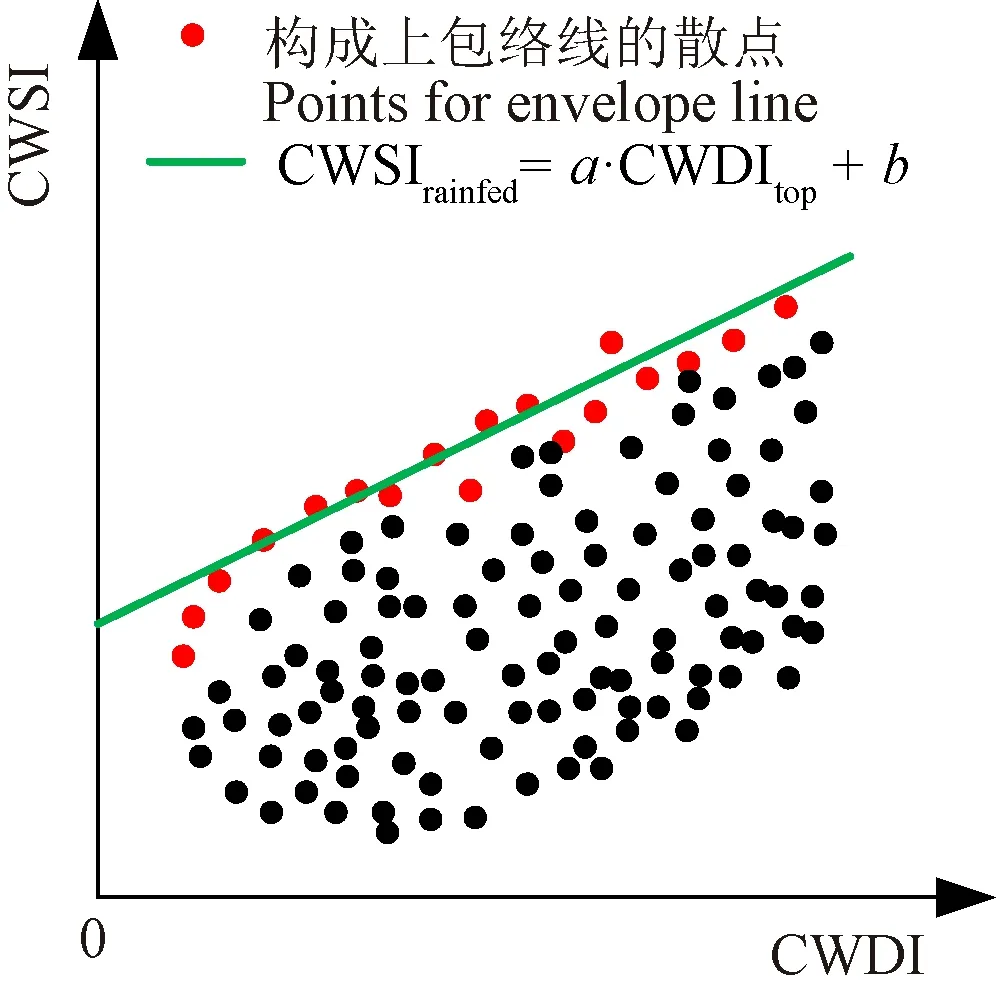
图1 雨养指示线理论示意图 Fig.1 Theoretical schematic diagram of the rain-fed indicator line
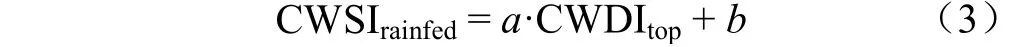
式中CWSI代表拟合得到的雨养指示线;CWDI代表构成上包络线的散点的气象干旱指数值;和为拟合得到的上包络线的斜率和截距。
1.4 灌溉概率指数的构建
提取了雨养指示线后,计算每个耕地像元与雨养指示线在纵轴方向上的距离作为灌溉概率指数,灌溉概率指数的值越大就表示该像元位置的农作物受到灌溉的可能性越大。灌溉概率指数的计算方法如下:
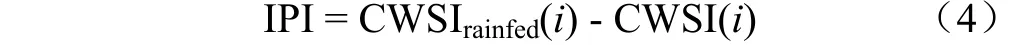
式中CWSI()代表气象干旱指数为的像元对应的农业干旱指数值;CWSI()代表气象干旱指数为的像元对应的雨养指示线上的农业干旱指数值。另外需要注意的是,存在一些像元点位于拟合的雨养指示线以上,将这些像元点的灌溉概率指数直接赋值为0,不再按照式(4)进行计算。
为了使灌溉概率指数的数值更加容易理解,采用最大-最小标准化的方法将计算得到的灌溉概率指数值进行拉伸。最大-最小标准化的公式如下:
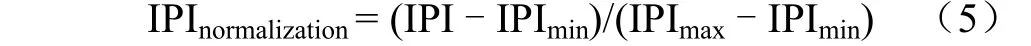
式中IPI为标准化后的灌溉概率指数值,其取值范围为0~1,数值越大,表明耕地受灌溉的可能性越大,数值越小,表明耕地受灌溉的可能性越小。IPI表示原始灌溉概率指数值,IPI、IPI分别为整个研究区内灌溉概率指数的极大值和极小值。
2 案例研究
2.1 研究区概况
本研究选择美国的内布拉斯加州作为研究区(图2)。内布拉斯加州(39°N~44°N,95°W~105°W)位于北美中部大平原区域,地势西部高、东部低,总体比较平缓,地形变化较小;平均温度和降水呈现自东向西下降的趋势,潜在蒸散量呈现自东向西增加的趋势。内布拉斯加州是美国主要的农业生产地区之一,也是世界上灌溉最密集的区域之一。农业活动自东向西沿着降水减少的梯度分布。玉米和大豆是该州的主要作物,其他次要作物包括冬小麦、高粱和苜蓿,主要作物的生长季是4 —10月。
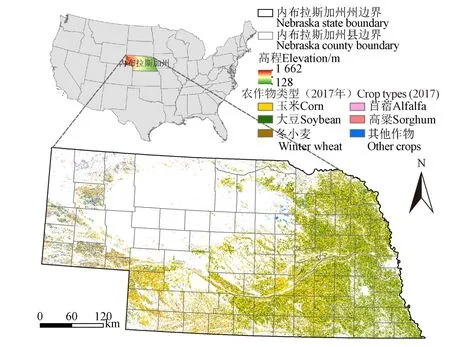
图2 研究区 Fig.2 The study area
2.2 数据说明
本文所用到的数据(表1)包括如下三类:
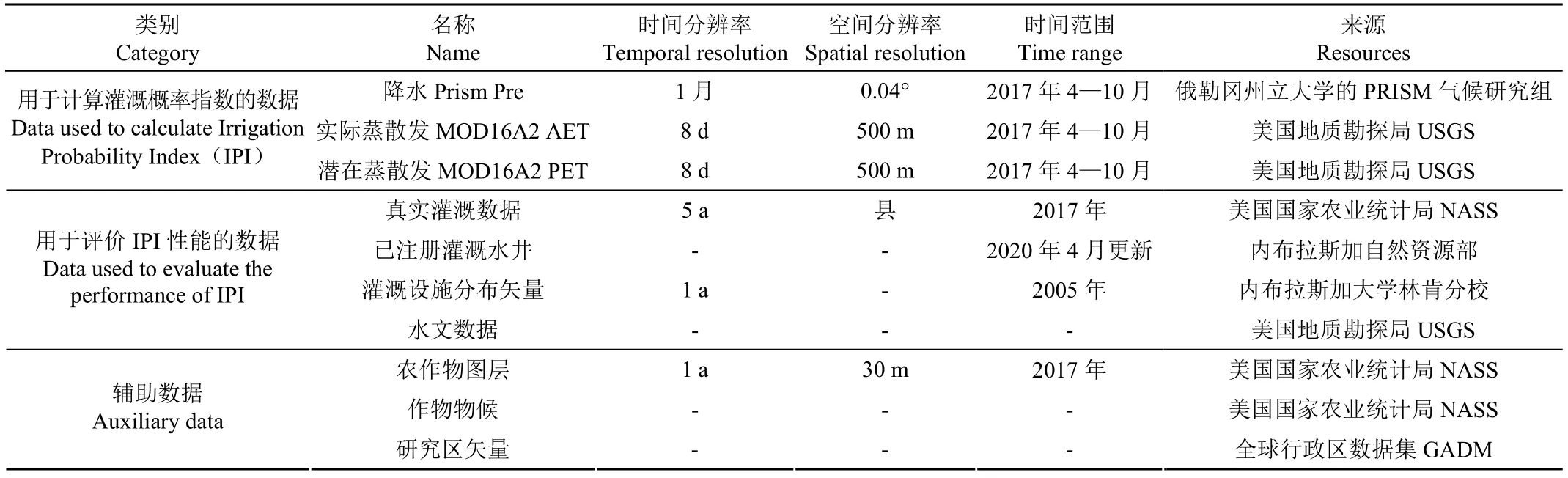
表1 数据说明 Table 1 Data instructions
1)用于计算灌溉概率指数的数据:包括降水Prism Pre、实际蒸散发MOD16A2 AET和潜在蒸散发MOD16A2 PET。Prism降水数据来自俄勒冈州立大学的PRISM气候研究组,下载网址为http://prism.oregonstate. edu/recent/。该数据的空间分辨率为0.04°,空间参考为GCS North American 1983,以波段按行交叉的数据格式存储。通过ArcMap软件建模对该数据分别进行投影转换、最近邻重采样、裁剪和格式转换的批量处理,得到内布拉斯加州空间分辨率为500 m、空间参考为阿尔伯斯圆锥等面积投影的TIF格式的降水数据。MOD16A2实际蒸散发和潜在蒸散发来源于MODIS的MOD16A2第六版本数据产品。该产品是以500 m空间分辨率生成的8 d合成数据产品,其下载网址为 https://lpdaac.usgs.gov/ products/mod16a2v006/。利用MATLAB编写程序按照8 d合成数据在月份中的比例将8 d数据合成月尺度数据。例如,2017年4月的第一天为当年第91天,最后一天为当年第120天,则该月数据的合成方法为:首先,筛选与该月天数有重合的8 d合成数据,即日期编号为2017089、2017097、2017105和2017113的数据。然后,计算每期数据所表示的8 d范围内有几天与该月重合,将该天数与 8 d的比值作为比例因子:日期编号为2017089、2017097、2017105和2017113数据的比例因子分别为6/8、1、1、1。最后,将筛选出的8 d合成数据与相应的比例因子相乘再加和得到月数据。计算过程中如果某期数据在某像元位置处是空值,则该像元的月合成结果也直接赋空值。完成上述处理之后,结合其缩放因子得到真实的蒸散发数据,再利用ArcMap软件建模对该数据分别进行投影转换、最近邻重采样、裁剪的批量处理,得到内布拉斯加州空间分辨率为500 m、空间参考为阿尔伯斯圆锥等面积投影的真实蒸散发和潜在蒸散发数据。
2)用于评价灌溉概率指数性能的数据,包括真实灌溉面积、已注册灌溉水井、灌溉设施分布图和河流分布。真实灌溉面积数据来自美国农业部的美国国家农业统计局提供的农业普查数据。该项普查每5 a进行一次,其中包含以县(County)为单位的真实灌溉数据,下载网址为https://www.nass.usda.gov/Publications/AgCensus/。需要注意的是,该普查数据中的真实灌溉面积仅被记录一次,不考虑多次灌溉和多季作物。已注册灌溉水井来源于内布拉斯加州自然资源部网站提供的注册地下水井数据,该数据以矢量点的形式存储,利用其属性表筛选出用途为灌溉且状态为活跃的水井构成已注册活跃灌溉水井数据,下载网址为https://dnr.nebraska.gov/data/ groundwater- data。灌溉设施分布图来源于内布拉斯加大学林肯分校先进土地管理信息技术中心(Center for Advanced Land Management Information Technologies,CALMIT),该数据图层以面状矢量文件的形式提供了根据2005年多时相的Landsat 5卫星影像和农业服务局的正射影像确定的内布拉斯加州2005年生长季的中心枢纽灌溉系统和其他灌溉系统分布图,其下载网址为 https://calmit.unl.edu/metadata- 2005-nebraska-land-use-center-pivots-irrigation-systems。河流分布来源于美国地质勘探局提供的国家水文数据集(National Hydrography Dataset,NHD),下载网址为https:// www. sciencebase.gov/catalog/item/5a96cdb1e4b06990606c4d29。
3)辅助数据:包括农作物图层、作物物候数据和研究区矢量。农作物图层是由美国农业部的美国国家农业统计局提供的农作物数据图层(Crop Data Layer,CDL),空间分辨率为30 m。利用ArcMap对该数据进行空间参考的转换,由GCS WGS 1984转换为阿尔伯斯圆锥等面积投影,利用ArcMap创建覆盖研究区的间隔为500 m的格网,统计格网内作物面积占整个格网面积的比例,得到空间分辨率为500 m的研究区主要作物面积百分比分布图,提取作物面积百分比大于0的像元作为研究中的待分析耕地像元。研究区的矢量边界数据来源于GADM database of Global Administrative Areas,下载网址为http://www.gadm.org/。
2.3 技术路线
灌溉概率指数构建的技术流程如图3所示。主要包括:1)对降水、实际蒸散发和潜在蒸散发数据进行预处理,得到2017年内布拉斯加州主要作物生长季(4—10 月)每月的降水、实际蒸散发和潜在蒸散发数据;2) 计算整个生长季的气象干旱指数和农业干旱指数;3)利用30 m空间分辨率的农作物图层计算500 m空间格网上的作物面积百分比,提取作物面积百分比大于0的像元确定为研究中的待分析耕地像元;4)在气象干旱指数与农业干旱指数构成的二维特征空间中,绘制整个生长季灌溉耕地像元点和雨养耕地像元点的散点图;5)提取散点图的上包络线作为雨养指示线,并定义每个散点在纵轴方向上到上包络线的距离为灌溉概率指数;6)利用灌溉概率指数和其他灌溉特征(真实灌溉面积、活跃灌溉水井数量和灌溉设施面积)以及水源分布的关系评价其对真实灌溉情况的反映。
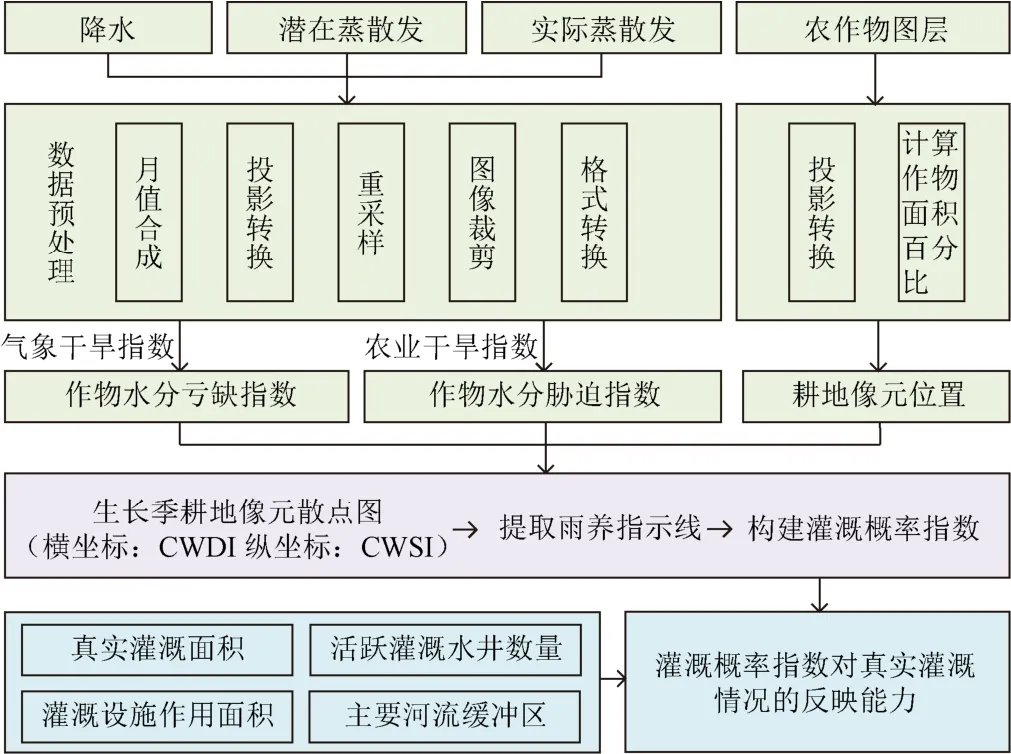
图3 技术路线图 Fig.3 Technological flowchart
3 结果与分析
3.1 雨养指示线提取结果
图4展示了根据内布拉斯加州2017年主要作物生长季内所有耕地像元的气象干旱指数与农业干旱指数所构建的雨养指示线。在图4a的散点图中存在一些离群值,它们会影响雨养指示线的提取结果,因此在拟合上包络线之前,对气象干旱指数CWDI以0.001的间隔提取散点图,以超出上下四分位数的2个四分位间距的农业干旱指数CWSI值为界限去除离群值,得到了图4b。去除离群值后,对气象干旱指数CWDI以0.001的间隔将每个间隔内农业干旱指数CWSI最大的点提取出来,仅使用气象干旱指数CWDI在0.05~0.75之间的散点进行上包络线的拟合,拟合的公式见图4c。
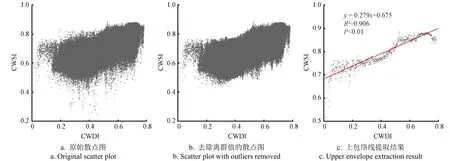
图4 2017年内布拉斯加州主要作物生长季的雨养指示线 Fig.4 Rain-fed indicator line for the major crops growing season in Nebraska in 2017
3.2 灌溉概率指数构建结果
2017年内布拉斯加州耕地像元的灌溉概率指数分布如图5所示。灌溉概率指数整体上呈现东部高、西部低的趋势,与该州的气温和降水的分布趋势以及农业活动的变化梯度类似。灌溉概率指数较高的区域也基本是沿着该州密布的河网分布的。可见,内布拉斯加州农业活动密集且靠近河流等水源地的区域,灌溉的可能性更大。
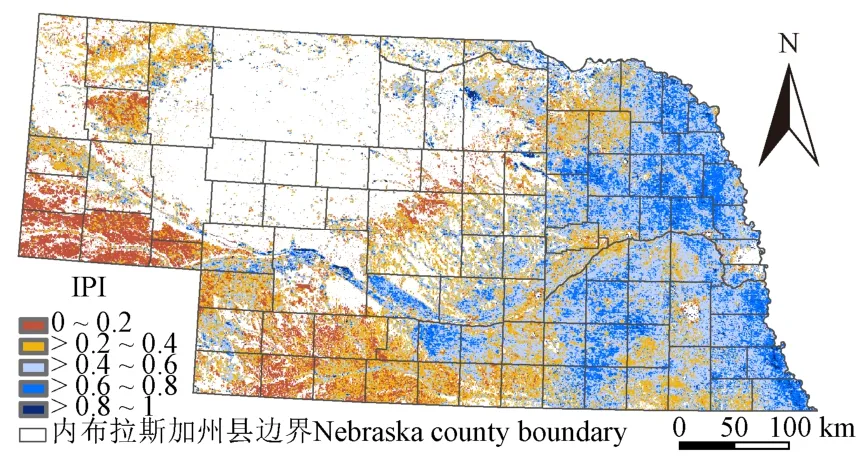
图5 2017年内布拉斯加州IPI分布图 Fig.5 Distribution map of Nebraska IPI in 2017
3.3 灌溉概率指数与其他灌溉特征的关系
为了验证灌溉概率指数是否能够有效地表征真实灌溉情况,根据该州的气候特征分布情况利用2017年主要作物生长季的县级气象干旱指数CWDI均值将该州的县划分为三部分(图6):气象干旱指数CWDI小于0.4的为气候相对湿润的县,气象干旱指数CWDI位于0.4~0.6之间的为气候适宜(不干也不湿)的县,气象干旱指数CWDI大于0.6的为气候相对干旱的县(此处的湿润、正常和干旱条件仅针对于2017年主要作物生长季内布拉斯加州的气候条件在空间上的相对情况),分别计算了各气候条件下县级灌溉概率指数总和与其他灌溉特征(县级真实灌溉面积总和、县级活跃灌溉水井数量总和以及县级灌溉设施作用面积总和)之间的相关系数(表2)。

表2 县级灌溉概率指数总和与其他灌溉特征的相关性 Table 2 Correlation between the sum of the county-level irrigation probability index and the other irrigation characteristics
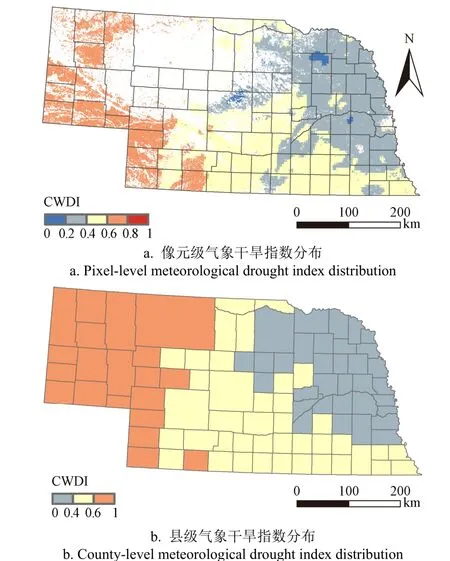
图6 2017年内布拉斯加州气象干旱指数分布图 Fig.6 Distribution map of crop water deficit index of Nebraska in 2017
总体来看,除了在相对湿润的县内,灌溉概率指数与活跃灌溉水井数量之间的相关关系不显著,该区域其他灌溉特征与其他区域内的所有灌溉特征均与灌溉概率指数具有显著的正相关关系,表明了灌溉概率指数在表征耕地受灌溉可能性上的有效性。不同的气候条件下,灌溉概率指数与其他灌溉特征之间的相关性不同。对于这三个灌溉特征,均呈现了气候条件越湿润,相关系数越低;气候条件越干旱,相关系数越高的特点,表明了灌溉概率指数对于真实灌溉情况的反映能力具有区域上的差异:在气候条件相对干旱和气候适宜的县,灌溉概率指数可以较好地描述真实灌溉情况;在气候条件相对湿润的县,灌溉概率指数反映真实灌溉情况的能力有所下降。
3.4 灌溉概率指数与河流分布的关系
以内布拉斯加州的主要河流为中心,分别创建了宽度为1、2、…、10 km的缓冲区,以每1 km为间隔(≤1、>1~2、>2~3、…、>9~10 km)统计缓冲区内灌溉概率指数的均值,以此来分析灌溉概率指数与水源分布的关系,结果如图7所示。在不进行内部分区的情况下,河流缓冲区的灌溉概率指数均值随着到河流的距离增加而降低。以气候条件进行分区后,不同区域内河流缓冲区的灌溉概率指数均值的变化情况不同:在相对湿润的区域,整体来看,距离河流越远,缓冲区内的灌溉概率指数均值越高;在气候适宜以及相对干旱的区域,距离河流越远,缓冲区内的灌溉概率指数均值越低。在相对干旱的区域,随着缓冲区到河流距离的增加,灌溉概率指数均值的变化更剧烈。
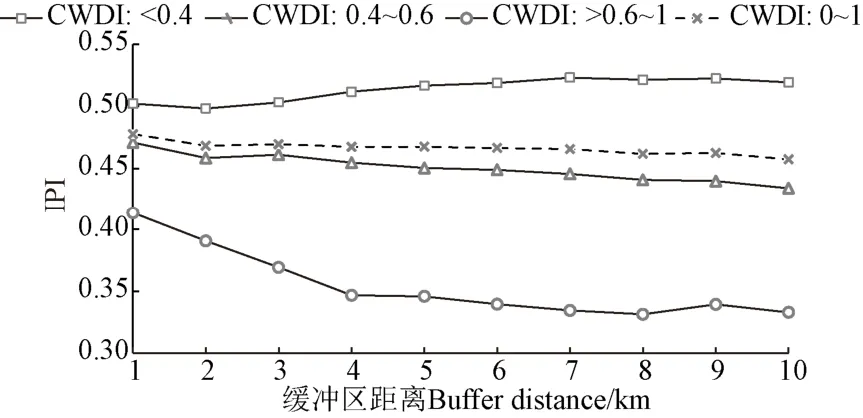
图7 灌溉概率指数与水源分布的关系 Fig.7 Relationship between irrigation probability index and water source distribution
4 讨 论
已有灌溉制图相关的研究多是利用表征植被生长状况或者土壤水分情况的参量来间接表征灌溉情况,存在物理机理不足的问题。气象干旱是土壤干旱的主要诱因,当土壤含水率减少、作物根系难以从土壤中吸收到足够的水分以补偿作物的蒸腾作用消耗的水分时,就会进一步诱发农业干旱。在没有灌溉进行额外的水分补充的情况下,气象干旱和农业干旱是高度相关的,而当灌溉发生时,气象干旱和农业干旱之间的相关性变弱、差异变大。基于此原理,本文首次提出了雨养指示线的概念,利用降水、实际蒸散发和潜在蒸散发数据,发展了能够直接表征耕地受灌溉可能性的特征参量—灌溉概率指数,并在美国内布拉斯加州进行了性能评估。本文发展的灌溉概率指数物理意义明确,能很好地反映农田受灌溉的可能性,具有潜在的应用价值,可以作为灌溉耕地分布制图的参量。
为了评估灌溉概率指数对真实灌溉情况的表征能力,以县为单位计算了灌溉概率指数总和与真实灌溉面积、活跃灌溉水井数量以及灌溉设施作用面积之间的相关系数。由于本研究中构建的灌溉概率指数是以灌溉农田和雨养农田之间的差异为出发点,本质上是对灌溉结果的反映,因此理论上真实灌溉面积和灌溉概率指数的相关性最高,表2也证实了这一点。整个研究区内灌溉概率指数和真实灌溉面积的相关系数为0.62,高于灌溉概率指数和活跃灌溉水井数量的相关系数(0.51),以及灌溉概率指数和灌溉设施作用面积的相关系数(0.55)。该结果从侧面说明了本文发展的灌溉概率指数表征灌溉的能力。
此外,整体来看,内布拉斯加州靠近水源分布的区域,灌溉概率指数会更高;在气候相对干旱的区域,该现象尤其明显;在气候相对湿润的区域,呈现相反的趋势,这可能是由于灌溉概率指数在气候相对湿润区域的表征能力下降导致的,也可能是由于气候相对湿润的区域,气象供水比较充分,地下水和气象水在正常年份可以满足灌溉水源的需求,导致灌溉概率指数对河流水源分布不敏感。
受数据等的限制,本研究仍然存在一些不足之处:1)没有从多个年份构建和验证灌溉概率指数。美国的灌溉面积统计数据每5 a发布一次,2017年是距今为止最近的美国发布灌溉面积统计数据的年份,而且2017年内布拉斯加州主要作物生长季的气象干旱情况居中,整个州内干旱和湿润的状态都有分布,选择该年可以比较客观地体现灌溉概率指数表征耕地被灌溉可能性的能力,避免由于选择过度干旱的年份造成对灌溉概率指数能力的高估以及选择过度湿润的年份对灌溉概率指数能力的低估。2)没有在其他区域对灌溉概率指数进行应用和验证。为了更好地验证灌溉概率指数表征灌溉可能性的能力,尽量避免其他不确定因素对研究结果的干扰,本研究仅考虑了具有真实灌溉面积统计数据的内布拉斯加州作为研究区进行试验及验证。该指数的物理意义明确、容易复现,而且在非湿润区域可以很好地反映耕地被灌溉的可能性大小。后续可以直接基于此原理在国内区域复现,在验证方面,可以利用国内的有效灌溉面积统计数据进行验证。在应用方面,该指数可以作为灌溉耕地制图的依据数据,也可以单独作为一个参数指标,用多年数据来表征灌溉的时空变化趋势。3)没有划分不同的气候区域构建和验证灌溉概率指数。为了提高灌溉概率指数在方法上的可迁移性,保证区域内灌溉耕地像元和雨养耕地像元的均匀性以及保证灌溉概率指数在空间上的可比性,本研究利用了整个研究区的耕地像元来提取雨养指示线、构建灌溉概率指数。但是,后续利用该指数在已经经过验证的区域内进行应用时,可以考虑划分适当的气候区域来提高灌溉概率指数的精度。4)没有与其他灌溉特征进行对比。目前国内外有关灌溉耕地制图的研究有一定的规模,但是灌溉相关的指数通常仅作为灌溉耕地制图中的基础数据被提及,而且大部分研究中使用植被指数、土壤湿度等已有的参数来间接地表征耕地受灌溉可能性的大小,在使用这些指数进行制图之前也几乎不对其反应灌溉可能性的能力进行评价,因此该指数暂时无法与其他灌溉特征进行对比。
5 结 论
本文提出了一种基于雨养指示线的灌溉概率指数,以2017年内布拉斯加州灌溉概率指数的计算为例,介绍了基于雨养指示线的灌溉概率指数计算的方法和流程,并分析了灌溉概率指数与真实灌溉面积、活跃灌溉水井数量、灌溉设施作用面积、河流分布之间的关系。结果显示灌溉概率指数整体上呈现东部高、西部低的趋势,与该州的气温和降水的分布趋势以及农业活动的变化梯度类似。县级灌溉概率指数均值和真实灌溉面积、活跃灌溉水井数量以及灌溉设施作用面积的相关系数分别为0.62、0.51和0.55,均通过了0.05显著水平的测试,说明了灌溉概率指数可以有效表征耕地受灌溉的可能性大小。但灌溉概率指数在3个气候区(偏湿润区、气候适宜区和偏干旱区)的适应性存在差异。在气候适宜区和偏干旱区,县级灌溉概率指数总和与真实灌溉面积、活跃灌溉水井数量以及灌溉设施作用面积均呈显著的正相关关系,灌溉概率指数均值随着到河流的距离增加而降低。在偏湿润区,县级灌溉概率指数总和与活跃灌溉水井数量的正相关关系不显著,灌溉概率指数均值随着到河流的距离增加而增加。在气候比较湿润的区域,灌溉概率指数的表征能力有所下降。
