基于通道注意力机制的文本生成图像方法
2022-04-18张云帆易尧华汤梓伟王新宇
张云帆,易尧华,汤梓伟,王新宇
(武汉大学 印刷与包装系,武汉 430079)
0 概述
文本生成图像任务[1]是图像生成领域的重难点之一,旨在根据输入的文本描述生成相应的自然场景图像,其包括计算机视觉和自然语言处理两方面,是一个多模态的交叉型任务。文本生成图像可应用于计算机辅助设计、智能美工、医疗图像生成[2]等多个技术领域。
随着深度学习技术的发展,生成对抗网络(Generation Adversarial Network,GAN)[3]及其各种变体[4]成为文本生成图像的主流方法。在早期有MIRZA等[5]提出的CGAN 和REED 等[6]提出的GAN-INT-CLS,但是这些方法生成的图像分辨率都较低。为了解决生成图像分辨率低问题,文献[7]提出了Stack-GAN,主要是将生成高分辨率图像的问题分成不同阶段,在低分辨率图像生成阶段侧重图像对象的布局和结构生成,在图像精炼阶段则纠正了低分辨率阶段生成图像的一些错误,然后对图像中的纹理细节[8]进行绘制。
多阶段生成图像的方法解决了生成图像分辨率低的问题,但是依然存在生成图像与文本条件不符及两者语义一致性较低的问题。为了进一步提高生成图像与文本条件之间的语义一致性,文献[9]在Attn-GAN中引入注意力机制,通过注意力模块将语义特征向量和生成图像中与之最相关的区域对应起来。文献[10]通过局部和全局特征相结合,设计了针对图像边框和图像对象的级联生成网络,提高了生成图像的逻辑性,使图像生成更加准确。文献[11]在图像生成任务中结合了空间注意力机制,实现了可控的图像生成,提高了生成图像的准确性。文献[12]提出了动态注意力生成对抗网络模型(DM-GAN),在每个生成阶段计算出每个单词与图像子区域之间的相关性,提高了生成图像与文本条件之间的语义一致性,但是依然存在生成图像细节缺失、低分辨率阶段生成图像存在结构性错误的问题。
针对上述问题,本文提出一种基于通道注意力的文本生成图像方法。在特征图上采样过程中,引入基于内容感知的上采样模块,提高特征图和输入文本之间的语义一致性,使生成图像更准确。同时在卷积层中使用通道注意力机制,对特征图进行加权,增加不同通道间的信息交互,以使生成图像的细节更丰富。
1 相关工作
1.1 通道注意力机制和上采样方法
近年来,通道注意力被广泛地应用于视觉处理任务[13],可以对每一个特征通道进行加权,实现突出重要信息及抑制无用信息的效果。典型代表是HU等[14]提出的SENet,实现了通过全局损失函数自适应地调整每个特征通道的权重,SENet 在图像分类任务中取得了显著效果。文献[15]在SENet 的基础上提出了ECANet,相比上述方法,ECANet 对特征通道加权时只需要计算与其相邻的k个通道,降低了参数量,同时保证了性能提升。
上采样是图像处理中常用的一种操作,其原理是根据图像原有的像素生成新的像素点,常用方法有插值法和反卷积[16]。文献[17]在目标检测任务中结合反卷积实现对小目标的有效检测。文献[18]提出了基于特征图语义的上采样方法,通过输入特征图得到重组卷积核,充分利用了语义信息,同时参数量较少,在图像增强和图像超分辨率重建任务中取得了较好的效果。
1.2 文本生成图像方法
文本生成图像主流方法是使用堆叠式的生成对抗网络生成高质量图像。文献[19]通过设计不同分辨率的特征融合模块,提高了训练的稳定性,网络收敛更快。文献[20]提出了镜像生成对抗网络(Mirror-GAN)模型,通过集成两个网络构建镜像结构,对生成图像进行重新描述[21],将得到的结果和给定文本条件进行对齐,由此提高生成图像和文本条件的语义一致性。但是低分辨率阶段生成的图像结构严重不合理,会导致后续的生成图像质量较差。如图1 所示,从上到下为DM-GAN 从低分辨率到高分辨的图像生成结果,可以看到在低分辨率阶段生成的图像存在结构不合理的错误,如生成了两个“头部”,缺少“爪子”等,后续精炼过程难以修正。所以,在低分辨率阶段设计更合理的生成器,保证低分辨率阶段生成的图像准确合理,是保证生成高质量图像的关键。

图1 DMGAN 各阶段生成图像Fig.1 Result at each stage of DMGAN
2 基于通道注意力机制的生成对抗网络模型
图2 所示为本文提出一种基于通道注意力机制的生成对抗网络模型(ECAGAN)。网络结构可以分为低分辨率图像生成阶段和图像精炼阶段,低分辨率图像生成阶段的生成器生成64×64 像素的低分辨率图像,图像精炼阶段的生成器生成128×128 像素和256×256像素的图像。判别网络有多个判别器{D0,D1,D2},在低分辨率阶段(k=0),判别器D0只对低分辨率图像和真实图像进行真假判定,在精炼阶段(k=1,2)有相应的判别器Dk对生成图像进行真假判定。

图2 ECAGAN 网络结构Fig.2 Network structure of ECAGAN
2.1 低分辨率图像生成阶段
在低分辨率图像生成阶段,将给定的文本描述输入文本编码器得到语义特征向量s和词向量V,本文使用的文本编码器为预训练的循环神经网络(Recurrent Neural Network,RNN)。语义特征向量s是一个包含文本语义特征的向量,用于低分辨率图像生成。词向量V是一个包含了18 个单词语义的向量,用于精炼阶段的图像生成。编码得到语义特征向量s需要进行条件增强,具体方法是从语义特征向量s的高斯分布N(μ(s),∑(s))中得到平均协方差矩阵μ(s)和对角协方差矩阵ν(s),然后计算得到特征向量c0,(c0=μ(s)+ν(s)⊙ε,⊙代表点乘操 作,ε~N(0,1)),最后c0和一个从正态分布中取样的随机噪声Z拼接得到。将进行一次全连接操作后输入内容感知上采样模块,上采样之后得到特征图R0,特征图输入通道注意力卷积模块之后得到低分辨率图像。
2.1.1 内容感知上采样模块
在低分辨率图像生成之前需要对特征图进行上采样操作,目前通用的上采样方式包括最邻近插值和反卷积。但是最邻近插值的感受野太小,而且未利用语义信息,反卷积则计算量太大。本文的内容感知上采样模块利用原始特征图得到重组卷积核,使用重组卷积核对输入特征图进行上采样,考虑到了每个像素和周围区域的关系,同时避免了参数过多、计算量太大的问题。内容感知上采样模块由自适应卷积核预测模块和内容感知特征重组模块组成[18],结构如图3 所示,特征图输入内容感知上采样模块之后共重复4 次上采样操作,假设输入特征图R的尺寸为C×W×H,上采样的倍率设置为S(本文中设置为2)。经过内容感知上采样模块之后输出上采样之后的新特征图R′,其尺寸为C×SH×SW,输出特征图R′中的区域l′=(i′,j′),对应于输入特征图R中的l=(i,j),对应关系为

图3 内容感知上采样模块Fig.3 Content-aware upsampling module
特征图R输入之后在自适应卷积核预测模块ψ中对输出特征图R′的每一个区域l′预测出卷积核γl′,如式(1)所示,原特征图在内容感知特征重组模块ξ中和预测得到的卷积核进行点乘得到结果,如式(2)所示:

其中:Z(Rl,kup)代表特征图R中点l周围kup×kup大小的子区域;kencoder表示内容编码器的大小。
在自适应卷积核预测模块中,特征图首先经过一个1×1 的卷积层将通道数从C压缩到Cm,然后通过内容编码器对卷积核进行预测,输入通道数为Cm,输出通道数为,将通道维在空间维展开,得到大小为的重组卷积核,最后利用softmax 函数进行归一化,使得重组卷积核权重和为1。
内容感知特征重组模块对于输出特征图中的每个位置l′,将其映射回输入特征图,取出以l=(i,j)为中心的kup×kup大小的区域,和以该点预测出的重组卷积核作点积,得到输出值,如式(3)所示,相同位置的不同通道共享同一个重组卷积核。
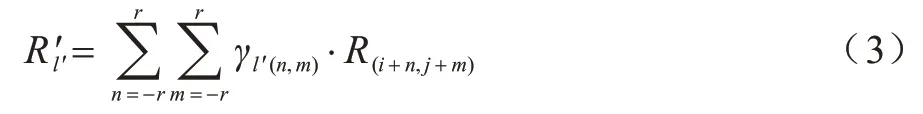
其中:l=(i,j)为输出特征图在输入特征图上的对应位置的点;r=为l的邻域。
2.1.2 通道注意力卷积模块
经过上采样之后得到特征图输入生成器,经过卷积运算生成图像。通过通道注意力对特征图进行加权,使生成图像细节更丰富。此外,跨通道交互可以在显著降低模型复杂度的同时保持性能。通道注意力[15]模块结构如图4 所示。

图4 通道注意力卷积模块Fig.4 Channel attention convolution module
在通道注意力卷积模块中,通道注意力权重ω的计算如式(4)所示:

其中:y=GGAP(R),由输入特征图经过全局平均池化得到;Q是权重矩阵;σ则是Sigmoid 函数。假设接受的特征图R∈RW×H×C,W、H、C分别代表特征图的宽度、高度和通道维度。全局平均池化公式如(5)所示:

权重矩阵Q大小为k×C,对于每一个通道yi,对应的权重ωi计算只需要考虑相邻的k个通道(本文中设置为5),如式(6)所示:

2.2 图像精炼阶段
在低分辨率图像生成阶段完成后,需要对生成图像进行进一步精炼,如图2 所示精炼次数设置为2(k=1,2)。具体的精炼算法步骤如算法1 所示,当两次精炼完成,可以得到高分辨率特征图,生成高质量图像。
算法1图像精炼算法
输入上一阶段生成的特征图Rk-1,词向量V
输出高分辨率特征图Rk
步骤1将特征图Rk-1和词向量V输入动态注意力计算层,表示为:
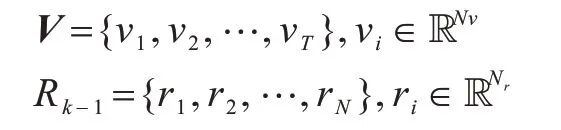
步骤2在动态注意力层中首先计算词向量中每一个单词νi与图像子区域ri之间的相关性mi:

步骤5将特征图进行上采样操作,上采样倍率为2
步骤6将特征图输入一个两层残差网络,得到高分辨率特征图Rk
重复步骤1~步骤6,得到符合要求的特征图,结束精炼过程,将特征图输入通道注意力卷积模块得到高质量图像。
2.3 损失函数
本文提出的模型ECAGAN 属于生成对抗网络,根据生成对抗网络的特点,网络损失函数分为生成器损失函数和判别器损失,其中生成器损失函数形式如式(7)所示:

各级生成器损失函数如式(8)所示:
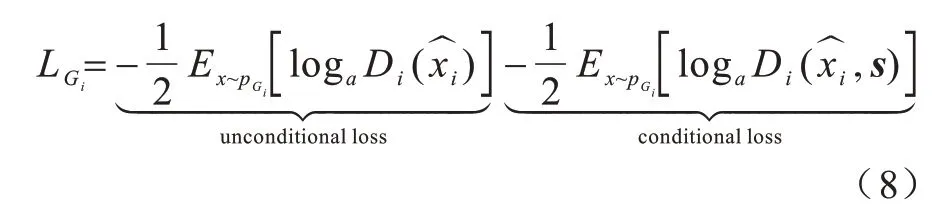
同时判别器的损失函数和生成器损失函数相似,也包括条件损失和非条件损失两部分,如式(9)所示:

在式(7)~式(9)中:Gi和Di分别代表第i阶段的生成器和判别器;xi来自第i阶段的真实图像分布则是来自模型分布是经过编码器编码后的语义特征向量。
DAMSM 模块通过计算文本语义特征向量和生成图像特征向量之间的相似度,来衡量生成图像和文本条件之间的语义一致性。图像特征向量使用Inception-V3[22]进行提取,DAMSM 损失函数可以提高生成图像和文本条件的语义一致性,条件增强损失则是通过从高斯分布中重新采样输入语句向量来增强训练数据,避免模型过拟合,如式(10)所示:

其中:N(0,I)代表高斯分布;μ(s)代表语义特征向量的平均协方差矩阵;Σ(s)是对角协方差矩阵。感知损失可以让生成图像的高层信息和真实图像更接近,如式(11)所示:

其中:I和I′代表真实图像和生成器生成的生成图像;ϕ是对图像进行特征提取操作,本文使用一个在ImagNet 数据集上预训练的VGG-16 网络来对图像进行特征提取;C、H、W分别代表特征图的通道数、高度和宽度。
在训练过程中,通过生成器损失和判别器损失交替迭代来优化更新参数,在训练生成器时判别器参数固定,在训练判别器时生成器参数固定。最终得到能够生成高质量图像的生成模型。
3 实验结果与分析
3.1 实验环境及数据集
本文实验环境如下:Ubuntu 16.04,CPU 为i7-4790k,GPU 为GeForce GTX 1080Ti,实验代码使用了Pytorch 深度学习框架,在GPU 上运行。
本文使用的数据集为公开数据集CUB-200-2011(Caltech-UCSD Birds-200-2011)[23],CUB 数 据集中包含200 种不同的鸟类图像,共计11 788 张图像,其中包含训练集8 855 张图像和测试集2 933 张图像。训练中设置batch size 为10,生成器和判别器的学习率均为0.000 2,训练轮数设置为900,优化器使用Adam,β1设置为0.5,β2设置为0.999。
3.2 评价指标
为验证本文方法的有效性,本文采用3 种评价标准对生成图像的质量与多样性和语义一致性进行评价:
1)R-值精度(R-precision)。由XU 等提出用来评估生成的图像与输入文本条件之间的语义一致性。对于每个生成的图像,使用其真实的文本条件和从测试集中随机选择的99 个不匹配描述来形成文本条件池,然后提取生成图像和给定文本描述的全局特征向量,最后计算全局图像向量和全局文本向量之间的余弦相似度。R值越高代表生成的图像与输入文本条件之间的语义一致性越高。
2)初始分数(Inception Score,IS)。由文献[24]提出,用于衡量生成图像的清晰度和多样性,具体方法是通过计算边缘分布和条件分布的相对熵损失,衡量生成图像的质量,如式(12)所示:

其中:x表示由生成器生成的样本;p(y)表示边缘分布;p(y|x)表示x输入图像分类网络得到的分布;DKL(A||B)表示A、B两者之间的KL 散度,用来衡量两个分布之间的相似度,IS 值越大,表示生成图像质量越高。
3)Frechet Inception 距离得分(Frechet Inception Distance score,FID)。由文献[25]提出,具体方法是计算生成图像和真实图像分布之间的距离,如式(13)所示:

3.3 结果分析
本节将定量和定性地与其他方法进行比较,从评价指标和视觉效果两个方面来评估实验结果。首先是评价指标的量化对比分析,使用R值、Inception Score 和FID 3 个评价指标对本文方法和经典文本生成图像网络在CUB 数据集上进行对比。然后对本文方法和之前的方法进行主观视觉对比,验证本文方法的有效性。
3.3.1 定量结果分析
为了得到式(7)中超参数λ1的最优值,在保证其他参数不变的情况下将λ1分别设置为0、0.1、1、5、10进行对比实验,实验结果如表1 所示,粗体表示值最优。可以看到:当λ1=1 时模型的评价指标值最好,分析可知,将式(7)超参数λ1的值设置为1 时模型的性能最佳。

表1 不同参数设置下ECAGAN 方法R、IS和FID的最优值Table 1 Optimal values of R,IS and FID for ECAGAN methods under different parameter settings
与主流方法的对比结果如表2 所示,其中,“—”表示没有数据,加粗字体为每列最优值。

表2 不同方法在CUB 数据集上的对比Table 2 Comparison of different methods on CUB dataset
通过对比发现,本文提出的方法(ECAGAN)在CUB数据集上的实验结果与目前主流网络相比均有一定提升。相比AttnGAN 和DMGAN,R值分别提高了11.5%和4.6%,Inception Score 分别提高了10.7%和1.6%,FID也有一定的降低。实验结果表明,ECAGAN 模型生成的图像质量更好。
3.3.2 定性结果分析
在视觉效果方面,图5 为4 种GAN 模型在CUB 数据集上的可视化结果。在图5(a)~图5(d)中,第1、2、3、4、5 列输入的文本条件和图1 一致,结果表明本文方法有效提高了生成图像的质量。可以看到图5(a)~图5(d)中第1、2 列中本文方法生成的图像在大面积的纹理特征上比较清晰,头部细节丰富合理,每个部位之间纹理过渡合适,其他模型生成的图像缺乏细节,不同部位如头部、躯干差异较大,导致图像缺乏真实感。在图5(a)~图5(d)第3、4 列图像中,本文方法生成的鸟类对象完整,每个部分细节合理且与背景相符。其他模型生成的图像鸟类结构缺失,细节不足,在背景中显得十分突兀,导致图像真实感不够。在图5(a)~图5(d)第5、6、7 列则能明显看出,相比其他3 种方法,本文算法生成的图像具有完整的结构和丰富的细节。StackGAN、AttnGAN、DMGAN 3 种方法生成的图像存在结构不合理,缺少喙、爪子、眼睛等部位,或者出现了2 个头部、3 个爪子等情况,明显存在语义一致性较差、无法按文本条件生成图像、图像存在结构性错误等问题。

图5 4 种GAN 方法在CUB 数据集上的生成结果Fig.5 Generation results of four GAN methods on CUB dataset
本文方法使用内容感知上采样模块,提高了生成图像和文本条件之间的语义一致性,使生成图像更准确。结合通道注意力卷积模块,使生成图像边缘细节平滑过渡,生成对象各个部位的纹理特征准确,区别明显,生成图像的质量更高,更接近真实图像。
3.4 消融实验
为了验证本文提出的内容感知上采样模块和通道注意力卷积模块的有效性,分别设置DMGAN、DMGAN+CAU、DMGAN+ECA 和DMGAN+CAU+ECA 4 组对比实验,实验结果如表3 所示。本文的基础网络为DMGAN,CAU 表示内容感知上采样模块,ECA 表示通道注意力卷积模块。从表3 可以看出,两个模块对生成结果均有正向调节作用,最终结合两个模块可得到本文方法的最佳效果,证明了本文方法的有效性。

表3 消融实验结果对比Table 3 Comparison of ablation experiment results
4 结束语
本文基于动态注意力生成对抗网络模型,针对生成图像细节缺失、低分辨率阶段生成图像存在结构性错误的问题,提出一种基于通道注意力的文本生成图像方法。通过引入内容感知上采样模块,提高生成图像和文本条件之间的语义一致性,改善低分辨率阶段生成图像的结构性错误。在卷积层加入通道注意力机制,使生成图像细节更加清晰,在训练过程中结合感知损失使训练更加稳定。实验结果表明,本文模型生成的图像质量更高,更加接近真实图像。本文方法虽然在生成图像上取得了较好的效果,但仍然存在网络模型较大、训练时间长等问题,下一步将对网络模型进行精简优化,在保证性能的基础上达到提高训练速度的目标。
