基于漂移检测的流程变体差异分析方法
2022-04-18巩秀钢徐兴荣李会玲牛慧敏
李 婷,巩秀钢,徐兴荣,李会玲,牛慧敏,刘 聪
(山东理工大学 计算机科学与技术学院,山东 淄博 255000)
过程挖掘技术提供了一种从事件日志中自动抽取过程知识的方法,其典型的应用场景之一是过程发现[1],即从事件日志中挖掘出潜在的过程模型。过程发现算法能够从稳定行为的事件日志中生成过程模型,但由于多方面的因素,过程模型在真实的业务环境中是动态调整的[2],这种业务流程在执行过程中的动态变化称为漂移。如果将传统的过程发现技术应用于含有漂移的事件日志中,挖掘出来的过程模型由于混杂了多个模型的行为变得复杂且无法解释。如何通过漂移检测来定位漂移前后流程内容的变化显得尤为重要。
在实践中,业务流程中漂移的存在是事先不知道的,分析人员需要随着时间的推移区分哪些流程发生了变化,哪些没有变化,从而做出决策来减轻其影响[3]。现有的过程挖掘研究仅侧重于漂移检测,对漂移前后流程变化的分析和解释略显不足。本研究通过抽取日志中轨迹的活动关系来检测和定位漂移,对漂移前后的流程进行可视化分析,揭示具有显著差异的流程行为,帮助企业管理者适应或改进其业务流程。实验结果表明,所提方法能够有效检测到漂移,并对检测到的漂移提供准确描述。
1 相关工作
1.1 漂移检测
业务流程中事件日志的可用性激发了各种流程挖掘技术,这些技术主要支持过程监控和分析。经典的过程挖掘技术通常假设日志对时间不敏感,即在产生事件日志的执行过程中从未发生版本演化[4]。在过程挖掘中引入漂移的挑战是如何以时间依赖的方式表示行为变化。
早期的方法大多基于假设检验和统计测试,不仅需要巨大的特征空间,还需要人为选择合适的特征,同时还不易扩展。如Bose等[5]将轨迹表征为特征向量进行统计测试,Maaradji等[6]直接对两个连续窗口之间的轨迹频率进行统计测试。这类方法保留了有损统计检验可靠性的低频行为,因此存在局限性。
基于相似性的漂移检测方法依赖于事件日志和提取的行为特征,如活动频率或活动之间的关系。Carmona等[7]从早期的数据中建立一个凸多面体来抽象表示包含多条轨迹的事件日志,并检查此多面体与最近轨迹的交点,但在检测到漂移后需要重新启动,扩展性不强。刘娜等[8]使用流程一致性技术来检查从轨迹中提取的活动与发现的流程模型之间关系的相似性。该类方法在考虑不属于实际业务流程的行为时,可能会检测到虚假的漂移。
1.2 流程变体差异分析
从过程挖掘的角度来看,比较流程变体的方法可以用在概念漂移中来描述业务流程行为方面的差异。Adriansya等[9]基于对齐的方法将每个流程模型与相应事件日志进行比较来显示模型和流程执行之间的差异。Beest等[10]从对应的事件日志中计算行为的相关频率来识别两个事件日志之间的差异,但此方法只考虑了相对频率,存在局限性。Perner等[11]利用决策树来比较变体差异,由于只对其分支规则进行结构比较,容易造成高度过拟合的现象。Bolt等[12]对从子日志中提取的流程指标执行统计测试,但不能识别某些变化,也无法对有差异的流程行为进行可视化表示。Nguyen等[13]通过抽取日志中实体间的关系来构造关系图,并根据权重、公共节点和边进行比较,生成一个可视化的矩阵来突出显示两个过程变体之间的变化。
1.3 现存挑战
现有工作只强调漂移检测和变体差异分析这两个孤立任务而缺乏全局观念,漂移检测仅能单纯地定位发生变化的关键点,并不能对漂移点前后的流程行为变化进行详实描述,无法有效解决漂移定位与变体分析孤立存在的问题。因此,本研究提出一种基于漂移检测和流程变体差异分析的综合方法,在不需要额外的数据结构或过程模型的情况下,能够有效检测变化并解释变化的具体内容,帮助业务分析人员更好地理解流程行为并做出决策。
2 基于漂移检测的流程变体差异分析方法
2.1 基于漂移检测的流程变体差异分析方法
本研究提出的基于漂移检测的流程变体差异分析方法,整体框架如图1所示。首先在郑灿彬等[14]所提方法的基础上进行改进,以事件日志为输入进行漂移检测;然后根据漂移检测的结果对事件日志进行分割,采用可视化方法将分割后的两个连续子日志的流程呈现出来;最后比较两个流程图中活动的发生顺序,标记并输出具有显著差异的活动结点和边。
2.2 漂移检测
过程挖掘领域的核心数据是事件日志,需要从事件日志中提取流程的相关信息,完成对漂移的检测和对流程差异行为的描述。本研究对文献[14]进行改进,提出一种通过抽取日志中活动间行为上下文关系来检测漂移的方法,整体架构如图2所示。
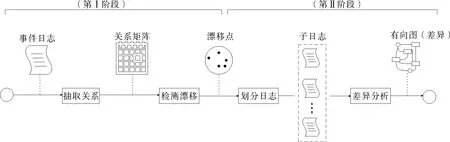
图1 基于漂移检测的流程变体差异分析方法框架
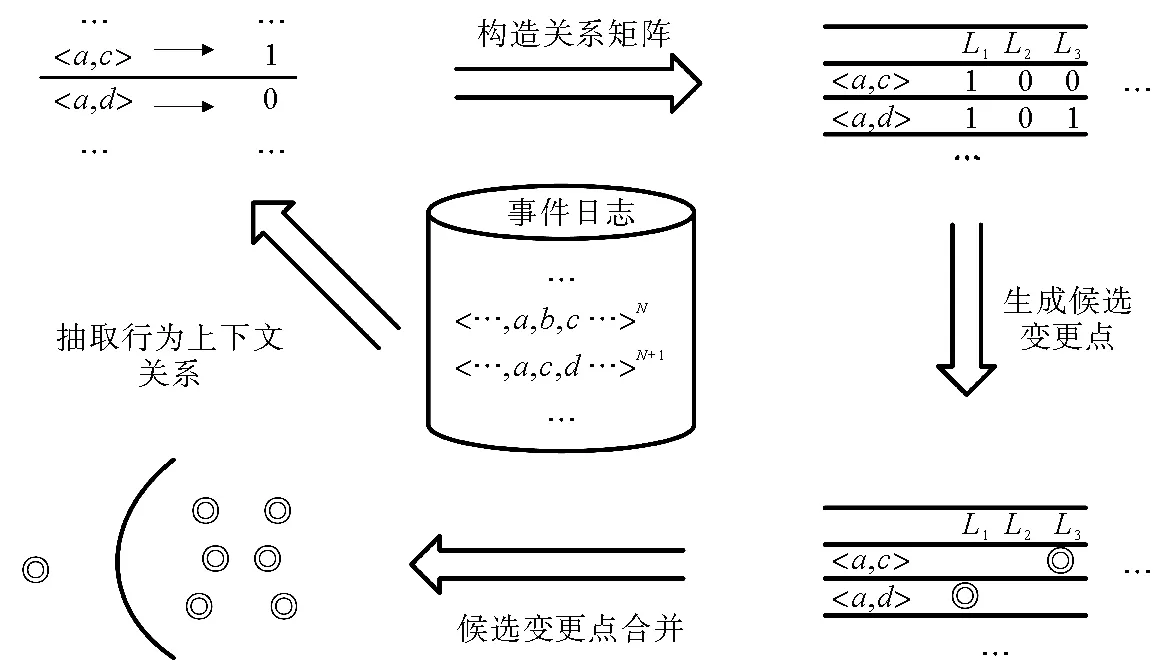
图2 漂移检测方法
定义1(行为上下文关系) 行为上下文关系[15]是一对活动序列,事件日志L中的一组行为上下文关系表示为:βL∈ρ(A*×A*),βL={(σl,σr)∈A*×A*|∃σ∈L,σ′∈A*(σl·σ′·σr∈σ)},其中,A为一组活动,A*为A上所有可能活动序列的集合,σl和σr为2个活动序列,σ′为则轨迹σ的子序列。
例如,在轨迹σ=
定义2(关系矩阵) 设L是一个包含n条轨迹的事件日志,即L={σ1,…,σn}。D为一个关系矩阵,Dij表示矩阵D中第i行第j列的元素,i为日志中所包含的活动关系的有限集合,j为轨迹的ID。若关系i在轨迹σj上存在,则Dij=1,否则Dij=0。
定义3(频率变化) 给定一种活动关系i和一个整数时间间隔[x,y),i在[x,y)上的频率变化情况为:
1) 总是存在,Dij=1;
2) 从不存在,Dij=0;
3) 有时存在,Dij={0∪1}。
以事件日志L={abcd,acbd,abdc,adbc,acdb}为例,表1为关系长度为1的行为上下文关系矩阵。根据关系矩阵的定义,矩阵的每一行代表日志中一种活动的变化情况,每一列代表每条轨迹中存在的所有活动关系。若活动关系i在时间间隔[x,y]上总是存在或者从不存在,表明关系i在此间隔内具有不变性,将间隔长度预先设置为某个阈值。若在相邻两个时间间隔上的同一活动关系有变化,即在给定的时间间隔内从一个值变为另一个值,则说明流程可能在两个时间间隔的交点处发生了漂移,此处的交点即为可能的漂移点。
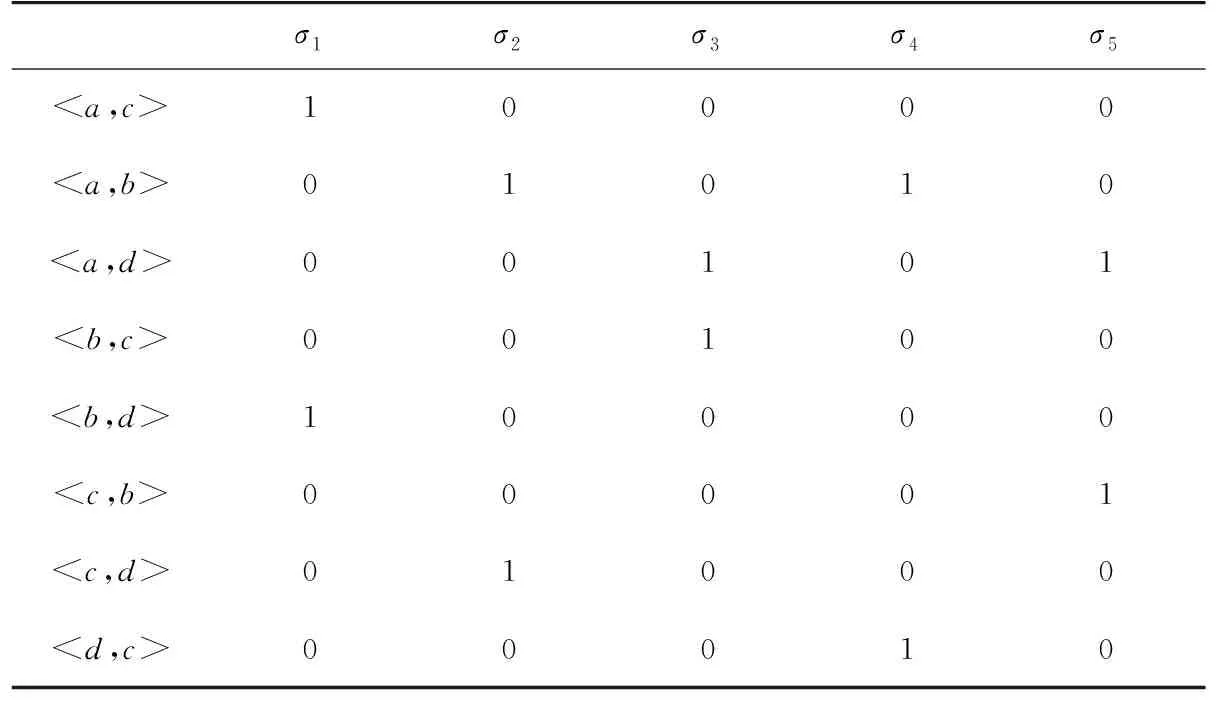
表1 L={abcd,acbd,abdc,adbc,acdb}的关系矩阵
具体检测过程如图3所示。设置间隔长度为4,第一行为矩阵中的列号(轨迹ID),第二行为活动关系的变化情况。区间[1,15]以5为单位划分为3个区间,区间内活动关系经历了有时存在、总是存在、从不存在3个阶段。区间[1,2)和区间[3,5)距离长度小于4,不认为两个区间关系的过渡会产生漂移;区间[1,5)和区间[6,10)距离长度大于4,关系从有时存在变为总是存在,认为两个区间关系的过渡产生漂移;区间[6,10)和区间[11,15)距离长度大于4,关系从总是存在变为从不存在,认为两个区间关系的过渡产生漂移,故可能的候选漂移点为6和11。

图3 候选漂移点检测
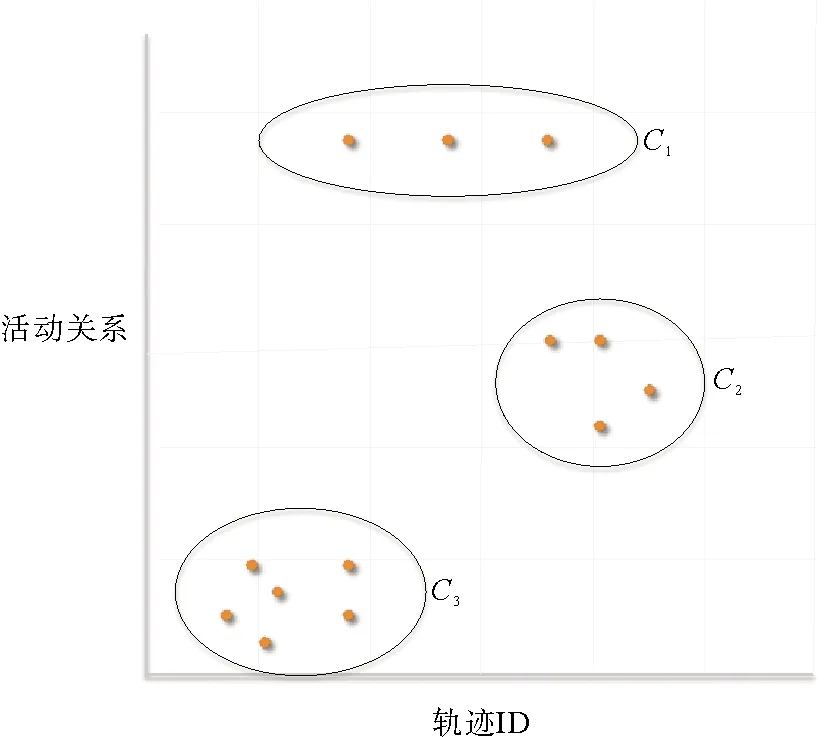
图4 候选漂移点合并
在每个给定的活动关系上进行检测得到的候选漂移点不一定是真正意义上的漂移点,需要对候选漂移点进行聚类,以获得大概率事件下整个流程的漂移点。该聚类方法依赖于密度聚类算法,通过密度聚类将检测到的漂移点聚成若干点簇,按照簇中点的数量由大到小排序,簇中点的数量越多,该点簇越有可能代表最终的流程漂移点。通过对簇内所有漂移点进行聚合平均,获得表示流程漂移点的单一值,可用质心来表示。
示例过程如图4所示,基于密度聚类算法对候选漂移点进行合并,合并后的点簇C3比点簇C2包含更多的候选漂移点,说明点簇C3更有可能代表一个真正的流程漂移点,此处点簇C3用质心来表示。下面给出漂移检测的算法。
设事件日志中包含的轨迹有n条,活动关系数有m个,轨迹的平均长度为k。算法1中抽取行为上下文关系并转换成关系矩阵的复杂度为Ο(nk)。由于候选漂移点的数量不会超过mn/s,因此,检测候选漂移点并对候选漂移点进行合并生成模型漂移点的复杂度为O(mn)+O(mn/s)=Ο(mn)。综合来看,整个漂移检测算法的时间复杂度为O(nk)+O(mn),稍低于文献[14]中的时间复杂度O(nk2)+O(mn)。

算法1 漂移检测 输入:事件日志L,关系长度d,最小时间间隔s,聚类半径r; 输出:模型漂移点集合Drift. 1)Drift←0, List←ø, C←0, res←ø, D←ø 2)For i←1 to len(trace)-1 do 3) For key to res, key() then 4) if [key[i]∈key[i-1], key[i+1]] then 5) D←{D∪res[i]} 6)return D 7)For j←0 to D[i][n] do (i≤n) 8) if [D[i][j], D[i][j+1]]∈d and [D[i][j], D[i][j+1]]>s then 9) List←{List∪D[i][j]} 10) return List 11) For k←0 to clusters[list, r] do 12) C← clusters[k] then 13) sort(C)max→min then 14) Drift←{Drift∪C} then 15) return Drift
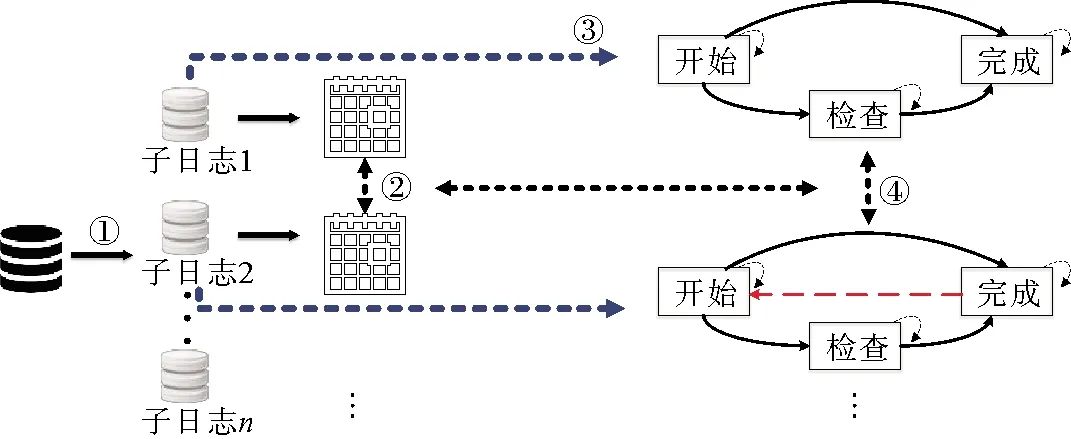
图5 变体差异分析算法
2.3 流程变体差异分析
基于上述工作,在漂移检测的基础上,给出定位相邻变体间流程行为变化的算法,算法的整体架构如图5所示。①将原始事件日志按照检测到的流程漂移点切割成多个连续的子日志;②通过比较子日志间关系矩阵的相似性来预判相邻变体间的差异;③通过绘制有向图的方式来描述每个流程漂移点前后子日志中活动间的发生顺序;④根据有向图中对应活动和活动顺序的一致性来判定变体间具有显著差异的行为并对其进行可视化。
将分割后的两个连续子日志依据活动发生的顺序生成有向图,再对有向图中的活动顺序进行比较,若无法匹配,则在有向图中对活动结点和活动顺序进行标记。其中,活动的发生顺序是指活动的跟随关系,在有向图中用箭头来表示,箭头的始端表示先发生的活动,箭头的尾端表示随后发生的活动。图6为两个变体间活动片段出现差异的场景示例。

图6 差异分析示例
算法2展示了流程变体差异分析的核心部分。设事件日志中包含的轨迹有n条,活动关系数有m个,则算法2的时间复杂度为Ο(mn)。本研究方法的整体复杂度为Ο(nk)+Ο(mn)。

算法2 漂移检测 输入:模型漂移点集合Drift; 输出:变体间的矩阵相似度δ, 变体间具有显著差异的行为Diff. 1)δ←0, Diff←ø, D←ø, count←0, 2)For i←0 to len(Drift)-1 do 3) basic on Drift[i] split L to L0, L1, L2,…,Ln-1 then 4) D0~n-1←{L0~n-1} compare [δ0~n-1, δ1-n] 5) count++ 6)For j←0 to count do 7) found activity and D[j] then 8) if activity!=D[j] then 9) Diff←{Diff∪D[j] } 10) return Diff
3 实验分析
3.1 数据集及实验设置
为了模拟概念漂移的存在,使用ProM工具对Petri网模型生成仿真日志。实验基于PC Intel Core i5-4210 M 2-60 GHz CPU,12 GB RAM环境,使用Python语言实现。
利用文献[6]中已公开发表的数据集进行测试,图7为用于测试漂移的一个贷款申请业务流程[6]模型,共包括15个活动、1个开始事件和3个结束事件,并展示了循环、并发和选择等控制流结构。数据集中共包含72个与贷款申请业务流程不同变体相关的合成日志。
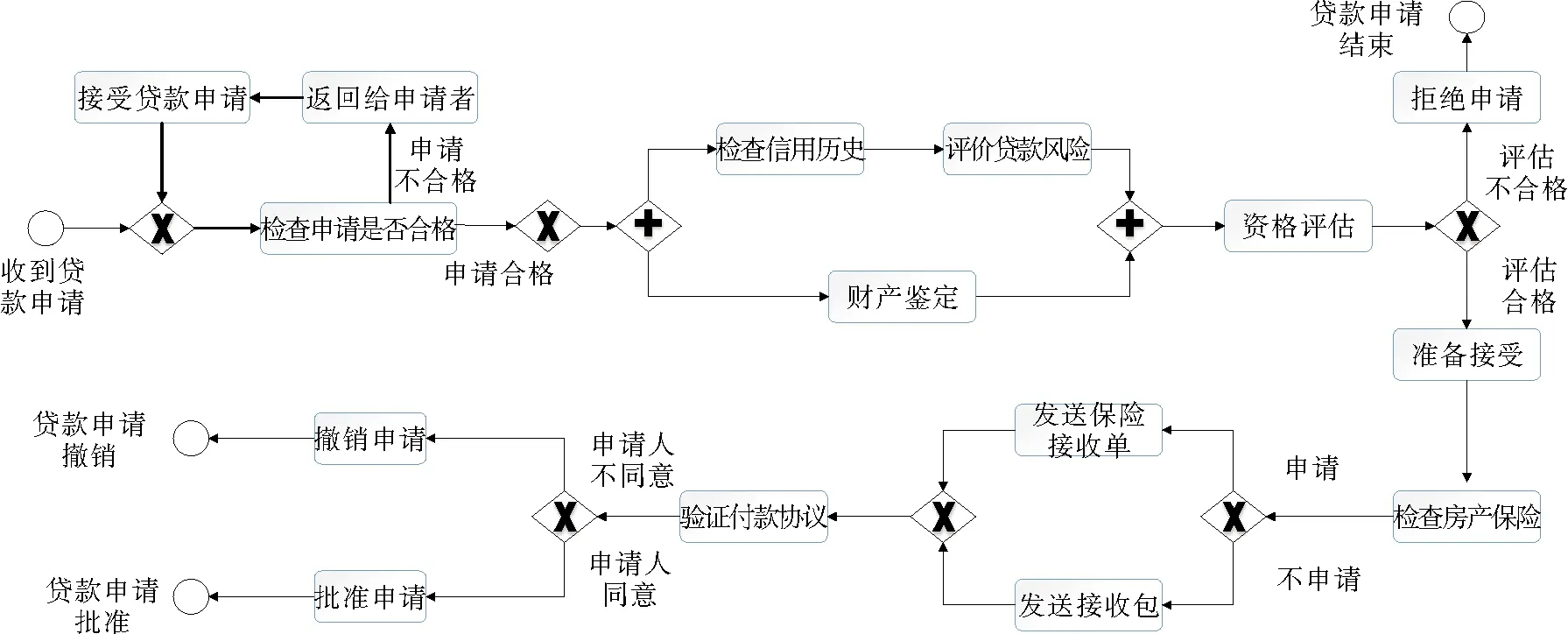
图7 贷款申请业务流程的参考模型
表2为12种简单的控制流变更模式,为了进一步模拟更复杂的情况,将简单的变更模式分为插入(I)、重排序(R)和选择(O)3个类别,通过从每个类别中随机应用一个模式相互嵌套产生6个可能的综合变化模式:IOR、IRO、OIR、ORI、RIO、ROI。例如,综合模式IOR是通过插入(I)一个新活动,然后选择(O)该活动或现有活动,最后将整个模块放入重排序(R)结构中来获得。
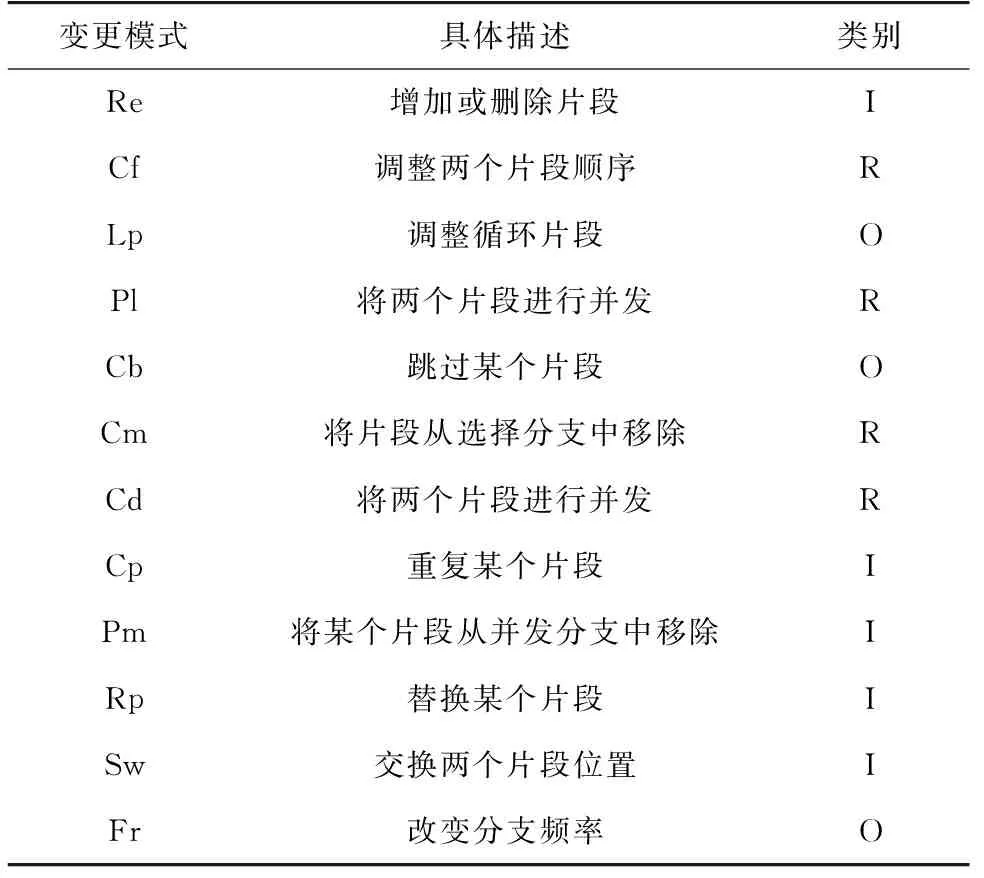
表2 12种简单的控制流变更模式
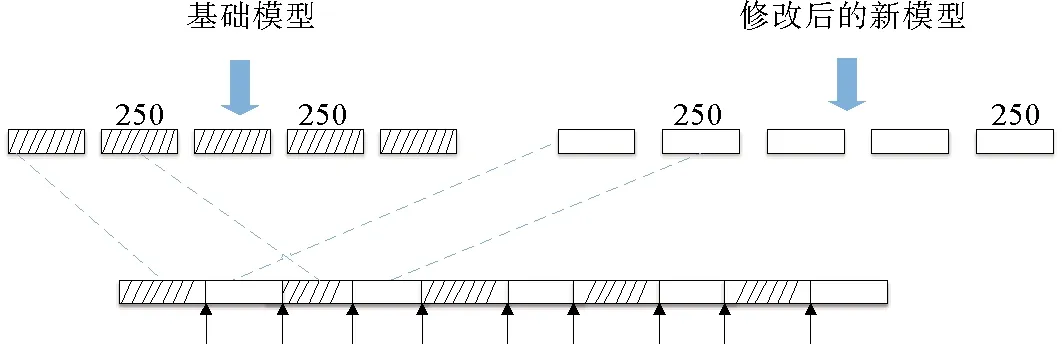
图8 日志仿真过程
在日志仿真过程中,先通过应用以上变更模式对基础模型进行修改得到新的模型,然后为每个修改后的新模型和基础模型仿真生成5组同等规模的事件日志,每组日志规模分别为250、500、750、1 000,最后将每组日志按顺序交叉拼接得到混合事件日志。图8以250条轨迹的日志规模为例进行仿真,该事件日志混合了两个模型的日志,每个模型分别生成5组250条轨迹的日志,得到10组250条轨迹规模的日志,即最后的混合事件日志为L10,250。
3.2 评价指标
以日志拼接的方式生成混合日志,说明日志中发生漂移的位置是事先已知的。如果检测到的漂移点位于实际漂移点的某个较小邻域半径R内,则认为该检测结果正确,R越小,检测的精度越高。为了评估检测的准确性,使用数据挖掘[16]中针对漂移检测建立的既定指标,即以召回率和精确度的调和平均值衡量的F-Score来度量方法性能:
(1)
(2)
(3)
其中:TP表示正确检测到的漂移点数量,FP表示误检的漂移点数量,FN表示漏检的漂移点数量。
为了对检测到的具有显著差异的行为进行准确评估,设计一个基于矩阵相似性的方法来预判相邻变体的差异:
(4)
(5)
其中:α为矩阵相似度,j为第j个矩阵,xi为矩阵中的某一活动关系,xi,j为活动关系xi在矩阵j中的成立情况。若活动关系xi在相邻两个矩阵中成立情况不一致,则标记为1,反之为0。然后,统计成立情况不一致的活动关系在全部活动关系中所占比例,进而得到两个矩阵的相似度。
3.3 实验结果
为测试算法的效果,在不同规模的混合日志上(L10,250,L10,500,L10,750,L10,1000)进行测试。图9为本研究算法在不同邻域半径R下对12种基本变化模式进行漂移检测的平均效果。由图9可以看出,本研究算法(简称本算法)的检测效果随着邻域半径R的增大而明显提升。聚类半径对检测效果的影响如图10所示,当聚类半径增大到超过每组日志的规模时,本该分开的点簇可能会聚合在一起,导致漂移点被漏检,从而影响召回率和准确率,故本算法在聚类半径较小时会取得好的效果。
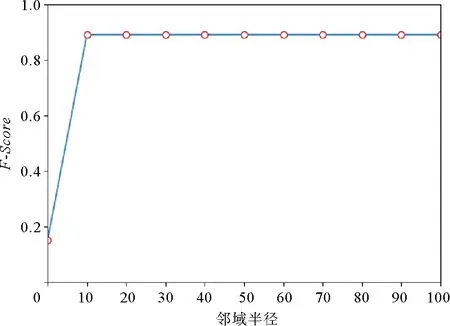
图9 不同邻域半径对结果的影响
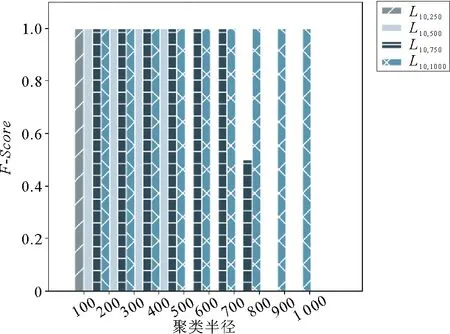
图10 不同聚类半径对结果的影响Fig. 10 The influence of clustering radius on the results
此外,本算法是在文献[14]的基础上改进得到的,在保证漂移检测准确性的前提下,对本算法和文献[14]在时间效率上进行对比,见图11。可见,本算法的时间效率优于文献[14],进一步验证了二者在时间复杂度上的差异。
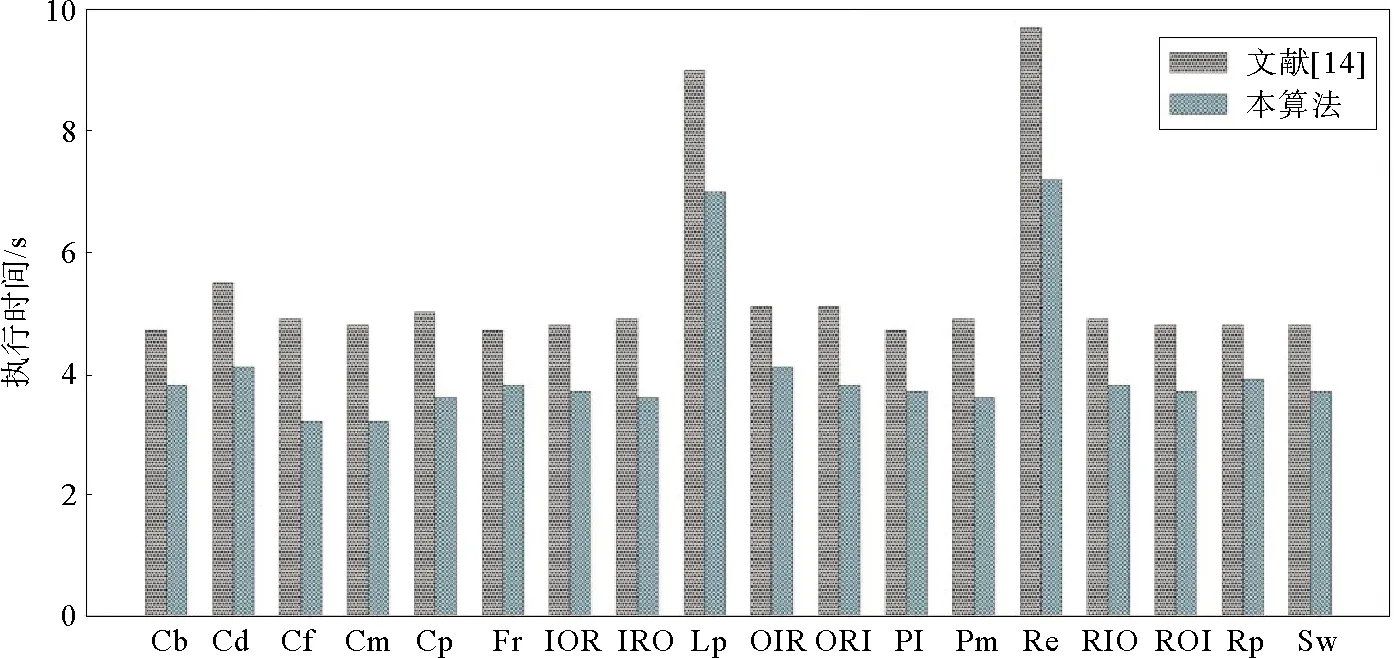
图11 时间效率对比
漂移前后相邻变体间行为的差异能够体现流程的演变,故利用漂移前后相邻变体的相似度进行预判,能大概率的度量流程变体之间行为程度的差异。将聚类半径R固定为10,在ORI模式下得到的混合日志L10,1 000中检测出来的流程变体矩阵之间的相似程度见表3。

表3 L10,1 000中相邻流程变体矩阵的相似度
对漂移前后流程变体间的差异行为进行检测和标注,能够更准确地把握流程行为的演变。图12为综合变化模式ORI下,混合日志L10,1 000中检测出来的变体1和变体2的有向图,图13为两者具有显著差异行为的可视化示意图。
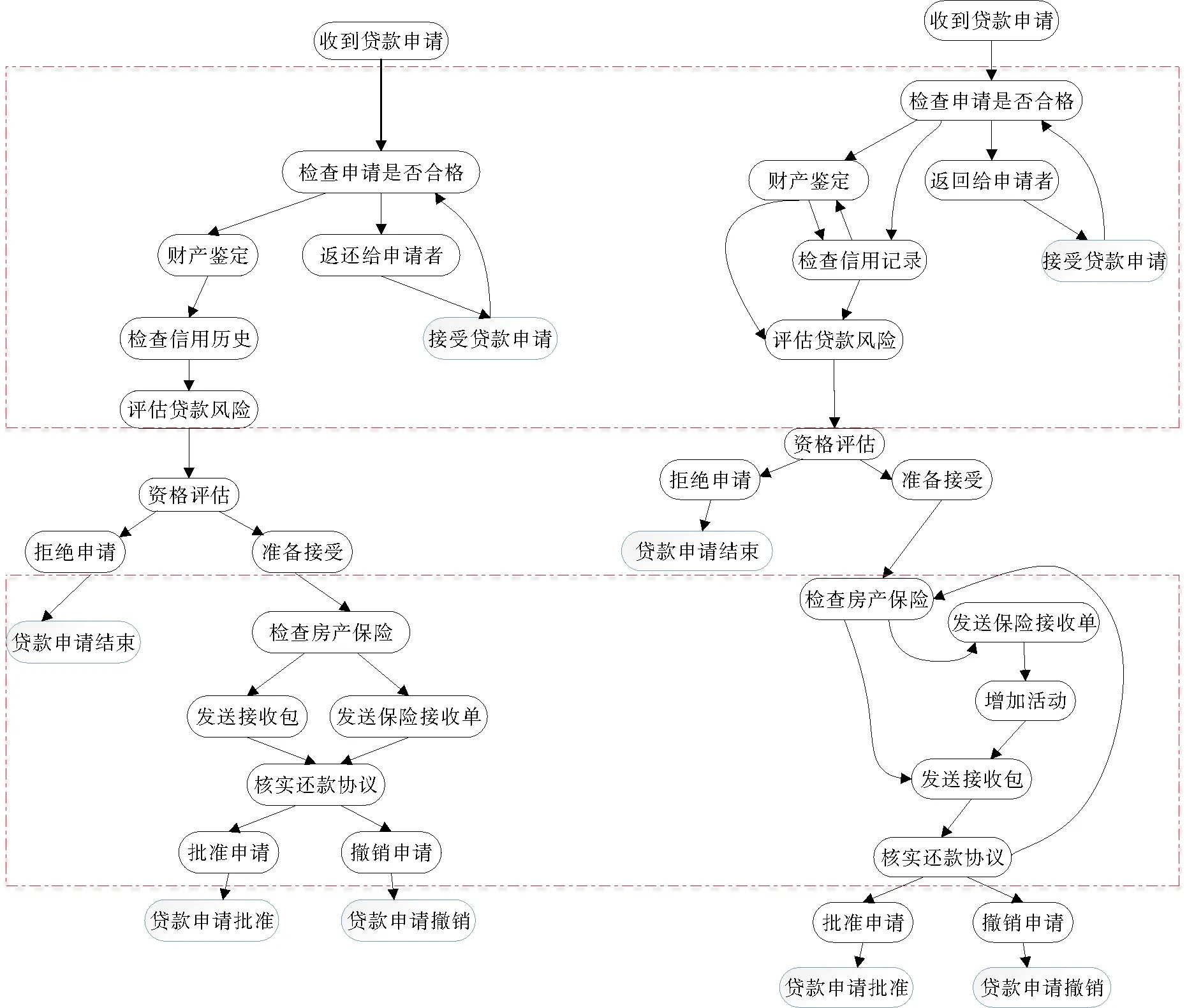
图12 变体1与变体2的有向图

图13 变体1与变体2差异行为的可视化
根据上述实验可知,从浅层的检测漂移点到更深层次的定位及可视化描述能够揭露业务动态演化过程,可以帮助业务分析人员更好地进行流程配置和维护。
4 结论
通过抽取事件日志中活动间行为上下文关系的方法来检测漂移,不仅可以降低算法的时间复杂度,还能通过结果对漂移前后的变体流程进行差异检测。此外,根据所提评估方法对变体间行为差异的检测结果进行质量评估,间接证明了本算法的有效性。本算法主要针对离线场景下的概念漂移,未来可以从在线场景入手对漂移以及漂移后的流程演变进行分析或者预测。此外,针对更复杂的业务流程场景,如跨组织交互过程,尝试给出针对性的漂移检测算法。
