基于多头注意力门控卷积网络的特定目标情感分析
2022-04-18樊建聪
李 浩,樊建聪,2
(1.山东科技大学 计算机科学与工程学院,山东 青岛 266590; 2.山东省智慧矿山信息技术重点实验室,山东 青岛 266590)
近年来,随着互联网的快速发展,越来越多带有情感的信息发布在社交媒体上,如对商品的评论、热门事件的观点、政治事件等。情感分析是从给定的主观性文本中挖掘有用信息的过程,这些信息能够反映人们对于商品的态度、热点事件的思考、政策的倾向等。文本情感分析[1]是自然语言处理领域中的一个重要研究方向,在舆情分析、意见挖掘[2]等应用领域中发挥着重要作用。
传统的情感分析方法主要包括基于词典的方法[3]和基于机器学习的方法。基于词典的方法主要依靠情感词典[4],分类效果取决于构建的情感词典的质量和输入规则。基于机器学习的方法包括有监督学习和无监督学习方法,有监督学习方法必须有大量标注的数据,耗费人工成本;无监督学习方法以聚类方法和隐含狄利克雷分配(latent dirichlet allocation,LDA)为主,不需要人工标注数据,但在处理复杂问题时准确率不如前者好。近几年随着神经网络技术的快速发展,循环神经网络(recurrent neural network,RNN)和卷积神经网络(convolutional neural network,CNN)在自然语言处理领域得到广泛应用。Kim等[5]利用CNN解决了文本分类问题;Cho等[6]使用RNN构建Encoder-Decoder模型,更好地学习到序列的语义信息和语法信息。早期基于RNN模型的特定目标情感分析主要是利用RNN来获得句子的上下文语义信息,如Tang等[7]提出的目标依赖的长短期记忆网络(target dependent long short-term memory,TD-LSTM)模型,Wang等[8]提出的带有目标嵌入的注意力长短期记忆网络(attention-based LSTM with aspect embedding,ATAE-LSTM)模型等,但LSTM模型存在模型复杂、不能并行计算等问题,在训练时需要大量的时间。尽管LSTM模型可以提取长距离的上下文语义信息,但是对于含有多个目标的文本目标情感分析任务,局部特征对特定目标分类结果的影响相对于全局特征更加重要。CNN通过不同的卷积核运算获取不同粒度的特征,在获取句子的局部特征任务上具有独特优势。
特定目标情感分析[7](aspect-based sentiment analysis,ABSA)是对文本中特定目标实体的情感极性进行分类,是一项更细粒度的情感分析任务。例如,“这家酒店的服务很好,但是地理位置不容易找到,太偏了。”该文本有“服务”和“地理位置”两个目标实体,目标实体“服务”对应的情感极性是积极的,而“地理位置”对应的情感极性是消极的。因此,一个文本中多个不同的目标实体可能存在相反的情感极性。在特定目标情感分析中,如何获取目标实体与上下文的关系也是热门研究内容。注意力机制通过一个注意力矩阵计算出句子相应的注意力特征,在训练时重点关注某些信息,在实体识别、文本分类、机器翻译等文本领域得到广泛使用。梁斌等[9]利用多注意力的卷积神经网络获取深层次的情感特征信息,有效识别目标的情感极性。李明扬等[10]融入自注意力机制对社交媒体命名实体识别任务做了改进,通过不同子空间捕获上下文信息来提高实体识别性能。然而,简单的注意力模型不善于捕获上下文词对目标词的影响程度。
本研究针对RNN对句子建模耗费大量时间和无法获取局部特征的问题,采用带有门控机制[11]的卷积神经网络获取句子语义特征,摒弃RNN结构,使用门控机制控制通过神经网络节点的信息,增强目标特征的表达;为了更好地获取上下文信息,本研究利用注意力机制构建多头注意力层,通过对文本信息特征进一步表达,提取更多的信息,通过带有门控操作的卷积神经网络,再经过隐藏层处理,获得目标文本的情感极性判断;为了弥补CNN在获取文本序列信息方面的劣势,在输入层加入文本与目标实体的相对位置编码信息,增加文本的额外信息,提升特定目标情感分析性能。
1 带有位置嵌入的多头注意力门控卷积网络
1.1 问题定义与模型架构
首先,模型通过输入层获得文本嵌入矩阵、位置嵌入矩阵和目标嵌入矩阵;然后,利用多头注意力层对文本嵌入矩阵进行深层次特征表达,在拼接位置信息后输入到卷积层进行局部特征提取,将提取到的特征与目标信息融合,利用tanh门和relu门进行对位相乘操作,控制信息传递;最后使用平均池化得到最终特征,输出到Softmax分类器,完成目标情感极性识别。

图1 PE-MAGCN模型架构
1.2 输入层
输入层包括文本嵌入(word embedding)、目标嵌入(target embedding)和位置嵌入(position embedding),目的在于获得文本的表示矩阵。
文本嵌入是使用自然语言处理中的词嵌入方法,将高维度one-hot编码转换为低维度的连续值向量来表达词的语义信息。用文本嵌入矩阵S={w1,…,wi,…,wn}表示Sc经过词嵌入得到的实数矩阵,wi∈Rdw是第i个词的实数值向量,其中dw是每个词用向量表示的维度。
目标嵌入是将目标实体用连续值向量来表示,向量的维度与文本嵌入向量一致。目标嵌入矩阵用T={wi,wi-1,…,wi+m-1}表示语料中标注的实体。
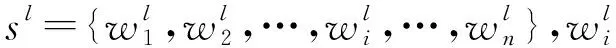
(1)
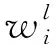
1.3 多头注意力层
受Transformer[12]结构的启发,本研究在输入层和卷积层之间额外加入注意力层,运用多头自注意力机制来更好地表示目标和句子的特征,通过使用缩放点积操作(scaled dot product attention,SDA)计算句子中上下文单词的权重,得出每个单词的注意力分数,如式(2)~(4)所示。
(2)
Q,K,V=fx(X),
(3)
(4)
其中:X为输入层的词嵌入矩阵;Q、K、V分别表示Query、Key、Value由X乘以权重矩阵Wq∈Rdw×dq、Wk∈Rdw×dk、Wv∈Rdw×dv;dq、dk、dv表示权重矩阵的维度,均为dw/h;h为注意力头的个数。
将所有头学习到的注意力表示拼接后进行矩阵转换,多头自注意力(multi-head self-attention,MHSA)矩阵
Xatt=MHSA(X)=tanh(H1:…:Hh}·W)。
(5)
其中:Xatt∈Rn×dw表示经过注意力层后的词向量矩阵;H1,…,Hh表示h个头学习到的注意力表示;“:”表示所有向量拼接;W∈Rhdq×dw表示多头注意力的权重矩阵;tanh(·)为非线性函数,作为激活函数加入,以增强网络学习能力。
1.4 卷积层
本研究使用卷积层的窗口卷积来提取句子中的局部特征。窗口卷积使用单词本身和上下文大小为窗口来进行卷积操作,在超出边界的句首或者句尾位置利用padding操作补齐,对上层得到的多头自注意力矩阵Xatt进行卷积运算[13],如式(6)所示。
ci=conv(w·xi+b),
(6)
其中:ci∈Rdc为第i个卷积核运算得出的结果;dc为模型结构超参数,表示卷积层的输出维度;conv(·)表示卷积运算;w为卷积核权重;xi表示多头自注意力矩阵Xatt的第i个向量,0≤i≤n;b为偏置向量。
1.5 门控层
门控层由带有目标嵌入的门控单元[14](gated tanh-relu unit,GTRU)组成,每个门控单元与两个卷积神经节点连接,其输入为卷积层的输出和特定目标特征向量,如式(7)~(9)所示。
gi=si×αi,
(7)
αi=relu(Wα·ci+Vα·vα+bα),
(8)
si=tanh(Ws·ci+bs)。
(9)
其中:vα表示经过卷积操作后的目标特征向量,Vα表示目标特征向量的权重矩阵,向量αi的元素∈(0,1)表示经过relu门后接收的目标信息比例,Ws、Wα分别表示tanh门和relu门的权重矩阵,bs、bα分别表示tanh门和relu门的偏置向量,αi、si、gi与ci的大小一致,0≤i≤n。
1.6 输出层
输出层包含平均池化层和分类器,门控层得到的向量ci按顺序拼接为矩阵C,先经过平均池化操作得出主要特征向量r,降低模型的参数和运行时间,再经过Softmax分类器得到特定目标的情感极性。
r=Avg{C},
(10)
y=Softmax(W·r+b)。
(11)
其中:Avg函数表示平均池化操作;Softmax输出最终特征,得到不同类别的概率;y为一个3维的向量,分别表示3个类别的概率。
1.7 模型训练
为了预测目标极性,需要在预测前对模型进行训练。使用交叉熵和L2正则化作为模型的损失函数,使用梯度下降法来最小化损失函数
(12)
PE-MAGCN模型的训练过程如算法1所示。输入包括使用Glove得到的文本嵌入矩阵X和目标嵌入矩阵T,使用建模方法得到的位置嵌入矩阵L。首先,使用(0,1)范围内的随机数对模型中的权重矩阵进行初始化(第1行),设置模型超参数和划分数据集。然后,多次迭代学习直到模型拟合(第2~7行)。具体是使用前向传播计算模型的损失函数,依据梯度下降法更新模型中的权重变量。最后,输出测试集的结果。

算法1 PE-MAGCN模型的训练算法Input:文本嵌入矩阵X,目标嵌入矩阵T,位置嵌入矩阵LOutput:测试数据集结果1) 随机初始化模型参数,设置超参数,划分数据集;2) while i <= epoch do:3) 使用公式(2)~(11)计算输出值ypre;4) err←ypre-y;5) 计算神经元总误差loss;6) if loss≤delta:break;7) 计算梯度误差,使用梯度下降算法反向更新参数;8)end while9)输出测试集结果;10) 计算准确率和F1值。
模型训练主要的计算成本是前向传播,评估模型的函数和计算梯度误差,使用梯度下降算法更新参数。句子、特定目标以及目标情感极性为一条数据,在前向传播过程中,一条数据分别经过输入层、多头注意力层、卷积层、门控层,最终达到输出层,时间复杂度为O(1),语料中共有N条数据,故前向传播的时间复杂度为O(N)。评估模型loss函数需要用到所有的样本标签和预测标签,时间复杂度为O(N)。计算梯度误差是对网络中的参数求梯度,然后使用梯度下降法更新参数,时间复杂度为O(N)。因此,模型训练一次迭代的时间复杂度为O(N)。
本模型针对RNN存在的问题,采用了卷积网络结构获取文本局部特征,引入多头注意力机制对文本嵌入特征进行处理,增强网络特征表达能力;增加位置嵌入矩阵,考虑了文本和目标的相对位置信息,通过对位置建模和训练,反映不同单词对目标实体的贡献程度,在卷积网络层后加入门控层,控制信息在网络中的传递,获取与目标实体更相关的特征。
2 实验与结果分析
为了验证本模型的文本情感分类性能,在2个不同领域的数据集上进行实验,并与8个模型进行对比。实验环境:操作系统为Windows 10 64位,处理器为AMD Ryzen5 2600,内存16 GB,显存为GTX2060 6 GB,开发语言是Python 3.6,采用的深度学习框架为Pytorch 1.50。
2.1 实验数据集
选取英文SemEval 2014数据集(http:∥alt. qcri. org/semeval2014/),数据集包括restaurant领域和laptop领域的评论数据。每个评论样本分为positive、neural和negative 3类情感倾向。数据集的统计情况如表1所示。

表1 SemEval 2014数据集
2.2 实验参数设置
使用多种窗口卷积核对输入矩阵进行卷积操作,训练过程中使用Adadelta[15]更新规则,其他参数如表2所示。
2.3 对比实验
为了验证本模型性能,在上述数据集上设置多个基准模型进行对比实验,具体基准模型如下。
1) 目标依赖的长短期记忆网络[7](TD-LSTM):利用两层目标依赖的LSTM来预测情感极性。
2) 带有目标嵌入的注意力长短期记忆网络[8](AEAT-LSTM):使用LSTM模型来获取全文序列信息,融合了注意力机制和实体嵌入,通过学习上下文和目标之间的信息来提高分类效果。
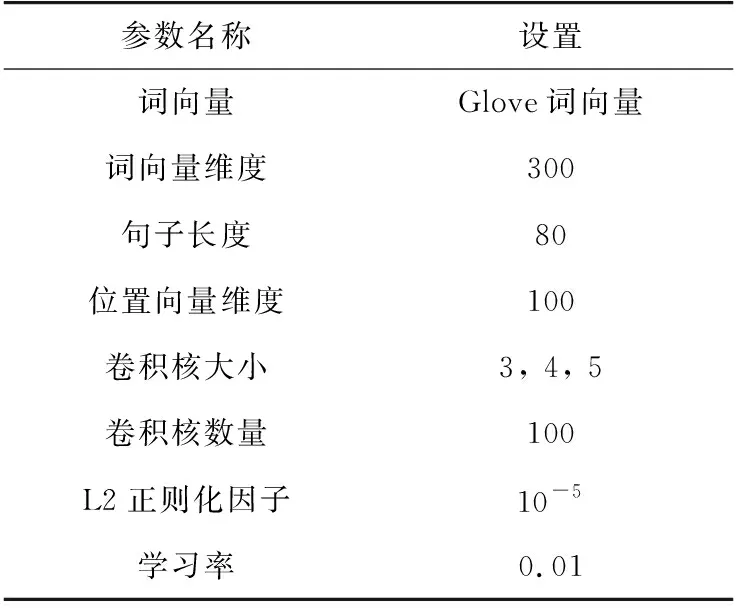
表2 实验参数设置
3) 文本卷积神经网络(text comvolutional neural network,TextCNN):Kim等[5]提出的一种针对NLP任务的卷积神经网络模型。
4) 带有目标嵌入的门控卷积网络[14](gated convolutional network with aspect embedding,GCAE):通过卷积层构建目标和情感信息,并且使用门控单元控制信息的传递,经过最大池化层后预测情感极性。
5) 交互注意力网络[16](interactive attention network,IAN):利用注意力机制对实体和上下文之间关系进行建模,关注目标和上下文之间的表示,融合后再作为最终表示。
6) 记忆网络[17](memory network,MemNet):包含多层权重共享的计算层,每层包含一个注意力层和全连接层,通过多层计算后输出到分类层。
7) 注意力编码网络(attention encoder network,AEN):利用注意力机制来对上下文和特定目标进行编码,放弃循环神经网络模型结构来提取句子特征,交互式学习上下文和目标的表示。
8) 包含句法依存信息的记忆网络[18](MenNet with syntactic dependency information,MNSI):在原始MemNet的基础上,利用卷积神经网络和多头注意力机制融合句法依存信息。
2.4 实验结果及分析
为了验证模型的性能,本模型与其他基准模型在相同环境下运行,各个模型的准确率和F1值的结果如表3所示。

表3 各个模型的准确率和F1值对比
从表3看出,与基准模型相比,本研究模型在两个数据集中有一定效果的提升。从模型的类型来看,使用循环神经网络的模型效果并不够理想,效果最差的模型是TD-LSTM模型,原因在于TD-LSTM模型只是简单地处理目标词,无法准确地识别文本信息的特征,因此模型的准确率和F1值较低。ATAE-LSTM模型在循环神经网络后加入注意力机制和目标实体嵌入信息,在效果上优于TD-LSTM模型。基于LSTM的两个模型结构效果都不理想,原因在于虽然LSTM网络能够得到文本的序列信息,但是容易丢失信息,忽略目标与上下文之间的相关性信息。
由于CNN可以获取文本的局部信息特征,准确率和F1值好于基础的TD-LSTM模型。然而Text-CNN模型表现却不好,因为TextCNN模型不是专门针对特定目标的模型,没有融合目标信息,导致输出的特征多为文本本身的特征,而并非目标相关的特征。GCAE模型由于存在门控机制,可以控制信息的传递,并且将目标嵌入到网络模型中,增强了模型的信息获取能力,表现优于TextCNN模型,且比循环神经网络结构模型的效果好,说明门控机制的存在能够一定程度改善目标特征选择的问题。MNSI模型利用图卷积结构,在训练中通过节点的距离改变节点状态,控制层与层之间的信息传递,增加了句法依存分析树,转换句子句法依存信息,消除目标词多义产生的错误结果,结果上优于TextCNN和GCAE模型。
在注意力机制的模型中,IAN模型表现一般,在获取目标词与上下文单词之间关系时,只是简单地交互学习注意力信息。MenNet模型通过多个计算层获取语义信息得到最后的文本表示,而且文本表示本质上为文本嵌入的非线性表示,模型效果优于IAN模型。AEN模型在三个注意力机制模型中表现最优,说明多头注意力交互的有效性,避免了网络递归计算,但整体性能相对于本研究模型还存在一定差距。
2.5 消融实验分析
为了进一步分析模型各部分对性能的影响程度,使用Laptop数据集进行消融实验,各个模型的参数值相同,结果如表4所示。

表4 消融实验结果
表4给出的实验结果中,从acc和F1值两个指标可以看到,消融后的模型在准确率和F1值两方面效果均不如提出的模型,表明模型改善的部分在提高分类性能发挥着积极的作用。通过对比无门控机制模型(PE-MACN)和本研究模型(PE-MAGCN)结果,能够发现存在门控机制的模型准确率提高了0.37%,F1值提高了0.9%,表明门控机制在控制信息传递方面发挥出积极作用。通过与无位置嵌入信息模型(MAGCN)对比,PE-MAGCN在Laptop数据集上的准确率和F1值分别提升了0.24%和0.97%,表明位置嵌入信息能够反映目标和文本的相对位置,在训练过程中一定程度反映局部特征对目标的贡献程度。从表中可以看出,不添加注意力层的模型(PE-GCN)准确率和F1值均小于无门控机制的模型和无位置嵌入信息的模型,本研究模型(PE-MAGCN)与之相比,准确率提高了1.68%,F1值提高了1.3%,提高幅度最大,表明注意力机制能够有效增强模型的特征表达能力。
2.6 模型复杂性分析
为了测试本研究模型与其他模型的复杂性,在Laptop数据集进行实验,迭代次数设置为20,学习率为0.01,batchsize设置为64,记录每次epoch所需时间、模型达到收敛所消耗的时间以及模型的参数数量。实验结果如表5所示。
由表5可以看出,PE-MAGCN模型的可训练参数数量为1.08×106个,少于由多层全连接层和注意力层构成的MemNet模型和MNSI模型,这是由于模型结构较为复杂,导致模型偏大。在迭代一次所需时间方面,模型要优于ATAE-LSTM、MNSI、MenNet和IAN模型,次于TD-LSTM、TextCNN、GCAE、AEN。虽然上述模型的时间复杂度均为O(N),但是由于模型内部的结构不同,实例消耗的时间也不同。
与注意力网络MemNet和IAN模型相比,收敛时间降低了44.38和58.5 s,因为模型摒弃了循环网络结构,模型训练时不会因为计算目标与上下文之间的注意力矩阵消耗较多时间。与循环网络相比,参数数量高于TD-LSTM和ATAE-LSTM模型,迭代一次所消耗的时间为3.7 s,高于TD-LSTM迭代一次所需时间,原因在于TD-LSTM模型的结构较为简单,训练一次所计算的参数较少。ATAE-LSTM模型在LSTM模型上加入全局注意力层,获得隐藏层特征后再进行注意力矩阵计算,消耗较多时间。而PE-MAGCN模型不使用LSTM结构获取特征,使用卷积单元获取句子局部特征,因此时间少于ATAE-LSTM模型。与TextCNN、GCAE模型相比,PE-MAGCN模型的迭代一次所需时间分别增加了0.7和0.44 s,收敛时间增加了2.69和6.76 s,说明加入多头注意力层会增加训练时间,但与提高的分类准确率相比,增加的时间代价可以接受。与MemNet、IAN模型相比,PE-MAGCN模型迭代一次的时间分别降低了3.74和5.58 s,收敛
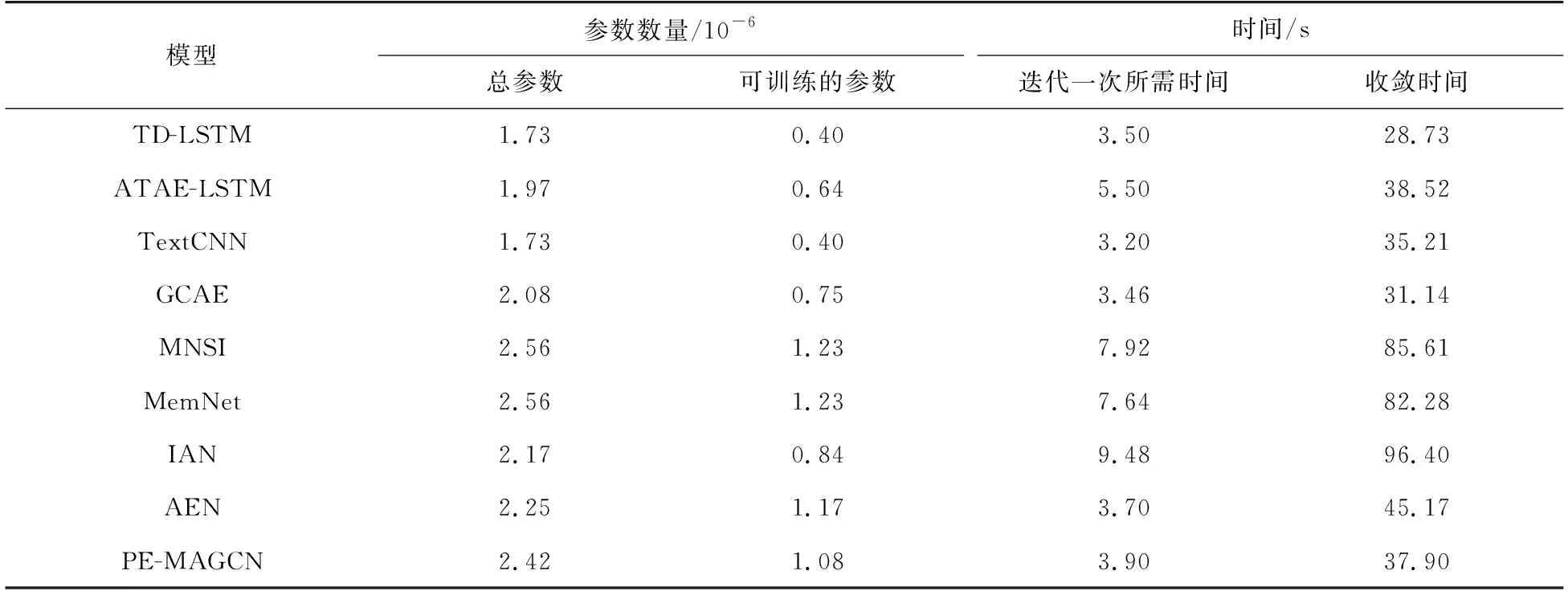
表5 模型参数数量和模型训练时间对比
时间分别降低了44.38和58.5 s,说明交互式注意力机制和LSTM模型的结构会消耗较多的时间,时间复杂性较高。与AEN模型相比,PE-MAGCN模型迭代时间增加了0.2 s,收敛时间降低了7.27 s,这是因为AEN模型使用注意编码层替代了LSTM层,获取输入嵌入的隐藏状态;使用点卷积获取目标语义相关,与本研究模型结构相似,因此时间代价相差不大。与MNSI模型相比,PE-MAGCN模型的迭代时间降低了4.02 s,收敛时间降低了47.71 s,这是由于MNSI模型是在MenNet模型的基础上又引入了句法依存关系并使用spacy工具包将句子转换为句法依存树。虽然转换句法依存树的时间复杂度也为O(N),但是仍然消耗额外的转换时间,在所有的对比模型中训练消耗的时间最高。PE-MAGCN模型使用多头注意力机制获取特征表达,利用门控卷积层控制信息的传递,能够有效地表示目标相关特征,收敛速度较快,获得了较高的准确率。
3 总结
针对循环神经网络在获取句子特征时,容易造成信息丢失和较长的训练时间,以及传统卷积神经网络不能很好获取上下文信息的问题,提出一种带有位置嵌入的多头注意力门控卷积网络,完成特定目标情感识别任务。本研究模型首先利用多头注意力层获取目标和文本词之间的语义交互信息,通过卷积神经网络结构获取文本局部特征,利用门控机制控制信息传递,将与目标相关的信息输入到分类层。另外,为了获取不同词与目标特征之间的距离信息,模型额外加入位置嵌入矩阵,增加了模型的信息获取能力。通过对SemEval 2014数据集进行实验,验证了模型的有效性和实用性,准确率和F1值在两个数据集上都有提高。与其他基准模型比较发现,本模型相较于循环网络和注意力机制网络,具有较快的收敛速度,可为特定目标情感分析提供新的模型,但仍存在一些不足,如实验所用的数据集规模有限且模型参数数量较多,一定程度增加了模型的训练时间。后续将研究如何将现有的额外知识融入到神经网络中,在精简网络模型结构的同时增强模型的情感分析结果。
