基于机器学习算法的天祝藏族自治县草地地上生物量反演
2022-04-15秦格霞吴静李纯斌吉珍霞邱政超李颖
秦格霞,吴静*,李纯斌,吉珍霞,邱政超,李颖
(1.甘肃农业大学资源与环境学院,甘肃 兰州 730070;2.中国科学院南京土壤研究所,江苏 南京 210008)
天然草原和热带稀疏草原是陆地生态系统中高度复杂的生物群系[1],占地球陆地面积40%,在物种组成、密度、生物量上随空间和时间变化很大[1-3],对不同气候和天气条件等较为敏感[4]。近来,由于气候变化和不断增长的人类压力,草原退化成为中国面临的一个严重生态问题[5-8]。草地地上生物量(above-ground biomass,AGB)作为表征植被活动、评价生态再生能力、反映草原生态系统健康状况和草地资源可持续利用状况的关键指标[9-12],在合理开发草地资源、发展畜牧业、维持生物多样性和维护生态系统平衡上具有重要作用[10,13]。动态获取大面积长时序草地AGB不仅可以评估草地生产力、草地生态效益和植被生长状况,而且可以为荒漠化地区生态修复研究和荒漠生态系统可持续发展提供参考[14-18]。
传统获取草地AGB是通过野外实测直接获取(如齐地刈割法、循环采样法),但费时费力,很难获取长时序大面积的草地AGB[19-20]。随着遥感技术的发展,不同时空分辨率的卫星数据成为大尺度草地监测的理想选择[21]。20世纪60年代,有学者利用遥感影像和实测草地AGB估算大范围草地AGB,通过整合多因素和学习高度复杂的非线性映射,获得了更好的仿真结果[22-26]。这类方法被越来越多的学者用于草地AGB的反演研究,但有研究发现归一化植被指数(normalized difference vegetative index,NDVI)-AGB模型虽可以解释近57%的草地生物量变化,但这些模型多数为回归模型,其精度往往受到草地AGB对植被指数的敏感性和外部环境的影响,且大多基于单一的植被指数,不能更加全面的考虑草地AGB的气象、地形等影响因子。在过去20年里,机器学习技术已开始应用于生物量反演研究,与传统回归模型相比,可以充分考虑草地生物量的影响因素(气候、自然因素等)。已有研究发现人工神经网络(artificial neural network,ANN)反演的草地AGB优于传统回归模型[27-29]。支持向量机(support vector machine,SVR)模拟的草地AGB精度优于ANN和传统回归模型[30];随机森林(random forest,RF)作为非参数集成建模方法,因具有减少偏置和过拟合的能力[28,31-32],对异常值和噪音更有容忍度,在遥感反演研究领域获得了较高精度。高度稳健和更高精度的梯度提升回归树(gradient boosting regression tree,GBRT)和深度神经网络(deep neural network,DNN)算法在许多领域兴起,但目前在草地AGB遥感反演研究中尚未运用。传统机器学习算法在反演精度上虽高于回归模型,但其均属浅层机器学习,存在局部最优、过拟合和梯度扩散等问题[33]。深度学习算法是在机器学习算法基础上通过设定深层次非线性结构实现对高度复杂数据建模算法的综合,比浅层机器学习算法更有优势[34]。机器学习算法凭借其优越性、高效性、稳健和精确性虽已被广泛应用于各个研究领域,但不同机器学习算法在训练样本要求、超参数设置和算法计算效率等方面存在较大差异。因此,综合评价不同机器学习算法及目前新出现的机器学习算法模拟精度、模型性能及适用情况对推动机器学习在遥感反演领域的应用极为重要。
天祝藏族自治县作为甘肃省的草原畜牧业大县,因处于石羊河流域和黄河流域重要水源涵养区和水源补给区,区域内的草原生态作用尤显突出。但由于天祝藏族自治县海拔高、自然条件恶劣,造成草地生态系统脆弱。在近30年气温增暖和增湿变化加剧的背景下,天祝藏族自治县草地AGB的实时、高精度监测受到越来越多的关注。
故此,研究基于天祝藏族自治县地面实测草地AGB并综合考虑地形、气象、植被覆盖情况等因素,比较不同机器学习算法[RF、SVR、ANN、高斯过程回归(gaussian process regression,GPR)、GBRT、DNN]在反演天祝藏族自治县草地AGB的精度、稳定性及其对训练样本的敏感性,并使用最优模型反演得到2020年生长季内草地AGB,以期评价各个机器学习算法模型在草地AGB遥感反演的应用潜力,从而为草地AGB最优反演模型的选择提供支持。
1 材料与方法
1.1 研究区概况
天祝藏族自治县(36°31′-37°55′N,102°07′-103°46′E)地处甘肃省中部,祁连山东端,是青藏、内蒙古、黄土3大高原交汇地带的一部分,西北部与祁连山主干相连,东北部靠近腾格里沙漠边缘,东南部没入黄土高原。境内草地覆盖面积约为3.914×103km2,草产量较低,70%以上的国土面积分布在海拔3000 m以上的区域。气候以乌鞘岭为界,岭南属大陆性高原季风气候,岭北属温带大陆性半干旱气候。年均温介于-8~4℃,垂直分布明显,常有干旱、冰雹、洪涝、霜冻等自然灾害发生,年日照时数达4434 h以上。降水量一般多在200~600 mm,主要集中在7、8月,春冬季节旱情严重,夏秋多暴雨,多大风天气。主要草地类型有温性草原、山地草甸、高寒草甸、灌丛草甸和疏林草甸,其中山地草甸生产力最高[13,16,35]。因境内地形复杂、气候持续干旱和超载过牧,草原生产能力下降、鼠害泛滥、水源锐减和草地沙化等生态问题表现较为严重(图1)[13,16,36]。

图1 天祝藏族自治县草地类型及野外实测点分布Fig.1 Spatial distribution of grassland types and field sites in Tianzhu Zangzu Autonomous County
1.2 数据来源
1.2.1实测草地AGB数据 根据天祝藏族自治县草地类型分布特点、草地利用方式、利用强度、管理制度和LANDSAT数据分辨率等方面的综合评估,于2020年6、7、8月下旬在不同类型、不同盖度,且地势平坦、草地优势草种比较单一、空间分布均匀、面积大于100 m×100 m的草地试验样区内进行野外数据采集(图2)。实测时使用GPS记录样地经纬度,并详细记录实测点海拔、地形、优势种、株高、植被覆盖度、坡度、坡向。草地AGB采用收获法将样方内草地所有绿色部分用羊毛剪齐地面剪下,称其鲜重,后在实验室内置于105℃温度下杀青,65℃烘至恒重,获得每个1 m×1 m样方的草干重,最后用5个样方的平均值作为10 m×10 m样方的草地AGB。

图2 样方分布及野外实测场景照片Fig.2 Photos of plot distr ibution and field measur ement
通过统计6月下旬、7月下旬、8月下旬不同草地类型的草地生物量可以发现,不同草地类型的干重数值上差异较大。温性荒漠草原从6-8月一致较低,集中分布在30~50 g·m-2;其次为温性草原,干重集中在40~150 g·m-2,草干重最重的为山地草甸,基本集中150~450 g·m-2;高寒草甸的数值分布因地形差异较大,数值集中在100~200 g·m-2(图3)。

图3 实测草地AGB数据分布Fig.3 Map of the measured data
1.2.2遥感数据 遥感数据使用Google Earth Engine(GEE)平台提供30 m空间分辨率的Landsat 8地表反射率产品(LANDSAT/LC08/C01/T 1_SR)。B1~B7波段(B1-Coastal/Aerosol;B2-Blue;B3-Green;B4-Red;B5-NIR;B6-SWIR1;B7-SWIR2)已经过了辐射定标、大气校正等预处理,包括使用Function of Mas生成的云、阴影、水和雪以及每个像素的饱和度掩膜。选择与实测数据同期的2020年的6月23日-7月1日、7月25日-8月3日、8月26日-9月7日云量小于10且代表植被最好生长状态的地表反射率数据,利用最大值合成对应时间段NDVI、EVI(enhanced vegetation index)。NDVI、EVI计算公式为:

式中:NIR为LANDSAT-8数据对应的近红外波段;R为红光波段;B为蓝光波段。
1.2.3DEM数据 DEM数据源于地理空间数据云(http://www.gscloud.cn/sources/accessdata/310?pid=302)的SRTM产品数据,分辨率为30 m。坡度、坡向均使用ARCGIS提供的工具计算获得。
1.2.4气象数据 从中国气象数据网站(http://data.cma.cn/data/cdcdetail/dataCode)获取气象数据日数据集,在剔除数据缺失的站点后,选取研究区内及周围12个气象站点的温度、降水和相对湿度数据。时间分别为2020年的6月23日-7月1日、7月25日-8月3日、8月26日-9月7日(图1)。基于样条函数插值理论的专业气象插值软件ANUSPLINE,以DEM数据为协变量,对气温和降水数据进行空间插值,获得研究区30 m的栅格数据。
1.2.5草地类型数据 草地类型数据采用《中国1∶100万草地资源图》。该类型图的编制过程:首先,对全国草地分布区的2000多个县内的野外实地调查数据进行编制。其次,辅以航、卫片编制了县级1∶5万或1∶10万草地类型图、草地等级图、草地利用现状图。最终,按照国家统一编制规范和制图综合原则,编制成国家级1∶100万草地资源图[36]。
1.3 研究方法
1.3.1机器学习算法 1)人工神经网络(ANN)是根据不同的技术来学习连接权值,通过反向传播过程将错误从输出层传播到输入层来反向调整权值,使模型能够沿着误差最小的梯度进行,从而达到全局最优[37]。神经元数量为10,激活函数为Relu,L 2惩罚系数为0.0001,学习率为constant,最大迭代次数为560,梯度下降方法为Adamx。
2)深度神经网络(DNN)是一个含有多层网络结构的模型,学习过程是通过从低到高逐层映射到新特征空间,具有层次化和分布式抽象的特点[37]。DNN网络以对草地AGB影响较大的Landsat 8数据的B1~B7的反射率数据、坡向(aspect)、坡度(slope)、DEM、NDVI、EVI、平均气温(mean temperature,TEM)和平均降水(mean precipitation,PRE)作为DNN输入层,经过4个隐藏层后得到反演结果。损失函数为均方误差(MSE),隐藏层的激活函数选择Relu,使用Dropout防止过拟合,优化函数选择Adam,学习率为0.006。
3)随机森林算法(RF)是一种基于分类回归树的机器学习方法,相比其他传统统计模型具有更高的准确性和更低的均方根误差,无需特征选择即可处理高维数据,具有良好的抗噪能力和稳定的性能,可在一定程度上避免过拟合[38]。RF决策树个数为600,最大树深为5,内部节点再划分所需最小样本数为2,叶子节点所需最小样本数为2。
4)梯度提升回归树(GBRT)是通过优化传统决策树算法的损失函数,对弱监督学习(决策树)进行预测,可以添加新的决策树来最小化损失函数以提高模拟精度[39]。GBRT损失函数为Squared_loss,学习率为0.005,弱学习器数目为800,学习器最大深度5,叶子节点所需最小样本数2。
5)支持向量机(SVR)是一种基于统计学习理论的监督学习技术,根据结构风险最小化标准,并采用二次规划的方式得到问题最优解[40]。SVR惩罚系数C为128,gamma为0.09,核函数为复杂度较小的RBF核函数。
6)高斯过程回归(GPR)通过核(协方差)函数提供预测,与SVR相似,GPR通过应用高度灵活的核函数将输入数据投影到高维空间来解决复杂的非线性问题[41]。GPR的alpha为0.01,n_restarts_optimizer为10。
算法均使用10重交叉验证、网格搜索和学习曲线对模型超参数调优和防止过拟合。
1.3.2模型精度评价 利用验证样本通过使用草地AGB实测值与预测值之间的均方根误差(RMSE)、平均绝对误差(MAE)和决定系数(R2)评价模型模拟精度[42]。

式中:AGBfid、AGBsim分别为实测草地AGB与模拟的草地AGB;N为实测草地AGB个数;是实测AGB的平均值。R2值越高,RMSE、MAE值越低,模型模拟精度越高。
2 结果与分析
2.1 变量优选
为提高模型模拟精度,将Landsat 8数据的B1~B7反射率数据、aspect、slope、DEM、NDVI、EVI、TEM和PRE自变量,与草地AGB实测数据进行相关性分析(图4)。结果表明:AGB与B6、B7、NDVI、EVI、TEM、PRE、aspect呈显著正相关。NDVI、EVI与AGB相关性较高(R2=0.61、0.64),与B1~B5、DEM呈显著负相关,与slope呈不显著负相关。坡度与其他几个待选自变量的相关性均不显著(图4)。因此,选择B1~B7反射率数据、NDVI、EVI、TEM、PRE、aspect和DEM作为机器学习模型输入变量,AGB作为模型输出变量。

图4 AGB与待选自变量相关系数Fig.4 Correlation coefficients between the AGB and the explanatory variables
2.2 算法精度对比分析
为避免训练数据和测试数据随机划分时造成的误差,对每种模型进行30次随机重复试验(训练数据51、测试数据13)。统计每种模型30次重复试验的R2、RMSE、MAE发现(图5和表1)DNN模拟精度及稳定性均较好;GBRT、RF模拟精度和稳定性表现较为一致,精度较高,稳定性差;GPR次于GBRT、RF,稳定性较高;SVR和ANN精度相对其他模型较差,但SVR稳定性较高,ANN稳定性较差。总体来看,几种模型的精度都较好,得到了较为满意的结果,机器学习模型在草地AGB遥感反演领域具有较大的应用潜力。

图5 30次重复试验中模型精度箱型图Fig.5 The boxplot of model accuracy in the 30 repeated experiments

表1 重复30次的R2、RMSE、MAE的统计Table 1 Statistical table of R2,RMSE and MAE r epeated 30 times
2.3 训练样本敏感性分析
为进一步评价不同机器学习模型对训练样本大小的敏感性及稳定性,以5为间隔,设定不同训练样本数量,对 模 型 均 进 行30次 随 机 重 复 试 验,记 录R2、RMSE、MAE,通 过30次 重 复 试 验 的 标 准 误(SD xˉ,SD xˉ=标准差评价模型稳定性(标准误用填充区域表示,填充区域越小,表示标准误越小,模型稳定性越强)。结果发现:6种模型精度均随样本数增加而增加,标准误在一定程度减小,模型稳定性增强。其中,DNN精度随样本数增加持续增加,增加幅度为6种模型中最大的一个。ANN列居第二,样本数<31,对样本的敏感性最强;样本数>31,随样本数的变化精度和稳定性变化较小。GBRT、RF对样本数的敏感性次于ANN,样本数达到26之后,对样本数敏感性降低。SVR、GPR精度随样本数增加,精度增加较为缓慢,但SVR标准误在样本数较大时,比其他5种模型大(图6)。

图6 机器学习模型对于训练样本大小的敏感性Fig.6 Sensitivity of the machine learning models to the training sample size
DNN、ANN对训练样本数最为敏感,RF、GBRT对训练样本数敏感性表现较为一致,次于DNN、ANN,SVR对样本数的敏感性较小,GPR最末。
2.4 综合评价
为综合评价6种机器学习模型在草地AGB遥感反演领域的适用性,设定模型训练30次的平均R2(M1)、RMSE(M2)、MAE(M3)及模型对训练样本大小敏感性重复30次的平均R2(M4)、RMSE(M5)、MAE(M6)综合评价比较不同模型的适应度。首先对评价指标采用最大最小值归一化方法对指标归一化,设定M1、M4为正指标,M2、M3、M5、M6为 负 指 标。结 果 表 明:DNN模 型 的 综 合 性 能 最 好,性 能GPR>ANN>GBRT>RF>SVR(图7)。

图7 使用雷达图从不同角度综合对比6种机器学习模型的表现Fig.7 Comprehensive comparison of six machine learning models with different metrics using a radar chart
2.5 草地AGB时空变化
采用性能最好的DNN作为反演天祝藏族自治县草地AGB反演模型,得到2020年天祝藏族自治县生长季(4-9月)草地AGB空间分布图。结果表明:不同月份草地AGB空间异质性较大,呈明显地带性分布,从西北向东南呈下降趋势。其中,草地AGB最低值区域主要集中在高山草甸类植被较为稀少的冷龙岭区域和荒漠草原南部区域。最高值主要分布在山地草甸分布区域和温性荒漠草原南部区域。
从不同月份来看,盛草期AGB集中在50~250 g·m-2,从5月开始上升,7月达到峰值,8月开始呈下降趋势。其中,温性草原和温性荒漠草原在4月的草地AGB高于其他2种草地类,介于50~70 g·m-2,且两种类型草地AGB均在5月达到最大(AGB>100 g·m-2)。不同的是,温性荒漠草原AGB在6月开始下降,温性草原AGB有较长生长期,一直延迟到9月才开始下降。高寒草甸和山地草甸4月AGB较低,基本小于70 g·m-2,5月开始上升,7月达到最高(AGB>150 g·m-2),9月开始下降(图8)。

图8 草地AGB空间分布Fig.8 Spatial distribution of AGB in grassland
通过分析草地AGB对气温、降水的响应机制。结果表明,除温性荒漠草原类之外,其他3种草地类型的变化与气温有较好的一致性,表现出较为明显的正相关关系(图9)。降水量对高寒草甸、温性草原和山地草甸的走势保持一致,但影响不是很明显。降水量对温性荒漠草原类的影响较大,随降水量减少,AGB出现一定程度的减少。
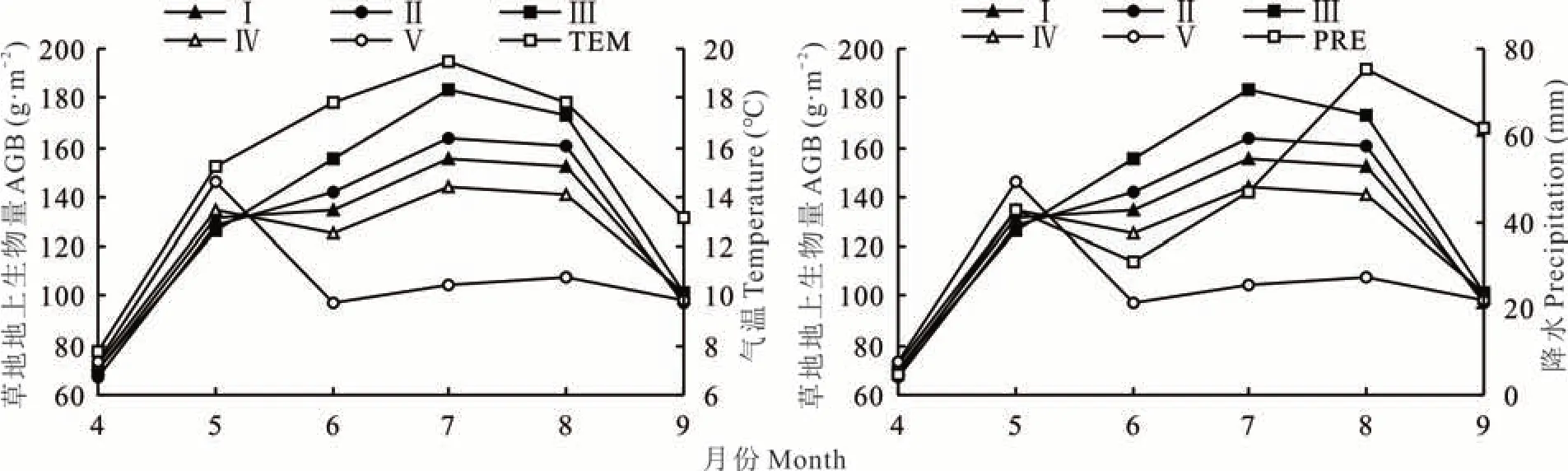
图9 各种草地类型AGB对气温和降水的响应机制Fig.9 Response mechanism of AGB in different grassland types to temperature and precipitation
3 讨论
机器学习方法不依赖于固定的模型框架,通过不断的“学习”模型校正过程中反馈误差,提高了模拟自变量与隐因变量之间的精度。以往研究证明机器学习模型能较好地保证模型的稳定性和可靠性,是目前解决非线性回归问题的有效方法,但机器学习模型是基于大样本数据建立的,在基于实测数据的遥感反演的过程中,很难获得成千上万的实测数据。近年来,诸多研究学者应用机器学习算法(GPR、ANN、SVR、RF)反演草地AGB,发现机器学习模型在解决小样本数据时也具有一定优势[28-30],且与草地AGB反演的参数化方法相比,机器学习算法通常具有更好的预测性能[24-30]。现阶段基于不同原理发展起来了许多种机器学习算法,这对模型的选择(训练样本数量、模型精度、模型的稳定性等)提出了巨大挑战。
通过综合对比不同机器学习算法使用小样本数据反演草地生物量的性能发现,6种机器学习算法在草地AGB反演中表现较好,具有较大的应用潜力。但从预测结果和实测值的比较可以发现,不同的机器学习模型对计算效率、稳定性和对样本数量的要求有异。DNN作为在机器学习基础上发展起来的深度学习算法中的一种,在草地AGB反演方面的性能较好,对样本数量的敏感性较大,随着样本数量增加,模型精度增加较大,当样本数大于某一个数时,模型精度明显高于其他几种传统的机器学习模型,但该模型具有较深层次的网络结构,学习过程较慢。GBRT作为在决策树基础上兴起的模型,在计算精度上优于RF,但该模型的稳定性与RF表现相近,稳定性较低。GBRT、RF精度较高,但稳定性较差,主要原因是这两者模型的超参数较多,超参数的较小变化就会导致模型精度的变化。ANN作为最早使用在遥感反演领域的传统机器学习模型,模拟精度较低,稳定性较差,过多的依赖于参数的设置。SVR精度最低,但稳定性很强,对样本数的敏感性较弱。GPR各方面表现较为良好,表现性能仅次于DNN模型。从原理角度分析,SVR通过寻求结构化风险最小的方式寻求最优预测结果,即以控制整体误差为目标校正模型;ANN是以不断的拟合局部真值为训练目标,因此得到的可能是局部最优解,这样会导致模型预测时泛化能力较差;GBRT和RF基于决策树,当训练样本的内部机构越混乱,模型的不确定性就越大,错误率也会相应增加。
作为最新发展起来的DNN、GBRT未曾应用于草地AGB反演的研究中,故无法将这两种机器学习模型的结果与其他的研究进行对比分析。有限的试验数据导致所建立的模型存在时空局限性,若能采用分布较为均匀的大样本数据对模型进行训练,可以更加全面评估不同模型在不同地形、草地盖度等的适用性,从而可以进一步讨论不同模型使用的植被覆盖情况和使用的边界。
虽然存在一定的不足,但在评价不同模型时采用了较为全面的评价指标对模型稳定性、精度、计算效率进行了评价。与同类研究相比,考虑了更多的评价因素,更客观、综合地评价了模型在草地AGB反演研究中的应用潜力,对相关研究有一定的参考价值。
4 结论
草地AGB有效和精确估算可作为放牧经济及草地管理制度的重要依据。利用R2、RMSE、MAE及模型稳定性综合考虑了草地AGB的影响因子,评价了DNN、RF、GBRT、SVR、ANN和GPR算法在反演草地AGB的适用性及性能。结果表明:1)通过相关分析发现对天祝藏族自治县草地AGB影响较为显著的因子为Landsat 8的B1~B7反射率数据、NDVI、EVI、TEM、PRE、aspect和DEM。2)DNN在估算天祝藏族自治县草地AGB表现的性能最佳,但该模型稳定性较差,对样本数的大小较为敏感,且GPR性能>ANN>GBRT>RF>SVR。3)天祝藏族自治县草地AGB集中在50~250 g·m-2,整体表现为从西北向东南呈下降趋势。气温与山地草甸、高寒草甸和温性草原的AGB表现出较为明显的正相关关系。降水量对高寒草甸、温性草原和山地草甸的AGB影响不明显,但对温性荒漠草原类的影响较大,AGB随降水量减少呈减少态势。
