局部与全局双重特征融合的自然场景文本检测
2022-04-14李云洪闫君宏
李云洪,闫君宏,胡 蕾
(江西师范大学计算机信息工程学院,南昌 330022)
引言
文本作为人类沟通的主要媒介之一,经常出现在自然场景图像中,例如商场商标、街道路标、车牌和票据等,文本信息对理解和解析场景内容有极其重要的作用,自然场景文本识别[1]一直深受研究者关注,而准确有效的文本检测是文本识别的前提。相较于文档类文本检测,背景多文字少、遮挡、文本类似块、文体形态各异、大小排列不一、方向不同、弯曲、艺术体、镜面反光等因素导致自然场景文本检测仍然面临严峻挑战。
传统的文本检测算法多采用自底向上方式进行文本检测,大致可分为两类:基于连通区域的算法和基于滑动窗口的算法。基于连通区域的文本检测算法多从图像边缘检测开始,根据文本的低级属性(大小、颜色和形状等)形成多个连通区域,然后对连通区域进行处理、合并生成最后的文本框,较为经典的算法有Matas 等[2]提出的最大稳定极值区域(Maximally stable extremal regions,MSER)算法,Epshtein 等[3]提出的笔画宽度变换(Stroke width transform,SWT)算法。基于滑动窗口的文本检测算法最早出现在目标检测中,Zitnick[4]提出的Edge Boxes 算法,在一幅图像上形成一个特定大小窗口,从左上角开始以特定步长扫描,寻找文本出现的区域,并对区域进行评分,根据分数高低来确定候选框。传统的文本检测算法对上下文信息较为依赖,一些类似文本纹理的干扰会导致严重的误检与漏检。
近年来深度学习技术在目标检测中取得了显著成效[5],可将文本视为被检测目标。由于文本定位需覆盖整个字符区域,而场景文本没有规律的边缘界限,导致很多现有的目标检测算法在文本检测中不能直接使用,很多研究者针对场景文本检测进行了技术的迁移与改进。目前深度学习技术下文本检测算法大致可分为两类:(1)基于文本框回归的算法,使用四边形表征文本区域,在文本方向多样、长短不一等情况下,该方法存在一定局限性;(2)基于文本分割的算法,将文本与非文本进行分割,不需要考虑文本的长短与方向。典型的文本框回归算法有Tian 等[6]提出的联接文本提议网络(Connectionist text proposal network,CTPN)算法,该算法对基于区域的快速卷积神经网络(Faster region-based convolutional neural network,Faster RCNN)[7]做了改进,考虑了水平文本的长短不确定性,用碎片框进行文本区域定位,利用循环神经网络(Recurrent neural network,RNN)的语义信息,通过长短期记忆网络(Long short-term memory,LSTM)合并文本的碎片区域生成最终的文本框。Shi 等[8]提出的SegLink 算法,可以检测任意角度的文本,在CTPN 的思想上融入了单次多框检测器(Single shot multibox detector,SSD)[9]算法思路,在SSD 中引入角度因子,检测出包含方向的多个候选框,拼接属于同一个文本的候选框得到最终文本框。典型的文本分割算法有Deng 等[10]提出的Pixellink 算法,在对文本或者非文本像素进行分离预测的基础上,预测文本像素的8 个方向上是否存在连接,通过判断连通区域得到最终的文本框。Long 等[11]提出的TextSnake 算法,首先在分割结果中确定文本中心线,然后围绕中心线采用不同大小和连接角度的圆盘覆盖文本区域,从而提高不规则文本检测性能。Wang 等[12]提出的渐进多尺度扩展网络(Progressive scale expansion network,PSENet)算法,通过精确查找多个尺度的内核,对紧密相连的文本进行准确定位与检测,该方法很大程度上解决了紧密相连文本的问题。从实验结果分析,这些方法在文本区域所占比例较小或者具有不规则艺术体的场景图像中会出现严重的漏检与误检。
本文在PSENet(Resnet-50)[12]的基础上提出一种局部与全局双重特征融合的网络模型(Local and global network,LAGNet),选择ResNet-50[13]作为骨干网络,对恒等残差块进行改进,实现局部细粒度特征融合(Fine-grained locally feature fusion,FLFF);然后在特征金字塔网络(Feature pyramid networks,FPN)[14]结构中采用跳跃连接的方式,实现多尺度全局特征融合(Multi-scale global feature fusion,MGFF),从而增强特征提取的性能;最后将多边形偏移文本域与真实文本边缘信息结合,对文本进行准确定位从而实现文本的检测。
1 LAGNet 网络模型
本文提出的自然场景文本检测网络模型LAGNet 如图1 所示,采用FPN 结构的ResNet-50 作为核心网络,主要包含Layer 1~Layer 4 构成的Down-top 分支,P5~P2 构成的Top-down 分支,并在每一个Layer 层后引入Transformer,实现图片尺寸缩放与通道降维以对不同尺度大小的图片进行卷积,从而利用浅层特征区分显著文本、利用深层特征区分较小文本。在Layer 层的恒等残差块中,用多分支卷积替换单分支卷积,实现局部特征融合;将Layer 中的特征信息通过跳跃连接的方式传递并采用Add 的形式融入到P5~P2,实现全局特征融合。通过浅层与深层的特征信息全局共享,增强了网络模型对各类文本检测的鲁棒性。P5~P2 中的特征映射上采样(Upsample)到原图尺寸并输入到Conv 2,得到一个文本实例区域、一个多边形偏移文本域、一个文本边缘信息,经过后处理模块形成最终的检测结果。其中Conv_2 由Concat 与n个Conv-BN-ReLU 层和Conv-Sigmoid 层组成,Concat 指将不同卷积层的特征通道融合,Add 指在保证通道数相等的情况下将卷积结果逐元素叠加。
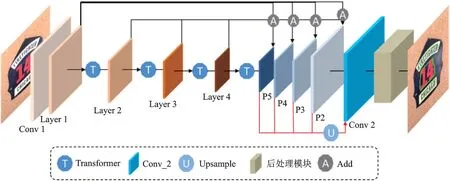
图1 LAGNet 网络模型Fig.1 LAGNet network model
2 功能模块
2.1 特征提取网络
现有经典算法在对文本区域所占比例较小的场景图像中会出现大量的漏检误检情况,本文的网络模型从特征提取模块入手,对ResNet-50 的恒等残差块进行改进,尽可能地保留底层语义信息,以提高对小文本的检测性能。
在Layer 1 的恒等残差块中引入密集残差块思想,如图2 所示,将每一层的卷积结果保留并传递给之后的每一层,并通过Add 形式进行特征融合,从而使局部特征信息通过深度级联聚合传递到整个网络,经过Transformer1 对图像尺寸与通道数进行处理并传递给Layer 2。此处采用Add 的融合形式是因为Add 的计算量比Concat 低很多。
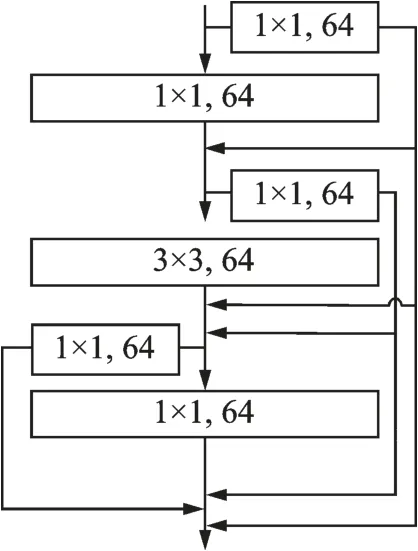
图2 Layer 1 恒等残差块结构图Fig.2 Identity residual block structure diagram of Layer 1
Layer 2 和Layer 3 的恒等残差块(图3)引入细粒度特征信息融合思想,采用分割-转换-合并的结构实现细粒度特征信息融合。具体为,将初始残差块中3×3 卷积分割成n条分支同步进行,即图3 中a1~a4(n=4),采用Add 形式对各分支卷积结果进行融合(图3 中B),将B 传递到1×1 卷积。在卷积后采用Add 形式将前两层保留的特征信息进行融合,实现细粒度的特征信息提取,不仅扩大了感受野,同时提升了卷积的表达能力。

图3 Layer 2和Layer 3恒等残差块结构图Fig.3 Identity residual block structure diagram of Layer 2 and Layer 3
Layer 4 的恒等残差块(图4)采用传统的卷积块模式,在直接映射中加入了一个1×1 卷积,对最小尺度的文本进行特征提取并堆叠。核心网络ResNet-50 经过残差块调整后构成的Down-top 分支参数如表1 所示,从表1 中可以很直观地看出输入图片的尺寸在每一阶段的变化情况以及所进行的操作。
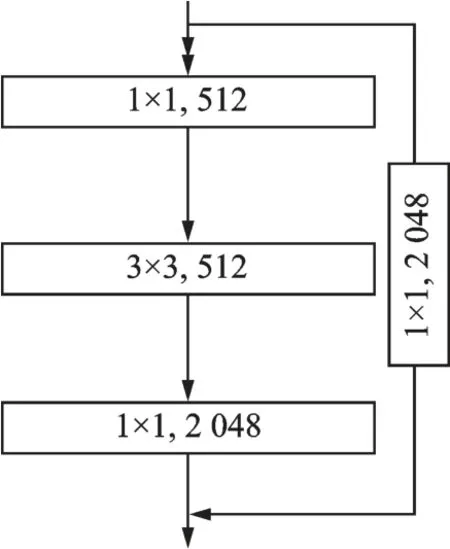
图4 Layer 4 恒等残差块结构图Fig.4 Identity residual block structure diagram of Layer 4

表1 Down-top 网络参数Table 1 Down-top network parameters
2.2 后处理模块
现有公共数据集中,不仅存在部分紧密衔接的文本图像,而且存在一些遮挡、覆盖等文本图像。最明显的是文本占有比例严重不均衡问题,有些图像中文本占有比例较大,有些图像中文本占有比例较小。如图5(a)场景中文本占有比例非常少,图5(b)图中文本占有比例相对较大。

图5 样本示例图Fig.5 Sample diagram
现有经典检测算法在进行文本定位时,偏向于图5(a,b)中某一类,为提高模型对场景图像中文本检测的泛化能力,本文采用多边形偏移文本域与文本边缘信息相结合的方式对文本进行检测与分离,从多边形偏移文本域的边缘像素向外扩张,以文本边缘信息为最大边界,清晰地分离出多个文本组件,采用多边形非极大值抑制算法[15]丢弃多余检测框,生成最终的文本检测标签。其中,多边形偏移文本域是在文本实例基础上按照一定缩放概率进行收缩,得到一个完全由本文像素组成的文本区域;文本边缘信息是文本实例区域的边界信息,图6 给出了示例图。

图6 文本区域示例图Fig.6 Example text area diagram
为计算多边形偏移文本域,本文采用Vatti 裁剪算法[16]将初始文本图像进行裁剪,裁剪比例di为

式中:Area()为面积函数,T为多边形文本实例,ri为第i个文本偏移域的缩放因子,Perimeter()为周长函数。
缩放因子ri的计算过程为
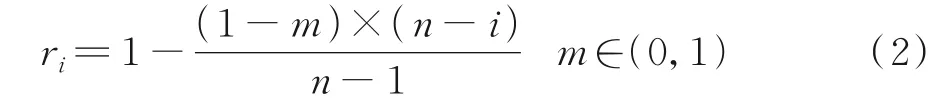
式中:m为超参数最小缩放比例;n为获取多边形文本偏移域的数量,本文中n=2。
为了更加直观地展示多边形偏移文本域的生成,如图7 所示,pi为第i个多边形偏移文本域;di为在文本实例基础上进行的偏移距离;pt为文本实例的边缘信息。
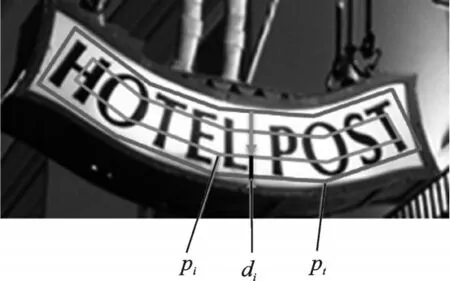
图7 多边形偏移文本域示意图Fig.7 Diagram of polygon offset text field
2.3 损失函数
本文采用实例分割方式进行文本检测,因此可以当作二分类任务选择损失函数。目前比较受欢迎的损失函数有很多,如交叉熵损失、焦点损失、Dice 系数损失等。Dice 系数损失源于二分类任务,经过改进被称为Soft dice 损失,改进过程中使用了目标掩码,利用目标掩码的大小归一化损失的效果,使得Soft dice 损失很容易从图像中具有较小空间表示的类中学习。而本文损失函数为式(3),损失主要由3部分组成,(1)预测文本边界框损失Lt;(2)生成多边形偏移文本域损失Ld;(3)像素损失Lp,指偏移文本域基于像素向外扩展过程产生的损失,λ1、λ2、λ3为平衡3 个损失设定的平衡系数。

式中:Pt(x,y)为预测文本框Pt的像素点(x,y),G(x,y)为真实标签G的像素点(x,y),M为经过OHEM 训练得到的掩码值。
多边形偏移文本域损失,本文也采用Soft dice 损失,根据偏移文本域pi中的像素点进行计算,计算过程为
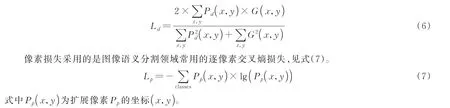
3 实验结果与分析
3.1 基准数据集
为了测试LAGNet 的性能,选取国际文档分析与识别大会(International conference on document analysis and recognition,ICDAR)提供的比赛数据集ICDAR2015,该数据集以英文为主,大部分场景是街区、商场和路标等,复杂的背景加上文本的多样性非常具有挑战性。该数据集共有1 500 张图,1 000张训练集,500 张测试集,标签是4 个坐标点顺时针排布。
为了进一步测试LAGNet 在弯曲文本上的性能,选取由Liu 等[15]构建的具有挑战性的曲线文本检测数据集SCUT-CTW1500,数据集中艺术字体较多,文本连接密集,场景多为广告牌、商标等。该数据集由1 000 幅训练图像和500 幅测试图像组成,标记方式为14 个点的多边形,可以描述任意曲线文本的形状。
3.2 训练细节
训练模型过程中,没有预训练步骤,直接在ICDAR2015、CTW1500 等数据集上从头开始训练,使用一块NVIDIA GTX 1080Ti GPU,反向传播采用的是Adam[18]和Adadelta 优化算法,其计算梯度为0.9,梯度平方的运行平均值为0.999,权重衰减系数为1E-8。初始的学习率设定为1E-4,在随后的训练中每经过训练批次的1/3 更新一次(乘以1E-1)。
深度学习采用Pytorch 网络框架,在训练过程中,忽略数据集中的模糊标签,对输入的图片大小归一化处理为640 像素×640 像素。在测试阶段,参考基础网络PSENet,对于数据集ICDAR2015 中的测试图片,大小归一化为2 240 像素×2 240 像素,最小卷积尺度设为0.4;对于数据集CTW1500 中的测试图片,大小归一化为1 280 像素×1 280 像素,最小卷积尺度设为0.6;分类置信度设为0.9,将大于置信度的像素归为文本像素。
本文对LAGNet 网络模型进行训练的时候,使用TensorboardX 库对训练集准确率Accuracy 与损失(Loss)进行可视化,方便观察网络模型的收敛情况。在常文本数据集ICDAR2015 上的训练情况如图8所示,由图8 可以看出,经过300 个批次以后精度基本达到稳定,准确率与损失变化幅度都变小,为了确保准确性,在经过400 批次时对学习率衰减,曲线图并未发生突变,到达600 批次时终止训练。在弯曲文本数据集CTW1500 上的训练情况如图9 所示,参考前面的训练过程,当达到300 批次以后模型基本趋于稳定状态,终止训练并采用当前模型进行测试。

图8 ICDAR2015 准确率与损失训练曲线图Fig.8 ICDAR2015 accuracy and loss training curves
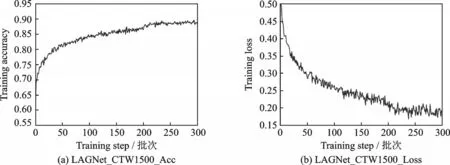
图9 CTW1500 精确度与损失训练曲线图Fig.9 CTW1500 accuracy and loss curves
3.3 实验分析
3.3.1 常文本检测分析
ICDAR2015 数据集是非常典型的常文本数据集,数据集中的图片背景极其复杂,包含大量的无关信息还包含多种多样的字体。如表2 所示,本文将LAGNet 检测模型与目前经典的CTPN[6]、SegLink[8]等检测算法在准确率P、召回率R和F值3 个指标上进行评估分析,同时为了验证本文特征提取模块改进的有效性,开展了消融对比实验,其中LAGNet-FLFF 是指在LAGNet 中只对恒等残差块进行设计,实现局部细粒度特征融合;LAGNet-MGFF 是指在LAGNet 中仅实现多尺度全局特征融合。为了直观显示本文方法的有效性,图10 展示了基础网络PSENet(Resnet-50)与LAGNet 模型的部分测试对比图。
通过表2 中的指标分析,本文方法在仅实现LAGNet-FLFF 的情况下,与基础网络PSENet(Resnet-50)相比,召回率有所提高,因为该方式加强了对高层语义信息的提取,提高了对小文本的检测性能,减少了漏检误检的情况,但是在准确率上却没有基础网络模型好。 在仅实现LAGNet-MGFF 的情况下,本文方法的准确率有所提升,因为该方式将特征实现了全局共享,低层语义信息中包含了大量的文本特征,对大文本的检测性能提升很多,而数据集中大文本所占比例相对较大,对应的一些草木、护栏和铁轨等类似文本模块的检测也提升了,导致召回率降低很多。将两个模块进行合并以后,本文方法在ICDAR2015 数据集上的准确率达到了84.2%。与CTPN、PSENet 的经典算法的评价指标值[12]相比,本文方法准确率低于TextSnake 0.7%,召回率低于PiexlLink 0.2%,但综合指标F值高于TextSnake 和PexelLink,同时,相比基础网络PSENet(Resnet-50)F值提高了2.2%。因此本文方法在ICDAR2015 数据集上的综合检测性能有所提升。
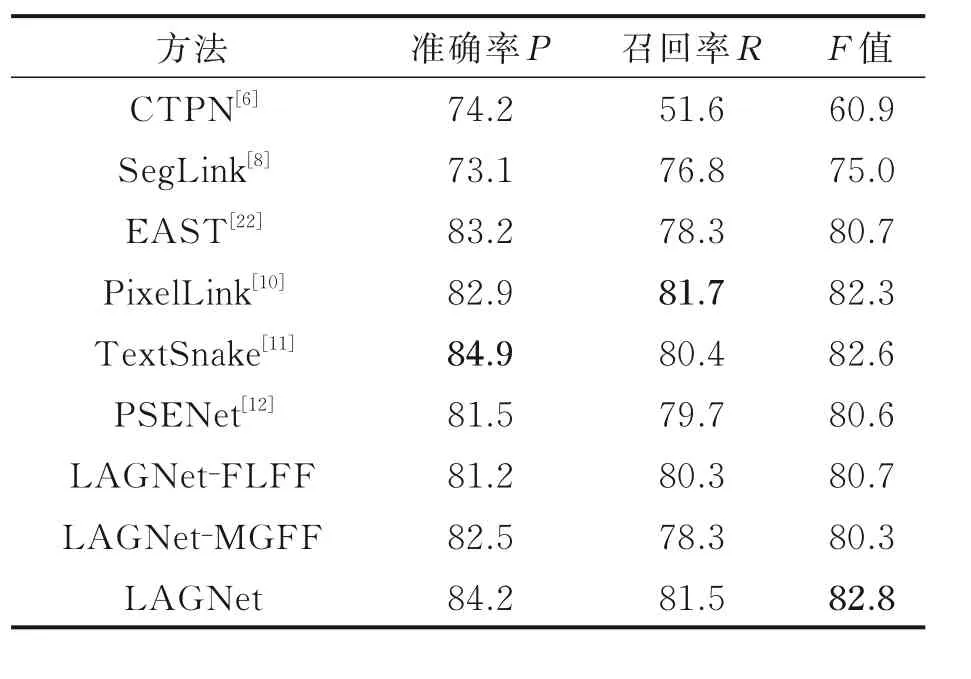
表2 ICDAR2015 数据集检测结果Table 2 ICDAR2015 data set detection results
图10 中,第1、2 行为基础网络模型PSENet(Resnet-50)的部分检测效果图。当场景中文本大小不一排列时,所检测的文本不够完整,边缘判断存在缺陷,例如第1 行第1 张张图所示。当场景中文本比例不均衡时,会出现漏检的情况,可能是浅层中提取的特征丢失引起的,如第1 行第2 张与第2 行的第1、2 图所示。当遇到场景中镜面反光的情况,如第1 行第3 张与第2 行第3 张图所示,对文本边缘的定位不准,也出现了漏检的情况。当场景图中文本所占比例非常小或出现遮挡的时候,文本检测出现漏检的现象,如第1 行第4 张与第2 行第4 张图所示。第3、4 行为本文所提出的LAGNet 网络模型对常文本的定位效果图,可以很直观地看出,经过改进后的网络模型在干扰较强的文本检测中有所提升。
3.3.2 弯曲文本检测分析
CTW1500 是一个典型的弯曲文本数据集,该数据集中存在大量的艺术体、模糊小文本和类似文本干扰等因素。为了验证本文所提方法在自然场景中弯曲文本检测效率,基于CTW1500,本文将LAGNet 检测模型与目前经典的文本检测算法在准确率P、召回率和F值3 个指标上进行评估分析,并对本文改进模块进行了消融对比实验,分析结果如表3 所示,部分检测效果图如图11 所示。
通过表3 中的指标分析,在弯曲文本中检测中,本文方法仅实现LAGNet-MGFF 的情况下,准确率提升幅度相对较大,达到了84.5%,比以上经典检测算法均高,但是与仅实现LAGNet-FLFF 的情况相比,召回率降低了3.4%,当对两个模型合并以后本文方法的召回率达到了79.2%,在所测检测算法中最高。
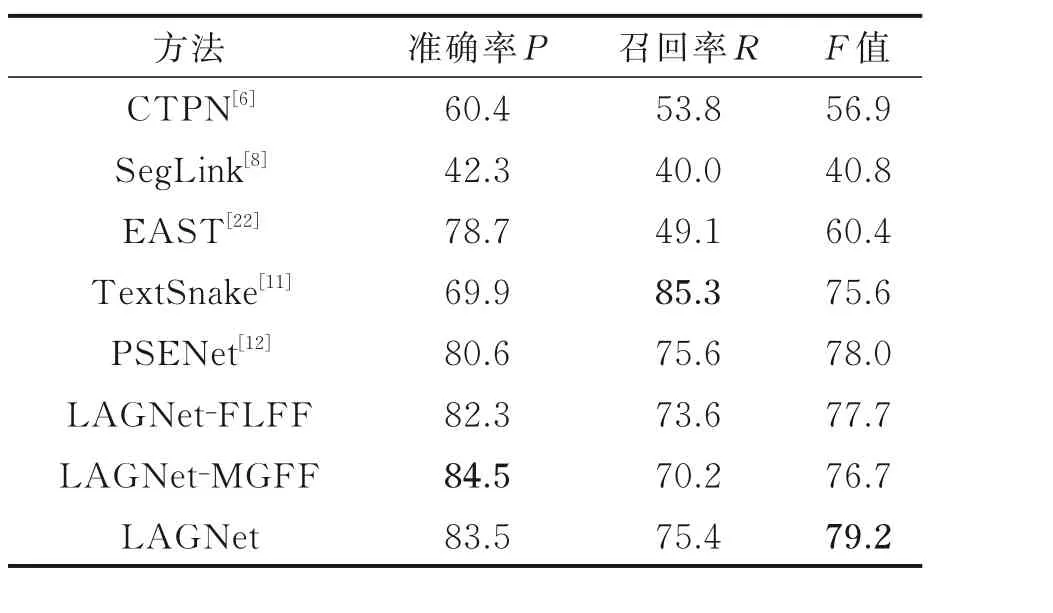
表3 CTW1500 数据集检测结果Table 3 CTW1500 data set detection results
图11 文本中,第1、2 行为基础网络模型PSENet(Resnet-50)的部分检测效果图,从图11 中可知,PSENet 对一些模糊的艺术体文本检测会出现遗漏或者检测不完全的情况,如第1 行第1 张与第2 行第1、3、4 图所示;对铁轨、围栏等一类的干扰因素无法排除,会发生误检,如第1 行第2 张与第2 行第2 张图所示;对遮挡的小文本区域定位不准,会出现漏检的情况,如第1 行第3 张图所示;对出现部分遮挡的文本检测不够完整,如第1 行第4 张图所示。第3、4 行为本文所提出的LAGNet 网络模型对弯曲文本的定位效果图,从图11 可以看出在边缘模糊文本、强干扰以及部分遮挡小文本等自然场景文本检测中,本文模型的检测效果有一定的提升。
4 结束语
基于PSENet 方法,本文提出自然场景文本检测网络LAGNet-MGFF,结合FPN 结构思想,实现了多尺度特征全局共享,增强了网络的鲁棒性,同时在后处理模块中将多尺度偏移文本域与文本边缘信息相结合,提高对复杂场景下文本的定位准确性。在数据集ICADAR2015 和CTW1500 上开展的训练与测试表明,在召回率、F值等指标上,本文的检测模型优于基础网络PSENet(Resnet-50)等方法。
