基于XGBoost 的微博流行度预测算法
2022-04-14任敏捷靳国庆王晓雯陈睿东袁运新聂为之刘安安
任敏捷,靳国庆,王晓雯,陈睿东,袁运新,聂为之,刘安安
(1.人民网传播内容认知国家重点实验室,北京 100733;2.天津大学电气自动化与信息工程学院,天津 300072)
引言
随着互联网的普及和媒体融合建设的推进,主流社交媒体的流行度预测是全媒体时代下备受瞩目的研究课题[1],可以广泛应用于舆情监测和数据话语权争夺的领域中,具有相当可观的现实意义。在我国,微博是一个影响力较广的主流社交媒体,对微博流行度预测问题进行研究有助于计算信息未来的热度、发现热点话题和提取信息传播的规律,进而广泛应用于信息检索、舆情研判和企业营销等领域[2]。
流行度预测指的是对由用户发布的信息未来所获得的关注程度进行预测[3]。而流行度的定义往往取决于社交媒体的平台,不同的网络平台有不同的数值指标度量。当前许多研究仅使用单一评价指标,例如,Pinto 等[4]将流行度定义为YouTube 上在线视频的浏览数,提出通过训练多元线性模型(Multivariate linear model,ML Model)和多元径向基模型(Multivariate radial basis functions model,MRBF Model)来预测视频的未来指定时刻的浏览数;孔庆超等[5]基于动态演化的论坛的讨论帖展开流行度预测,认为相较于帖子的浏览数,将流行度的度量定义为讨论帖的评论数更加能够反映用户的关注情况。Hong 等[6]将给定时刻Twitter 的转发数作为Twitter 的流行度,Gao 等[7]同样将转发数作为Twitter 和微博的流行度度量,但这种度量没有将微博的评论数和点赞数考虑在内,对受欢迎程度的指标范围覆盖不够全面,因此,为了使流行度的评价指标更具有代表性和普遍性,本文同时将微博的转发数、评论数、点赞数和三者之和定义为互动值来作为微博流行度度量的标准。
目前社交媒体流行度预测的主流方法是基于特征的模型预测,即先进行有效特征的挖掘,再进行模型的构造用以训练学习,最后得到流行度的各项指标。有效特征的挖掘立足于社交媒体平台信息特点的分析,Wu 等[8]在研究社交媒体流行度时针对Flickr 平台进行了考察,认为Flickr 平台上照片和帖子的时空信息对于最后流行度的影响十分重要。Mazloom 等[9]针对Instagram 上的帖子进行研究,发现其帖子的分类特征对流行度的准确预测大有益处。Vilares 等[10]在研究Twitter 上的信息时关注更多的是文本特征,流行度预测基于Twitter 信息的词汇和句法处理。这些方法都立足于所研究社交媒体的特点,表明特征的提取依赖于社交媒体的特性分析。而关于微博流行度的特点,有研究表明微博信息的流行度呈现幂律分布[11]。这种现象的出现源于微博社会网络中的信息过载导致的用户注意力稀缺[12],即微博信息的流行度与用户密不可分。张旸等[13]采用信息增益法分析多种发帖用户特征的重要性,证实了用户影响力之于帖子流行度的重要地位,Jiang 等[14]发现在影响微博信息流行度的重要因素包括该信息内容对相关用户的提及率。可以看出,以上发现多基于单类影响因素重要性的分析,没有综合考虑多种影响因素,特征利用不够全面,同时,不同社交媒体的特点具有独特性,现有的基于其他社交媒体平台的相关工作不能直接应用于微博的研究。
针对上述问题,本文对微博这一社交媒体平台进行分析,针对其特点提出和构造了对应的特征,设计了多种流行度预测方案。考虑到XGBoost 可以有效地对所提特征进行联合利用[15-16],本文着重提出了一种基于XGBoost 的微博流行度预测算法。所提出的算法能够从多方面充分考虑与微博流行度密切相关的影响因素,将涉及的相关特征进行提取和融合。首先,基于对原始数据分析,分别从博文信息、话题信息和用户信息3 方面提取特征。在博文特征中,重点构造了博文内容数值化特征和博文时间特征,并基于博文特征衍生出话题特征。在用户特征中,将用户的影响力具象化,同时从统计学的角度对用户的档位分布特征进行比例计算,作为新的用户特征。本文算法采用了分类式框架,多类特征融合之后,提前对流行度的档位进行划分,使用XGBoost 作为分类模型对微博的流行度档位进行预测,将流行度预测问题转换为流行度分类问题。最后,对用户特征进行再构造,基于新的用户特征,将微博的流行度进行分类输出,得到需要的微博转发数、评论数、点赞数和互动值。
总而言之,本文的创新点可以归纳为以下3 个方面:
(1)针对国内社交媒体流行度预测工作匮乏的情况,对微博这一国内主流社交媒体平台的流行趋势特点进行分析和建模,着重挖掘了发博用户、发博时间、博文话题等信息与博文流行度的关联并构造了对应的多种特征。
(2)基于提取和构造的多种特征,设计了多种微博流行度预测方案,在实验部分进行了性能比较。
(3)着重提出了一种基于XGBoost 的微博流行度预测算法,该算法采用了分类式框架,综合考虑了点赞数、评论数和转发数3 个指标,将提取好的博文特征、话题特征和用户特征融合起来,对流行度进行分档预测,在微博流行度预测数据集上取得准确率高达85.69%的良好效果。
1 相关技术
1.1 特征提取和特征融合
本文运用特征提取(Feature extraction)和特征融合(Feature fusion)的思想。特征提取指的是对初始的某一模式的未处理数据进行变换,建立非冗余的能够提供该模式有代表性信息的派生值,即特征,以便后续学习与泛化,特征提取被广泛应用于模式识别和机器学习中,提取出特征的好坏与泛化能力密切相关[17]。
特征融合,是指对同一模式抽取不同的特征矢量进行优化组合[18]。根据融合时间的不同,特征融合又可分为两大类,一类为前期融合(Early fusion),即在模型训练前就将不同的特征融合,融合后的特征用于训练和学习,经典的特征融合方法有串联拼接(Concat)和并行策略(Add)。另一类为后期融合(Late fusion),这一类在特征未完全融合之前就进行模型训练,根据结果改进后多次训练后融合。后期融合典型的方法有Single shot multibox detector(SSD)[19],Multi-scale CNN(MS-CNN)[20]和Feature pyramid network(FPN)[21]等。基于前期融合在社交媒体领域流行度预测的良好表现[22],本文算法采用的是前期融合中的串联拼接方法。
1.2 机器学习模型的应用
社交媒体的流行度预测还依赖于良好模型的构建。极端梯度提升决策树(eXtreme gradient boosting,XGBoost)是在梯度提升决策树(Gradient boosting decision tree,GBDT)的基础上将速度和效率发挥到极致的机器学习模型[15,23],其核心思想是根据样本的特征,从零开始,每一次迭代都在现有基础上增加一棵树,即分类器,去拟合上一次迭代中预测值和真实值的残差,训练完成得到所有分类器的值相加,即为最终的预测结果。在整个迭代的过程中,需要定义一个目标函数,使整个树群的预测值尽可能靠近真实值,同时保障有较大的泛化能力。
本文算法将采用在残差学习中,表现比GBDT 更好的XGBoost[15-16]对微博信息的多模态特征进行训练,在充分挖掘和构造有效特征的基础上,利用机器学习的模型提高算法的性能。
1.3 深度神经网络原理
在下文的对比实验中,采用深度神经网络(Deep neural networks,DNN)[22]结构设计了基于深度学习框架的流行度预测方法,与本文算法进行性能对比。
基于感知机的扩展,DNN 可以被理解为含有多层隐藏层的神经网络,其内部可分为输入层、隐藏层和输出层3 类。见图1,使用的DNN 网络包含两个隐藏层,最左边一层是输入层,中间两层是隐藏层,分别为256 和128 维(此处分别用4 和2 个神经元代替表达),最终输出层为1 维的输出。输入层即为融合后的特征输入。
2 基于XGBoost 的微博流行度预测算法
本文提出了一种基于XGBoost 的微博流行度预测算法(图2)。在算法架构中主要包括数据分析、特征的提取与融合以及XGBoost 训练3 个模块。
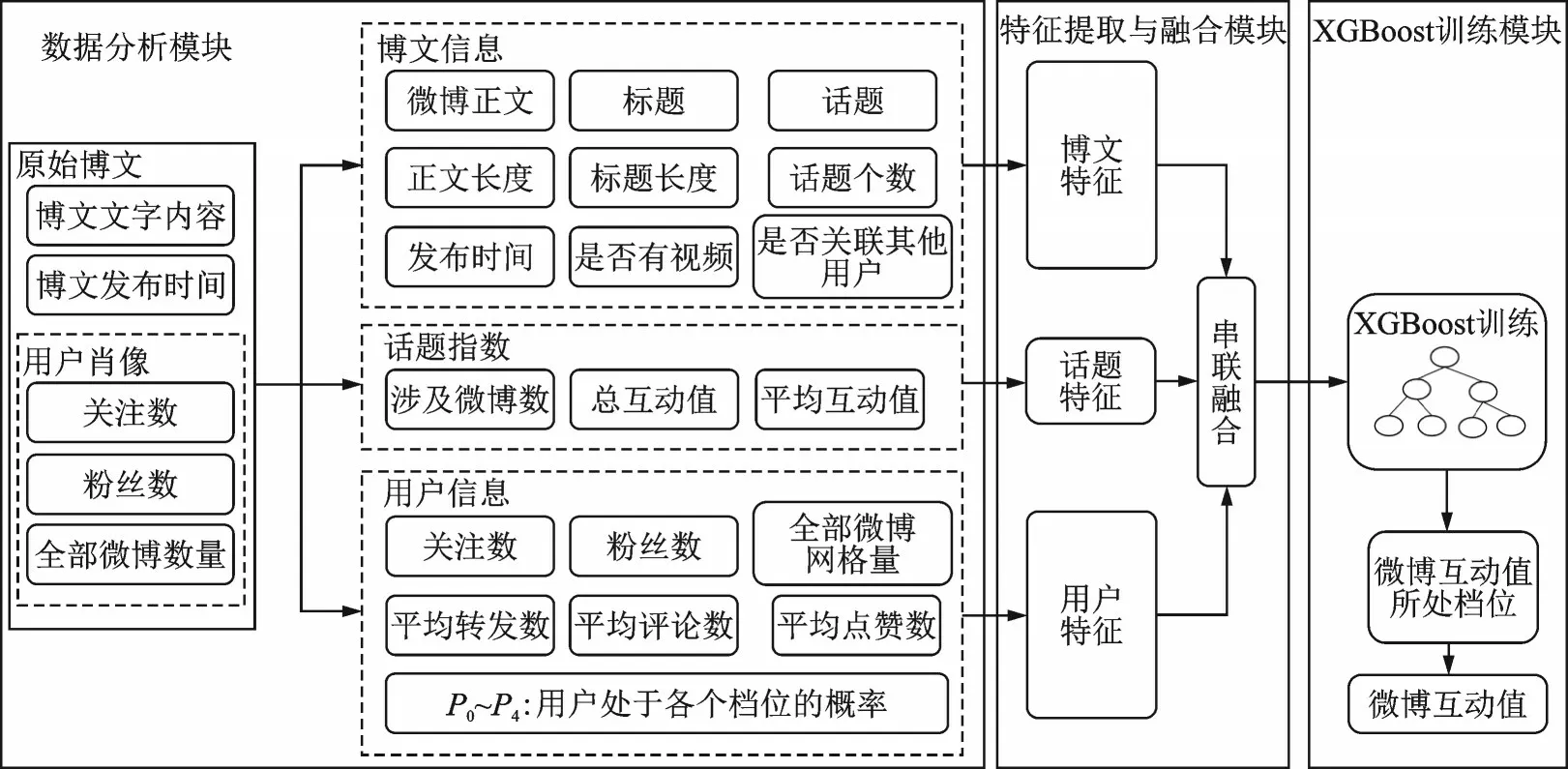
图2 基于XGBoost 的微博流行度预测算法架构Fig.2 Framework of microblog popularity prediction algorithm based on XGBoost
2.1 数据分析
微博流行度预测数据集中的用户肖像信息和微博信息分别见表1 和表2。对以上数据进行分析,选取影响流行度预测的关键因素汇总,见表3。从表1~3 可以看出,原始数据主要可分为博文信息和用户肖像信息两大类,博文信息有博文文字内容和博文发布时间,用户肖像信息包含用户的全部微博数量、该用户的关注数和粉丝数。这两类数据信息与流行度预测密切相关,都是微博流行度的重要影响因素[2]。但两类数据包含的特征重要性各有差别,在此基础上分别进行特征的提取与构造是十分必要的。在进一步特征提取与构造的过程中,本算法将有效特征分为3 类:博文特征、话题特征和用户特征。
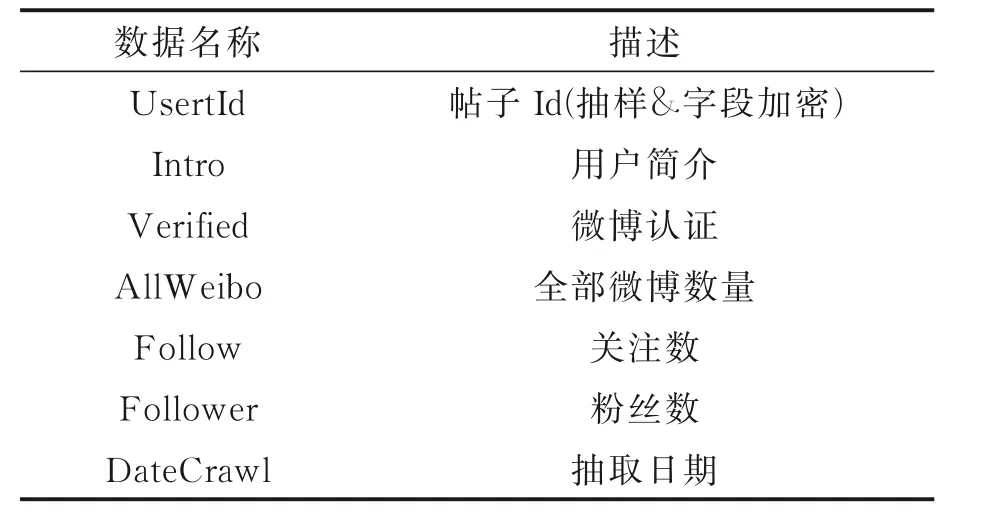
表1 用户肖像信息Table 1 User portrait information
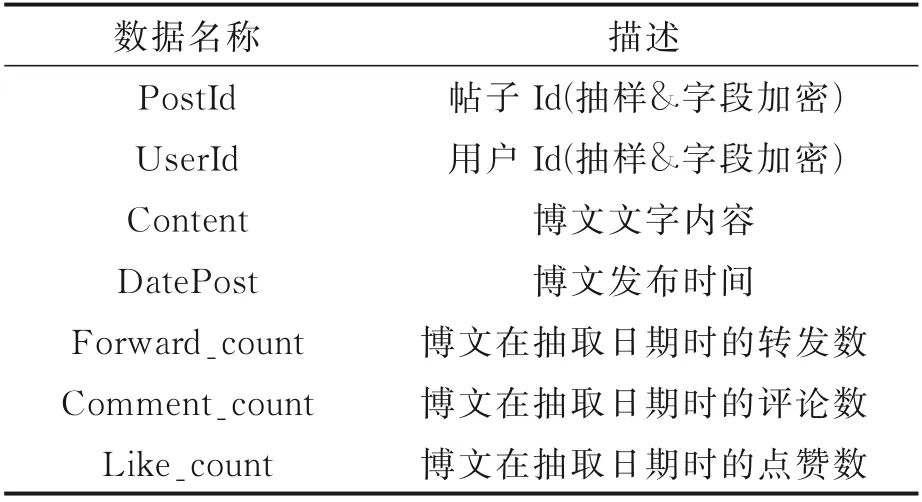
表2 微博信息Table 2 Microblog information

表3 微博流行度预测相关的原始数据Table 3 Original data related to microblog popularity prediction
2.2 特征提取与融合
2.2.1 博文特征提取
将原始的博文文字内容和博文发布时间进一步分析可以提取和构造出如表4 所示的博文特征。
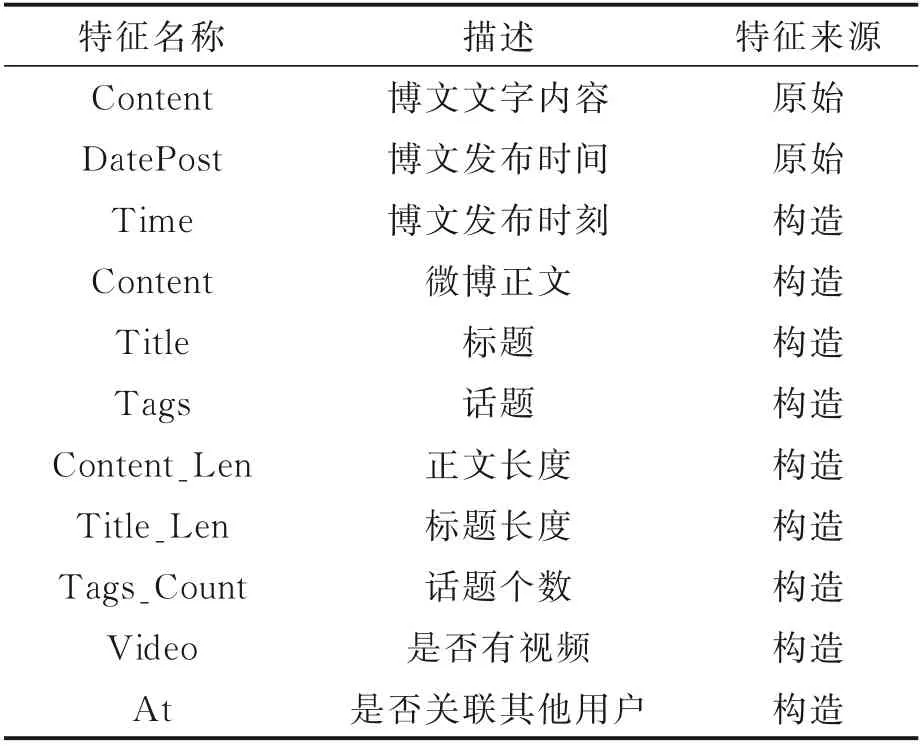
表4 博文特征Table 4 Blog features
对于博文的文字内容,关注到其包含着微博正文、标题和话题等重要内容特征,且内容结构工整,格式较为统一。例如,标题一般由“【】”进行标注,话题存在于“##”之间,微博正文是剩余的文字内容。基于以上特性,对原始的博文进行第一次数据清洗,得到了标题、话题和第一版微博正文。
针对所得第一版微博正文,部分博文带有特殊符号@和网址,分别表示关联其他用户和存在视频链接。基于该发现,对第一版微博正文进行第二次数据清洗,得到了最终的微博正文和是否有视频及是否关联其他用户的布尔类型的附加特征,其中1 代表有,0 代表无。
得到微博正文、标题和话题等文本化的内容特征并不能完全满足模型训练的要求,在此基础上进一步对其进行数值化的构造,得到正文长度、标题长度和话题个数3 个新的数值化特征。
对于博文的发布时间,基于一天中不同时刻社交媒体的流量存在高低峰差异,见图3,横轴为一天24 小时中不同的时段,纵轴表示数据集中所有博文在一天中该时段的平均或总互动值,可以看出不同时刻互动值相差较大,反映了流行度的时间敏感性,故重点关注博文的发布时刻,并从原始发布时间中提取出这个时间特征,认为其可以作为需要关注的有效博文特征。
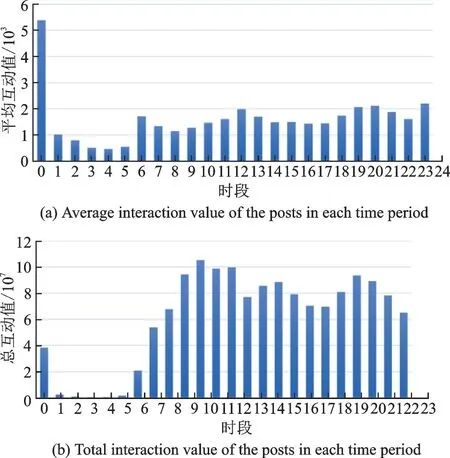
图3 博文发布时段与互动值关系Fig.3 Relationship between publishing period and interactive value
2.2.2 话题特征提取
话题特征是从博文特征中的话题衍生出来的新的特征,主要反映某话题的影响力,即话题指数。
表5 主要构造了3 个话题特征:话题涉及的微博数、话题的总互动值和话题平均互动值。其中互动值表示为微博的转赞评之和,总互动值是话题涉及微博的所有转赞评之和,而平均互动值是话题涉及微博的单条微博的平均转赞评之和。一般认为,话题指数越高,该话题的影响力越大。

表5 话题特征Table 5 Topic features
2.2.3 用户特征提取
如表4 所示,用户特征是从用户肖像信息中提取和构造得来。原始的用户肖像特征如用户全部微博数量、关注数和粉丝数可以大致反映用户的影响力,但还不够细致和全面。
在此基础上,对用户的影响力进一步具象化,主要反映在用户的每条微博的平均转发数(Avg_Repost)、平均评论数(Avg_Comment)、平均点赞数(Avg_Like)和平均互动值(Avg_Total)这4 个新构造的用户特征。他们之间存在如下关系
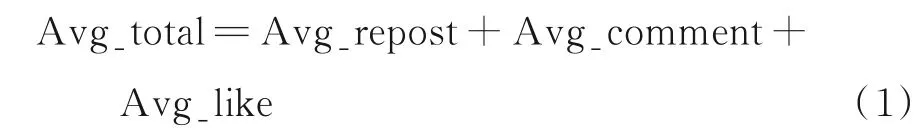
除此之外,还创造性地从统计的角度对用户的微博在不同档位的概率进行了计算。档位划分见表6。

表6 档位划分Table 6 Division of gears
用户的微博在不同档位的比例计算公式为
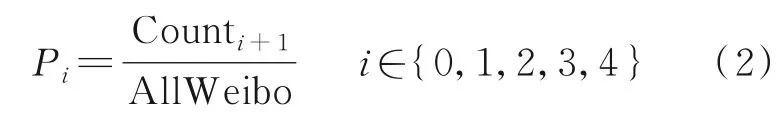
式中Counti+1表示用户在i+1 档位的微博数。最终,提取的用户特征总结见表7。
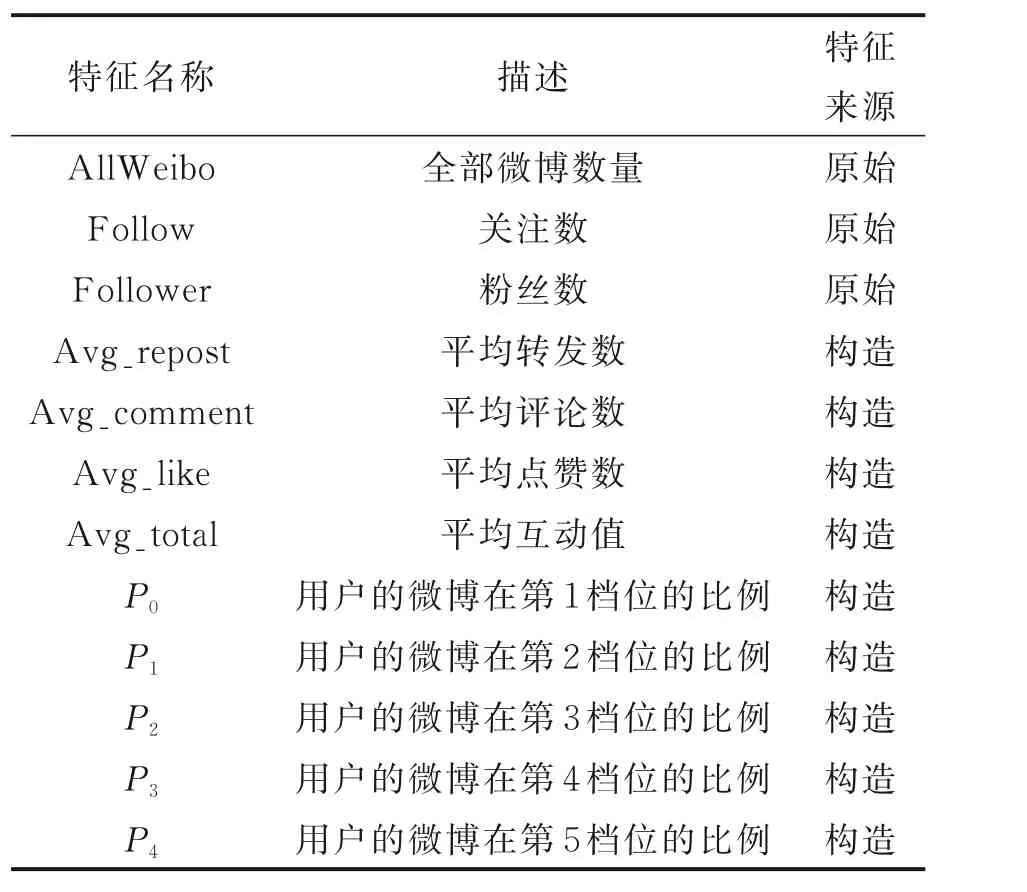
表7 用户特征Table 7 User features
特征工程的最后一步,是特征的融合,如图2所示,将提取和构造得到的博文特征fpost、话题特征ftag和用户特征fuser进行串联合并得到fall,即fall=fpost⊕ftag⊕fuser,作为XGBoost 模型的输入特征。
2.3 XGBoost 训练与输出
2.3.1 模型分类训练
得到特征工程输出的特征fall后,利用XGBoost 对fall进行分类训练,用以预测微博的流行度档位,亦即互动值档位。XGBoost 是一种广泛应用于分类和回归问题的决策树模型,在本文算法架构中,输入数据表示如下
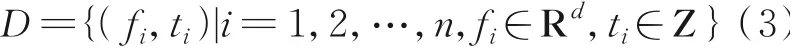
在输入数据表示中,fi表示第i条微博的总体特征,ti表示该微博的互动值档位,n为数据集中的微博总数,d表示特征的维度。训练目的是得到预测的微博互互动值档位t^i,定义如下

式中l表示损失函数。目标函数ο越小,XGBoost 的训练效果越好。
在训练的过程中,还采取了丢弃过大互动值(大于等于10 000)的训练策略,以提高模型对小数值的预测能力,在该训练策略下模型对丢弃的大数值也有能将其预测到档位5 的能力。
2.3.2 基于用户特征的分类输出
XGBoost 的分类训练运用于微博档位的预测事实上将互动值预测问题转换为互动值的分类问题,在得到预测的档位结果后,需要基于用户的特征将微博的互动值乃至转发数、评论数和点赞数进一步计算得到。
用户在不同的档位上会有不同的互动值,构造一个新的用户特征User_label_avg,计算公式为


式中:Label_repost 表示用户的转发比例,Label_comment 表示评论比例,Label_like 表示点赞比例,3 者共同构成了label_distribution 这一新的用户特征。
3 实验结果
3.1 数据集
微博流行度预测数据集由随机抽取的500 个主流价值观微博用户数据,以及这500 个用户于抽取日期前发布的共100 万条原创博文数据所构成。实验取每个用户随机90%博文内容数据形成训练集,而每个用户剩下10%数据为测试集。在训练过程中,随机选取训练集的80%用于模型训练,剩下的20%用于算法验证。
数据集中的用户数据包含用户Id(抽样&字段加密)、用户简介、微博认证、全部微博数量、关注数、粉丝数和抽取日期这些用户肖像信息。训练集中原创博文数据包含帖子Id(抽样&字段加密)、用户Id(抽样&字段加密)、博文文字内容、博文发布时间、博文在抽取日期时的转发数、评论数和点赞数。测试集的博文转发数、评论数和点赞数不公开。
3.2 评价指标
实验的评价指标按照分档规则,将每条微博的互动值(转赞评之和)划分为5 档,0~10 为1 档,11~50 为2 档,51~150 为3 档,151~300 为4 档,大于300 为5 档。每个档位对应的权重见表8。

表8 档位权重Table 8 Weight of gears
在这个分档规则下,将对于每一条博文抽取日期时的互动值(转赞评之和)的预测准确率进行评测,准确率(Accuracy)计算公式为
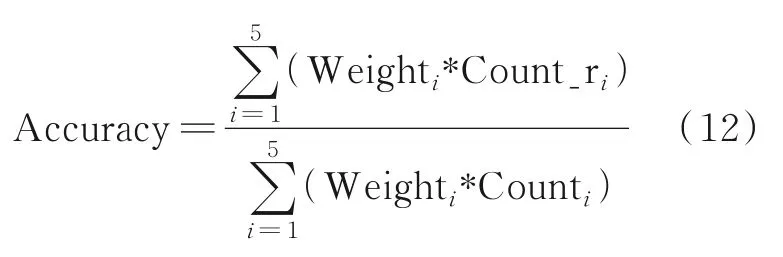
式中:Weighti为第i个档位的权重,Count_ri为第i个档位预测正确的博文数量,Counti为第i个档位的博文数量。
3.3 对比实验
除了上文提出的基于XGBoost 的分类式流行度预测算法,本文还提出了基于深度学习框架的方法、基于XGBoost 的预测式流行度预测算法和用户匹配方法3 类不同的设计方案与本文算法进行性能比较。
具体的实验细节为XGBoost 训练时采用5 次交叉验证,主要参数设置如下:“n_estimators”设为500,“ base_score”设为0.5,“gamma”设为0.1,“learning_rate”设为0.02,“min_child_weight”设为3,“max_depth”设为7。基于深度学习框架的方法在PyTorch 环境下训练,学习速率为10-4,训练验证次数设为10。
3.3.1 与深度学习方法对比
表9 给出了深度学习方法和本文方法在微博流行度预测数据集上的性能对比实验。
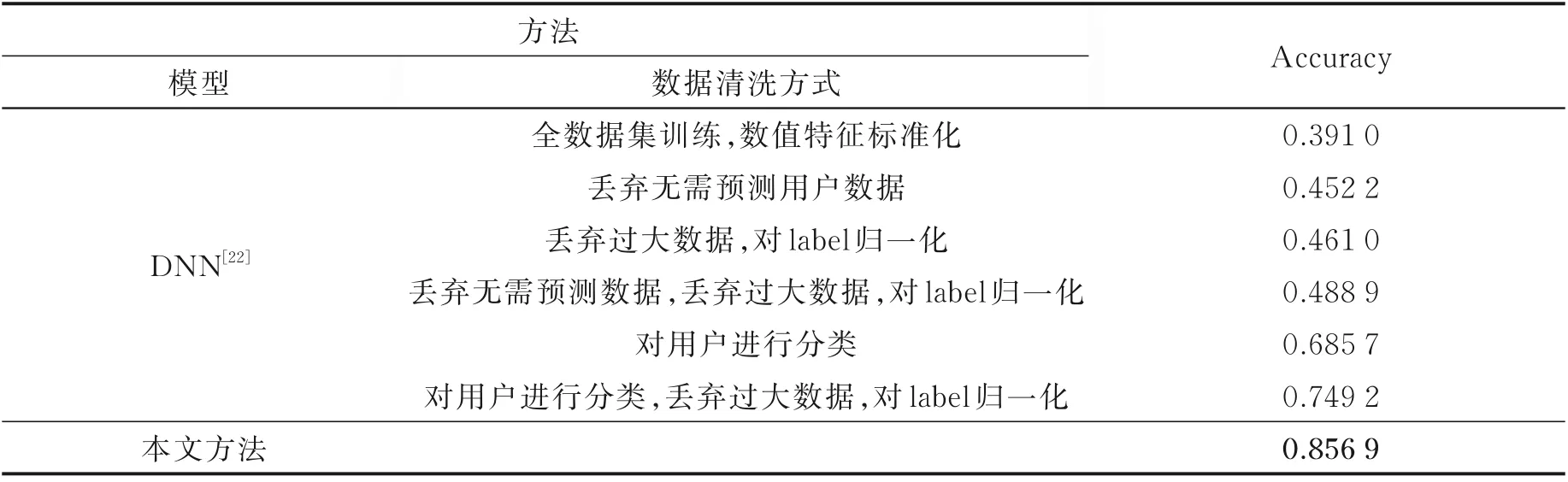
表9 与基于深度学习框架的方法对比实验Table 9 Comparative experiments with methods based on deep learning framework
深度学习的方法即基于前文介绍的DNN 结构,见图4,在此将所有特征分为两大类,文本特征使用BERT 模型处理,数字特征进行串联拼接处理,最后将所有特征融合,送入DNN 中训练学习。
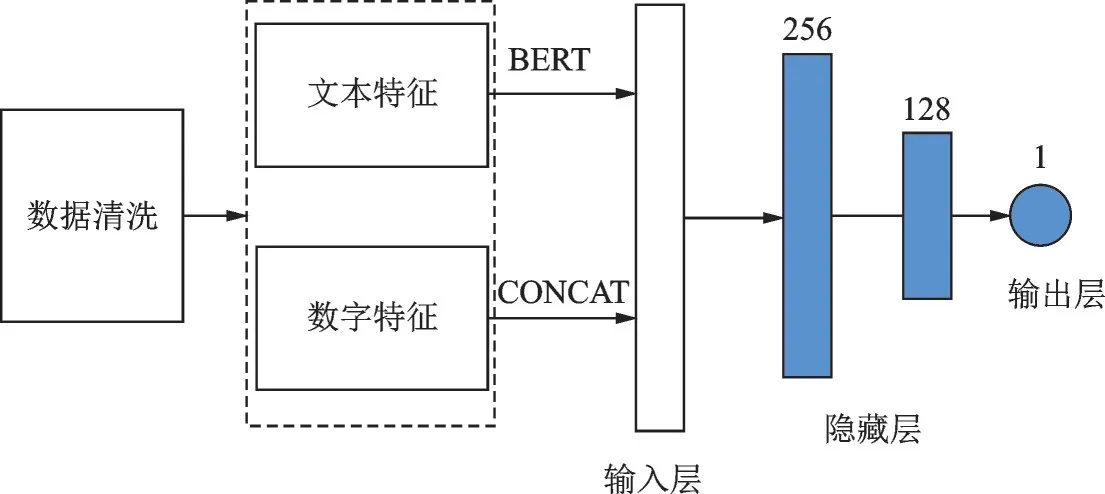
图4 深度学习方法框架Fig.4 Framework of deep learning methods
如表9 所示,在深度学习的各种方法中,发现仅基于DNN 模型[22]进行全数据集的训练准确率只有39.10%。
而丢弃无需预测的用户数据,即数据集内其所发微博有95%以上处于某一固定分类,在测试计算准确率时,将这部分权重单独计算,取测试集比例折合到训练结果中,和丢弃互动值过大(≥10 000)的数据,分别提高了6.12%和7%的准确率。同时将两种数据丢弃并将预测目标归一化用于DNN 训练,则可以将准确率提高到48.89%。另一种数据处理的方案是对用户进行分类(图5),不同的用户类别赋予不同权重,分类依据如下:
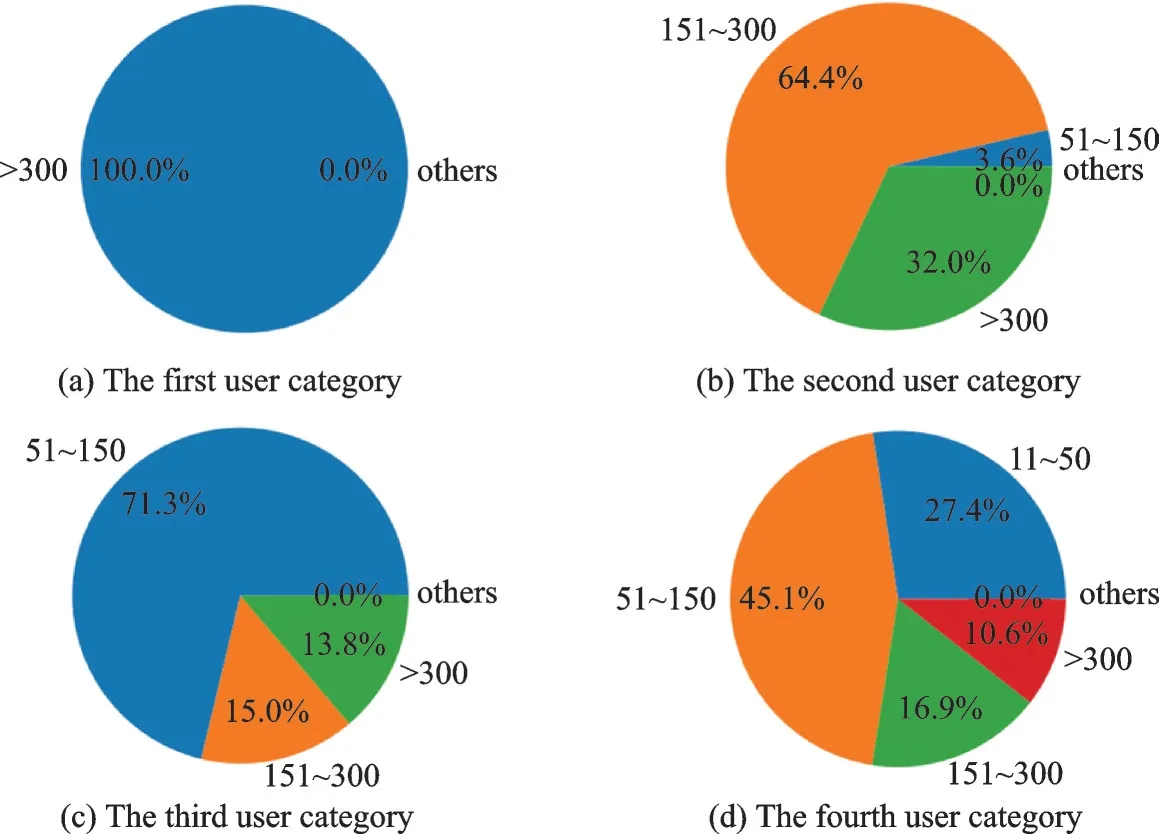
图5 用户分类示例Fig.5 Example of user classification
(1)用户类别1:95%以上博文全属于某一分段的用户(0,1,2,3,4);
(2)用户类别2:90%以上博文属于两个相邻分段的用户(01,12,23,34);
(3)用户类别3:90%以上博文属于3 个相邻分段的用户(012,123,234);
(4)用户类别4:剩余用户。
如表9 所示,对训练集进行用户分类处理后,准确率达到68.57%,性能得到大幅度提升,基于此,将所有对性能提升有益的方案加以融合,最终的准确率达到了74.92%。
尽管深度学习的方法对数据的特征利用率已经很高,但是最终的性能并没有超过本文方法。这是由于与深度学习的方法相比,XGBoost 模型对数字特征的敏感性较强,在本文微博流行度预测的情境下,结合用户信息博文信息数字特征占比很大的情况,本文方法所使用的XGBoost 模型能更好地利用这些数字特征的关联信息,具有一定的优势,因此优于深度学习算法。
3.3.2 预测与分类对比
本文的方法基于机器学习下的XGBoost 模型构建,其中预测对象是区别预测类型的重要关注项,预测对象为互动值或转发数、评论数和点赞数的方法,视作预测方法;预测对象为互动值所处档位的方法,则称之为分类方法。表10 列出了基于XGBoost 的预测与分类方法的不同数据划分方案的对比实验。
如表10 所示,考虑到互动值过大的数据对预测结果的不良影响以及其导致的训练样本分布不均衡的问题,在机器学习的所有方法中,训练时均丢弃了互动值过大的数据。对比发现,分类方法的性能明显高于预测方法,由于分类方法在流行度预测过程中对档位边缘的数据具体互动值容错率较高,提高了其档位预测的准确性。进一步分析可知,在预测方法中,对用户进行分类较其他数据划分方案性能更好,而预测方法中对互动值的预测较转发数、评论数和点赞数的预测更为准确,准确率高了1.53%。在分类方法中,对全数据集的训练性能要略高于丢弃部分用户数据,这表明在分类方法中,即使存在不同用户微博互动值差异过大的损失,提高数据量即使用所有的用户数据对提升互动值档位分类准确度仍有贡献。

表10 基于XGBoost 的预测与分类方法对比实验Table 10 Comparative experiments with prediction and classification methods based on XGBoost
3.3.3 与用户匹配方法对比
表11 展示了本文方法和用户匹配等其他方法的综合对比实验。

表11 与用户匹配方法的对比实验Table 11 Comparative experiments with user matching methods
用户匹配方法是一类基于用户特征的,不依靠于任何模型训练的方法。这类方法依赖于已知的用户微博流行度统计信息,将微博流行度情况与微博用户紧密联系在一起。用户匹配方法分为按用户最大权重档位匹配方法和按用户对应时段最大权重档位匹配方法。
按用户最大权重档位匹配方法的匹配策略是通过计算出用户微博各档位总权重分布,将某档位博文数量乘该档位权重。按用户对应时段最大权重档位匹配方法的匹配策略是先按用户一天中各个时段(0~23)统计所发博文获得最大权重的档位,然后按用户和时间进行匹配,若测试集中出现训练集中未出现的时段,匹配两侧相邻时段中权重大的那一个档位。见表11,实验结果表明,用户匹配方法准确率最高可达81.75%,这体现出用户特征在分类处具有显著作用,尽管用户匹配的方法对用户特征的挖掘十分全面,但是缺少模型的支持,在准确率上仍未超过本文方法。
所有实验结果表明,本文方法在评价指标上优于用户匹配和深度学习的所有方法。
4 结束语
针对全媒体时代下,社交媒体流行度预测在信息处理领域的重要性和必要性,本文提出了一种基于XGBoost 的微博流行度预测算法。首先,通过对微博数据的特点进行分析,梳理提炼出需要重点考虑的数据;其次,算法运用特征工程的思想详尽地挖掘、提取和构造了与微博博文及微博用户相关的包括博文特征、话题特征和用户特征在内的有效特征,并将有效特征进行融合;最后,将融合后的特征与XGBoost 模型进行结合用于训练学习,对用户特征进行二次构造利用,构建一个分类式的流行度预测架构,实现对微博的流行度预测。本算法证实了用户特征在流行度预测上的高影响力,并且在微博流行度预测的数据集上取得了优越效果,进一步验证了本文算法的合理性和优越性。在实际的应用中,本文算法可用于揭示社交媒体中个人偏好和公众关注,有助于预判社会舆情趋势,提前做出应对决策。同时,高准确率的流行度预测还可以提高用户体验和服务效率,并有利于广泛的应用,如内容推荐、在线广告和信息检索等,具有巨大的商业价值。但基于算法与用户的高度关联性,对缺乏用户信息的流行度预测或存在一定的局限性。
