融合LSTM-GRU 网络的语音逻辑访问攻击检测
2022-04-14杨海涛王华朋牛瑾琳楚宪腾林暖辉
杨海涛,王华朋,牛瑾琳,楚宪腾,林暖辉
(1.中国刑事警察学院公安信息技术与情报学院,沈阳 110854;2.广州市刑事科学技术研究所,广州 510030)
引言
科学技术的发展给人们带来便利的同时也产生了新的问题,例如语音作为生物识别技术的重要环节在日常生活中常常被人恶意利用,以进行诈骗、造谣和煽动公众情绪等。语音欺骗方法很早就产生,其类型主要包括:语音模仿、语音回放、语音合成和语音转换[1]。近年来人们开始重视语音欺骗检测。自动说话人识别欺骗攻击与防御对策挑战赛(Automatic speaker verification spoofing and countermeasures challenge,ASVspoof)于2015 年第一次举办,主要关注于逻辑访问(Logical access,LA),包括语音合成(Text to speech,TTS)和语音转换(Voice conversion,VC)检测[2]。随后的ASVspoof2017 注重于物理访问(Physical access,PA)区分真实音频和回放音频[3]。ASVspoof2019 则涵盖了LA 和PA[4]。在这几个挑战赛中度量标准都是等错误率(Equal error rate,EER),包括语音合成、语音转化的逻辑访问攻击语音因其逼真性而被广泛应用[5],这也给不法分子提供了便利条件。传统机器学习的语音欺骗检测主要使用高斯混合模型和i-vector,前者具有训练速度快、准确度高的优点,但由于语料不够,抗信道干扰差;后者则对全局差异进行建模,除信道的干扰,放宽了对训练语料的限制[1,6-7]。随着深度学习的快速发展,深度神经网络(Deep neural network,DNN)被应用于语音欺骗检测。Villalba 等使用DNN 对提取的率波库(Filter bank,FBank)及相对相移(Relative phase shift,RPS)特征进行检测,在10 种欺骗语音检测结果中有9 种EER 低于0.05%,取得了非常好的效果[8]。卷积神经网络(Convolutional neural networks,CNN)在图像领域的成功应用为语音处理提供了更多思路。Lavrentyeva 等使用CNN 的变种LCNN 进行语音回放检测,并在ASVspoof2017 挑战赛中取得语音回放检测第一名的成绩[9],证明了CNN 在语音欺骗检测中的能力。处理语音时序数据能力较强的是循环神经网络(Recurrent neural network,RNN),RNN 通过循环单元和门限结构使其具有记忆性。Gomez-Alanis 等使用CNN-RNN 的混合模型对噪声鲁棒性语音进行欺骗检测,取得了较好的效果[10]。该团队在后来的研究中使用GRU-RNN 的混合模型对回放语音、转换语音及合成语音进行欺骗检测,其结果都比ASVspoof2019 提供的基线系统更优[11]。但是RNN 在处理长时依赖问题时易出现梯度消失和梯度爆炸的现象[12]。Hochreiter 等提出的长短期记忆网络则是为了解决这一问题[13]。在ASVspoof2017 挑战赛中,Li 团队使用了基于注意力机制的LSTM 结构取得较好的结果[14]。Cho 等于2014 年提出的门控循环神经单元是长短期记忆网络(Long short-term memory,LSTM)的变种中改动较大的一种[15]。Chen 等使用门控循环神经单元(Gated recurrent unit,GRU)在ASVspoof2017 数据集上进行试验,EER 为9.81%,表现突出[16]。文献[17-18]则对LSTM 和GRU 网络模型进行了比较,发现两者的能力相当,但相比于LSTM网络,GRU 的张量操作更少,训练速度更快,泛化能力更强。
在语音逻辑访问攻击检测的任务中,单一的神经网络结构在进行逻辑访问攻击检测时存在着一定的局限性,因此混合网络模型成为研究热点。在处理语音序列中,LSTM 网络和GRU 网络能够更好地处理语音序列中的长时依赖问题,进而提高网络的性能。由于两种网络结构相似,在融合时能够正确获取语音信息。为进一步提高语音欺骗检测的准确率,本文将LSTM 网络及GRU 网络进行融合,提出一种融合LSTM-GRU 网络模型进行语音欺骗检测研究。
1 门控循环神经网络
门控循环神经网络是在传统DNN 的基础上加入了门控机制用来控制神经网络中信息的传递,可以解决长时依赖关系问题,避免了梯度消失和梯度爆炸。
1.1 长短期记忆网络
LSTM 网络结构由一系列的记忆单元组成,记忆单元通常包含一个自连接记忆单元来存储网络的时间状态。LSTM 拥有3 个门(输入门、输出门和遗忘门)来保护和控制单元状态,也就是控制信息的流动,其中:输入门决定记忆单元内保存什么新信息;输出门决定要输出的单元状态信息;遗忘门决定要忘记什么内容。图1 所示为LSTM 记忆单元结构。在时间步长t处,LSTM 可表示为
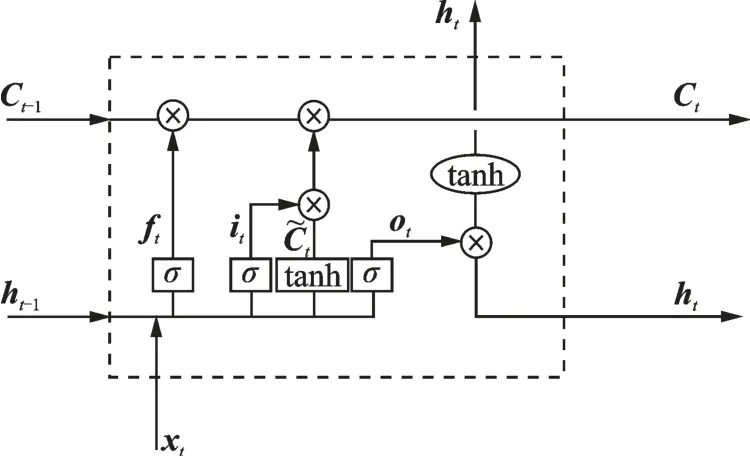
图1 LSTM 记忆单元Fig.1 LSTM memory cell
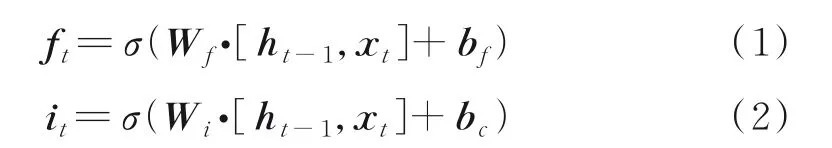
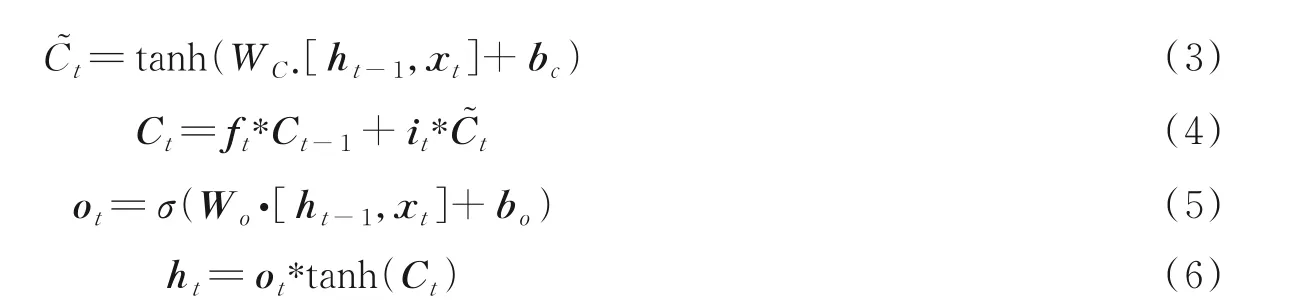
式中:激活函数使用的是Sigmoid 函数(σ)和双曲正切函数(tanh);it、ot、ft、Ct、C~t分别表示为输入门、输出门、遗忘门、记忆单元内容和新记忆单元内容;W表示权重矩阵;b表示偏置向量,比如bi表示输入门的偏置向量;ht为时间t时的隐层向量。
1.2 门控循环神经单元
GRU 与LSTM 的结构相似但是结构更简单,张量操作更少。它引入了重置门和更新门的概念,从而修改了循环神经网络中隐藏状态的计算方式,图2 所示为GRU 的记忆单元结构。GRU 通过直接在当前网络的状态ht和上一时刻网络的状态ht-1之间添加一个线性的依赖关系,来解决梯度消失和梯度爆炸的问题,表达式为
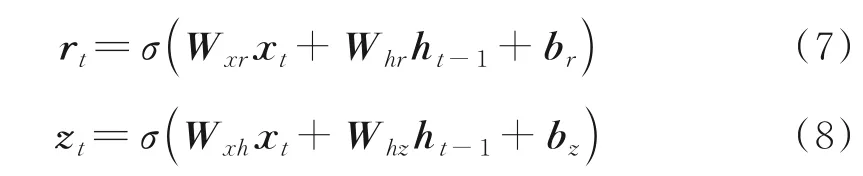
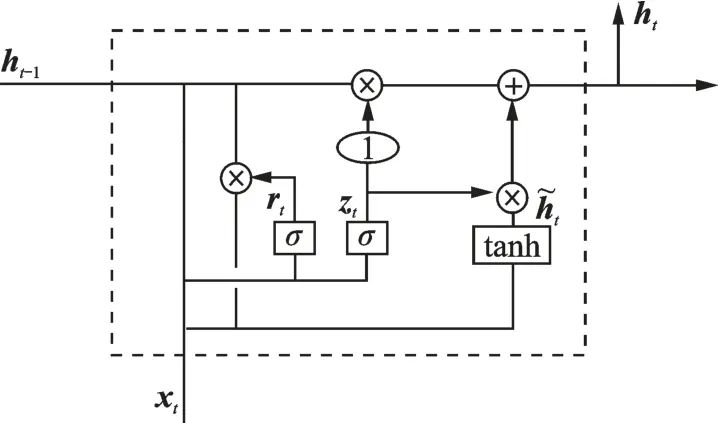
图2 GRU 记忆单元Fig.2 GRU memory cell
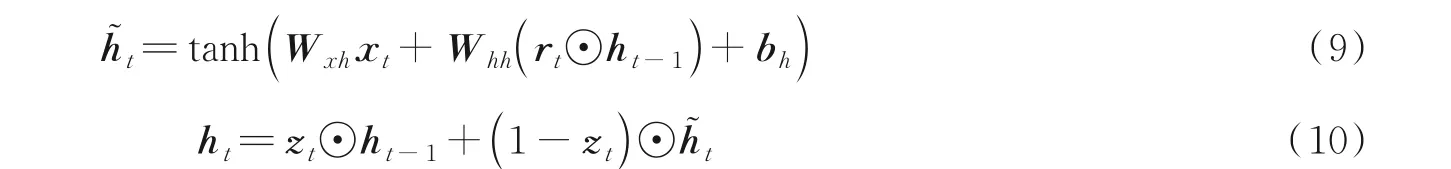
式中:rt、zt、xt分别表示重置门、更新门和输入向量;⊙表示Hadamard Product,也就是操作矩阵中对应的元素相乘;其他变量含义与LSTM 网络相同。
2 融合LSTM-GRU 网络的检测系统
2.1 LSTM-GRU 网络结构
LSTM 通过自身的3 个门控装置来控制数据信息在网络间的流通并以此解决长时依赖问题,但是由于LSTM 网络设置的参数过多,每1 个细胞里面都有4 个全连接层,在实际应用过程中,如果时间跨度较大而LSTM 网络层次又深则会容易出现过拟合现象,并且对计算机的运算能力要求也较大。GRU为LSTM 的简化,它引入了更新门和重置门来处理数据信息,相比于LSTM 设置的参数更少,减少过拟合风险,但是在处理大数据集的情况下表现不如LSTM。在此本文将两种网络结构进行串联处理,提出一种融合LSTM-GRU 的网络结构。
LSTM-GRU 网络是由单层LSTM 网络及单层GRU 网络串联形成的一种混合网络结构,如图3 所示。数据输入LSTM 层后依次通过输入门、输出门和遗忘门,使用sigmoid 函数和tanh 函数进行信息的更迭处理后进入GRU 层;GRU 层中的更新门和重置门对信息进行矩阵相乘处理,输入到Dropout 层,丢弃一些神经节点防止过拟合;随后进行归一化处理,再输入到全连接层;最后通过使用softmax 函数的分类层进行真假语音分类。
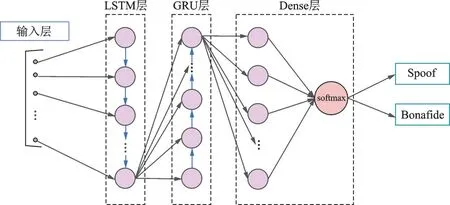
图3 LSTM-GRU 网络结构Fig.3 LSTM-GRU network structure
2.2 检测系统的评价指标
评价语音欺骗检测性能的常用指标是EER。EER 是错误拒绝率(False rejection rate,FRR)和错误接受率(False acceptance rate,FAR)相等时的数值。EER 是衡量生物识别系统性能的重要指标,能够同时反映出系统的安全性和准确性[19]。FRR、FAR、EER 的计算表示为
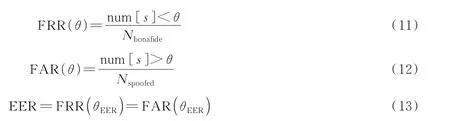
式中:Nbonafide、Nspoofed分别表示真语音的总数及假语音的总数;num [s]<θ 表示攻击样本中得分小于θ的数量;num [s]>θ表示攻击样本中得分大于θ的数量。当EER 数值越小,反映其系统性能越好。
AUC(Area under the curve)是机器学习常用的二分类评测手段,指的是ROC(Receiver operating characteristic)曲线下的面积[20]。ROC 曲线通过真正例率与假正例率两项指标,可以用来评估分类模型的性能。AUC 的计算公式为
式中:ranki代表第i条样本的序号;M、N分别代表正样本的个数和负样本的个数。ROC 曲线下的面积介于0.1 和1 之间;AUC 越接近于1 说明模型越好。
2.3 特征提取
本文选取梅尔频率倒谱系数(Mel-frequency cepstral coefficients,MFCC)作为训练神经网络特征。MFCC 考虑了人耳对不同频率的感受程度[21],在语音信号处理领域应用广泛,其提取过程如图4所示。
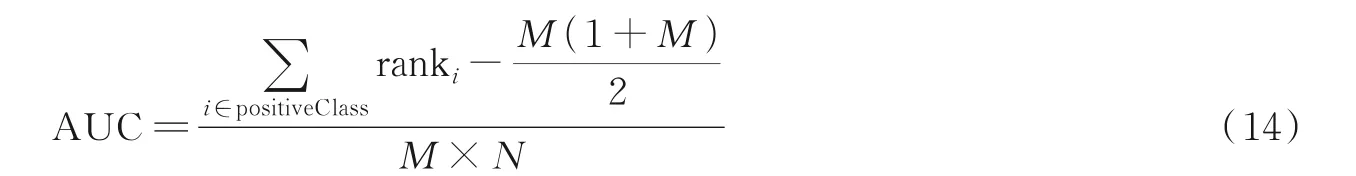

图4 MFCC 提取过程Fig.4 MFCC extraction process
3 逻辑访问攻击检测实验
3.1 实验环境
本文基于Ubuntu18.04.4LTS 系统,使用Jupyter Notebook 软件运行环境,Tensorflow2.2 框架,硬件配置采用Intel Xeon(R)Gold 6132 CPU 处理器,NVIDIA Tesla P4 显卡。
3.2 数据库
本文针对语音合成及语音转换两种语音逻辑访问攻击的欺骗方法进行检验,采用ASV spoof 2019数据集中的LA 数据库。该数据库是基于VCTK 数据库进行开发的,划分为3 个子集:训练集、开发集和验证集,本文采用训练集进行实验。训练集由20 名(8 男12 女)不同说话人组成,采样率为16 kHz,共计23 580 个音频文件。提取MFCC 特征后从特征集中随机选取60%(25 345 个)特征数据作为本次实验的训练集,20%(8 449 个)特征数据作为本次实验的验证集,20%(8 449 个)特征数据作为本次实验的测试集。
3.3 实验参数设置
实验中提取MFCC 作为训练神经网络的语音特征。在语音提取过程中,MFCC 的特征维度设置为20 维,选择二维离散余弦变换,每50 帧语音为特征长度组成1 个序列。
在神经网络模型的选择上采用GRU、LSTM 和LSTM-GRU 混合模型分别对提取到的MFCC 特征进行对比实验。实验控制单一变量,LSTM-GRU 设置的网络参数及结构如表1 所示。设置的LSTM-GRU 网络第1 层为LSTM 层,具有64 个隐藏节点,输入数据的维度为20 维;第2 层为具有128个隐藏节点的GRU 层,用来将信息传递到下一层,激活函数为Relu;第3 层使用了Dropout,随机丢弃50%用来防止过拟合;第5 层为Batch normalization,减少网络计算量使其学习率更稳定地进行梯度传播;第5 层为全连接层,含有128 个隐藏节点;第6层为分类层,激活函数为softmax。网络的迭代周期分别设置为400、1 000,batch-size 对应分别设置为128、256,即网络一次训练128 或256 个数据。学习率的设定使用指数衰减法,初始学习率设置为0.01,衰减系数为0.96,衰减速度为100,优化器使用adam ,通过梯度衰减学习率可以使模型更稳定运行。
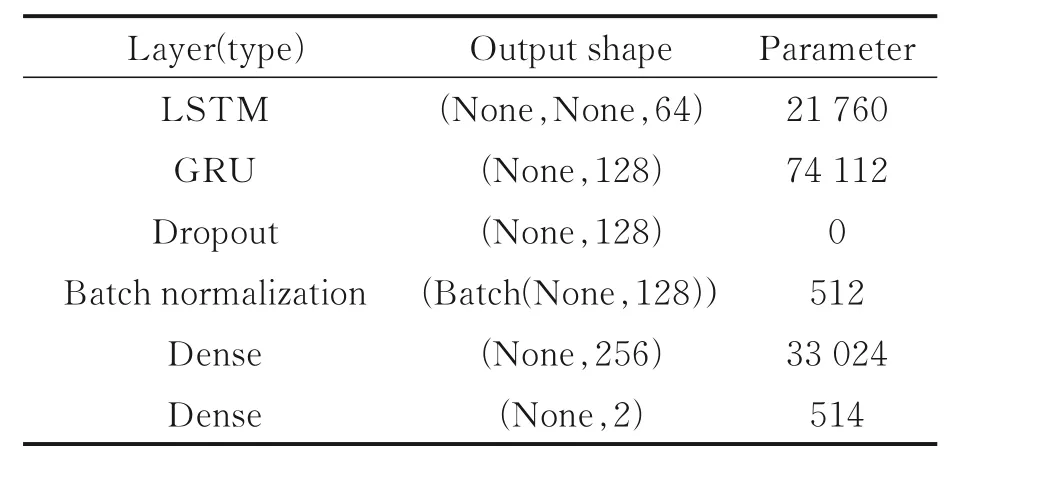
表1 LSTM-GRU 网络结构参数Table 1 LSTM-GRU network structure parameters
3.4 实验结果及分析
GRU、LSTM 及LSTM-GRU 三种网络模型分别在训练周期为400、1 000 下对提取到的MFCC 特征训练结果如表2、3 所示。结果分析所用评价指标为EER、AUC 和准确度。
由表2、3 可以看出,在准确度上3 种模型均有不错的效果,其中LSTM-GRU 模型所达到的准确度最高分别为98.12%和97.96%;在AUC 指标上LSTM-GRU 表现也超过GRU 和LSTM。在等错误率表现上LSTM-GRU 网络模型最低,表现最优分别为5.9%和7.1%。通过比较这3 种模型的各项评判指标可以发现,训练周期为400 时,三者都比ASV2019 挑战赛所提供的基线系统EER=8.09%要低。其中GRU 比基线系统低17.18%;LSTM 比基线系统低17.18%;LSTM-GRU 比基线系统低27.07%。训练周期为1 000 时GRU 比基线系统低3.58%;LSTM 表现较差;LSTM-GRU 比基线系统低12.2%。由此可以得出在GRU、LSTM 和LSTM-GRU 三种网络中LSTM-GRU 网络表现最佳。
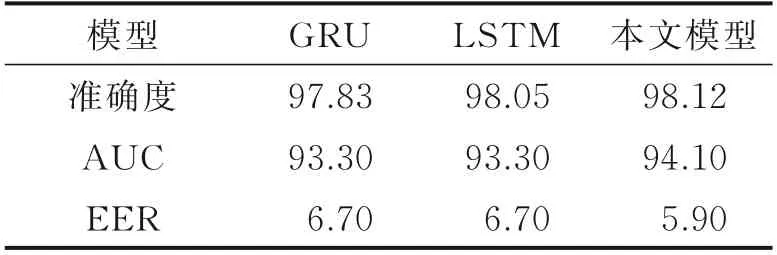
表2 训练周期400 下3 种模型实验结果Table 2 Experimental results of three models under 400 epochs%
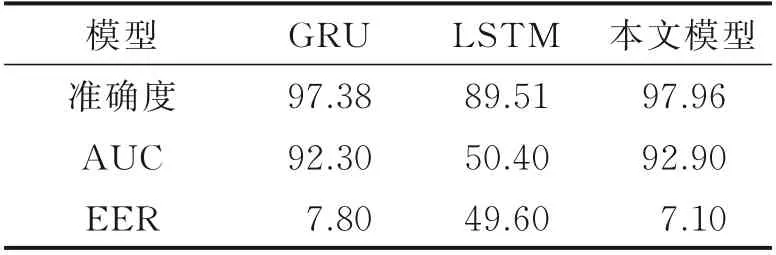
表3 训练周期1 000 下3 种模型实验结果Table 3 Experimental results of three models under 1 000 epochs%
比较两种周期对3 种模型的结果影响可以发现:在周期为400 时GRU、LSTM 及LSTM-GRU 这3种网络模型的结果均比周期为1 000 条件下的要好。训练周期为400 下的GRU、LSTM-GRU 的等错误率分别比训练周期为1 000 的等错误率低14.1%、16.9%。可以看出这3 种模型在相对较小的训练周期下能够达到更好的训练结果。
在训练周期为400 次时GRU 和LSTM 的表现相近,LSTM 网络在准确度上比GRU 略高,LSTM-GRU 网络较前两者的表现都更加优秀,等错误率比前两者分别低11.94%、11.94%,AUC 指标分别比前两者高0.85%和0.85%。在训练周期为1 000 时LSTM 表现差,准确率低,AUC 为50.4%,EER 为49.6%并出现过拟合的现象。而GRU 及LSTM-GRU 均表现稳定且LSTM-GRU 性能优于GRU,EER 比GRU 低8.97%,AUC 比GRU 高0.65%。在进行周期长、数据多的情况下,LSTM-GRU比GRU、LSTM 表现都更好,其稳定性好,准确度高。
图5 为2×2 的混淆矩阵,能够清晰地显示LSTM-GRU 对真假语音的区分准确率。纵坐标表示真实标签,横坐标表示预测标签。图中数值表示预测值被归为某一类的比例,位于对角线上的数值越大表示有越多的序列被正确归类。图中所示:欺骗语音有99%被正确归类,真实语音有89%被正确归类,有0.01%的欺骗语音和11%的真实语音被错误分类。
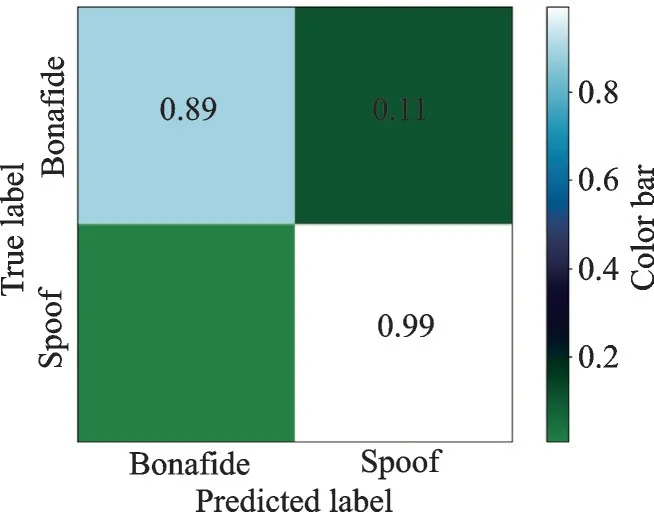
图5 混淆矩阵Fig.5 Confusion matrix
图6、7 为LSTM-GRU 网络模型、周期为400 训练过程的识别准确度变化曲线及损失大小变化曲线,为每次处理完128 个数据的分类准确度及训练损失大小变化,得到交叉熵损失函数值。可以看出,在迭代50 个周期后,准确度变化曲线及损失大小变化曲线进入收敛状态,识别准确率训练集稳定在100%附近,测试集准确率稳定在98%附近。交叉熵损失函数值训练集稳定0%附近,测试集稳定在0.075%附近,测试结果准确率为98.12%。说明LSTM-GRU 网络对于欺骗语音检测具有良好的潜力,适用于大规模数据库,同时也反映出该网络模型不容易出现梯度爆炸或梯度消失具有稳定性。
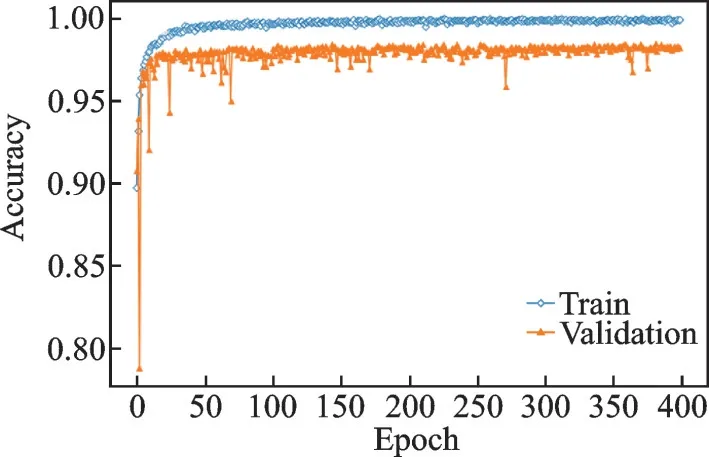
图6 训练过程中准确度变化曲线Fig.6 Accuracy curves during training
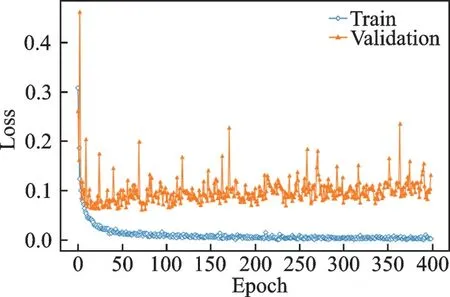
图7 训练过程中损失大小变化曲线Fig.7 Loss curves during training
在实际应用中模型的运算量及运算速度十分重要。为验证模型的快速准确性,在训练周期为400 下将3 种模型的参数量、训练速度及测试所用时长进行比较。每次调用程序前在终端使用kill PID 命令释放GPU 内存保证运行环境一致,同时网络参数设置不变保证变量唯一,实验结果如表4 所示。
由表4 可看出本文模型的参数量和训练每个周期所费时长均介于GRU 和LSTM 网络之间,说明本文方法的运算量和损耗时间处于合理范围内,在应用模型进行真假语音分类过程中本文模型耗时最短。综上所述,本文提出的融合LSTM-GRU 网络在语音逻辑访问攻击检测任务中能够快速准确地识别伪造语音。
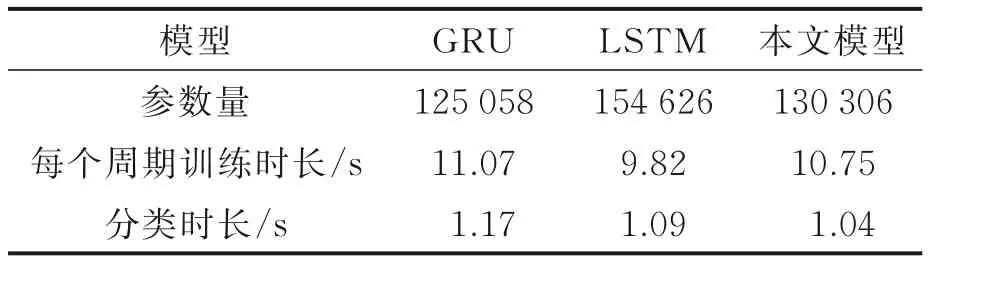
表4 训练周期400 下3 种模型运算性能比较Table 4 Comparison of operation performance of three models under 400 epochs
4 结束语
本文提出了一种融合LSTM-GRU 网络的语音逻辑访问攻击检测方法。通过比较GRU、LSTM 与LSTM-GRU 这3 种网络模型在ASVspoof2019 逻辑访问数据库上的表现可见,基于LSTM-GRU 网络的等错误率在设置的两种实验条件下分别为5.9%、7.1%,准确度分别为98.12%、97.96%,在3 种网络模型中表现最好。实验中设置训练周期分别为400 和1 000,通过比较3 种模型在相对长训练周期下的表现,发现LSTM-GRU 抗过拟合性强、准确率高。比较3 种网络的运算性能并结合LSTM-GRU 模型的训练情况,发现该网络模型不容易出现梯度爆炸或梯度消失,具有良好的稳定性,能够快速准确地对真假语音进行分类,可适用于大规模数据库。LSTM-GRU 网络可为语音逻辑访问攻击检测提供新的方法。
