一种基于多维度图神经网络的短文本分类方法
2022-04-14李书彬周安民
李书彬,周安民
(四川大学网络空间安全学院,成都 610200)
0 引言
近年来,由于互联网的快速发展和人工智能的快速兴起,在科研领域中使用深度学习方法来处理文本分类问题变得十分有效,文本分类问题作为自然语言处理领域的一个重要分支,在信息检索、情感分析、异常检测等方面得到了广泛的应用,随着微博、贴吧、论坛等网络社交媒体的出现,中文短文本广泛出现于各种应用程序中。不同于长文本,中文短文本具有歧义多、信息量小、特征稀疏等特点,传统的用于处理长文本的深度学习模型如卷积神经网络(CNN)、长短期记忆网络(LSTM)等模型应用于短文本时难以提取出有效的特征进而导致难以获得较好的分类效果。如何有效地对中文短文本进行建模并提高分类模型的准确率成为了中文文本分类领域的重要研究内容。
在传统的基于数据特征的机器学习方法中,模型分类的效果很大程度上依赖于所提取的特征,特征的提取需要花费大量的人力和时间,且提取出的特征仅包含人为可辨的特征,那些人力难以提取却又十分重要的深度语义特征和隐藏特征会大量丢失,严重影响检测效果。另外,当面对不具有已提取特征的新文本时,已建立的分类模型往往不能取得令人满意的分类效果。
基于深度学习的文本分类技术可以有效的解决以上问题,在面对文本分类任务时,为了使得文本特征易于被模型提取分析,研究人员往往会采用词嵌入技术来对文本进行建模,解决了人工提取特征时文本深度语义特征以及隐藏特征提取不充分的问题。使用CNN对中文文本进行分类时,可以通过调节卷积核的大小来对不同范围内的词向量模型进行特征提取进而进行分析和分类;使用LSTM对中文文本进行分类可以利用词之间的顺序关系抽取关键语义信息,解决了循环神经网络(RNN)中的梯度消失和梯度爆炸等问题,进一步提升了文本分类的效果。但中文短文本不同于长文本,短文本具有歧义多、信息量小、特征稀疏等特点,无论是CNN还是LSTM在面对短文本时都难以获得较好的分类效果。
为了解决以上问题,本文提出了一种基于多维度图神经网络的中文短文本分类方法,通过对文本中词向量的抽取,从多个维度对短文本信息进行建模以达到提取深度语义特征以及隐藏语义特征的目的,进而提高中文短文本分类的准确度和检测效率。
1 模型整体框架及方法
传统的图神经网络中相邻两个结点之间的关系通过相连的边进行体现,一条边连接特定的两个结点,利用边的数据信息以及结点中包含的信息进行聚合来生成新的结点表示。本文提出的多维度图神经网络分别通过文档中文档级别词语出现频率情况和文档中词句关系以及文档主题词间关系进行建模。整个模型主要有数据预处理,语义特征建模及融合,模型计算方法及分类三个部分组成。
1.1 数据预处理
中文文本不像英文文本中两单词由空格隔开,中文文本中的词而是紧密相连的,所以对文本首先要进行分词处理,并去除起连接作用的停用词,如虚词、语气词等没有实际意义的词。数据预处理中最重要一个环节就是文档中词的特征表示,为了能够较为完整地表示出文档中词的特征属性,我们采用Word2Vec来进行词的特征表示,Word2Vec是一种轻量级的神经网络,其结构包括输入层,隐藏层和输出层,模型框架分为CBOW模型和Skip-Gram模型,CBOW模型是在已知词w上下文w,w,w,w的情况下根据上下文对当前词w进行预测,不同于CBOW模型,Skip-Gram模型是已知词w的情况下对w的上下文w,w,w,w进行预测,文档包含个句子,其表示形式为={,,,…,s},其中代表文档中句子的数量,s表示第个句子。句子被分词后可得到={,,,…,w},其中为句子中词的数量,w表示第个词,w所表示的特征向量长度为。
1.2 语义特征建模及融合
我们定义一个文档的拓扑图为=(,),其中={,,,…,n}代表拓扑图中的结点,n表示文档中第个结点,={,,,…,l}代表拓扑图中的边,l表示文档中第条边。对于一个文档,其中结点代表文档中的词,为了能提取到文档中的深度语义特征,我们采用了以下三个维度对文档的边进行定义。
为了能完整表示出一个文档中的逻辑结构,覆盖到文本全部的语义信息及上下文信息,我们首先使用序列边将文档中每一句话中各词进行连接,文档中每一句话的拓扑图综合构成整个文档的拓扑图。整个文档的拓扑图={,,,…,g},其中代表文档中句子的拓扑结构,g表示第个句子的拓扑结构。
词频统计是自然语言处理领域中一个重要技术手段,一个词语在一篇文档中出现次数越多并且在其他文档中出现次数越少则该词越能代表该文档,信息熵和词概率等均是词频的映射变换,其实质均与词频统计相同。对于一个文档,去除没有实际意义的停用词后,当一个词在文档中出现的频次较多且在整个语料库中出现频次较少,说明该词所包含的信息对于文档较重要,则可以作为文档区分于其他文档的关键词之一。我们使用词频-逆文本频率指数(TF-IDF)来对文档中的关键词进行词频统计和重要程度分析,TF-IDF由TF(term frequency)和IDF(inverse document frequency)两 个 组 成部分。
TF表示词频,当一个词在一篇文档中出现的次数较多,则代表该词在该文档中比较重要,可作为该篇文档的关键词之一,如公式(1)所示:

其中n代表词在文档中出现的频次,n代表文档中的词语个数。
IDF表示逆文本频率,当一个词在一篇文档中出现次数较多,且在语料库中其他文档里出现次数较少,则该词呈现出较高的区分文档的能力,就将该词作为该文档区分其他文档的关键词之一,如公式(2)所示:
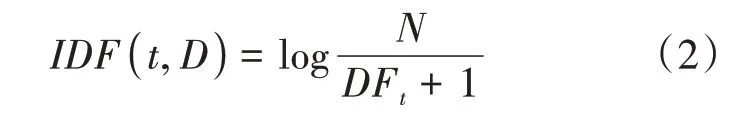
其中为语料库中文档总数,DF为词在所有文档中的出现频次。
得到文档中词的和的值之后,可以计算该词的权重值,具体计算公式如(3)所示:
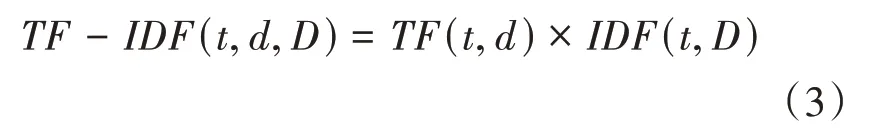
我们可以得到文档中各词的权重值={,,…,θ},其中θ表示第个词的权重值,选取每个文档中权重值最大的前个词作为可代表该文档区别于语料库中其他文档的关键词,我们将这前个结点相连作为该文档的词频边来代表该文档的词频关系。
为了丰富文档中的语义信息,我们将主题模型融入到拓扑图建模的过程中,我们使用三层贝叶斯模型(LDA)提取每个文档中的前个最能体现文档中心观点的主题词,并将这些词相连作为能够体现文档深度语义信息的拓扑模型,主题模型能够发掘出文档中的抽象主题,进一步丰富拓扑模型中的语义特征。
得到以上三个维度的文档拓扑图后,将三个拓扑图进行融合,得到最终的文档的拓扑图,该拓扑图不仅包括句子的序列上下文关系和高频词来区别其他文档,而且还有主题词边来体现文档的主旨。模型结构如图1所示。

图1 多维度图神经网络模型结构
1.3 模型计算方法


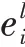

拓扑图中的结点和边经过层的融合计算,得到各个结点的最终特征信息,使用平均池化的方法对结点特征信息进行处理得到整个文档的特征信息,最后使用softmax分类函数来对文档的标签即所属类别进行预测,如公式(7)所示:
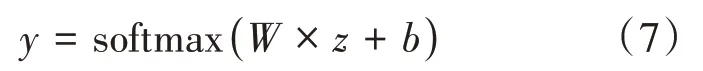
其中为权重矩阵,为偏置量,为文档的特征表示,为预测的分数。
2 实验部分
2.1 实验环境
本文使用Python作为基础编程语言,并基于PyTorch框架搭建图神经网络模型,表1展示了详细实验环境数据:

表1 实验环境概述
2.2 实验数据
为了更好地对模型的性能进行评估,本文选取了三个公开的中文数据集对模型的可行性和有效性进行了验证。

表2 数据集概述
2.3 实验结果
本文选取了CNN和双向长短期记忆网络(Bi-LSTM)两个分类模型分别在今日头条新闻、waimai_10k和dmsc_v2三个数据集上进行试验,实验结果通过精确率(Precision)、召回率(Recall)和F1分数三个评价指标对不同模型的性能进行评估,实验结果如表3、表4、表5所示。结果表明,多维度图神经网络无论是在今日头条新闻数据集还是在waimai_10k和dmsc_v2数据集上与其他两个模型相比各项指标均为最优,呈现出更准确的分类效果。
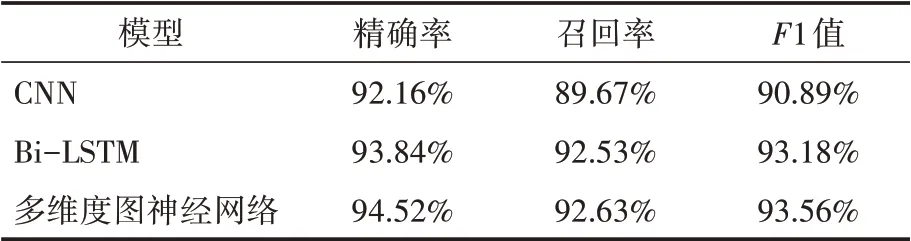
表3 今日头条新闻数据集上不同模型性能比较
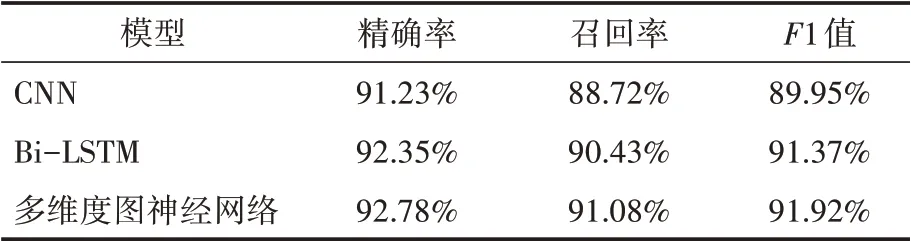
表4 waimai_10k数据集上不同模型性能比较

表5 dmsc_v2数据集上不同模型性能比较
3 结语
文本分类是自然语言处理的重要领域之一,为了能获取到中文短文本中的隐藏语义信息,本文提出了一种基于多维度图神经网络模型的文本分类方法,通过序列边、词频边和主题边三个维度对本文信息进行建模并进行分类。相较于目前先进的模型分类方法,多维度图神经网络在精确率和召回率等指标上有明显提升,可以获得更为准确的分类效果。未来将在模型处理上加入注意力机制来进一步提高分类的准确性以达到高精度处理中文文本分类的目的。
