基于CaffeNet的工业瓶口缺陷检测
2022-04-14张卫华周激流
张 良,张卫华,周激流
(1.四川大学电子信息学院,成都 610065;2.四川大学计算机学院,成都 610065)
0 引言
在药瓶产品生产过程中,瓶口容易发生破碎。破碎后的药瓶不能用以存储药品(图1),因此,对瓶口进行缺陷检测是一个非常重要的环节。在对药瓶进行缺陷检测的过程中,需要对药瓶进行分类,筛选出有缺陷的瓶口;而在传统的工业生产过程中,大部分还在使用人工筛选,筛选的速度和质量都与人疲劳程度相关联,无法满足工业自动化和智能化要求。随着计算机技术以及存储器的高速发展,利用深度学习的方法进行药瓶瓶口缺陷检测已经被大规模的应用于生产之中。
深度学习在最近十年里高速发展,在计算机视觉领域、自然语言处理领域、语音识别领域以及生物医学相关领域都取得了较为显著的成果,并逐步应用于工业生产和日常生活中;使用深度学习对工业产品的缺陷检测也逐渐成为一种主流的方式。周显恩提出一种基于改进测地线距离变换与模板匹配的瓶底缺陷检测方法,该算法能够对瓶口缺陷进行全面的检测,但对图像本身的质量要求较高;罗时光以瓶口的周长、圆形度和相对圆心距为特征,使用卷积神经网络对瓶口缺陷进行识别,达到了较好的检测效果;张帅使用了两种卷积神经网络对瓶口缺陷进行分类,在其给定实验条件下准确率达到了95%,能够较好的完成对缺陷瓶口的分类。总体而言,深度学习能够有效地提高缺陷检测的效率,推动瓶口检测智能化发展,被越来越多的应用于瓶口缺陷检测当中。
卷积神经网络能够有效地提取图像特征,对给定的图像进行正确分类,从而达到缺陷检测的目标;CaffeNet是一种较为常见的卷积神经网络,其是由五个卷积层、三个全连接层构成,能够有效地提取图像高维特征。本文主要是使用调整后的CaffeNet对工业生产中的药瓶瓶口进行检测,测试条件为CPU、GTX 1060 Mo⁃bile、GTX Titan X Pascal和华为Atlas200DK,通过对比在同一权重文件下对同一测试数据集进行识别所需要的功耗,以探求一种低功耗、高效率瓶口缺陷检测方法。
1 实验部分
1.1 实验样本
由于当前还不存在一个完整适用于瓶口缺陷检测的数据集,根据药瓶生产过程瓶口完整状态进行分类,本文主要区别完整瓶口和缺陷瓶口两种,创建了一个瓶口数据集,其中完整瓶口数量为300张,缺陷瓶口数量为300张,共600张瓶口样本图片,瓶口样本来自于实际工业生产。由于陶瓷瓶口表面具有一定的反光性,完整瓶口之间的区分度微小,缺陷瓶口之间的差别较大,在拍摄时应采用较高分辨率工业相机进行拍摄以保留瓶口特征并减少图像背景的影响,因此需要选择合适亮度的环状光源对药瓶瓶口进行拍摄,具体见图1所示。

图1 完整药瓶、瓶口和缺陷药瓶、瓶口示例
1.2 网络模型搭建
卷积神经网络本质上是求在满足给定输入和输出的情况下各个神经网络层上的权重参数信息,在整个模型输入交叉熵损失最小时,求得权重文件;卷积神经网络具有极强的泛化能力,能够提取到图像高维特征,可以提取到迷糊、失真图片的特征。一般而言,常见神经网络含有两个或以上的卷积层、两个及以上的池化层以及一个全连接层。本文所采用的的网络是CaffeNet,CaffeNet是AlexNet的在深度学习框架caffe中的实现版本,AlexNet在2012年ImageNet竞赛中获得冠军,top-5的错误率达到17.0%,其在常规的图像分类任务上达到了较高的准确率,对神经网络的发展奠定了十分重要的发展基础,在实际问题中的应用较为广泛,CaffeNet在具体的网络结构实现上与AlexNet有部分差异,为了达到本实验分类任务的要求,具体的网络结构结构、参数设置详见下文介绍。
本文所使用的网络结构沿用了CaffeNet的总体框架,包含五个卷积层、三个全连接层,其中每一个卷积层中使用Relu作为激活函数,Relu激活函数相比于Sigmoid和tanh能够加速网络收敛的速度,相比于AlexNet第一个卷积层、第二个卷积层以及第五个卷积层后面有池化层,池化层位于局部相应归一化层之前,池化层采用的是最大池化,使用最大池化能够在保持图像原有特征的基础上有效地降低整个网络的参数数量,具体网络各层参数如表1:
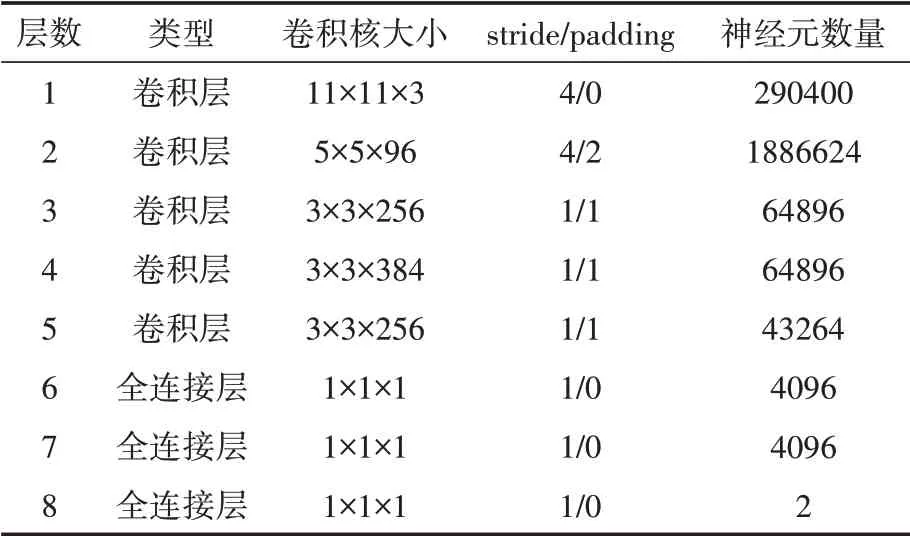
表1 网络各层参数
在上述表格中未对第一、二、五卷积层后池化层的卷积核等参数进行详细介绍,详细可参照图2所示具体网络结构。
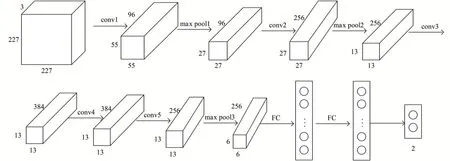
图2 本文网络结构
为了提高对缺陷瓶口的识别准确率,需要对图中第八层做出相应的修改。在本实验的条件下,样本分为两类,一类是缺陷品,另一类是正样本。因此对于最后一层输出神经元个数为2,为了提高模型的泛化能力以及整体网络识别的准确率与鲁棒性,在第六层卷积层和第七层卷积层上使用dropout方法,dropout参数设置为0.5。同时设置本网络的初始化学习速率为0.001,训练集样本批次为20,验证集批次为50,整个网络的最大迭代次数为500,在训练的过程中采用随机梯度下降法训练网络,最大迭代次数为500次,每一层的初始学习速率设置为0.001,每次迭代训练样本数量为64张图片,初始动量设置为0.9,更新权重过程中权重衰减系数为0.0005,且权重更新规则如下:
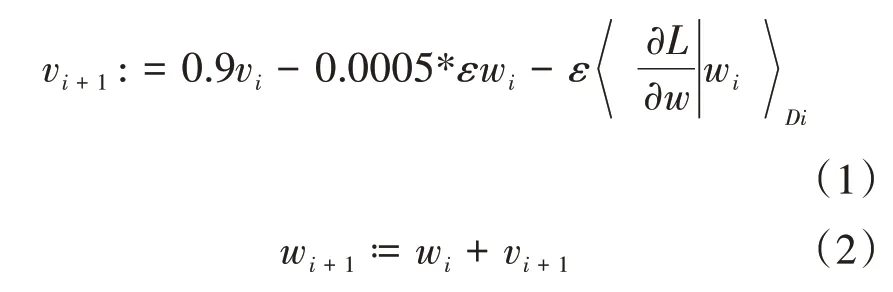
其中代表迭代次数,代表动量参数,代表学习速率,是指在批次训练过程中损失函数对权重进行求偏导,使用均值为0、方差为0.01高斯分布正态曲线对权重进行初始化,第一、三、八层初始偏置设置为0,第二、四、五、六、七层初始偏置设置为1。关键参数设置情况见表2。

表2 网络初始参数
损失函数的大小直接和网络的泛化能力相关。在通常情况下,网络的损失函数越小,网络分类的准确率越高,即网络分类结果就越符合实际工业生产分类的实际。因此,本文采用随机梯度下降法以优化本网络的损失函数,损失函数表示为:

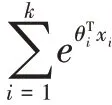
1.3 实验具体流程
本实验主要是使用Python与C++实现,主要环境是Ubuntu18.04内存32 G、显存为12 G的GTX Titan X Pascal显卡、显存为6G的GTX 1060 Mobile显卡以及华为Atlas200DK。At⁃las200DK全称为Atlas 200 Developer Kit,可作为边缘设备使用,主要包含Atlas 200 DK AI加速模块、图像音频接口芯片(Hi3559C)和LAN SWITCH三个模块,其AI加速模块可以加深度学习的推理速度。实验第一步需要在GPU支持下对数据进行训练,第二步需要测试和计算在使用CPU、GTX Titan X Pascal、GTX 1060 Mo⁃bile以及Atlas200DK的情况下所需要的功耗和时间。
对于本实验样本数据集,从中随机选取500张作为训练集,剩余的100张作为测试集,在制作两种数据集时对完整瓶口和缺陷瓶口进行随机打乱。具体的训练流程是首先从训练数据集读取一张图片输入到网络,通过网络的卷积层和池化层对输入图像的特征进行提取,之后通过三层全连接层对上层得到的图像特征进行集合输出,计算理想输出和实际出处之间的误差,在输出层无法得到理想的输出结果时,需要对损失函数进行优化,进入反向传播过程,更新各层的权重,直至损失函数的值达到全局最小或是为0可得到适合本样本的权重值;每训练50次对测试数据集进行测试一次,每进行一次测试,对测试的准确率进行输出打印并记录。最终测试数据集的准确率和loss图像如图3所示。
由图3可知,迭代次数超过400次之后,整个网络的训练损失和测试集的准确率逐渐平稳,在训练次数达到500次时,最终测得测试集的准确率为97%,训练损失趋于0.6左右,训练完成之后保存权重文件。
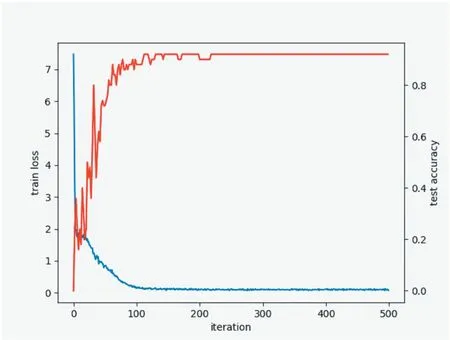
图3 训练损失和测试准确率曲线
1.4 对比实验
使用第二步中训练得到的权重文件,对给定测试数据集中的100张图片进行测试,在此过程之中需要设定的实验条件分别为:①使用CPU对给定的一百张图片进行推理。②使用GTX Titan X Pascal加速对给定的100张图片进行推理。③使用GTX 1060 Mobile加速对给定的100张图片进行推理。④使用Atlas 200 DK对给定的100张图片进行推理,在上述三种测试过程中需要记录相应推理时间、推理过程中设备的平均功率,其详细信息如表3和表4所示。
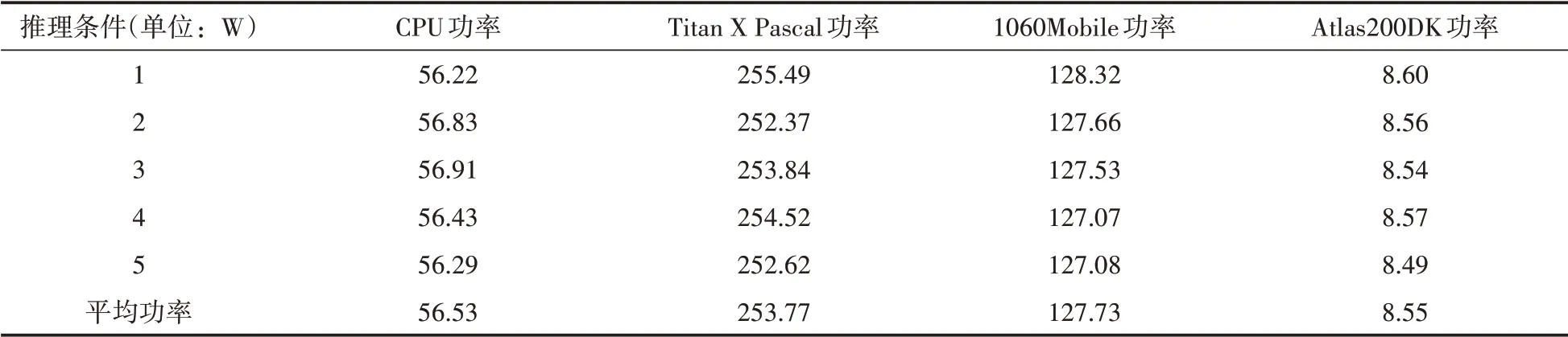
表3 推理100张样本所需功率
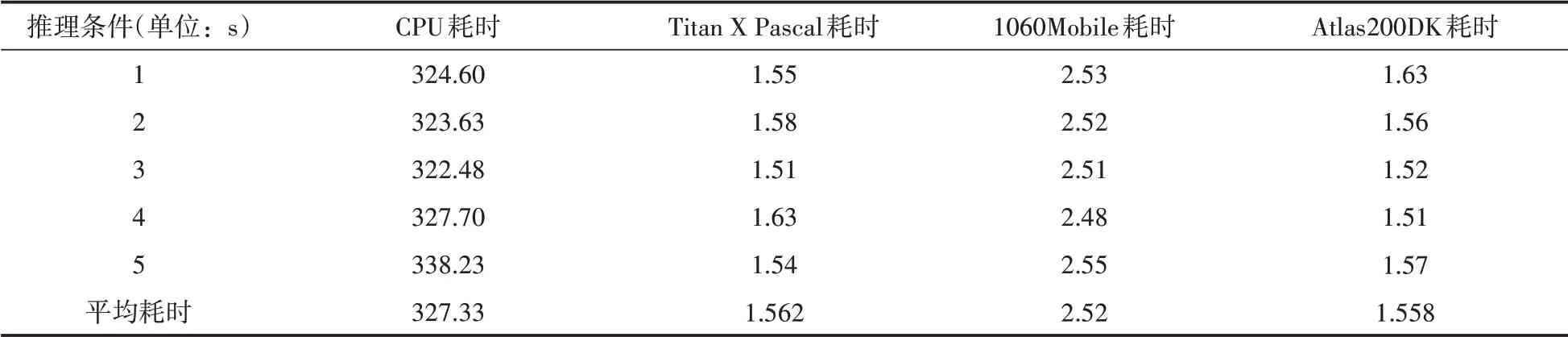
表4 推理100张样本所需时间
2 结果分析
从表格3中的数据分析,在使用CPU推理平均功率为56.53 W,在使用GTX 1060 Mobile推理平均功率为127.73 W,在使用GTX Titan X Pascal推理平均功率为253.77 W,使用At⁃las200DK推理平均功率为8.55 W,结合表4中的数据进行分析,在整个推理过程中其消耗的能量是最低的;从表格4中的数据分析,对于推理给定100张图片,在使用CPU推理所需时长为327.33 s,在使用GTX 1060 Mobile推理需要2.52 s,在使用GTX Titan X Pascal推理需要1.56 s,使用Atlas200DK推理需要1.558 s。该种结果表明使用GPU和NPU对推理具有极为显著的加速效果,缩短了推理所需时长。对于使用Atlas200DK进行推理加速的条件下,其在测试时间内的平均功率达到了最低值,结合表4中的推理时长进行判断,在三个测试方案中,使用NPU进行推理加速的情况下,所需要总能量达到最小,使用Atlas200DK进行推理加速达到了较为理想的实验效果,对于之后的应用实践达到了前提条件。
3 结语
根据样本瓶口之间差异性建立了600张含有缺陷瓶口和正样本的数据集;提出了一种基于卷积神经网络CaffeNet对瓶口进行识别分类的解决方案,通过神经网络的卷积层和池化层对瓶口特征进行识别提取,使用反向传播算法对隐含层的权值进行更新,随机梯度下降法对损失函数进行调优,得到权重文件;之后,分别使用CPU、GTX Titan X Pascal、GTX 1060 Mobile和Atlas200DK对测试数据集进行分类,最终四种测试方案所得准确率在97%,能够很好的区分出残次品,其中使用Atlas200DK推理100张测试图片所需时间最少、消耗能量最低。相较于使用CPU和GPU,使用Atlas200DK能够在最低的功耗下对样本瓶口分类有较高的检测效率,为了药瓶瓶口的缺陷检测提供了一种有效的方案。
