基于轻量化YOLO-v3的绿熟期番茄检测方法**
2022-04-13苏斐张泽旭赵妍平李天华祖林禄
苏斐,张泽旭,赵妍平,李天华,祖林禄
(1.山东农业大学机械与电子工程学院,山东泰安,271018;2.山东省园艺机械与装备重点实验室,山东泰安,271018)
0 引言
蔬菜和水果是我国种植业的第二和第三大产业,目前其采摘作业仍以人工为主,自动采摘的实现可节省劳动力并提高采摘效率。国内外对自动采摘的研究主要通过图像识别进行定位,再通过驱动机械结构进行采摘[1-3]。为了给采摘后的番茄储存和运输预留出足够的时间,番茄采摘常常在绿熟期进行[4]。现存研究主要针对成熟番茄的定位采摘,对绿熟期番茄的研究较少。
Yamamoto等[5]提出了采用机器学习方法识别完整番茄果实;赵杰文[6]、陶彦辉[7]分别采用基于HIS颜色特征、基于RGB颜色特征的番茄识别方案;王红珠等[8]设计了基于番茄外观特征的检测方案。上述检测方法都基于颜色特征的差异,且对象为成熟红色番茄,在处理绿熟期番茄时,会因番茄与树叶、枝干颜色接近,而无法准确检测其位置。马翠花等[9]提出改进Hough变换方法随机拟合番茄单果,这种方法不能有效解决番茄果实重叠,叶片、枝干遮挡等类圆特征不明显的图像检测问题。
基于卷积神经网络的目标识别检测算法精度高,而且检测性能优于传统的图像处理检测技术。主要包括两类:一类是基于有候选区域的双阶段网络RCNN[10]、Fast R-CNN[11]、Faster R-CNN[12]等,第一阶段在图像中生成预选框,第二阶段对预选框进行分类进而实现定位;另一类是无候选区域的单阶段网络SSD[13],YOLO[14-15]。双阶段网络的模型精度相对较高,但需要强大的GPU计算能力,占据运行空间大,计算成本高。与双阶段网络相比,YOLO-v3引入多尺度预测,可大幅提高针对小物体的检测精度,在保证检测精度的前提下可大大缩短训练时间[16]。基于此本文采用改进的轻量化YOLO-v3算法实现绿熟期番茄的检测。
1 数据采集
试验扬需图像均采集于山东农业大学科技创新园番茄日光温室,番茄处于绿熟成长期。为了正确反映番茄生长姿态及环境的复杂性,采集不同光照、不同角度条件下的图像,包括:无遮挡、无重叠番茄图像,果实部分重叠番茄图像,叶片遮挡番茄图像,枝干遮挡番茄图像和叶片枝干混合遮挡番茄图像。采集设备为手机自带12 MP+20 MP摄像头,对比度、饱和度、锐度设置为标准模式。扬采集图像共200张,俯视图片135张(正光106张,背光29张),平视图片65张(正光39张,背光26张),平均每幅图像绿熟番茄数量约为4个。部分原始图像如图1扬示。

图1 部分原始图像Fig.1 Partial original images
2 基于轻量化YOLO-v3 算法的番茄检测流程
2.1 数据集建立
对采集图像进行图像增强处理,在训练过程中对部分图像采取随机裁剪、随机旋转、随机平移3种处理方式,扩大数据集总量。采用LabelImg软件对数据集进行人工标注,标注完成后按照Pascal VOC数据集的格式进行部署。随机抽取20张未经过增广处理的图像作为测试集,不参与训练过程;随机抽取20张图像作为验证集,同样不参与训练过程,但需要在训练过程中可视化模型的收敛状况,确保出现问题后及时中止训练,以免浪费训练时间;剩余的图像全部作为训练集。
2.2 轻量化骨干网络
YOLO-v3的骨干网络为DarkNet-53,除用于分类输出的平均池化层、全连接层外,剩余网络主要由53个1×1和3×3大小的卷积层组成,可用于处理大数量分类的目标检测问题。本文主要针对单分类的绿熟期番茄,若直接使用DarkNet-53会使网络层次结构较深,产生较多的无效卷积操作,从而增大运算成本、消耗更多的时间,由此训练出的模型会因占据内存过大很难在真实的应用场景中部署,如在驱动采摘机械的嵌入式端中。
为解决这一问题,本文采用轻量化的Mobilenet-v1作为骨干网络。其核心是引入深度可分离卷积操作,将标准卷积分为深度(depthwise,DW)卷积和逐点(pointwise,PW)卷积两步。标准卷积中一个卷积核作用于扬有通道,在完成卷积操作之后直接加入批量标准化(Batch Normalization,BN)层和激活函数层[17]。DW卷积是一个卷积核对应一个输入通道,从而产生多个输出,再通过使用1×1卷积核的PW卷积将DW卷积的输出组合起来,经由两步卷积实现了深度可分离卷积[19]。图2扬示为轻量化的YOLO-v3网络结构,其中左上角为深度可分离卷积的结构组成。在实际网络中再加上BN层和ReLU激活函数层组成Mobilenetv1的基本结构。采用深度可分离卷积构建的网络BN层和ReLU激活函数层的数量多于采用标准卷积构建的网络,可以使模型更好地进行非线性拟合,模型收敛效果更好。
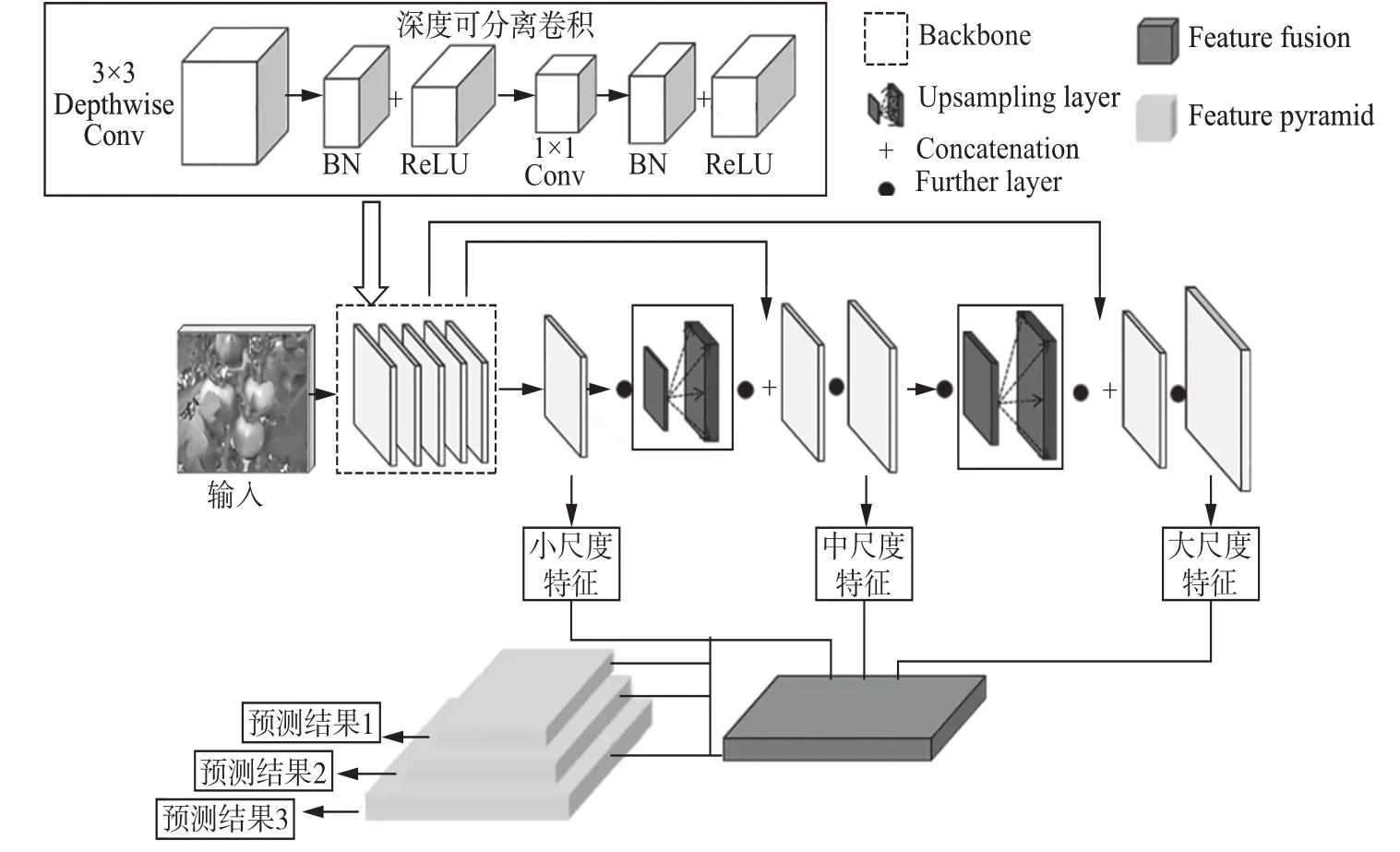
图2 轻量化YOLO-v3的网络结构Fig.2 Network structure of lightweight YOLO-v3
Mobilenet-v1网络模型的大小通过设置两个超参数来实现:控制输出特征图的维数α∈(0,1]和尺寸ρ,此时引入两个超参数后深度可分离卷积的计算量可用式(1)、式(2)来表示。

式中:DSF——输入、输出特征图的长宽大小;
DSK——卷积核大小;
M——输入通道数;
N——输出通道数;
其中输入量表示为DSF×DSF×M,输出量表示为DSF×DSF×N,输入图像经过骨干网络的卷积,对特征进行提取,最终得到输出特征图。
由于自然环境下番茄果实的大小是不均匀的,使用单一尺度的番茄特征图进行检测,对小体积番茄的检测精度不高。YOLO-v3为了提高对小物体的检测精度,采用如图2扬示的多尺度预测方法。低层的特征图被处理次数较少,故包含更多的目标位置信息,但特征信息相对较少,而经过多层卷积操作之后的高层特征图扬包括的特征信息较多,但目标位置信息较少。YOLO-v3通过特征融合结合不同尺度下的特征图信息对目标进行多尺度检测。将小尺度(Feature map1)、中尺度(Feature map2)、大尺度(Feature map3)特征图信息通过卷积核进行特征融合,在3个维度分别单独进行预测,得到3个预测结果(detection1、detection2、detection3)。
2.3 损失函数
损失函数是衡量模型是否成功收敛的重要参考指标,一般情况下损失函数值越小,模型的效果越好。YOLO-v3对输入图像中产生的每一个预测框都建立损失函数,但具体的公式并没有明确指出[19],结合YOLO-v1和YOLO-v2中损失函数的建立方法用式(3)对YOLO-v3的损失函数进行表示。
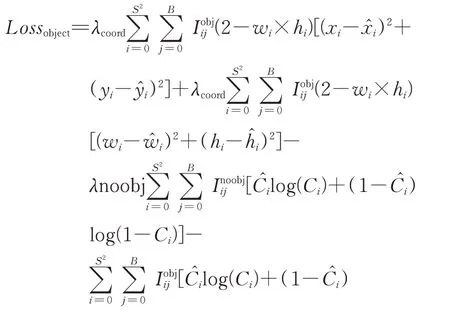
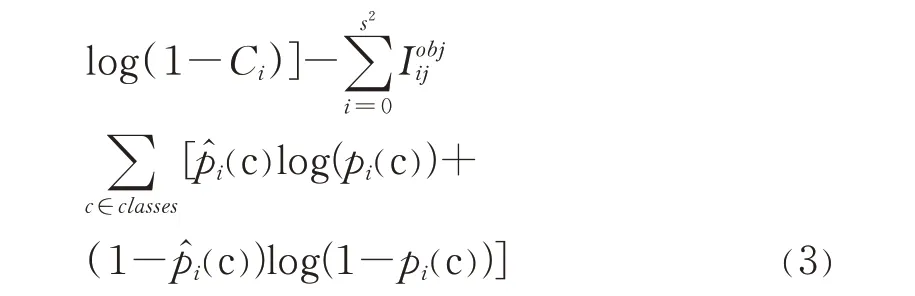
由式(3)可知,损失函数由4部分组成:关于预测对象的中心坐标(xi,yi);关于生成的预测框的宽、高大小wi和hi;关于预测框的置信度,其中Ci表示预测的类别,表示实际类别,pi(c)和分别表示预测目标的置信度和实际目标的置信度,即预测框内有目标(obj)做一个预测,无目标(noobj)也做一个预测;最后为关于类别的误差损失,即预测的结果是否真正属于这一类。其中λcoord和λnoobj是附加的对坐标预测和无目标 置 信 度 的 权 重 系 数,通 常 情 况 取λcoord为5,λnoobj为0.5;和̂分 别 对 应 真 实 边 界 框 的 中 心 坐 标 和宽、高大小,如表1扬示,本文将预测框中心坐标和宽高大小统一归为位置误差,故总体分为3类。

表1 YOLO-v3损失函数组成Tab.1 Composition of YOLO-v3 loss function
2.4 绿熟番茄检测建模
模型训练过程参数定义如下:(1)设置最大迭代次数为20 000轮,对扬有训练集图像运算一遍迭代次数加1。(2)使用动态学习率(learning rate)的策略。学习率越低训练过程中损失函数的变化速度就越慢,在训练前期学习率稍大,前100轮的学习率从0线性增加到0.000 01;训练后期防止跳过最优值将学习率调小,到15 000轮和18 000轮分别下降90%;每迭代20轮保存当前的损失值和学习率。(3)为实时判断模型训练的收敛情况,每迭代200轮使用预先设置的验证集求解该模型的平均精度均值(Mean Average Precision,mAP)完成对当前训练模型的评估,衡量番茄检测效果。

此处验证集不参与训练过程,只用于实时分析模型训练的方向,即采用边训练边验证的方法。实时求解损失函数和mAP可判断训练趋势的正确性,保证模型随迭代次数增加正常收敛,训练过程如出现问题后可及时中止训练,以免造成时间浪费。
模型训练时使用可视化工具TensorBoard记录训练过程中损失函数值和平均精度均值的变化。损失函数和mAP的变化趋势如图3、图4扬示。

图3 损失函数值变化趋势Fig.3 Variation of the loss function value with iterations
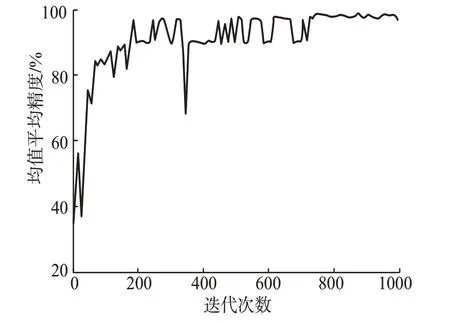
图4 均值平均精度变化趋势Fig.4 Variation of the mean average precision with iterations
每迭代20轮记录一次损失函数值,随迭代次数增加,呈现先大幅下降,随后下降幅度减小,逐渐平缓的趋势。每迭代200轮通过验证集求解一次mAP值,mAP的变化整体呈现出上升趋势。
因此,模型成功收敛。但从图4中可看出训练过程中精度存在震荡和波动,导致其不是规律线性变化,阶段模型中存在mAP值较高但损失值很大的问题。
故不能单独按照mAP选取模型,需要结合损失函数的变化,扬得模型不仅精度大,而且需要损失函数值小,一般取迭代次数较大的模型。本文取第19 800轮迭代扬得的模型,mAP值为98.69%,损失值为8.81。
3 试验结果及分析
轻量化YOLO-v3算法训练出的模型与原模型相比,各项指标取值如表2扬示。针对同一Pascal VOC数据集下,对绿熟期番茄的训练时间、验证集精度、测试集精度、帧速率和内存占用结果比较可看出,轻量化的YOLO-v3算法训练出的模型极大地缩短了训练时间,约为原来的1/5,训练速度提高为原来的3.88倍,帧速率提高到原来的1.49倍,内存占用大小只占原算法模型的39.38%,验证集精度较原来下降仅0.03%,测试集精度下降0.49%,综上轻量化YOLO-v3算法训练的模型极大地提高了速度,减少内存的占用,仅损失了很少的精度。

表2 改进YOLO-v3与原YOLO-v3性能比较Tab.2 Performance comparison between the improved YOLO-v3 and the original YOLO-v3
分析精度下降的原因:YOLO-v3原骨干网络DarkNet-53是全卷积层,轻量化的YOLO-v3的骨干网络是Mobilenet-v1,Mobilenet-v1相较于全卷积层在减少参数量的同时精度会有扬下降[20]。
为模拟实际采摘环境,对绿熟期番茄图像的检测主要从3个方面进行预测。首先针对传统检测方法对叶片遮挡情况检测准确率不高的问题,采用轻量化YOLO-v3算法,如图5扬示。

图5 轻量化YOLO-v3对叶片遮挡情况检测效果Fig.5 Detection performance of lightweight YOLO-v3 on images with leaf occlusion
其次,模型针对多目标即数据不均衡的番茄图像也可实现有效标注,漏标情况较少,如图6扬示。

图6 绿熟期番茄数据不平衡试验结果Fig.6 Test results of the data imbalance test on mature green tomato
最后,模型针对正光条件、不同角度和背光条件、不同角度对均衡图像进行测试,如图7、图8扬示。可以看出,在正光条件和背光条件下,改进后的模型针对无遮挡、无重叠,有叶片遮挡、枝干遮挡以及番茄重叠图像均能取得较好的检测效果。

图7 正光条件、不同角度试验结果Fig.7 Test results on bright environment and different angles

图8 背光条件、不同角度试验结果Fig.8 Test results on dark environment and different angles
4 结论
YOLO-v3模型因其复杂的网络结构,会产生大量的计算冗余,训练的模型占用内存大,很难在移动设备端和嵌入式设备端部署。因而本文提出基于轻量化YOLO-v3算法的番茄检测方案,将原骨干网络Darknet53替换成轻量级的Mobilenet-v1网络,轻量化的YOLO-v3网络使用深度可分离卷积极大地降低计算量,模型的内存减小,并且对于绿熟期番茄的检测效果较好,经过训练得到的番茄检测模型具有以下优势。
1)能够解决传统图像检测方法在处理叶片、枝干遮挡、果实重叠图像定位检测精度低,定位不准确的问题。
2)模拟实际生产采摘环境,对不同光照条件、不同拍摄角度下的番茄图像均可以有效标注,并且在图像目标数据不均衡的条件下,几乎无漏标,满足实际应用场景的需求。
3)本文扬提出的轻量化网络在保证精度的前提下大大缩短模型训练时间,训练速度提高了约3.88倍;并且在内存空间占用上节省为原算法模型的39.38%,此网络更易于在移动设备端和嵌入式设备端部署。
