基于注意力机制的弱监督动作定位方法
2022-04-12华钢
胡 聪,华钢
(中国矿业大学信息与控制工程学院,江苏徐州 221116)
0 引言
在当今的信息化时代,随着大数据的发展和科技的进步,视频数据量呈现井喷式增长,传统的人工动作定位已经很难满足信息化时代中对视频分析和处理的需求,因此,近年来,深度学习模式下的视频动作定位逐渐成为许多学者着重研究的方向[1-3]。动作定位的实质是获取视频中可能存在的动作的开始和结束的时间,并对获取的动作片段进行分类。动作定位技术的应用可以使人们有效地对若干视频片段进行查找。
深度学习模式下的视频动作定位方法主要分为强监督动作定位方法[4-6]和弱监督动作定位方法[7-9]。强监督动作定位方法需要采用帧级标签(即预先准备好的视频每一帧的类别标签)进行动作定位,在训练过程中,利用帧级标签能够实现帧对帧的校准,从而得到较为精准的候选动作片段,定位准确性较高;然而,对于大规模、长时间的视频,很难高效、准确地对视频每一帧预标注标签,且获取大规模的帧级标签需要花费大量的人力和时间,因此,针对大规模、长时间的视频进行动作定位,只能采用基于视频级标签(即视频片段的类别标签)的弱监督动作定位方法。弱监督动作定位方法虽然不依赖帧级标签,但是无法实现帧对帧的校准,定位准确性相对较低,因此,为了提升弱监督动作定位的准确性,本文提出了一种基于注意力机制的弱监督动作定位方法。
注意力机制是一种通过模仿人脑,关注任务中的关键信息,从而实现对信息的合理分配和利用,以提高工作效率的方法。近年来,基于注意力机制的方法被广泛应用于动作定位的研究[10-12]中。基于注意力机制的弱监督动作定位方法主要分为两种:第一种是从上到下的方法,首先训练一个视频分类器,将原始视频数据送入视频分类器,得到视频的时序动作分类分布图,即TCAM(Temporal Class Action Map)[13];然后利用每个片段的TCAM 获取动作提议片段,进而进行动作定位[13-14]。第二种方法是从下到上的方法,先利用原始视频数据生成帧级注意力值;然后训练和优化帧级注意力值。对于某个动作类别,帧级注意力值较高的帧被认为是动作帧,否则是背景帧。根据帧级注意力值得到动作提议片段,以对视频进行动作定位[15-17]。
尽管弱监督动作定位方法能够摆脱对帧级标签的依赖,其也存在以下的两个问题:其一,由于缺少帧级标签,若只根据注意力值进行动作定位,没有考虑到相邻帧之间可能存在相关性,可能导致出现信息丢失的问题。例如,对于动作“跳”,包含准备、跳、落地、恢复四个过程,其中准备和恢复过程在动作定位时对于跳的注意力值可能偏低,从而在定位时可能过滤到这两个部分,导致在弱监督动作定位过程中常会出现动作漏检的问题。其二,由于缺少帧级标签,弱监督动作定位常会出现动作和背景混淆的问题,将背景误识别为动作,进而影响动作定位的精确性。
针对上述问题,本文对基于注意力机制的弱监督动作定位方法进行了研究。为了减少动作定位时可能出现的遗漏,本文采用条件变分自编码器(Conditional Variational AutoEncoder,CVAE)[18]注意力值生成模型,并在此基础上加入了动作前后帧信息。参考语义理解领域中的Transformer模型[19-20],将前后帧的特征及当前帧的特征进行位置编码后,进而得到加入动作前后帧信息的视频特征;然后将视频特征送入CVAE 生成模型中的编解码器,得到加入前后帧信息的帧级注意力值。同时,为了使得注意力值对于动作的类别有出色的区分能力,本文提出基于区分函数的注意力值优化模型,结合TCAM[21-22],构建区分函数,以优化注意力值的分布,提升注意力值的分类能力。最后,经过训练和优化后,得到每一帧的帧级注意力值,作为视频的伪帧级标签,并基于帧级注意力值构建动作定位模型,以得到动作的时序位置。本文在THUMOS14 和ActivityNet1.2 数据集上取得了较好的成果。
由于视频数据量巨大,为了减少计算量,本文采用预训练好的特征提取网络对THUMOS14 和ActivityNet1.2 数据集进行视频特征提取。近年来,基于深度学习的视频特征提取研究取得了较大的进步,如双流模型[23]、TSN(Temporal Segment Network)模 型[24]、C3D(Convolutional 3D)模 型[25]、P3D(Pseudo 3D)模型[26]和I3D(Inflated 3D)模型[27]等。本文选用在Kineitics 数据集上预训练好的I3D 模型进行特征提取,以得到THUMOS14 和ActivityNet1.2 数据集的视频特征。
近年来,许多学者对弱监督动作定位模型进行了研究。W-TALC(Weakly-supervised Temporal Activity Localization and Classification framework)模型[28]和3C-Net 模型[29]是目前比较成熟的从上到下的模型;STPN(Sparse Temporal Pooling Network)模型[30]采用从下到上的方法,并在此基础上加入一个规范项以加强动作的稀疏性;AutoLoc 模型[31]采用OIC(Outer-Inner-Contrastive)损失函数使得不同动作之间有更强的区分度。为了验证本文提出的弱监督动作定位方法的动作定位效果,本文在实验中对比了本文模型和AutoLoc 模型、W-TALC 模型、3C-Net 模型等弱监督动作定位模型的平均检测精度均值。
此外,本文在注意力值生成过程中采用的生成模型近年来也有了长足的发展。目前常用的生成模型包括生成对抗网络(Generative Adversarial Network,GAN)[32]、变分自编码器(Variational Auto-Encoder,VAE)[33]、CVAE 等。GAN 生成模型主要包括生成器和区分器两部分,通过不断减少区分器和生成器的输出获取准确的数据分布;VAE 生成模型通过输入数据构建一个虚拟分布空间,再通过在虚拟分布空间采样获取生成的数据,VAE 生成模型中的虚拟分布空间均符合高斯分布,以便于采样;CVAE 生成模型是VAE 生成模型的一种扩展,相对于VAE 生成模型,CVAE 生成模型对于数据有更好的控制能力。由于弱监督动作定位中的视频数据集缺少帧级标签,为了生成能够预测视频特征类别的帧级注意力值,以作为视频的伪帧级标签,本文采用基于动作前后帧信息的CVAE 生成模型,生成符合高斯分布的帧级注意力值,以进行动作定位。
1 动作定位模型
本文首先采用I3D 模型[27]获取视频的RGB 和光流特征,用于训练和测试,其中T是每个视频的帧数,xt∈Rd是每一帧的特征向量,d是特征的维数。视频级标签被标记为y∈{0,1,…,C},其中C表示动作类别数,0 表示背景。在得到视频特征后,本文采用从下向上的方法进行弱监督动作定位,包括基于动作前后帧信息的CVAE 注意力值生成模型、基于区分函数的注意力值优化模型和基于注意力值的动作定位模型三个部分。
为了得到每一帧的注意力值分布(即伪帧级标签)λ,本文构建CVAE 注意力值生成模型,并将视频特征送入CVAE生成模型中,以得到视频特征的注意力值分布,其中λt是对应于每一帧的视频特征xt的注意力值分布向量,取值范围为[0,1]。为了提升帧级注意力值对于动作分类的准确性,注意力值分布应满足式(1):

其中p(λ|X,y)是在给定输入视频特征X和每个视频标签y的情况下,得到对应于标签y的注意力值的分布。由于缺少帧级标签,很难获取准确的p(λ|X,y),因此采用贝叶斯式得到logp(λ|X,y)的近似值,如式(2)所示:

其中logp(λ)-logp(X,y) 是常数。因此式(1)可以简化为式(3):

式(3)中第1 项的目的是使视频的特征被注意力值精准地预测和表示,即注意力值能够区分视频特征;第2 项的目的是使注意力值对于动作有出色的分类能力。为了使式(3)中第1 项达到最大值,本文构建CVAE 注意力值生成模型,利用注意力值重构视频特征,从而生成能够最佳预测和区分视频特征的注意力值;为了使第2 项达到最大值,本文采用注意力值优化模型,通过构造区分函数,对注意力值的分类能力进行提升和优化。
1.1 基于动作前后帧信息的CVAE注意力值生成模型
1.1.1 CVAE注意力值生成模型
CVAE 注意力值生成模型是一种用于生成帧级注意力值的模型,主要包含编码器和解码器两部分,均由两个全连接 层(Fully Connected layers,FC)和两个ReLU(Rectified Linear Unit)激活层构成,其中:第1 个全连接层的目的是使输入数据映射到虚拟分布空间上,第2 个全连接层用于生成注意力值的分布。
CVAE 注意力值生成模型首先采用编码器,将输入的视频特征映射到一个虚拟分布空间(虚拟分布空间符合高斯分布以便于采样);再采用解码器从虚拟分布空间进行限定条件的采样,得到具备一定约束条件的重构的视频特征。本文将CVAE 生成模型生成的帧级注意力值作为视频的伪帧级标签,用于后续的动作定位。下面对CVAE 注意力值生成模型的具体实现方法进行论述。

其中:φ为解码器中的参数,zt为解码器对注意力值进行采样得到的潜在变量,即,其分布符合高斯分布。为了生成重构特征,构造初始注意力值,将其和视频特征xt送入解码器中进行采样,得到潜在变量zt,再采用注意力值λt和潜在变量zt送入解码器中采样,得到重构特征。
同时,为了训练CVAE 生成模型的参数,本文采用输入的视频特征xt和注意力值λt构造另一个潜在变量ht~qϕ(ht|xt,λt),以及符合高斯 分布的虚拟分布空间qϕ(ht|xt,λt)=Ν(ht|μϕ,σϕ2),其中ϕ为编码器中的参数。为了提升CVAE 生成模型的生成效果,构造损失函数LCVAE,在训练中通过减小损失函数LCVAE提升CVAE 生成模型的生成能力。损失函数LCVAE如式(5)所示:

其中:LKL用于计算散度的损失量,Lre用于计算CVAE 生成的重构视频特征和输入视频特征之间的损失量。β为调节参数,KL 为编码器得到的虚拟分布空间qϕ(ht|xt,λt)和解码器得到的虚拟分布空间pφ(zt|λt)之间的散度,目的是使得两者得到的潜在变量尽可能接近,从而使得CVAE 中的编码器和解码器匹配。式(5)中的KL 的计算方法如式(6)所示:

通过训练和优化LCVAE,使qϕ(ht|xt,λt)和pφ(zt|λt)尽可能接近,并使注意力值生成的重构视频特征和原输入视频特征xt接近,从而得到能够表示视频特征的帧级注意力值。因此,CVAE 生成模型的生成方式如图1 所示。
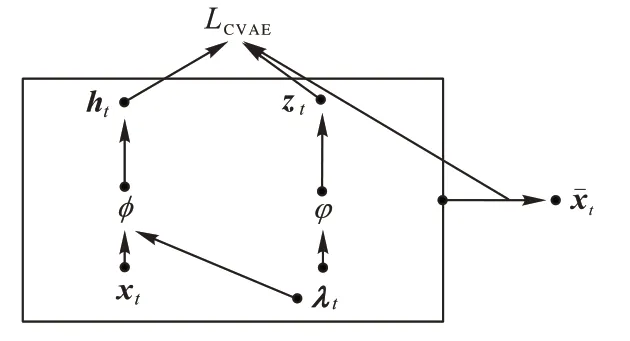
图1 CVAE生成方式Fig.1 CVAE generation mode
1.1.2 基于动作前后帧信息的位置编码层
本文在CVAE 生成模型的编码器和解码器的基础上加入一个基于动作前后帧信息的位置编码层,以增强动作帧的前后关联性。令输入的第t-1 帧的视频特征xt-1为K,输入的第t帧的视频特征xt为Q,输入的第t+1 帧的视频特征xt+1为V,经过位置编码层处理后的视频特征如式(7)所示:

其中α为调节参数。通过位置编码层,以加强动作前后帧的关联性,减小动作漏检率。
1.2 基于区分函数的注意力值优化模型
为了最大化式(3)中的第二项,本文构造基于区分函数的注意力值优化模型,通过构建区分函数,优化动作的分类结果,以训练和优化注意力值,使注意力值能够精准地分类动作的类别,同时将与动作无关的背景帧剥离开来。注意力值优化模型的目标如式(8)所示:

其中xfg是对应于任一种动作类别的动作前景特征,xbg是对应于任一种动作类别的背景特征。两者的计算方法分别如式(9)和式(10)所示:

为了使得注意力值能够最佳拟合动作的实际类别,在区分函数中,首先构造一个损失函数LE。通过训练,降低损失函数LE的值,以优化注意力值。损失函数LE如式(11)所示:

其中pθ包含一个全连接层和一个Softmax 分类器。式(11)中的第一项用于提升注意力值对于视频标签y分类动作的准确性,第二项用于提升注意力值区分背景的能力,第三项用于减小注意力值被分类为其他动作的概率。对于任一种动作类别c∈C,全连接层的参数为wc∈Rd。
此外,为了能够进一步优化注意力值的分布,本文在区分函数中增加TCAM 项,以进一步提升注意力值的分类能力。TCAM 由一个全连接层和一个高斯滤波器组成。对于一个给定的视频标签y,TCAM 可以由式(12)计算得出:

其中:wc表示动作属于c类别时的全连接层的参数,wy表示动作属于标签y的类别时全连接层的参数,w0表示动作属于背景时全连接层的参数分别是前景和背景的TCAM 分布。G(σs)是一个标准高斯滤波器,σs表示高斯滤波器的标准差,*表示卷积操作。采用前景和背景的TCAM分布,可以构造TCAM 对注意力值优化的损失函数LTCAM,如式(13)所示:

通过最小化损失函数LTCAM,优化全连接层的参数,以提升注意力值对于前景和背景的区分能力。
由上所述,区分函数包含损失函数LE和TCAM 损失函数LTCAM两部分,区分函数如式(14)所示:

其中γ1和γ2为调节参数。注意力值优化模型的目标相当于最小化区分函数LAttention。
1.3 注意力值生成及优化流程
注意力值生成及优化流程主要分为两个步骤循环进行:1)固定注意力值优化模型,训练并更新CVAE 注意力值生成模型中的损失函数LCVAE;2)固定CVAE 注意力值生成模型。训练并更新注意力值优化模型中的区分函数LAttention,将训练好的注意力值分布送回CVAE 生成模型,用以训练CVAE 生成模型。
注意力值生成及优化模型的流程如图2 所示。

图2 注意力值生成及优化流程Fig.2 Flowchart of attention value generation and optimization
1.4 基于注意力值的动作定位模型
获取了帧级注意力值后,本文构建基于注意力值的动作定位模型。对于某一动作分类,在[ts,te]时间内若这一动作的注意力值连续高于阈值IoU(Intersection over Union)时,认定是可能的动作片段,该片段的平均注意力值即为该片段的动作分类分s(ts,te,c),其中c表示动作的类别。参考文献[34],将s(ts,te,c)优化为s*(ts,te,c),其计算方法如式(15)所示:


其中η是调节参数,参考文献[34],将其设置为0.1。
1.5 本文模型整体流程
在本文提出的基于动作前后帧信息和区分函数的动作定位模型中,首先采用预训练好的I3D 模型分别获取视频的RGB 和光流的特征;然后,构建注意力值生成和优化模型,利用视频特征得到RGB 和光流注意力值,将两种注意力值合并后,即得到视频的帧级注意力值分布;最后,基于不同的阈值IoU(THUMOS14 数据集中IoU 取值0.10~0.90,间隔0.10;ActivityNet1.2 数据集中IoU 取值0.50~0.95,间隔0.05),利用注意力值完成动作定位。本文模型的流程如图3 所示。

图3 本文模型的流程Fig.3 Flowchart of proposed model
2 实验与结果分析
2.1 数据集和评价标准
为了评估模型的效果,本文在两个公共视频数据集THUMOS14 和ActivityNet1.2 上进行了实验。两个数据集的视频都是未修剪的。在测试集中不存在帧级标签,只存在视频级标签。
THUMOS14 数据集在其训练集、验证集和测试集中共有101 个动作类的视频级标签,在20 个类的测试集中具有视频级标签(不包含帧级标签)。本文采用由200 个未修剪视频组成的验证集进行训练,包含212 个视频的测试集进行性能测试。
ActivityNet1.2 数据集是近年来推出的用于动作识别和定位的基准数据集,包含大量天然视频,涉及语义分类下的各种人类活动。本文采用包含100 个动作类别的4 819 个验证集视频进行训练,采用2 383 个测试集视频进行测试。
THUMOS14 和ActivityNet1.2 数据集中的视频从几秒到26 min 长短不一,且一个视频中可能存在多个动作(平均每个视频包含15.5 个动作),相对于其他数据集,对于模型的分类能力和鲁棒性有更高的要求。
本文采用在不同IoU 阈值下的平均检测精度均值(mean Average Precision,mAP)进行动作定位的准确性评估。IoU的定义如式(16)所示:
IoU=Predict∩Ground Truth(16)
其中:Predict表示检测到的候选动作片段,Ground Truth表示训练集中给定的真实的动作片段。
在对动作定位的预测结果进行评判时,一个准确的动作定位的预测结果应当满足以下两条准则:1)预测的动作片段中动作类别与真实发生的动作类别较为一致;2)预测的动作与真实动作的IoU 较大。
为了计算动作定位的准确率,设定一个IoU 的阈值。当预测动作片段与真实动作片段之间的IoU 大于等于该阈值时,计算预测动作片段的平均检测精度mAP,以评估模型的效果。mAP 的计算方式如式(17)所示:

其中:C表示总动作类别数,c表示动作类别,AP(Average Prevision)表示对于c种动作类别的检测精度。AP 的计算方法如式(18)所示:

其中:P表示查准率,R表示召回率,二者分别代表预测结果中正例被预测正确的比例和真实正例被预测正确的比例。查准率和召回率的计算方式如式(19)、(20)所示:

其中:TP(True Positive)表示被正确预测的帧数,FP(False Positive)表示背景帧被预测为动作帧的帧数,FN(False Negative)表示动作帧被预测为背景帧的帧数。
通过计算每个动作类别的检测精度AP,并对每个动作类别的检测精度AP 求均值,即可得到平均检测精度mAP。选定不同的IoU 阈值,计算在该阈值下的平均检测精度,可表示为mAP@IoU=a,a表示IoU 的取值。
在本文采用的THUMOS14 数据集和ActivityNet1.2 数据集中,采用固定IoU阈值进行模型的检测效果比对。在THUMOS14 数据集中采用的阈值IoU范围为0.1~0.9,间隔0.1;在ActivityNet1.2 数据集中采用的阈值IoU范围为0.50~0.95,间隔0.05。由于THUMOS14 数据集视频数量较少,因此在THUMOS14 数据集上的实验结果每5 次采一次平均值。
2.2 实验预处理方法
本文首先采用在Kinetics 数据集上预训练好的I3D 模型对输入的THUMOS14 和ActivityNet1.2 数据集的视频进行特征提取,对视频进行帧切割后,获取到每一帧的RGB 数据;其次采用TV-L1(Total Variation regularization and the robust L1 norm)算法[35],利用RGB 的数据得到光流数据;接着将两种数据分别划分成若干片段,每个片段16 帧,并将它们送入I3D 模型获取两种1 024 维的特征数据,得到两种特征数据后,分别将特征数据送入本文的模型中得到注意力值分布,对注意力值的训练和优化完成后,参考文献[36],采用非最大抑制法对两种数据得到的注意力值分布进行融合。出于运算量的考虑,对于THUMOS14 数据集,每个视频的最大帧数T设置为400。如果视频帧数大于400,则只取前400 帧。对于ActivityNet1.2 数据集,每个视频的最大帧数T设置为200。整个实验在Pytorch 框架下进行,实验设备为Nvidia m40 GPU,学习率为10-3。
2.3 CVAE生成模型中的参数调节
为了评估CVAE 生成模型中各部分的作用,固定其他参数,在THUMOS14 数据集中对实验中的各个可调参数进行控制变量实验(ActivityNet1.2 数据集计算量过大不利于多组对照实验)。
如式(5)所示,CVAE 注意力值生成模型的损失函数LCVAE包含LKL和Lre两部分,为了评估两个损失函数在CVAE生成模型中的作用,采用不同的β进行对比实验。此外,针对式(7)中的α调节参数进行对比实验。CVAE 生成模型中构造的虚拟分布空间的大小同样影响实验结果,因此,针对不同的虚拟分布空间大小,进行对比实验。在THUMOS14 数据集上采用不同的β、α和虚拟分布空间大小得到的基于IoU=0.5 的mAP值对比如表1 所示。
根据表1 所示,β设置为0.2 时,mAP 最佳,这是因为相较于重构视频特征和输入视频特征之间的偏差,虚拟分布空间之间的KL 散度值相对较大。因此,在进行损失函数LCVAE计算时,为了防止KL 散度过大导致训练过程中出现过拟合的问题,需要对其进行一定程度上的缩减。
根据表1 所示,α设置为7 时,mAP值最高。这是因为在加入动作前后帧信息对视频特征进行位置编码时:若动作前后帧信息在注意力值生成过程中占比过大,会影响动作定位的准确性;若动作前后帧信息在注意力值生成过程中占比过小,则加入动作前后帧信息的注意力值生成模型对动作定位的平均检测精度均值提升有限。因此α设置为7 时能够得到最佳的检测效果。
根据表1 所示,虚拟分布空间大小为128×128 时效果最佳。这是由于虽然较大的虚拟分布空间可以使得采样更充分,但是存在降低采样准确性的可能性;较小的虚拟分布空间虽然可以提升采样准确性,但是同样存在采样样本不充分的可能性。因此采用适中的虚拟分布空间大小时能得到最佳的检测效果。

表1 在THUMOS14数据集上采用不同的β、α和虚拟分布空间大小得到的基于IoU=0.5的mAP值对比Tab.1 Comparison of mAP values based on IoU=0.5 using differentβ,α and latent space size on THUMOS14 dataset
2.4 注意力值优化模型中的参数调节
为了评估注意力值优化模型中区分函数中各部分的作用,固定其他参数,在THUMOS14 数据集上对实验中的各个可调参数进行控制变量实验。如式(14)所示,注意力值优化模型中的区分函数中包含LE、LTCAM两部分,为了调整LE、LTCAM在区分函数中的占比,以最优化区分函数的作用,对式(14)中的γ1和γ2进行控制变量实验。对照实验结果如表2 所示,γ1设置为0.3,RGB 和光流数据的γ2值分别设置为0.5和0.3 时,能够得到最佳的mAP值。

表2 在THUMOS14数据集上采用不同的γ1和γ2得到的基于IoU=0.5的mAP值对比Tab.2 Comparison of mAP values based on IoU=0.5 using differentγ1 andγ2 on THUMOS14 dataset
2.5 基于动作前后帧信息的CVAE生成模型效果评估
为了证明本文在CVAE 生成模型中加入动作前后帧信息对于减少动作漏检的提升作用,设置对照实验,其中一组在CVAE 注意力值生成模型中加入动作前后帧信息,另一组不加入动作前后帧信息。视频中动作帧被注意力值λ检测为背景(即未被检测出的动作帧)的个数为FN,全部动作帧个数为TP+FN,漏检率即为。采用THUMOS14 数据集,在IoU=0.5 时,漏检率实验结果如表3 所示,相较于未加入动作前后帧信息的模型,采用加入动作前后帧信息的CVAE 注意力值生成模型后,漏检率减小了11.7%。

表3 在THUMOS14数据集上加入动作前后帧信息对mAP值的提升效果Tab.3 Improvement of mAP value of adding pre-and post-information of action frame on THUMOS14 dataset
2.6 区分函数作用评估
在评估了CVAE 注意力值生成模型中加入动作前后帧信息的效果后,进一步比较在本文模型中区分函数的作用。为了对比,同样设置对照实验,其中一组在模型中采用区分函数,另一组不采用区分函数。采用THUMOS14 数据集,在IoU=0.5 时,平均检测精度均值mAP 的对比如表4 所示。

表4 在THUMOS14数据集上区分函数对mAP值的提升效果Tab.4 Improvement of mAP of distinguishing function on THUMOS14 dataset
实验结果表明,区分函数明显提高了mAP,这体现了基于区分函数的注意力值优化模型的有效性和可靠性,适用于提升弱监督动作定位的准确性。
2.7 与其他动作定位模型的效果对比
在印证了本文提出的加入动作前后帧信息和区分函数对模型效果有提升后,进一步比较本文模型和其他动作定位模型的mAP。表5 展示了在THUMOS14 数据集上,采用本文模型和AutoLoc 模型[31]、STPN 模型[30]、W-TALC 模型[28]等弱监督动作定位模型,在不同的阈值IoU 的情况下得到的mAP值的对比,其中UNT 表示UntrimmedNet 特征提取网络。时,本文模型表现出色,在THUMOS14 数据集上比其他弱监督动作定位模型的mAP值提升10.7% 以上,在ActivityNet1.2 数据集上比其他动作定位模型的mAP值提升8.8%以上。体现出了本文模型在提升动作定位准确性和减少动作漏检率方面的优势,证明了本文模型对于动作定位效果的显著提升。

表5 THUMOS14数据集不同模型基于不同IoU的mAP值对比 单位:%Tab.5 Comparison of mAP values of different models based on different IoU on THUMOS14 dataset unit:%
表6 展示了在ActivityNet1.2 数据集上,采用本文模型和AutoLoc 模型[31]、TSM(Temporal Structure Mining)[37]、BaS-Net(Background Suppression Network)[38]等弱监督动作定位模型,在不同阈值IoU 的情况下得到的mAP值对比。本文对比的模型采用的视频数据均为未修剪的视频片段。

表6 ActivityNet1.2数据集不同模型基于不同IoU的mAP值对比 单位:%Tab.6 Comparison of mAP values of different models based on different IoU on ActivityNet1.2 dataset unit:%
从实验结果可以看出,本文的弱监督动作定位模型和其他弱监督动作定位模型相比,总体表现较好。在IoU=0.5
3 结语
本文对基于注意力机制的弱监督动作定位方法进行了研究,提出一种基于动作前后帧信息和区分函数的动作定位模型。对于没有帧级标签的数据集,本文通过CVAE 注意力值生成模型获取帧级注意力值,将其作为伪帧级标签,并在CVAE 注意力值生成模型中加入动作前后帧信息,以减小动作漏检的概率;此外,本文构建基于区分函数的注意力值优化模型,在训练中对注意力值进行优化,以提升注意力值对动作的分类效果,从而提升动作定位的精确度。本文在公共数据集THUMOS14 和ActivityNet1.2 上进行了实验,验证了本文模型能够有效地减小动作漏检的概率;与其他弱监督动作定位模型相比,本文模型对动作定位的准确性有明显提升。
