基于机器学习建模的XSS 攻击防范检测*
2022-04-11温嵩杰罗鹏宇胥小波范晓波
温嵩杰,罗鹏宇,胥小波,2,范晓波
(1.中国电子科技网络信息安全有限公司,四川 成都 610041;2.中国电子科技集团公司第三十研究所,四川 成都 610041)
0 引言
随着网络应用和互联网技术的高速发展,生活更加便利的同时,也产生了大量的安全漏洞。跨站脚本(Cross-Site Scripting,XSS)攻击是一种高危害、高影响力的网络攻击手段,广受黑客、高级持续威胁(Advanced Persistent Threat,APT)组织的青睐。在web 发展初期,恶意攻击者针对应用层的web 弱点,通过向web 页面插入恶意的超文本标记语言(Hyper Text Markup Language,HTML)代码,以达到窃漏cookie 和获取用户个人隐私等目的。在web 2.0 时期,当用户浏览web 页面时,攻击者仅通过挂马等方式就可执行其中的恶意HTML 代码,就可以完成劫持会话记录、偷取用户访问历史信息等恶意操作。XSS的出现是web 安全史上的一个里程碑,近年来XSS 攻击事件层出不穷。在2005年,一位名叫Samy的网友在全球最大的在线交友平台——MySpace 中发布了一个XSS 蠕虫攻击事件,借助MySpace 网站自身存在的漏洞,在短短几小时内,产生了大量的恶意数据和垃圾信息在MySpace上传播,对网站和用户造成了巨大的经济损失。在2009 年,推特(Twitter)遭遇了来自stalkDaily 网站的蠕虫病毒传袭击,用户一旦访问该网站,电脑就会被感染,并会发送大量的Twitter 垃圾信息,以诱骗其他用户访问StalkDaily 网站来感染别的主机。在2011 年,在新浪微博又出现了一次比较大的XSS 漏洞攻击,“中毒”的微博用户会自动向自己的粉丝发送含毒的微博与私信,并自动关注一位名为hellosamy的用户,粉丝点击此恶意链接后会再次中毒,以此形成恶意循环,此蠕虫事件仅持续了16 分钟,受影响的用户就达数万个。此次XSS攻击事件利用了用户间的人际关系,发布带有诱惑性字样的博文,引起别人关注并点击,从而得到大范围的传播。每年的XSS 攻击都会造成非常巨大的经济损失,目前已被列为危害最为严重的web 漏洞之一。
XSS 攻击总体上可分为非持久型XSS 攻击和持久型XSS 攻击这两种类型。非持久型的攻击是一次性的,往往仅对当前的页面产生影响,而持久型的XSS 攻击会把攻击者的数据存储在服务器端,因此整个攻击行为将持续存在。XSS 攻击从攻击手段上大体可分为反射型、存储型和文档对象模型(Document Object Model,DOM)3 类:反射型是只经过后端但不经过数据库的一种XSS 攻击;存储型XSS 攻击是既经过后端又经过数据库的一种攻击;DOM 型是基于文档对象的一种漏洞,可以通过统一资源定位符(Uniform Resource Location,URL)传入参数去控制触发条件。在以上3 类攻击手段中,反射型XSS 攻击尤为常见,存储型XSS 攻击具有较大的危害,DOM 型攻击手段最为丰富。
为了防范XSS 攻击,刘海等人[1]提出了一种新的防范XSS 攻击的架构,该架构采用服务器端、服务器代理和客户端浏览器、网页备份服务器合作的方式来共同防范XSS 攻击,该方法不仅能够防范XSS 攻击类型,而且对于防止网页的篡改有着一定的作用,但是由于XSS 攻击的多样性,需要人为的维护和改善策略,需要大量的人力。黄文锋等人[2]提出了一种基于DOM 型的XSS 攻击防范模型,通过在服务器端和客户端合作防范XSS 攻击,具体是在服务器端采用随机数对DOM 动态写入的每一个标识元素进行标识,在客户端修改脚本解析引擎以获得更新后的HTML 文本,通过随机数来标识可信标记与不可信标记。此方法检测速度快,检测精度高,但由于设计初衷只检测DOM 型的XSS 攻击,因此缺乏对其余XSS 攻击类型的检测能力。杨美月等人[3]提出了使用机器学习技术识别web 中的XSS攻击,首先对数据进行预处理,其次利用doc2vec进行特征提取,最后将特征提取的特征向量作为分类模型的输入,并训练分类模型。当攻击数据分布较为均匀时,此方法的准确率较高,但对数据集的依赖程度较大,对分布不均匀的数据集具有较低的识别性能。为了解决数据漂移和数据分布不均匀的问题,赵澄[4]提出了基于支持向量机(Support Vector Machines,SVM)分类器的XSS 攻击检测技术,在大量分析XSS 攻击样本和正常样本的基础上,提出了代表性的五维特征并将这些特征向量化,然后进行算法的训练与测试,通过深度特征到算法模型演练的技术来进行XSS 攻击识别,能够有效识别常规XSS 攻击及其部分未知和变形攻击,但由于缺乏较为细致的数据预处理过程,以至于后续特征工程无法准确提取出XSS 攻击特征,导致后期维护需要不停的数据打标、特征更新和算法迭代,极大地增加了人力成本。蒋华等人[5]提出了基于行为的XSS攻击防范方法,该方法结合动态污点分析和超文本传输协议(HyperText Transfer Protocal,HTTP)请求分析处理,对应用程序中的敏感数据进行标记并跟踪,以防止XSS 蠕虫的繁衍,能有效防止XSS 攻击和0-day 蠕虫的传播,但该方法有一部分是手动的,还没法达到自动化防范检查的需求。为了解决自动化检测等需求,张思聪等人[6]提出了基于最大熵模型的XSS 攻击检测模型。该模型首先通过输入预处理模块对原始输入进行规范化处理,其次由特征提取模块将特征序列转化成特征向量,并将特征向量交由最大熵分类器进行分类,最后由结果处理模块根据分类的结果进行后续的处理,此方法在已知条件有限的情况下给出的分类结果较为准确,但对存储型XSS攻击的检测效果有待提高。冯倩等人[7]提出了基于Fuzzing的存储型XSS 漏洞检测技术,使用遗传算法来优化攻击样本,将生成的XSS 攻击样本作为Fuzzing的测试用例,以此来提高测试用例的覆盖率,此方法有效降低了存储型XSS 攻击的漏报率,但检测面较小,无法有效地检测反射型XSS 攻击和DOM 型XSS 攻击。钱丽[8]在研究XSS防御机制上,提出了过滤非法字符和字符转义两种手段,对用户输入的数据进行严格规范检测和字符转义处理,只有符合数据规范和经过字符转义处理的输入信息才被允许执行。该防御方法在web 安全漏洞检测过程中可有效识别一定的XSS 漏洞,但无法检测新的XSS 变种攻击。Salas 等人[9]提出的使用渗透测试的方式检测XSS 漏洞,通过模拟XML格式的攻击进行渗透检验,对指定格式的XSS 攻击具有较好的检验效果,但XSS 攻击变幻丰富,此方法无法全量检测与识别其余的XSS 恶意攻击。Jim等人[10]提出了一种基于白名单和DOM 沙盒的安全策略,在客户端通过修改浏览器的方式来支持并执行安全策略,使得服务器端和客户端合作防范XSS攻击,此方法能有效抵御部分XSS 攻击并提高防御精确率,却缺乏后期及时性,无法及时响应与拦截恶意攻击。Nadji[11]提出了一种基于文档结构完整性的方法,通过修改客户端脚本解释引擎的方式来检测XSS 攻击,此方法具有较高的检测率,但不便于配置与部署。
Web 安全和人们的生活息息相关,在确保给网民带来快捷服务的同时,理应为网民的财产与隐私保驾护航。自从20 世纪第一个XSS 攻击诞生至今,每年都会衍生出新的,且更具威胁的XSS 攻击,给公司与个人造成了大量的财产损失。而现有的XSS攻击防范模型无法及时响应与部署,对不同类型的XSS 攻击无法做到全量检测与拦截。
针对以上问题,本文提出一种基于机器学习建模的XSS 攻击防范检测方法。该方法将海量数据经过数据加工模块转换为规整数据,并将安全攻防经验用于特征向量的构造,然后用机器学习技术训练算法模型,以此对流量进行全量、高效、精准的识别与拦截,发掘网络流量中的XSS 恶意攻击。
1 数据加工
数据加工是整个建模的第一步,这是因为现实网络流量中充斥着大量的无用干扰信息,且数据参差不齐。攻击者会发现系统中存在的漏洞,并通过各种复杂的编码、转义技术来混淆和躲避web 安全检查。整体数据加工流程如图1 所示。
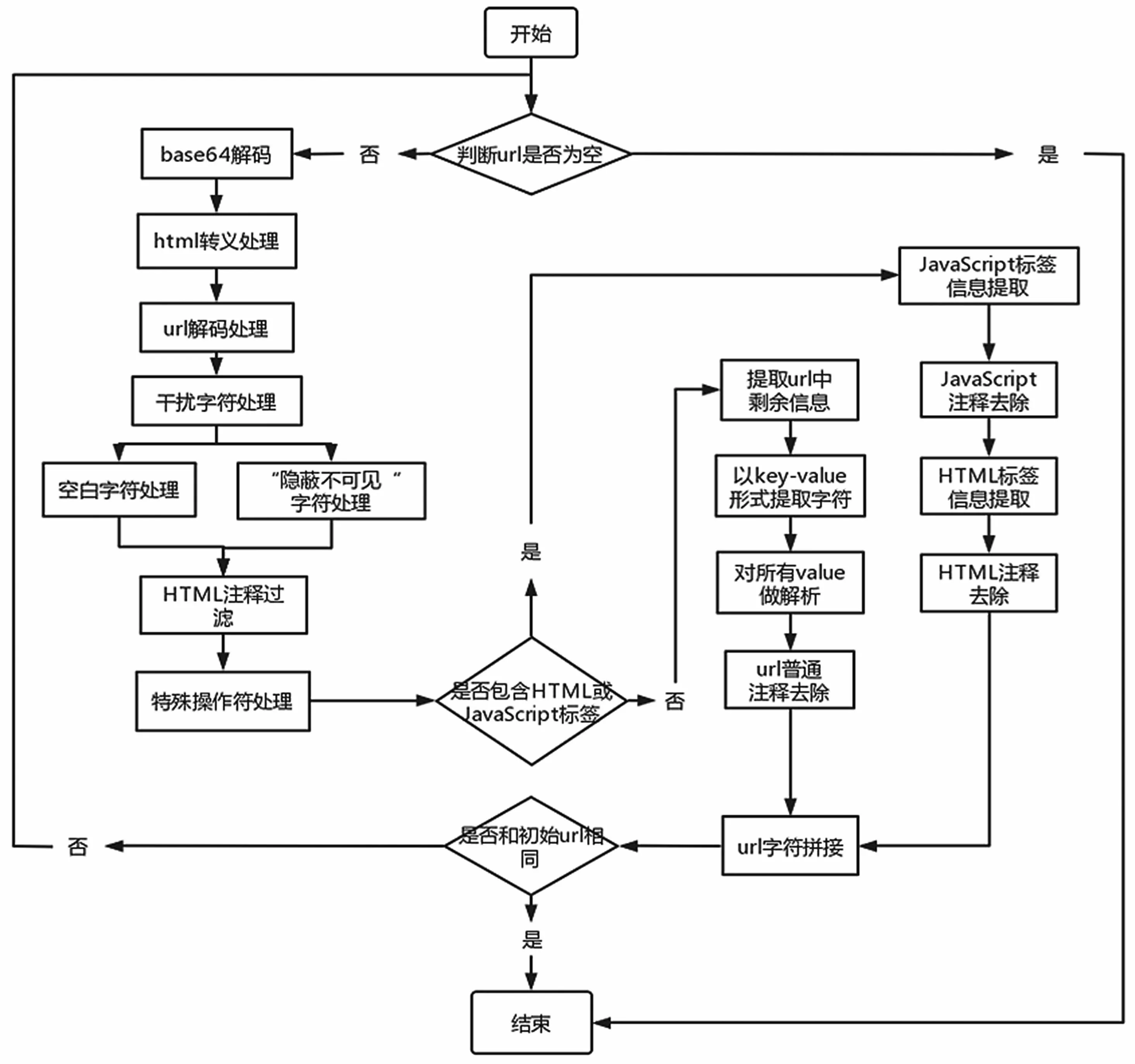
图1 数据加工流程
为了挖掘网络流量中隐藏着的真正有意义的信息,通过数据加工模块对原始数据进行数据解析与加工,将混淆视听的数据转换成真正有价值的数据。数据渗透模块中包含base64 处理、HTML 转义字符处理、URL 解码处理、干扰字符处理、HTML 注释处理、特殊操作符处理等操作。
Base64[12]内容是数据的一种编码表示,有一定的加密作用,是网络上最常见的用于传输8 Bit字节代码的编码方式之一。Base64 编码可用于在HTTP 环境下传递较长的标识信息,在web 攻防中,攻击者使用Base64 来将URL 中一个较长的标识符编码为一个字符串,用作HTTP 表单中的参数,采用Base64 编码具有不可读性,即所编码的XSS 攻击数据不会直接被安全人员用肉眼所识别。字符转义[13]也称字符实体,在HTML 中像“<”和“>”这类符号已经用来表示HTML 标签,因此不能直接当作文本中的符号来使用。为了在HTML 文本中使用这些符号,就需要定义它的转义字符串,且有些字符在ASCII 字符集中没有定义,也需要使用转义字符串来表示。攻击者利用了转义字符的原理,当需要隐蔽自己的攻击意图时会在URL 中隐藏HTML标签,用“"”等字符进行HTML的“<”关键符号替代,来迷惑web 安全人员。在互联网上传送URL 只能采用ASCII 字符集,即只能使用英文字母、阿拉伯数字和某些标点符号,如果包含中文等其余字符时,就需要再使用编码。攻击者利用了URL 编解码原理,将恶意代码通过URL 编码[14]后进行隐蔽混淆,以逃过web 安全检索。除了编码转义等混淆手段,攻击者也会在URL 中加入干扰字符和注释信息等,起到蒙蔽视听的作用。
2 特征工程
特征工程是把数据加工模块清洗好的规整数据进行加工处理,转换为机器模型可识别的向量化指标数据。特征工程作为衔接数据加工和算法模型的中间桥梁,是整个算法建模流程的重中之重,好的特征工程能够有效提炼出正常样本和恶意样本的差异所在,帮助机器学习模型做出正确的抉择,有效提高模型的检测性能。
本文将特征分为常规特征、字符统计特征、特定模式特征和特殊字符特征四大类,共19 个特征。特征分类如图2 所示。
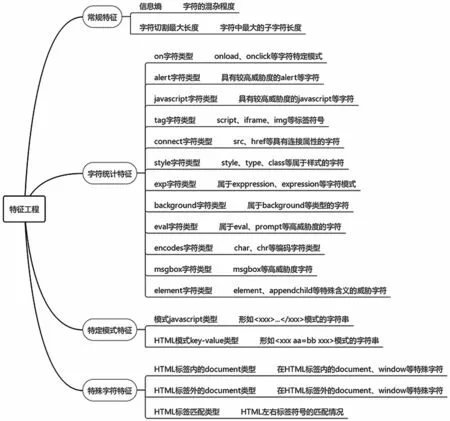
图2 特征工程分类
其中信息熵[15]常被用来作为一个系统的信息含量的量化指标,用于表示一段信息的混杂程度。常见的XSS 攻击信息中包含的字符种类较多且字符混杂程度较高,信息熵偏高,用信息熵特征能较好地识别出XSS 攻击,信息熵计算公式:
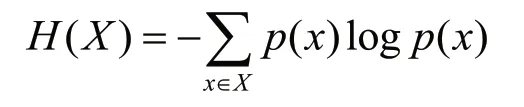
式中:x为随机变量;p(x)为输出概率函数;H(X)为信息熵值。
统计特征用于表示XSS 攻击信息中某类特殊关键词[16]的出现频数。XSS 攻击中往往带有某类特定的恶意关键词用于恶意函数或恶意代码的链接传递作用,而正常的URL 信息中很少带有此类关键词,所以关键词信息作为一个特征,能很好地区分正常URL 信息和XSS 攻击信息,但若单一凭借关键词的出现频率来认证XSS 攻击,模型会有较高的误报率。为了解决高误报问题,通过反复地对大量正反样例进行观察与取证,使特征在涵盖关键词信息的同时,会为关键词设计其前后特定模式的字符顺序,当仅出现某单一关键词时并不会触发此类特征,关键词正则匹配公式:

在URL 信息中会包含一些攻击者精心构造和编排的特定字符,其中局部单一的字符串不具有XSS 攻击的威胁。当其前后字符遵循特定的出现顺序时即具备触发恶意攻击,比如JAVASCRIPT 模式的XSS 攻击,此模式以形式的字符作结尾,中间以其余字符填充并整体混淆在URL信息中,这种特定模式的字符串用肉眼难以区分出其危害,本文使用正则匹配发掘此类字符:
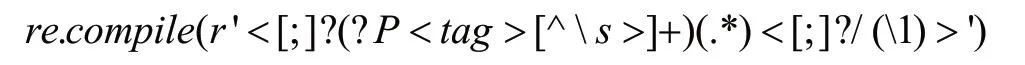
并通过特定模式特征统计其出现频数,检测流程如图3 所示。
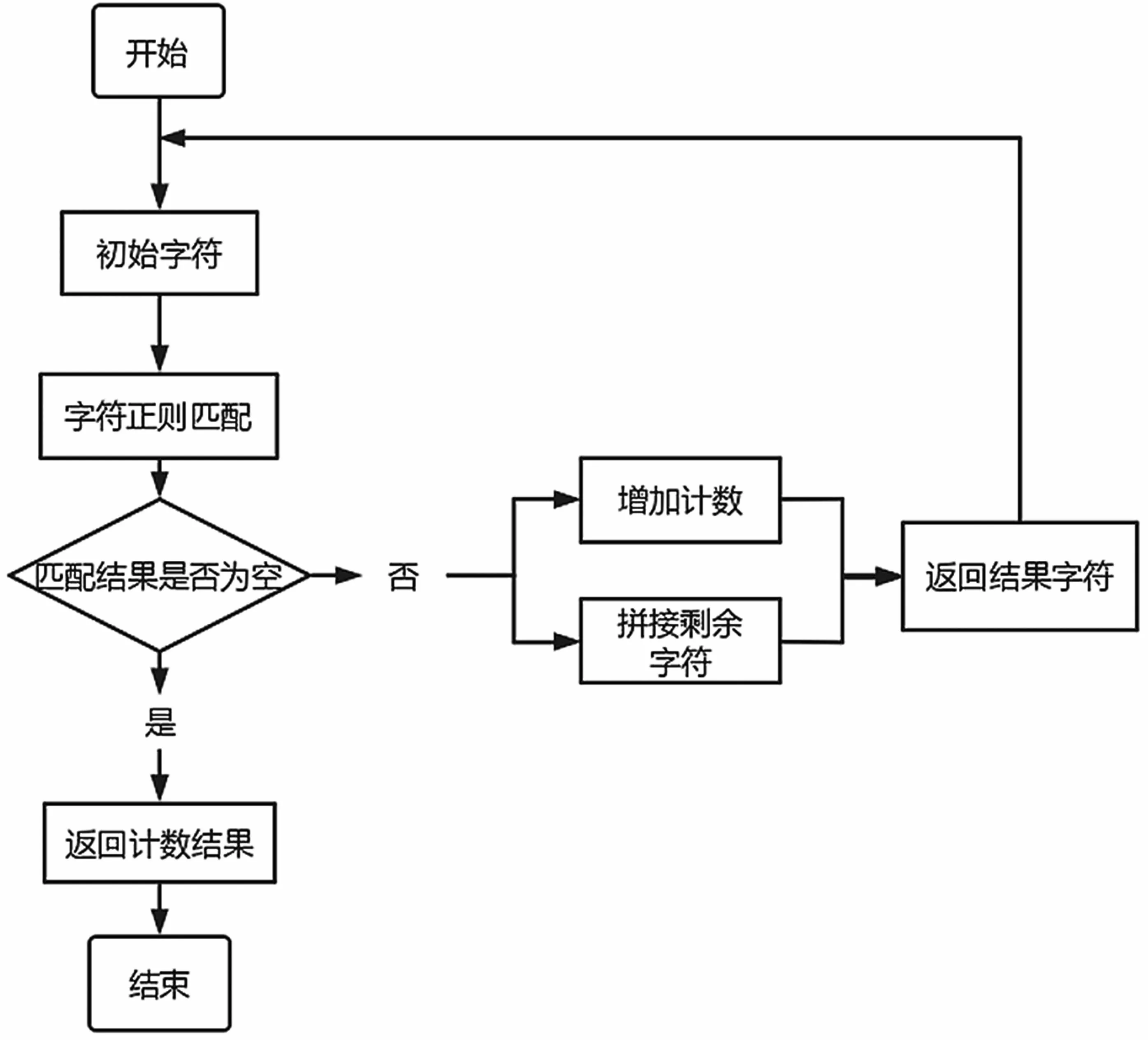
图3 特定模式检测流程
3 算法模型
算法模型是把特征工程加工好的特征进行巧妙组合,通过高阶决策指标对高纬特征进行融合、分类并给出最终结果指示的过程。安全算法模型有别于传统的入侵检测系统(Intrusion Detection Systems,IDS)规则[17],传统的IDS 规则通过专业知识区分恶意网络攻击,并基于手工和经验的方式来维护检测规则和维持检测性能。IDS 规则局限于人为经验和繁琐的工程步骤,而算法模型则通过构建复杂的决策逻辑,发掘数据中真正有用的关联信息,在减轻人工静态工作强度的同时可有效提高检测效率。通常而言,算法模型具有较低的维护成本和较高的检测准确率,在安全评估和安全决策方面具有较好的应用前景。
本文采用机器学习决策树[18]分类算法进行算法建模。决策树是一种从根节点开始对数据集进行测试划分,并将不同数据测试结果最终划分成不同叶子节点的树状结构的方法,本质上是通过一系列复杂规则对数据进行分类的过程。对于给定的数据样本集合,决策树C4.5 使用信息增益率来选择分裂属性,属性A的信息增益表达式:
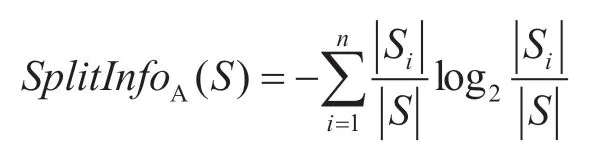
式中:训练集S通过属性A划分为n个子数据集,|Si|表示第i个子数据集中样本的数量,|S|表示在属性划分之前的数据样本总量,通过属性A划分样本集之后的信息增益和信息增益率为:
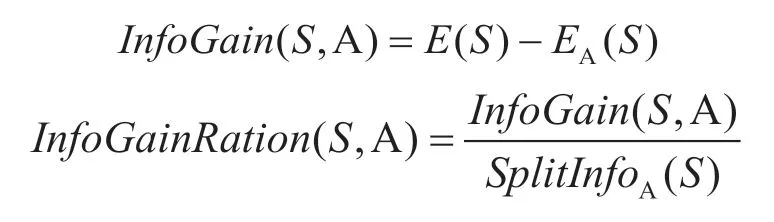
类型为连续型的属性进行离散化处理,对属性B的具体取值进行升序排列后得到序列:
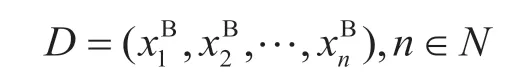
式中:为属性B的具体取值。
在序列D中的N-1 种二分方法求得二分阈值:
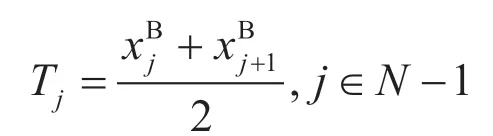
阈值Tj将数据集划分为两个子集,并通过计算其信息增益选取N-1 种信息增益最大的分割方式作为属性B的划分结果:

式中:E(S)代表数据集进行属性划分之前的信息熵、(S)代表数据集按照属性B进行数据划分之后的信息熵。
决策树的决策运营逻辑如图4 所示。
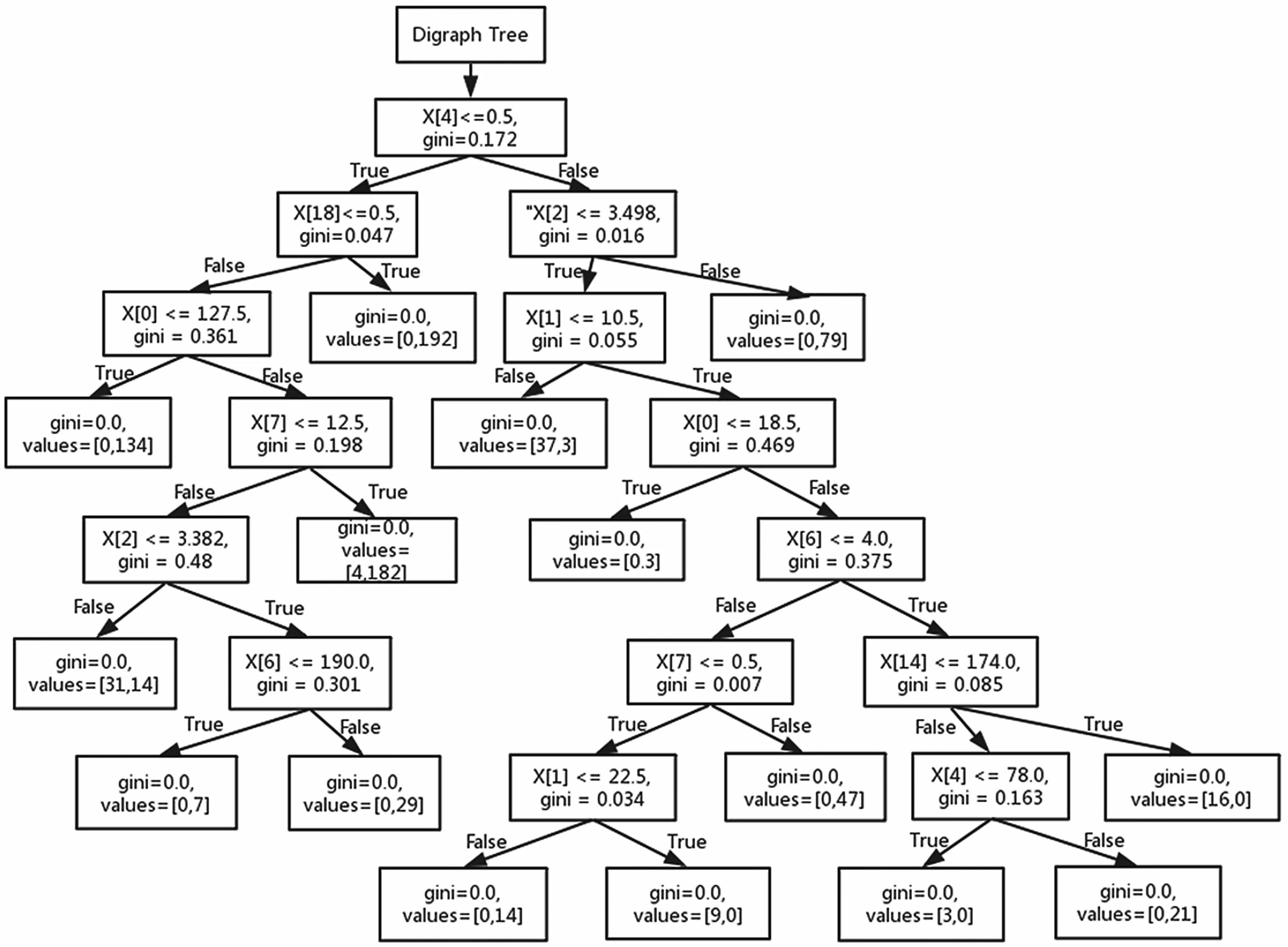
图4 决策树运营逻辑
为了防止过拟合的问题,决策树C4.5 采用一种自顶向下的剪枝方法,通过评价一个叶子节点在剪枝前与剪枝后对样本误判率的高与低,来决定此叶子节点是否具备剪枝的必要。对于一个覆盖了m个样本、e个错误样本的叶子节点,该叶子节点的样本划分误判率是,其中p表示惩罚因子。对于一棵有n个叶子节点的决策树,其误判率为:
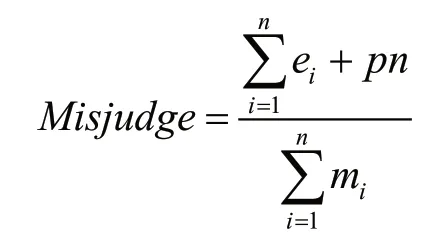
式中:ei为树结构中第i个叶子节点的错误样本数;mi为树结构中第i个叶子节点的样本总数;pn为树结构中全部叶子节点的惩罚因子。对于二分类子树的误判次数就是伯努利分布,即可估算出子树对于误判次数的均值和标准差为:

去掉原先的叶子节点,将子树替换为新的二分类叶子结点后,其误判次数也满足伯努利分布,新叶子节点的误判率和误判次数均值为:
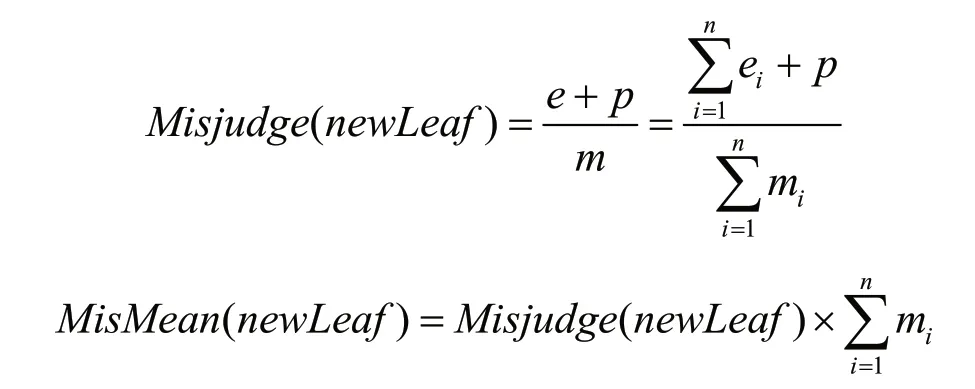
当子树的误判次数均值和标准差之和大于对应叶子节点的误判均值时,则进行剪枝操作,剪枝后在整体树结构中原子树替换为新的叶子节点。剪枝条件为:
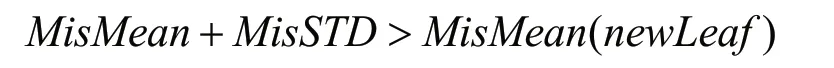
决策树是一种白盒模型,对数据量的依赖程度较小,且模型的决策逻辑具有可观测性,相较于其他黑盒模型算法而言,决策树算法具有更强的可解释性。决策树的算法流程如图5 所示。
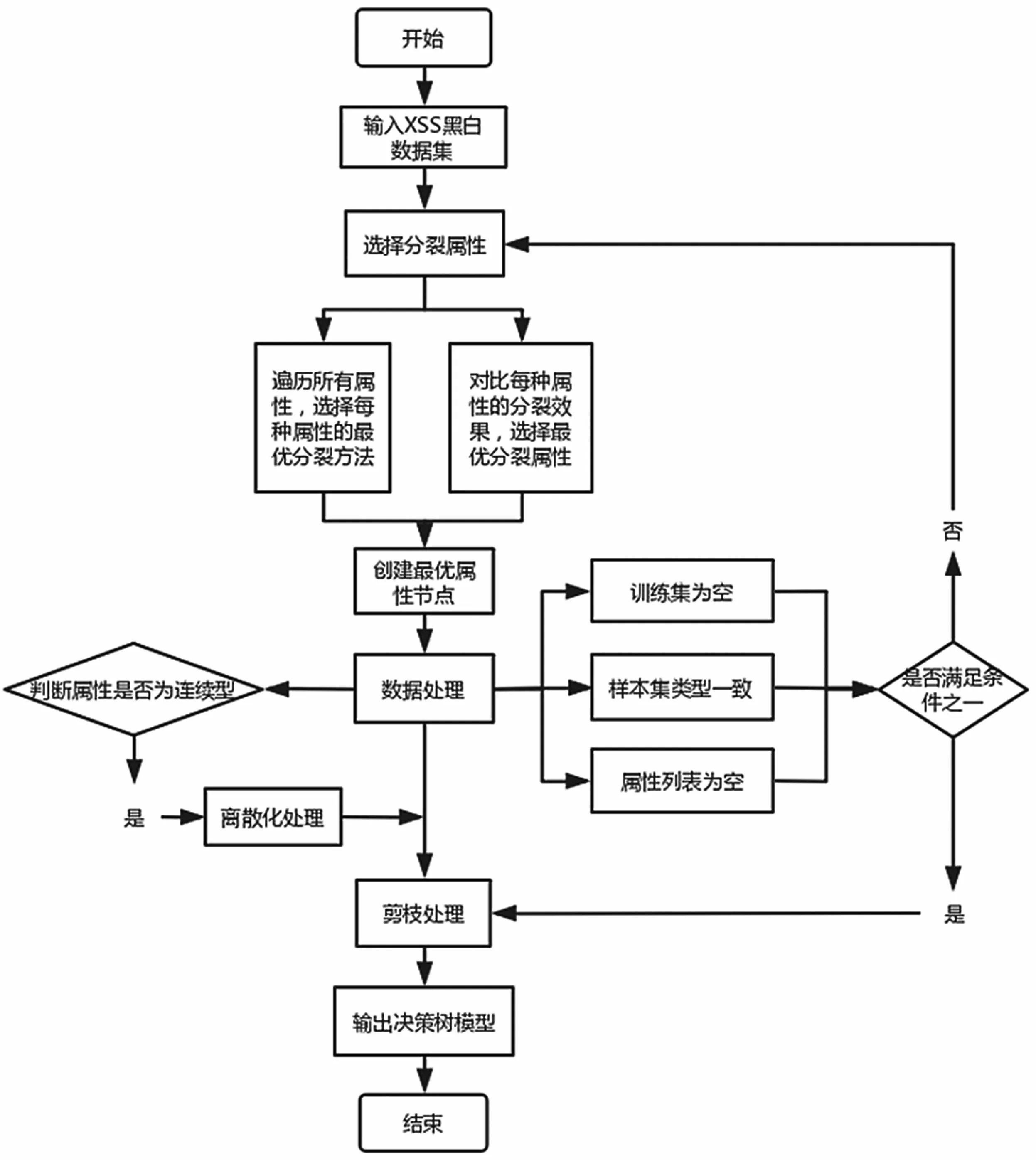
图5 决策树算法流程
4 性能测试与分析
模型训练数据集通过网络开源共享、公司安全团队积累、互联网流量渠道采集,由共计420 万条数据组成,并在安全数据分析专家的指导下进行修正和核实整个数据集的标注评判。数据集由330 万白样本和90万黑样本组成。将整体样本集按照7∶3分别划分成用于模型训练和用于模型验证的数据集,模型采用2 分类的方式进行结果评判,并采集线上流量数据进行模型分析测试,通过准确率和召回率等评判指标来进行模型的修正与回溯。通过比较不同方法的性能,得到了如表1 所示的结果。
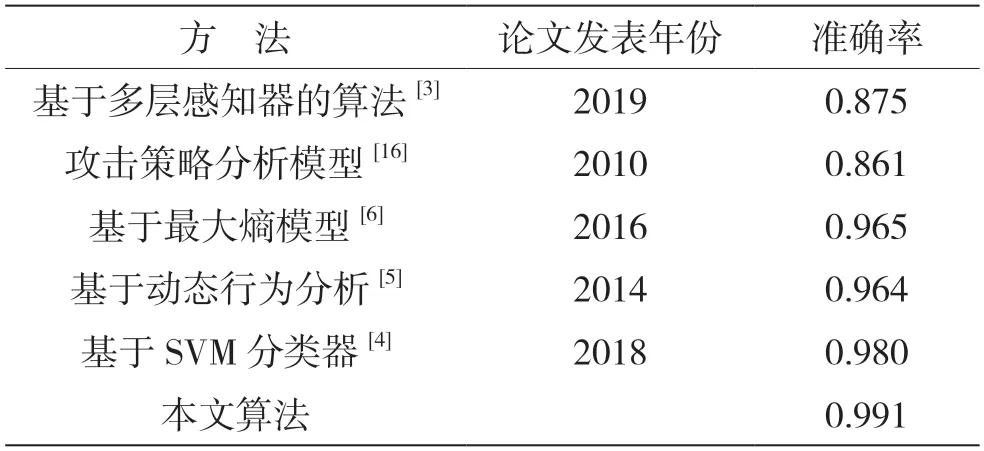
表1 不同评估方法的性能比较
如表1 所示,基于机器学习建模的XSS 攻击防范检测具有较高的准确率,在提炼IDS 规则特征的同时,能较好地融合安全专家的业务经验知识。本文模型能够从海量信息中高效准确发掘攻击信息,具有很强的衍生性能,且可维护性强,能有效地降低人力维护成本,在高效运营的同时能及时发掘攻击者的真实意图,并为安全分析人员提供更好的指示,使他们能够更好地维护网络安全环境。
5 结语
本文研究了基于机器学习建模的XSS 攻击防范检测模型,在网络流量安全智能检测领域引入机器学习技术,实现了对网络流量中跨站脚本攻击的智能化检测。通过分析现有检测方式对XSS 攻击检测的不足,并结合XSS 攻击灵活多变、混淆复杂等特点,提出了一种基于安全专家经验学习、业务信息特征加工和机器学习算法建模的检测方式,能很好地识别并检测网络中的真实XSS 攻击,解决了传统检测方式中误报高、效率低的难题。此检测方式能更好地检测、响应和拦截危险网络攻击,具有准确率高、泛化性强、维护性高的特点,利于即时检测已知XSS 攻击和即时发现未知XSS 威胁,有助于更好地保障网络安全生态环境。
