迁移学习及其在通信辐射源个体识别中的应用*
2022-04-11王天池
王天池,俞 璐
(陆军工程大学,江苏 南京 210001)
0 引言
在现代战场通信对抗中,作为“千里眼、顺风耳”的通信侦察技术早已是各国争相进行研究与攻关的关键领域。辐射源个体识别(Specific Emitter Identification)作为通信侦察的一种技术手段,在现代战场上发挥着至关重要的作用。
辐射源个体识别技术能够提高战备防御能力,在识别敌方设备、分析敌方目标个体、分析战场电磁态势、获取有价值的情报等方面,均有着十分重要的应用。辐射源个体识别是将辐射源电磁特征与辐射源个体相匹配的技术。不同辐射源个体之间,制造工艺、电子元件非线性的差异及信号调制方式的不同,导致了同一辐射源所发射信号的内在特征的不同。辐射源个体识别是通过提取通信辐射源发送信号中的细微特征,来识别不同的通信辐射源个体的方法[1,2]。
由于通信辐射源数据采集和标注成本高,构建通信辐射源数据集非常困难,而且数据量过小易导致训练时发生过拟合,造成模型识别精度较低。迁移学习[3](Transfer Learning)不要求源域与目标域数据同分布,大大减轻了传统模型对数据量和数据分布的敏感性,可以一定程度上解决通信辐射源数据集不全面、不充足等问题。
1 基于迁移学习的通信辐射源个体识别原理
传统机器学习从训练数据中学习知识产生模型,模型对测试数据进行识别,因此基于传统机器学习的通信辐射源个体识别方法要求训练数据和测试数据要在相同的特征空间,并具有相同的分布。在缺少同特征空间、同分布的训练数据时,迁移学习从不同的特征空间及数据分布的源域中学习知识向目标任务迁移[3],可以有效解决目标域数据集构建困难造成的训练问题。基于迁移学习的通信辐射源个体识别基本原理如图1 所示。图1 中“○”表示一个数据集,“■”和“▲”表示采集到的带标签数据,“◇”为采集到的不带标签的数据。
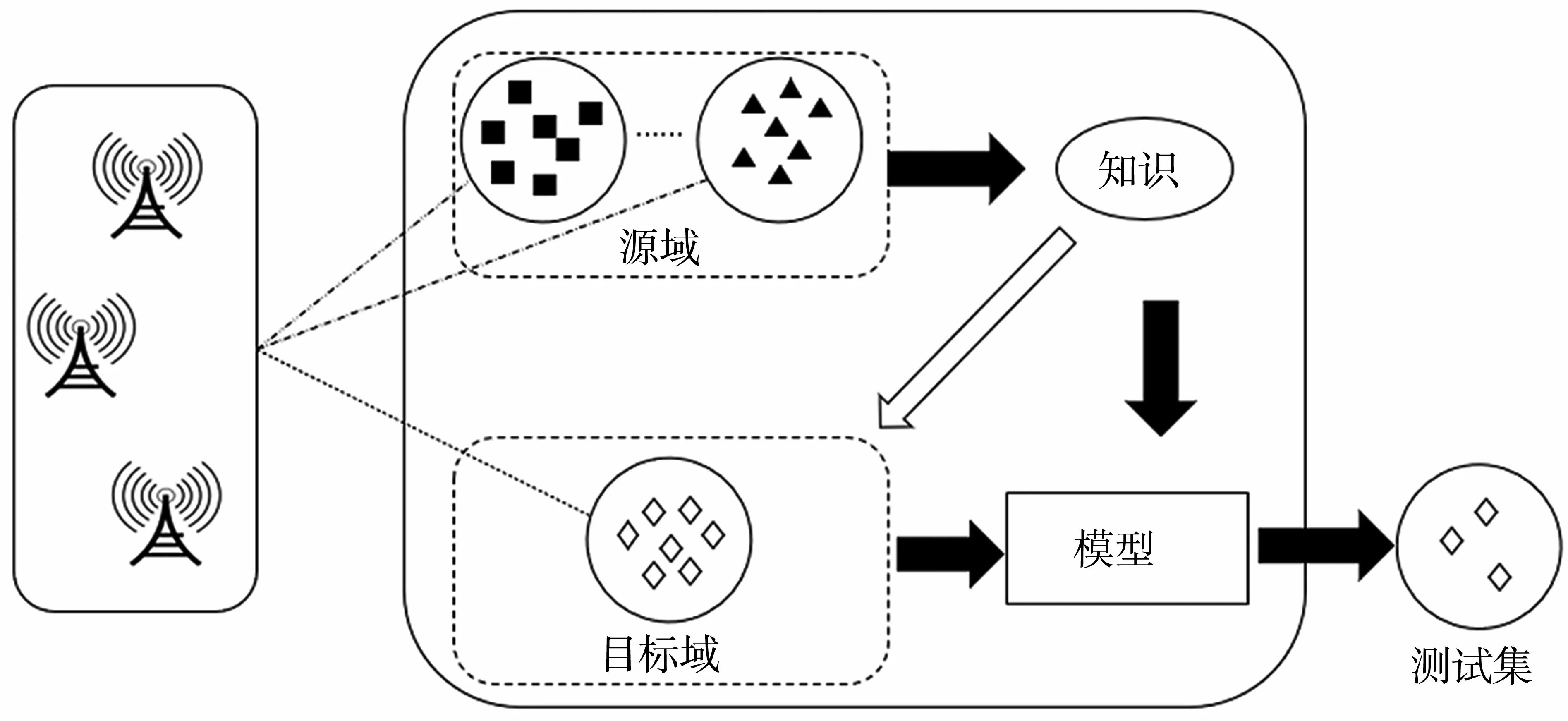
图1 基于迁移学习的通信辐射源个体识别基本原理
基于迁移学习的通信辐射源个体识别的基本思想是,由于通信辐射源信号采集环境复杂,不同环境采集难度不一,通过在较易环境中采集大量数据,构建标签,建立数据集作为源域,将不带标签的待测信号数据作为目标域。对于通信辐射源个体识别问题来说,这里的源域和目标域属于同特征空间、不同分布数据,符合迁移学习的基本设定。迁移学习将从源域中学到的知识迁移到目标域训练任务中去,从而提升模型的鲁棒性。在基于迁移学习的通信辐射源个体识别任务中,迁移学习就是将从不同信道采集到的数据中学到的知识迁移到待测信号训练任务中去。
从通信辐射源个体识别问题本身出发,对于同一通信辐射源而言,即使发送的信号经历了不同的环境,其所带的“指纹特征(Fingerprint Feature)”是不变的。因此,对于同一辐射源在不同信道环境下发射的信号,即使信号数据的特征空间及边缘分布有所偏差,但是在低维上仍是“相近的”,这进一步证明了迁移学习在通信辐射源个体识别任务上的可行性。
2 迁移学习方法研究现状
机器学习技术在分类、回归和聚类等众多领域得到了广泛的应用,并取得了显著的成果。在分类领域,对数据进行分类时,首先需要对分类器进行训练。对于传统机器学习方法或经典深度学习算法,训练集和测试集应具有相同的特征空间并服从相同的分布。对于已训练好的分类器,如果新数据不满足与训练集同分布这个条件,那么需要对新数据进行重新标注,用于分类器的重新训练。在很多领域,标注新数据的成本往往很高,这在实际项目中难以实现。在这种情况下,为了降低标注新数据的成本,迁移学习作为一种新的机器学习范式逐渐受到了人们重视。Pan 等人[3]系统地研究了迁移学习的发展情况,并归纳总结了迁移学习的类型和应用场景。他们从3 个维度将迁移学习进行了分类:根据源域与目标域的特征空间和标记空间的一致性,将迁移学习分为同构迁移学习与异构迁移学习;根据迁移的领域属性,将其分为归纳式迁移学习、直推式迁移学习、无监督迁移学习,总结如表1 所示;根据迁移学习的实现方法,将其细分为基于实例、基于特征表示、基于参数以及基于关系知识的迁移学习。基于实例和特征表示的迁移学习方法在归纳式、直推式、无监督迁移学习中均有应用,基于参数和关系的知识迁移学习方法只在直推式迁移学习中研究过。
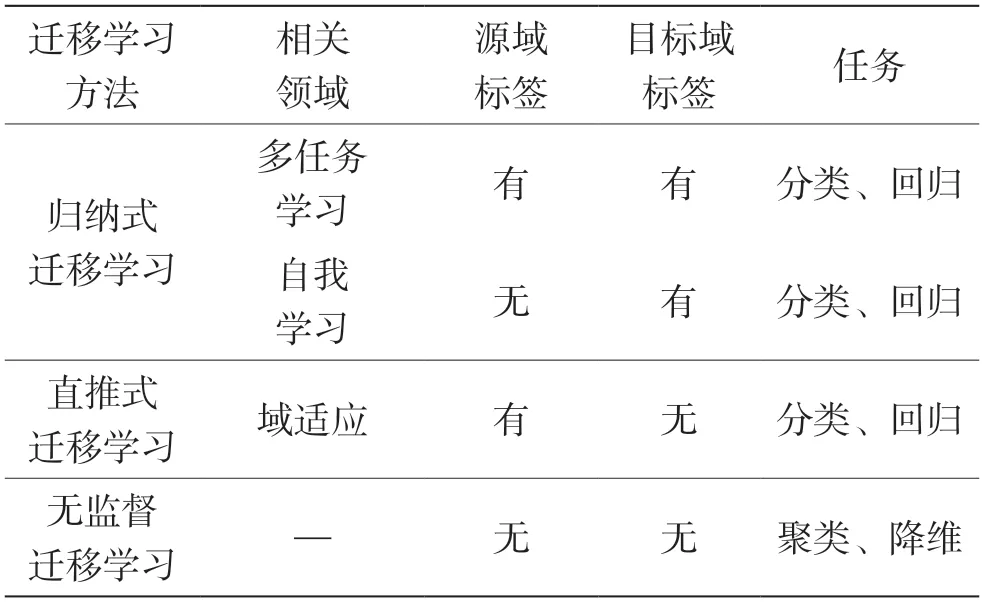
表1 迁移学习不同方法的联系及相关领域
本文主要基于迁移学习的实现方法对国内外迁移学习具有代表性的研究成果进行分类讨论。
2.1 基于实例的迁移学习
基于实例的迁移学习方法主要应用于源域和目标域不完全相同分布而不能直接重用于目标域训练任务的场景,该方法通过重采样或改变样本存在形式等方式来减少源域和目标域的差异。
Jiang 等人[4]提出了利用源域和目标域两者的条件概率P(ys|xs)和P(yt|xt)的差异,来去除源域训练样本中影响目标域“正确”训练的“错误”样本,然后利用新的源域样本训练分类器,并对目标域中的数据添加标签。最后,结合新源域与目标域作为训练集来共同训练分类器。
Dai 等人[5]提出了一种称为TrAdaBoost的迁移学习算法,是AdaBoost算法的拓展。TrAdaBoost 旨在解决当源域与目标域中存在不同分布的数据时,AdaBoost算法对分类器产生负面影响的问题,属于归纳式迁移学习范畴。该算法通过给同分布样本增加训练权重,不同分布的“负作用”样本降低权重的方式,最大化减轻因不同分布的数据样本对分类器造成的负面影响。具体算法如下:

Cheng 等人[6]基于TrAdaBoost算法提出了一种加权多源的迁移学习算法。该算法首先利用源域和目标域组成的多个训练样本集来训练多个弱分类器,并根据训练效果给每个弱分类器分配权重,将多个弱分类器的加权和作为候选分类器;其次根据候选分类器的分类损失,更新源域和目标域的样本权重;最后,多个弱分类器根据新的样本权重重新训练,并形成新的弱分类器权重,以上步骤迭代进行。
Antunes 等人[7]基于文献[6]中加权多源TrAda Boost算法,提出了一种改进的迁移学习方法。该方法引入每个数据点重要性的权重,考虑了目标数据和源数据之间的平衡,同时比较了目标域和源域数据量不同比重对算法效果的影响,在目标域数据比重较大时取得比基础算法更好的效果。
Ren 等人[8]提出了一种基于模糊近邻密度聚类与重采样的迁移学习算法,该方法区别于其他迁移学习方法,不是直接估计不同的分布,而是通过聚类分析探索数据结构,然后利用获得的结构信息生成新的训练集,用于重采样策略下的目标学习。基于聚类分析和重采样的迁移学习过程如图2 所示,图中有两类样本“○”和“□”,“○”采样后标记为“●”,“□”采样后标记为“■”。该算法首先通过对整个数据集进行聚类分析,找到数据结构信息,如图2(b);其次从每个子类中,按照相同的比例,通过一定的重采样策略,生成一组新的与目标域数据分布偏差较小的训练样本,用于目标域学习,如图2(c)。如图2(d)所示,该算法性能较对数据直接估计分布的方法有了很大的提升。
Sharma 等人[9]首先证明了不同源域样本对目标模型迁移学习效果不同的假设,其次提出了一种基于实例的无监督迁移学习算法,用于改善源域到目标域的迁移过程中,由于训练样本导致的模型衰弱的问题。算法通过提取源域和目标域中相似和不同的样本,利用多样本对比损失来驱动领域对齐,并结合类别之间的类内聚类和类间分离,从而减少噪声分类器边界,提高可迁移性和准确性。
2.2 基于特征表示的迁移学习
基于特征表示的迁移学习方法的主要思想是通过寻找“域不变”的特征表示去最小化域间差异以及分类或回归模型误差。此类迁移学习方法也称作域适应方法,这类方法通常结合对抗学习、度量学习等方法来获取“域不变”特征。
Pan 等人[10]提出了一种称为迁移成分分析(Transfer Component Analysis,TCA)的迁移学习算法。该算法针对源域与目标域数据处于不同数据分布的情况,先将两个领域的数据一起映射到一个高维的再生核希尔伯特空间,达到降维的效果,接着利用最大均值差异(Maximum Mean Discrepancy,MMD)最小化源域和目标域的数据分布距离,最大程度地保留源域和目标域的共同属性,即“域不变”特征表示。该算法中将源域和目标域数据降维映射到再生希尔伯特空间生成MMD 距离的公式为:
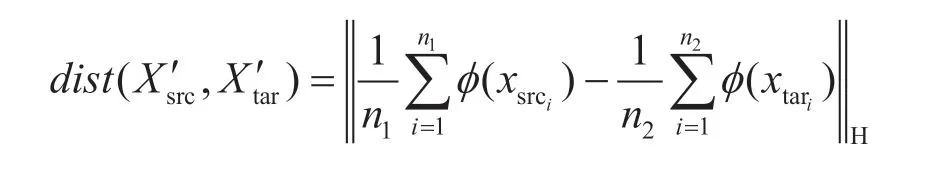
式中:n1为源域数据数量;n2为目标域数据数 量;为第i个源域数据;为 第i个 目标数据;ϕ表示假设存在的一个特征映射使得P(ϕ(xsrc))≈P(ϕ(xtar));H 表示再生希尔伯特空间条件。
Long等人[11]在文献[10]中TCA算法的基础上,提出了联合分布自适应(Joint Distribution Adaptation,JDA)迁移学习算法,证明了域之间的差异来自边缘分布和条件分布。JDA算法在TCA算法的基础上同时最小化边缘分布和条件分布的差异,最终生成对分类有效的“域不变”特征表示。
Wang 等人[12]在文献[11]中JDA算法的基础上,进一步改进并提出了平衡分布自适应(Balanced Distribution Adaptation,BDA)算法,证明了JDA算法中提到的边缘分布和条件分布两种分布并不是同等重要的假设。BDA算法可以自适应地衡量边缘分布和条件分布对目标任务的重要性,并分配权重,从而更加合理地进行域之间特征的对齐。此外,基于BDA 方法提出了加权平衡分布自适应(Weighted Balanced Distribution Adaptation,W-BDA)算法来进一步解决迁移学习中的类不平衡问题。
Wang 等人[13]进一步对边缘分布和条件分布适配对迁移任务的重要性展开了研究,提出了动态分布适应(Dynamic Distribution Adaptation,DDA)迁移学习方法,该方法能够定量评估两个分布的相对重要性。此外,基于DDA 方法提出了两种新的迁移学习算法:用于传统迁移学习的流形动态分布自适应(Manifold Dynamic Distribution Adaptation,MDDA)算法,基于深度迁移学习的动态分布自适应网 络(Dynamic Distribution Adaptation Network,DDAN)算法。
Ghifary 等人[14]提出了一种域自适应神经网络(Domain adaptive Neural Networks,DaNN)模型,该模型只有特征提取层和MMD 适配层。通过特征提取层提取的特征,结合MMD 进行数据分布距离的计算,将其与源域数据的分类损失相结合作为网络损失进行训练,从而保证在提高训练精度的同时,使网络能够学到更多“域不变”的特征表示。
Tzeng 等人[15]则基于DaNN的思想将MMD 适配层引入AlexNet 网络,并将其添加到最后一个全连接层之前,即特征提取层之后。与DaNN 一样通过将MMD 距离引入网络损失中,减少特征提取层提取源域与目标域特征的差异,也就是更多地提取“域不变”特征。此外,该模型利用AlexNet 网络更高的表征能力进一步提升了神经网络解决迁移学习问题的能力。
Long 等人[16]首先证明了不同的特征提取层提取的特征分布适配对目标任务的影响,其次在特定的特征提取层引入多核最大均值差异(Multi-kernel MMD,MK-MMD),用于抵消不同核对数据分布衡量准确性的误差,并提出了一种基于深度自适应网络(Deep Adaptation Networks,DAN)的神经网络模型,网络模型结构图如图3 所示。
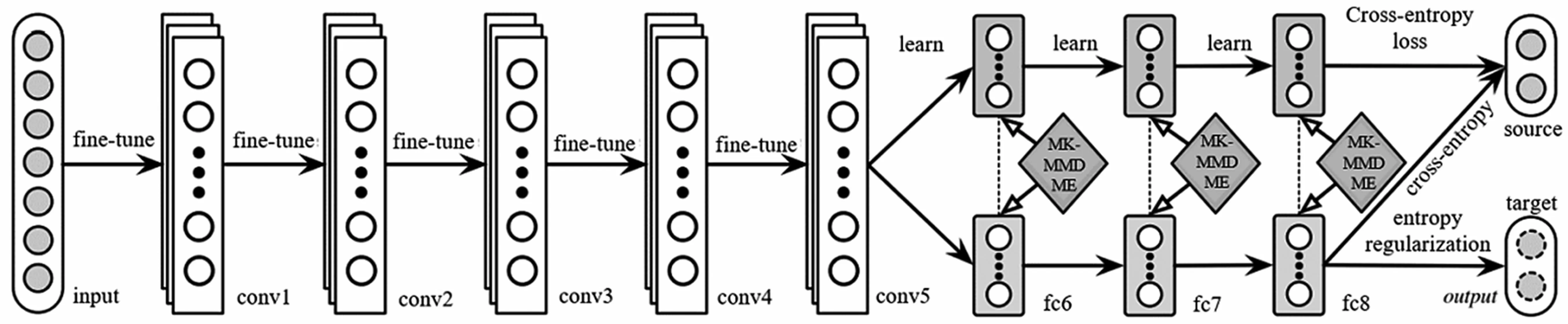
图3 基于AlexNet的DAN 模型[16]
Ganin 等人[17]首先证明了在域适应过程中,若由提取的特征无法分辨是源域样本还是目标域样本,那么该特征更能体现类别特征而不是域特征,即“域不变”特征的假设;其次提出了一种基于对抗的深度迁移网络(Domain Adversarial Neural Networks,DANN)模型。该模型通过利用源域样本有监督地训练特征提取器,之后域分类器判断经过特征提取的源域和目标域样本特征到底是来自源域还是目标域,并计算损失Ldomain,再引入梯度反转使得Ldomain向相反方向传播,达到混淆域分类器的目的,同时设置类别分类器对源域进行测试,计算分类损失Llabel。该模型的训练目标就是最大化域分类损失Ldomain和最小化类别分类损失Llabel。模型总体损失函数为:

式中:参数γ为可人为调整控制训练的倾向性;参数ρ为当前训练轮数与训练总轮数的比值。设置参数λ的目的是让DANN 在训练初期将更多的注意力放到学习源域特征上,使模型更好地收敛。DANN网络模型结构如图4 所示。
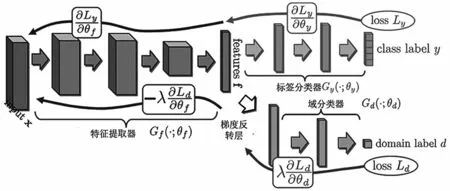
图4 基于对抗的深度迁移网络(DANN)模型[17]
Tzeng 等[18]人基于文献[17]中的DANN 和生成对抗网络(Generative Adversarial Networks,GAN)的思想提出了一种对抗鉴别域适应(Adversarial Discriminative Domain Adaptation,ADDA)迁移学习域适应模型。由于他们先证明了DAAN 中源域和目标域特征提取器参数共享会导致模型在目标域上性能的下降的假设,因此ADDA 采取了部分参数与源域共享的方式,并在鉴别器损失设计上,ADDA 区别于DANN。ADDA 鼓励域鉴别器能够准确分开源域和目标域样本,同时又鼓励目标域特征提取器提取的特征能够混淆域鉴别器识为源域,以实现对抗思想。该模型在域偏移较大任务上取得了较好的效果。
Yu 等人[19]基于文献[17]中的DANN 模型,提出了动态对抗自适应网络(Dynamic Adversarial Adaptation Network,DAAN)迁移学习域适应模型。该模型结合文献[13]中提出的边缘分布和条件分布适配在域适应过程中有着不同重要性的基本假设,为对抗迁移模型同时引入全局域鉴别器和局部域鉴别器两个鉴别器,目的就是在域适应的过程中同时适配源域和目标域的边缘分布和条件分布。模型总损失包括类别分类损失Llabel,全局域鉴别器分类损失Lglobal和局部域鉴别器域鉴别损失Llocal,模型总体损失函数为:
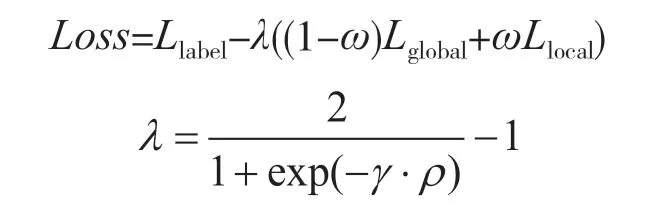
式中:参数γ为可人为调整控制训练的倾向性;参数ρ为当前训练轮数与训练总轮数的比值,参数λ为动态权重因子,目的是在模型训练初期更加注重放到学习源域特征上;参数ω为动态可学习参数,目的是动态评估边缘分布和条件分布的相对重要性,在训练过程中发挥了平衡两个分布对源域和目标域之间的域适应的作用,使模型更加具有鲁棒性。DAAN 网络模型结构如图5 所示。
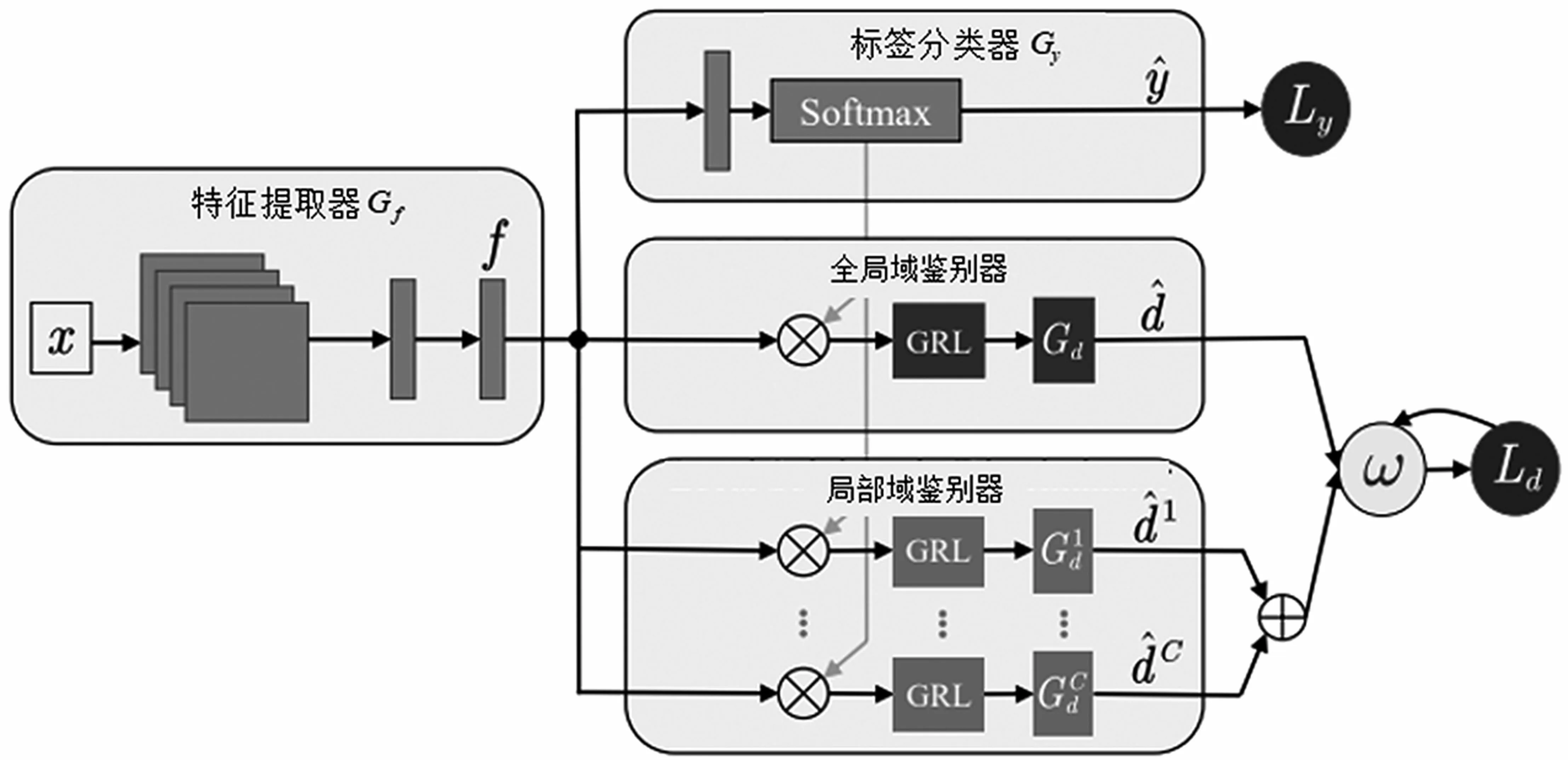
图5 动态对抗自适应网络(DAAN)[19]
2.3 基于参数的迁移学习
基于参数的迁移学习假设源任务和目标任务之间共享模型的部分参数,通过源域任务的先验知识总结,帮助完成目标任务。
Evgeniou 等人[20]提出了一种在正则化框架下的支持向量机参数的迁移学习方法。该方法把支持向量机(Support Vector Machines,SVM)中的参数w针对每个任务分为共同项和特殊项,然后对SVM的学习目标进行扩展,得到参数w实现迁移学习。
Bonilla 等人[21]提出了一种用带高斯过程的层次贝叶斯模型解决多任务学习问题的方法,该模型在任务上用自由形式的协方差矩阵使相互依赖的内部任务模型化,通过共享协方差函数实现参数共享,从而实现任务间的知识迁移。
Karbalayghareh 等人[22]提出了一种贝叶斯迁移学习算法,该算法通过模型参数的联合先验密度将源域和目标域相关联,为源域和目标域中的高斯特征标签分布的精度矩阵定义了一个联合Wishart 分布,以充当传递源域有用信息的桥梁,并通过改进目标后验来帮助目标域中的分类。此外,利用多元统计将矩阵参数的超几何函数以封闭形式导出后验和后验预测密度,从而得到最优贝叶斯迁移学习(Optimal Bayesian Transfer Learning,OBTL)分类器。
2.4 基于关系知识的迁移学习
基于关系知识(Relational Knowledge)的迁移学习方法的基本假设是源域和目标域中某些数据之间关系是相似的。这类方法不要求各领域的数据是独立同分布的,而是将数据间的关系从源域迁移到目标域,也就是在关系领域上解决迁移学习问题。
Mihalkova 等人[23]提出用马尔科夫逻辑网络(Markov Logic Network,MLN)在关系领域上迁移关系知识,该方法基于相关的两个领域存在一种从源域到目标域的实体之间的关系映射。该算法构造了一个基于加权对数似然度的从源域到目标域的映射,在目标域上进行修正,修改后的MLN 可以直接用作目标域的关系模型来使用,实现基于关系知识的迁移。
Wang 等人[24]提出了基于图的知识迁移方法。该方法将所有数据建立为一个混合图,然后利用相似矩阵对类标的相似性进行传播,最后通过构造图的不同部分的相似矩阵实现关系知识的迁移。
3 基于迁移学习的通信辐射源识别方法研究现状
基于迁移学习的通信辐射源识别问题逐渐受到了人们的关注,但是实际上,将应用在其他领域的迁移学习方法应用在通信辐射源识别任务上时,往往得不到较好的效果,这和迁移学习本身的能力与通信辐射源数据的特点有很大的关系,为此一些学者通过结合通信辐射源数据的特点,来改进合适的迁移学习方法,并在识别任务上取得了一定的成果。
陆鑫伟[25]设计了一种基于迁移成分分析(Transfer Component Analysis,TCA)的径向基函数(Radial Basis Function,RBF)深度迁移学习模型。该作者借鉴了参考文献[26]和文献[27]的思路,研究了集成学习理论以及在迁移学习框架下的TrAdaBoost算法,设计了一种基于文献[10]和文献[28]的改进Boosting 迁移学习算法,实验结果表明该算法对通信辐射源识别任务准确率有所提升。最后,该作者研究了Boosting算法中的基分类器训练样本分布修正函数对分类正确率的影响。
秦嘉[29]结合文献[14]中将MMD 度量作为监督学习中的正则化项,以减少潜在空间中源域和目标域之间的分布不匹配的问题,设计了一种深度迁移学习模型,用于解决因信道噪声干扰,待识别(目标域)信号与训练(源域)信号的分布产生偏差,从而导致识别率低的问题,并且分析了由高信噪比信号训练的深度学习模型,在识别低信噪比信号时识别精度不高的原因。此外,在研究了深度学习模型如何提取通信辐射源特征并识别的基础上,分析了不同网络层和分布距离度量函数对通信辐射源信号分类效果的影响,并在不同噪声条件下进行迁移比较,实验结果表明选取合适的网络层和分布距离度量函数能够明显提升识别准确率。
苟嫣[30]考虑到通信辐射源源域样本迁移到目标域的过程中,不同的信号样本实例训练模型的成效有较为明显的差别,也就是对迁移学习效果有不同的影响,因此提出对不同的源域实例赋予不同的权重值,该权重值表示训练样本在目标模型中的重要性[31],并结合极限学习机(Extreme Learning Machine,ELM)思想[32],提出了一种加权的迁移极限学习机算法。该算法在小样本条件下,有效提升了通信辐射源个体识别的精度,且比传统算法均有所提升,证实了该算法的有效性。
刘剑锋等人[33]受文献[34]工作的启发,首先做出域内可聚类性、类间紧密性两种假设;其次结合领域自适应和无监督聚类算法[35]的思想,定义目标域聚类约束和类间紧密性约束,联合建立优化模型,提出了一种基于迁移学习和无监督学习的辐射源个体识别算法。该算法将不同信噪比下信号的特征对齐,使在特定信噪比下训练的神经网络学习到与信道噪声无关的射频指纹特征,从而实现对其他信噪比情况下的信号的高准确率识别。
4 存在问题及发展方向
经过充分的文献阅读与数据分析,可以看出在特定条件下,基于迁移学习的通信辐射源识别方法的相关研究取得了一些成绩,但是该方向仍然存在很多值得进一步探索和研究的问题,主要有以下几个方面:
(1)目前,国内外对本课题的研究几乎都是在实验室仿真条件下进行实验,很难保证在复杂的战场电磁环境下,能够取得较好的识别效果。在战场复杂多变的信道环境下,辐射源指纹受扰动影响大,加大了知识迁移的难度,从而导致迁移学习系统鲁棒性不强,因此如何结合迁移学习进行各维度特征提取是一个重要的课题。
(2)迁移学习方法在通信辐射源个体识别的应用上仍然存在着问题和方法结合不够深入的状况,相关研究更多的是针对特定样本进行算法分析与设计,因此如何通过样本驱动的方式结合迁移学习进行通信辐射源识别,成为该领域的一个新的研究思路。
(3)迁移学习研究目前与深度学习紧密相关,神经网络的可解释性现在作为研究热点受到广大学者关注,如何针对通信辐射源识别的领域特点,在深度迁移学习可解释性上找到解决问题的关键点,是非常值得关注的一个方向。
5 结语
本文对迁移学习和基于迁移学习的通信辐射源识别方法进行了介绍,对一些具有代表性的成果进行了阐述,并探讨了相关方法的算法性能和优缺点,总结了基于迁移学习的通信辐射源识别技术优势和难点,最后为该领域下一步的研究提供了思路和参考。
