A hierarchical optimisation framework for pigmented lesion diagnosis
2022-04-06AudreyHuongKimGaikTayKokBengGanXavierNgu
Audrey Huong|KimGaik Tay|KokBeng Gan|Xavier Ngu
1Department of Electronic Engineering,Universiti Tun Hussein Onn Malaysia,Parit Raja, Malaysia
2Department of Electrical, Electronic& Systems Engineering, Universiti Kebangsaan Malaysia,Bangi,Malaysia
3Institute of Integrated Engineering, Universiti Tun Hussein Onn Malaysia,Parit Raja, Malaysia
Abstract The study of training hyperparameters optimisation problems remains underexplored in skin lesion research.This is the first report of using hierarchical optimisation to improve computational effort in a four-dimensional search space for the problem.The authors explore training parameters selection in optimising the learning process of a model to differentiate pigmented lesions characteristics.In the authors' demonstration, pretrained GoogleNet is fine-tuned with a full training set by varying hyperparameters, namely epoch,mini-batch value,initial learning rate,and gradient threshold.The iterative search of the optimal global-local solution is by using the derivative-based method.The authors used non-parametric one-way ANOVA to test whether the classification accuracies differed for the variation in the training parameters.The authors identified the mini-batch size and initial learning rate as parameters that significantly influence the model's learning capability.The authors' results showed that a small fraction of combinations (5%) from constrained global search space,in contrarily to 82%at the local level,can converge with early stopping conditions.The mean (standard deviation, SD) validation accuracies increased from 78.4 (4.44)% to 82.9 (1.8)% using the authors' system.The fine-tuned model's performance measures evaluated on a testing dataset showed classification accuracy, precision, sensitivity, and specificity of 85.3%, 75.6%, 64.4%, and 97.2%,respectively.The authors' system achieves an overall better diagnosis performance than four state-of-the-art approaches via an improved search of parameters for a good adaptation of the model to the authors' dataset.The extended experiments also showed its superior performance consistency across different deep networks, where the overall classification accuracy increased by 5% with this technique.This approach reduces the risk of search being trapped in a suboptimal solution, and its use may be expanded to network architecture optimisation for enhanced diagnostic performance.
KEYWORDS hierarchical, hyperparameter, optimisation, pigmented lesion, search
1|INTRODUCTION
Dermatology is one of the most important fields of medicine that deals with diseases related to skin and cosmetic problems.This disease accounts for one-third of cancers diagnosed worldwide[1,2]and will continue to be on the rise.Among the common challenges in the practice of dermatology is the exact diagnosis of skin cancer after a thorough physical examination,even at an early stage.Most skin lesions exhibit visually indiscernible characteristics [3], so morphological features that are looked after by dermatologists in their diagnosis include colour, boundary regularity, size, and texture of the examined skin [4, 5] using either ABCD rule, a seven-point checklist,or Menzies method [6, 7].This abnormal discolouration in the outer skin layer can be classified into benign and malignant skin lesions.While benign lesions are generally not invasive(i.e.non-cancerous)and do not pose any threat,malignant cells are aggressive.They are more likely to metastasise and destroy vital organs.The examples of benign skin cancers include lichen-planus like keratosis (Bkl), dermatofibroma (Df),vascular lesions(Vasc),melanocytic nevi(Nv),and actinic keratoses/Bowen's disease (Akiec), whereas the cancerous forms are such as melanomas (Mel) and basal cell carcinomas (Bcc).Even though a benign lesion would not require surgical interventions,lesions such asVascandAkieccan become invasive and spread into deeper layers of the skin if left untreated over long periods.If cancer is suspected malignant or a lesion cannot be diagnosed by routine methods, histologic examination and cytology testing would be necessary to confirm the diagnosis.
Following the upward trend in the incidence of pigmented lesions in the past 50 years[8],the future of dermatology seems promising.But the lack of experienced and qualified dermatologists on a geometrical scale poses a major setback.Therefore,most of these responsibilities fall on general practitioners who are not properly trained for this matter.Because of the low level of confidence in the diagnosis, any suspected skin lesions, the majority of which turned out to be benign[9],would be excised for pathological diagnosis and grading.This results in unnecessary biopsied procedures that can be painful and discomfort for patients.For this reason, computer-assisted classification tools have been seriously considered in this application.While it is often favourable to establish a comprehensive classification system for an elaborated class of problems, most works considered a two-class problem (i.e.benign or malignant)[10,11]to simplify the network's decision boundaries.The larger class sizes considered in this area of study are up to seven classes using standard datasets,for example,International Skin Imaging Collaboration (ISIC) and Modified National Institute of Standards and Technology(MNIST)database[12-14].
The approaches of deep learning in science and engineering have gained immense interest over the years.Their applications have substantially benefited society in many ways,including in decision-making processes and implementation activities.Among the deep learning methods, computational neural network(CNN)models are the most commonly used for image recognition.The weights and architecture of a CNN are popularly studied as they influence its performance and efficiency.A recent attempt in [15] improved the existing methodology used for the implementation of activations and pooling operations in CNN for more effective handling of features data.The same authors also reported a combined CNN and Graph Convolutional Network for image-level representation learning in [16] to enhance breast cancer detection.The results from these improved approaches are shown to be significantly better than those from the conventional methods.Another strategy of improving classification accuracies is via a proper training hyperparameters value selection.These parameters affect various criteria on how a model is trained, the learning speed,and their adaptation to the problem at hand.So,the choice can lead to vastly different outcomes.The varied parameters may include (1) solver type, (2) epoch number, (3) mini-batch size,(4)initial learning rate,(5)validation frequency,and(6)gradient threshold.It has been pointed out in many works of literature[17-19] that the initial learning rate is the most important configurable hyperparameter in the model learning process.It determines the model's learning efficiency and adaptation speed.This is followed by the epoch value and mini-batch size,which underpin the number of times a set of data is passing through the same network.Meanwhile, the gradient threshold determines the convergence speed.There is no golden rule to decide the best-suited values for all tasks as they are known to be dependent on the data the model is trained on.An optimal combination of parameters is sought to best solve the given problem.The various method of tuning these values ranged from the common practice of either brute force or grid search to auto-search engines.The former approaches can be laborious and experimentally exhaustive, and it also demands knowledge of how each parameter influences the learning process.However,due to the large dimensionality of data,it is not possible to solve this problem efficiently with human expertise.Thus,algorithmic development in the latter strategy is preferable.This includes minimisation of a fitness function,such as by using either genetic algorithm (GA), Bayesian network, or gradient descent, to iteratively optimise a given function or cost measure [11, 20, 21].Randomised adaptive search procedures based on statistical approaches such as the Markov decision process and Monte Carlo Tree Search has also gained popularity [22].Even though global optimisers such as GA and particle swarm optimisation (PSO) are among the common methods for finding near-optimal solutions, it is identified that the search for a correct solution can be refined with local methods[23].
The majority of prior works in dermatology focussed on finding the best network hyperparameters for the problem at hand[13,14,24,25].These works determined the values based on intuition and prior experiences at the beginning of their process before the performance-guided search converged to a solution close to optimum.Other studies[14,26]used the brute force technique in determining the suitable training hyperparameters and pointed out the urgency and necessity of a less intuition-driven hyperparameter search.Automatic optimisation of training hyperparameters using either global or local or hybrid algorithms has been proven successful in many applications in other fields[27-29].Among these optimisation tools,Bayesian optimisation (BO) that works by incrementally building a probabilistic model during a search is the most studied.Atef and Eltawil [30] implemented BO to optimise hyperparameters used in the training of different structures of stacked Long Short-Term Memory(LSTM)for electricity load consumption forecasting.This technique allows an accurate and unbiased comparison of the performance of different models.Using the same technique,Yao and Chen[31]showed improvement in the result of the Deep Belief Network(DBN)through optimisation of the initial learning rate, momentum, and weight loss.Hyperparameters tuning for application on the same network was also attempted by Kuremoto et al.[32] using PSO.This algorithm iteratively searches in a region defined by the best success of neighbourhood particles.The authors found the proposed method achieved a better prediction rate when compared to the multilayer perceptron and Arima model.Recently, GA was proposed in [11] as a way to successfully optimise hyperparameters for the training of the GoogLeNet-Inception v1 model for two-class skin cancer problems:NvandMel.This technique randomly generates different populations of solutions (generations) and was shown able to effectively identify the optimal values even in the first generation.From the review of the literature, we concluded that derivative or gradient-based optimisation techniques, such as sequential quadratic programing,are underexplored in this area.This may be largely due to its computational expensive nature.Even so,this technique has been successfully applied in various optimisation problems in other domains.This includes optimisation of homotopy in the design of microwave and millimetrewave filters [33].The simulation study showed the outputs converge with the optimised filter responses.Khanum et al.[34]applied gradient-based(global and local search)algorithms with considerable success in solving 15 benchmark functions.This hybrid algorithm was shown to produce a low error rate than evolutionary algorithms (EAs).Nakauchi et al.[35] used the global search method to evaluate all possible solutions in determining optimal filter set(for target detection),followed by a local search approach to adjust the filter parameters in their experiment design.It is the objective of this study to adopt a hierarchical gradient-based global-local optimiser for automatic hyperparameters tuning in training GoogLeNet networks for recognition of an increased number of pigmented lesion classes(up to seven).The contributions of this study are as follows:
(1) A demonstration of a dual hierarchical search framework for four-degree freedom (i.e.epoch number, mini-batch size, initial learning rate, and gradient threshold) optimisation problem in a near-continuous search space;
(2) A quantitative evaluation of the effects of varying training hyperparameters on the prediction accuracies;
(3) A side-by-side comparison of the outcomes of our methodology with state-of-the-art approaches, before repeating the comparison for different deep networks.
All the following works were carried out using MATLAB R2020b running on a single GPU Tesla K80 256 GB RAM.
2|METHODOLOGY
In the following section, we describe the CNN model and dataset used in testing our hierarchical tuning method.We adopted a dual-level optimisation approach to solve the problem of model learning.
2.1|Pretrained classification model
There are different variations of pretrained CNN available for use.These networks differ in their depth and arrangement of layers initially designed for different purposes.Some architectures, such as Visual Geometry Group (VGG) and Residual Network (ResNet), have deeper depths (increased number of learnable layers) and wider widths to learn a complex hierarchy of features in predicting the most probable labels of a given problem.Dense Convolutional Network (DenseNet) is another popular network, where each layer is connected to all the other layers for maximum information flow and feature reuse between layers.This strategy of concatenating feature maps allows the network to learn more compactly using fewer parameters.Others such as AlexNet and SqueezeNet have shallower architecture, which places smaller demand on computational resources.This explains their higher preference within the research community.To continue from the previous study in [11],GoogLeNet-Inception v1 was used as the demonstration model for the following discussion of the proposed method,before we present the results obtained with other CNN networks.
The basic structure of the GoogleNet-Inception model is shown in Figure 1.This network has nine inception modules repeating the convolution, pooling, softmax, and concatenation processes.The auxiliary softmax classifiers are to reduce the vanishing gradient problem, hence providing better output.The output of the classifier was modified as seven classes using thelayerGraphfunction following the labels of the used dataset before the commencement of the model learning.

F I G U R E 1 Basic GoogLeNet-Inception v1 structure
2.2|Hierarchical optimisation and mathematical formulation
The hierarchical framework involved the use of global search followed by the local search method for determining the best value of hyperparameters for dermatology applications.No statistical difference was observed in [11] on learner type and random seed number with grading accuracies, so the hyperparameters considered are 1.epoch number(n), 2.mini-batch size (β), 3.initial learning rate (η), and 4.gradient threshold value (ψ).These parameters were specified in the training options before the training started at each (optimisation) iteration.The rest of the parameters include random seed number of 1, and stochastic gradient descendent (sgd) as a network optimiser because of its rapid convergence and fast training speed.We used the default value for most of the other learning parameters,such as momentum rate of 0.9 and learn rate factor 0.1,because previous research in[36]has established that they do not affect the performance of a network, whereas others[37, 38] showed that these default values produced reasonable results.The model performance was concurrently validated during the training process using a validation frequency of five(instead of default value 50)to reduce the computing time.The four steps involved in the iterative process are as followed.
Step 1 Initialisation and search space.All parameters should be in a non-zero, real positive form.Specifically,ηandψtake continuous positive values,whereasnandβare in positive integer forms.To avoid the search in the negative direction, lower limits are chosen from regions near to origin as shown in Table 1.We do not use an unbounded positive system because evaluating a large number of points (near infinite) in sampling a wide region (i.e.fourdimensional search space) can be computationally impossible and unrealistic.Thus, the upper limits in Table 1 are chosen as feasible solutions.These bounds values are of subjective decisions, partly based on previous implementations by the authors in [38-40],but they are necessary to solve the large search space problem—as the focus here is to evaluate the performance of our technique in optimising model training.It is worth mentioning that these ranges are much larger than those previously reported in [11, 13, 14] for the same dataset, with over 100 billion possible combinations (solutions).The starting point (i.e.hyperparameters'value)in the global stage is selected using a Twister pseudo-random number generator (rng= 1)from within the bounds specified in Table 1.The globally optimised solution is passed to the local stage to be used as its starting point.
Step 2 The search and early stopping criteria.The optimisation problem in Equation(1)is modified from the work in [11].Instead of placing greater weight on the training error (i.e.3-order magnitude above validation error)in the objective function to be minimised,we enforce an equal penalty on the deviations in training,Tacc,and validation prediction accuracies,Vacc,from the perfect score of 100%(i.e.κT=100-TaccandκV= 100-Vacc).This is to reduce the risk of overfitting training data and to promote generalisation to unseen or evaluation data.This function also takes into account the learning adaptation time,T.

T A B L E 1 Upper and lower limits for each hyperparameter used in the search

Since the efficiency variables in Equation(1)depend on the chosen hyperparameters, this problem is transformed into the optimisation problem of hyperparameters.The termination criteria include either when the optimisation iteration has exceeded 200 times (in local stage), changes inf<10-3, step tolerance <10-10, or when the validation accuracy stops increasing at a rate of at least 1% from its previous value for more than 30 consecutive validation times.
Step 3 Hybrid global-local search.The solver used in finding the minimum of the objective function in Equation (1) is by invoking the non-linear optimisation toolbox of Matlabfmincon‐Sequential Quadratic Programing (SQP).This standard-derivative-based method is used to find the minimum of the problem in the presence of bound constraints.This algorithm transformed the differentiable function represented byf(xk):Rnin Equation(2)into several subproblems,that is, quadratic approximations expressed based on the Lagrange function, to be solved via an iterative process,k.

wheredis the search direction of descent,Hiis a symmetric positive definite matrix for theith objective function.The objective-based search and key steps of this dual-stage process are summarised in Table 2.The global search launched 200 trial points in a near-continuous space, only the points located within the bounds in Table 1 (represented byMth points in Table 2) were picked and evaluated.The best solution from each iteration is identified based on their function value before moving on to the next point.This process continues until thelast trial point is evaluated or when termination criteria are satisfied.The solution or point that gives the lowest objective function value is selected as the global optimum and is used in the local stage.

T A B L E 2 The hierarchical optimisation process of training hyperparameters
The same problem in Equation (1) and the strategy in Equation (2) were adopted in the second stage.The boundary conditions are shown in Table 1.In this stage, for each iteration, the last solution is used as the starting point of the next iteration until the termination condition is satisfied.Finally, the hyperparameters set that produced the lowest function value in Equation (1) is chosen as the best solution.This hierarchical order of the hyperparameters finetuning process before the model testing is also shown in Figure 2.
Step 4 The statistical significance test.The significance of hyperparameters value on the distribution ofVaccvalues during the optimisation stages was evaluated using the Multivariate Analysis of Variance(MANOVA) method using SPSS ver.23 (SPSS Inc.)software,ρ<0.05.The obtained data are not normally distributed, so a non-parametric Kruskal-Wallis oneway ANOVA test is used to independently analyse the results.
2.3|Images handling and distribution
This work used the MNIST database of the HAM10000 pigmented lesions dataset [41] freely available for public use in(http://www.kaggle.com) for demonstration.There is a total of 10,015 dermatologic images of seven classes from different sources available.The image distribution in each class is shown in Table 3.These images were randomly split using seed number 1 following a percent ratio of 60%: 15%: 25% for training, validation, and testing purposes.No same images are put in these sets.All images were resized using theimresizefunction to a size of 224 × 224 × 3 to match the network input.We used theimageDataAugmenterfunction to increase the number of training images.This is done by rotating the training images with a random angle of ±10°, ±20°, and translating the images in a random vertical and horizontaldirection of ±10 pixels.In addition, each original image was also flipped in both vertical and horizontal directions using theflipdimcommand.This process produced six images of different augmented schemes for each original image as shown in the centre block of Figure 2.
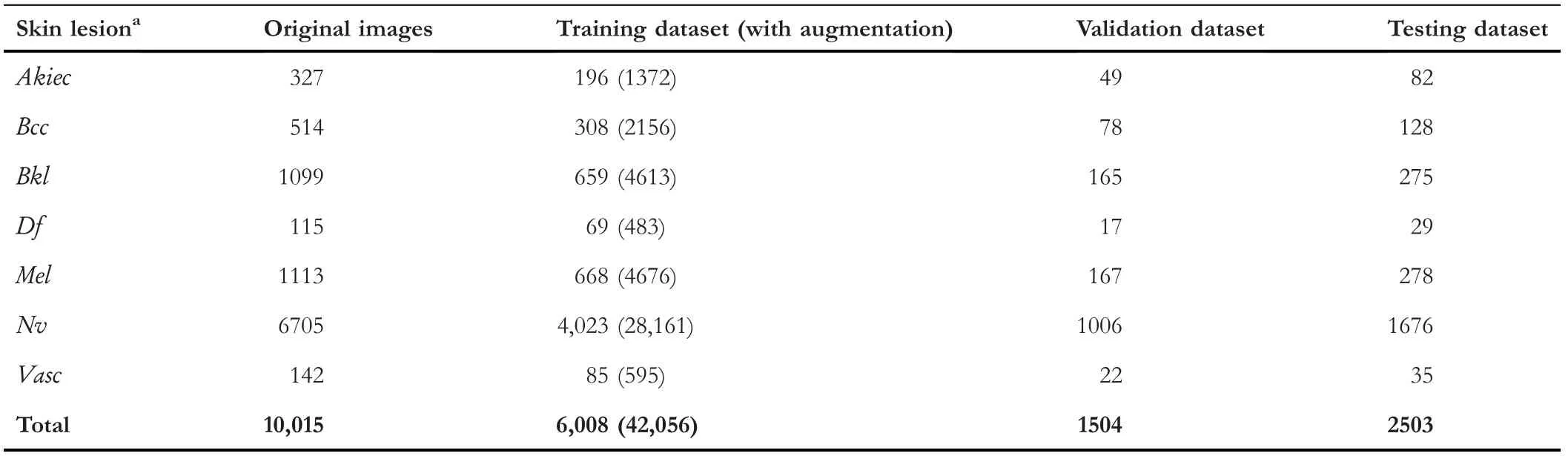
T A B L E 3 Distribution of original and augmented skin lesion images

F I G U R E 2 Dual-stage optimisation framework and pigmented lesions classification pipeline
In the earlier experiments, after the optimisation model is established, we performed 10 runs in the global tuning phase to check the classification accuracies of the optimised models trained with and without image augmentation.Our findings showed that both training and validation accuracies are, on average, improved by 12% and 9%, respectively, with the addition of our augmentation scheme.So, we report in the following only results with the use of image augmentation on the training set.We did not attempt to address the imbalanced class distribution problem to prevent overoptimistic outcomes as this represents real-world scenarios when benign lesions are most examined.
3|RESULTS AND ANALYSIS
Shown in Figure 3 are the errors in the final training (κT) and validation accuracy (κV) at each search optimisation operation(N).The search process was iterated 220 times in the globalstage, which is the maximum count of potential trial points(and local trial points) evaluated.The local stage was set to perform for 200 iterations in the programing, but it was terminated earlier at iteration #67 when the limit of step tolerance has been reached.The GPU computing time spent to complete the global and local optimisation process is given by 48 and 23 h, respectively.

F I G U R E 3 Plots of errors in percent training(κT)and validation accuracies(κV)versus iteration count index,N,from(left)first stage:global search,and(right) second stage: local search
The presence of outliers shown in the left panel of Figure 3 indicates the optimisation process that yields suboptimal solutions as the global search progresses.This observation is not identified in the local search space that finds feasible solutions within the vicinity of the initial solution [42].This study consideredTacc>80% (orκT<20%) as the ability of the optimisation problem to converge.A total of 11 of 220 iterations (or 5%) and 55 of 67 iterations (or 82%) in the case of global and local search, respectively, met this threshold.The mean (SD) prediction training/validation values calculated from converged points were recorded as 83.6(5.6)%/78.4(4.44)% and 84.5(2.2)%/82.9(1.8)%, respectively.The validation accuracies of all points (values of the parameters) found from global (blue) and local search (red open circles) are plotted in Figure 4.The distributions of these values are shown diagonally as histograms.The statistical results in Table 4 show a significant relationship (ρ<0.05) observed for all hyperparameters except for gradient threshold in the case of global search,while no relationship was found between the prediction outcomes and hyperparameters value in the case of local search.This is supported by the decrease in the standard deviation of their histogram.No statistical test can perform on the relationship between epoch value and accuracies as there is no change in its value during the search.The best hyperparameters set obtained from this process are:n=7,β=256,η= 0.0203 andψ= 0.195.
The model trained on the full training set with early stopping was used to predict the output class of the test images that have no role in the learning process shown in Figure 2.The model's classification outcome is plotted as a confusion matrix in Figure 5.The classification accuracy is calculated from the matrix in Equation (3) as 85.3%.The percent value shown in the diagonal of this matrix is the classification precision for each class label expressed in Equation (4).The mean precision is given by 75.6%.Other performance metrics are sensitivity and specificity, given in Equations (5) and (6),calculated as 64.4% and 95.9%, respectively.
Accuracy,acc:

Precision,prec:

Sensitivity,sen:
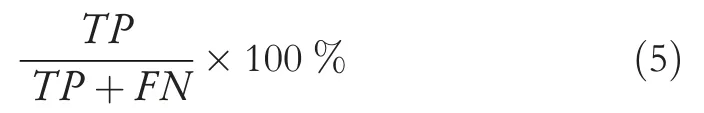
Specificity,spec:

where a true positive (TP) is a class member correctly predicted as a specific class label.A false positive (FP) is a nonclass member incorrectly predicted as a class member, a false negative (FN) is a class member misclassified as a non-class member and a true negative (TN) is when a non-class member is correctly classified as a non-class member.
There are very few studies in this area that deal with training hyperparameters optimisation.So, for a fair comparison between our system and methods in the literature [11, 30,32, 34], we implemented prior approaches using our dataset and the same network in Figure 1.The search constraints are defined in Table 1.These competing methods are genetic algorithm (GA) [11], Bayesian optimisation (BO) [30], particle swarm optimisation (PSO) [32], and gradient-based local search method (LS)[34].In their application, the optimisation of the objective function in Equation(1)was repeated 50 timesto avoid selection bias.The optimal solution(i.e.produced the lowest function value) chosen at the end of this iterative procedure is used in training the ‘best’ model.A starting point is required in the local search method, so step 1.1 in Table 2 is followed.In Table 5,we present the classification performance of these models tested on our testing dataset for comparison.
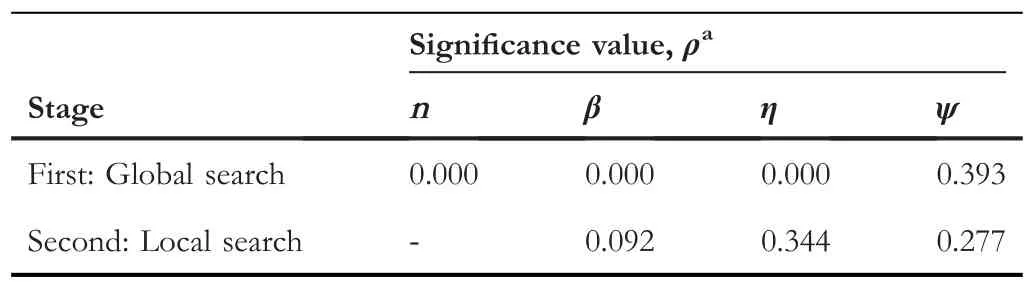
T A B L E 4 Non-parametric correlation tests between validation accuracies and hyperparameters values
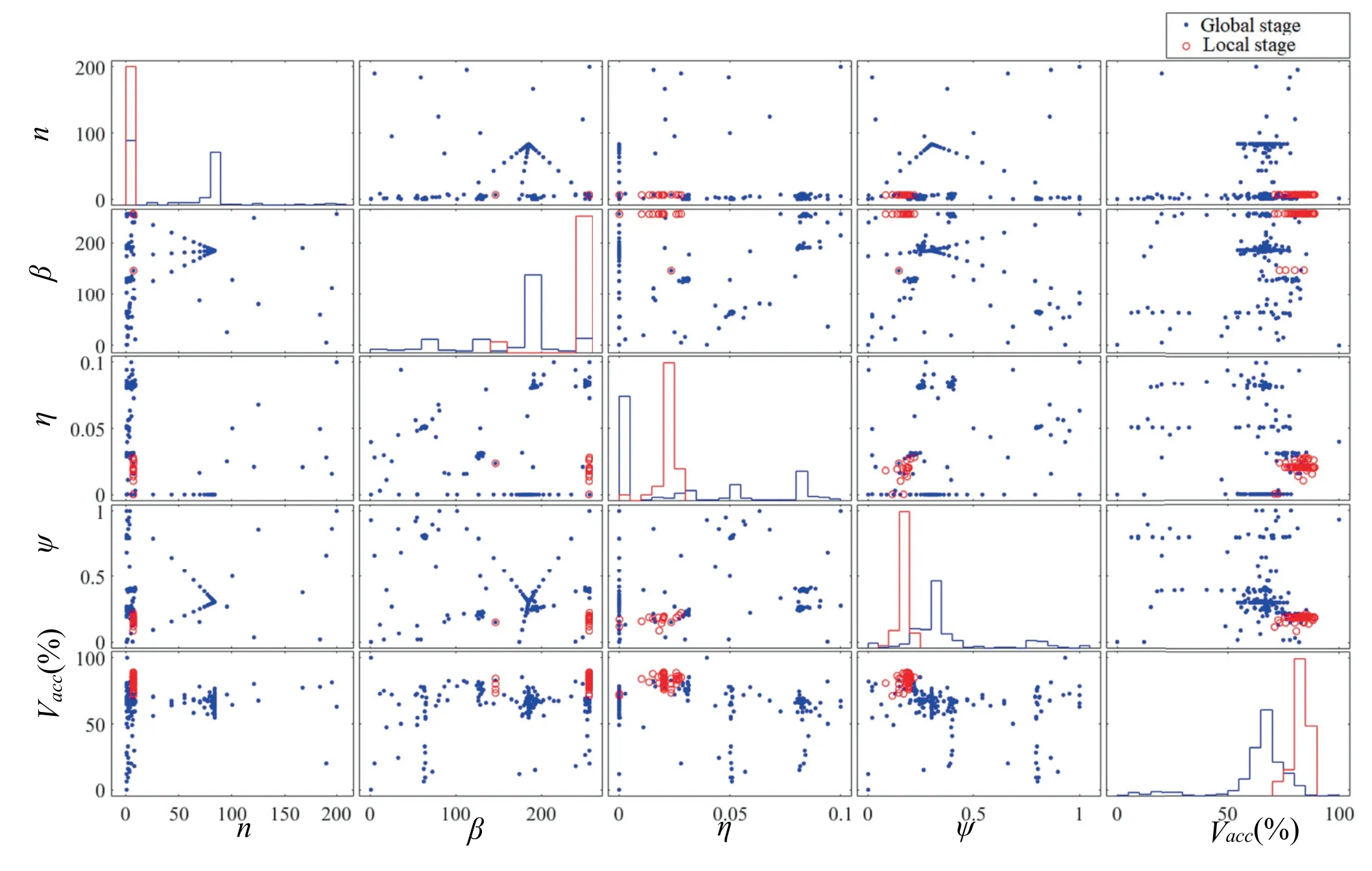
F I G U R E 4 Relationships between hyperparameters:epoch number(n),mini-batch size(β),base learning rate(η)and gradient threshold(ψ),and the final percent validation accuracy (Vacc) from the first stage: global search and the second stage: local search.Diagonal shows stair-step histogram of each variable
Overall,our results in Table 5 show a superior classification performance with respect to other existing approaches.The increase in the average accuracy, precision, sensitivity, and specificity rates are calculated as 3%, 11.5%, 5.6%, and 2%,respectively.But the sensitivity and precision performances of all methods are generally low.To investigate this,we plotted the sensitivity and precision measures of the models against lesion type in grouped bar graphs in Figure 6.

F I G U R E 5 Classification model performance evaluation
For the completeness of this work, we also tested and evaluated these optimisation methods on different CNN architectures using the same experimental design.We could implement optimisations when training any CNN architecture,but in practice,our experiment is limited by our GPU capacity,where memory is too small to fit large models.Thus, in our demonstration, we chose ResNet-18, AlexNet, and Squeeze-Net as they are lightweight and less computationally demanding; without a loss of generality and for the sake of comparison,we report the testing accuracy of these models in Figure 7.
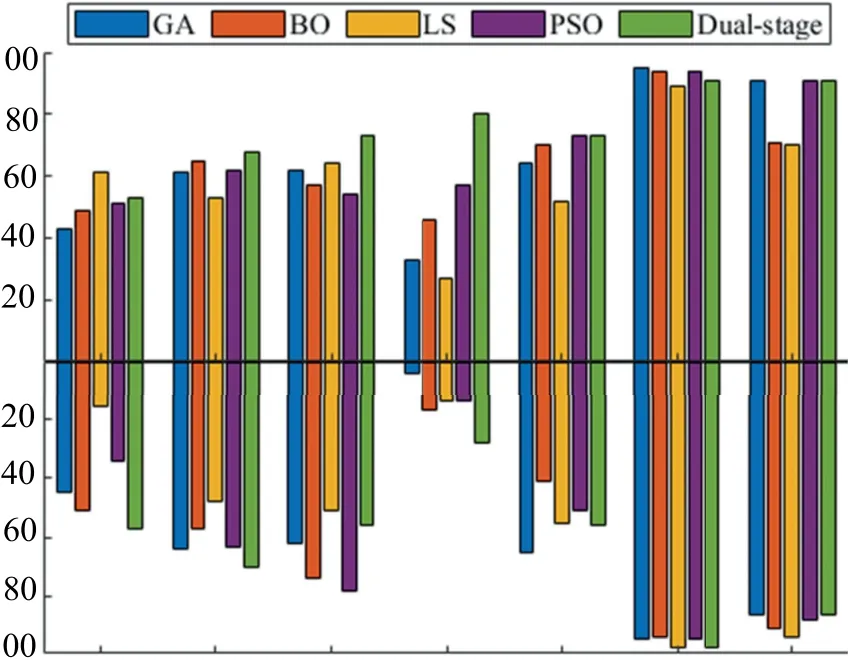
F I G U R E 6 Classification precision and sensitivity of different optimisation methods against skin lesion class labels

T A B L E 5 Diagnostic performance comparison of model optimised using our method and the state-of-the-art search techniques using the same dataset and experiment design
4|DISCUSSION
This work improved the efficiency of the conventional CNNs,which are built and trained to optimise their performance for a specific task, through the proper control of training parameters.We used a dual-stage optimisation method to search for an optimal solution for training hyperparameters in a nearcontinuous space.This strategy supports decision-making and identifies the most favourable learning parameters solution to promote convergence of the learning, along with a high-efficiency gain in terms of experimenting time and efforts.From Figure 3, outliers in the plots are evidence in the first optimisation phase (left panel) as the search expanded and covered a broad range for different sets of variant parameter values.So, the possibility exists that some points failed to converge, resulting in early termination of the process with inferior results.The training and validation accuracies from the global method in this diagram have higher SD in their distribution given by 15.2%and 17.6%,respectively,in comparison to the local results.In the latter case, they are given by 3.9%and 2.62%.Since this work evaluated all feasible points within the defined bounds, some of these points are not in approximate optimal point, leading to poor classification accuracies.So,a large fluctuation in the accuracies can be visibly seen.The local method that depends on the output of the global search showed better consistency.This process looks for the minimum in the neighbourhood space.The improvement in the optimisation performance after the local method is also noticeable with the validation accuracies increased from 78.4(4.44)%to 82.9 (1.8)%.During our experiments, we noticed a slow but steady increase in these accuracies towards the end of each training iteration.Thus,the errors in predictions would be lower than in Figure 3 with the relaxed termination criteria.

F I G U R E 7 Classification accuracy of deep networks optimised by different search methods
A statistical investigation into the correlation between the distribution of hyperparameter values andVaccin Figure 4 showed positive statistical significance (ρ<0.05), except for the gradient threshold value in the global stage.We also documented a negative statistical effect of all parameters in the local search, as can also be seen from the negligible spread in the results.While it is safe to say that the gradient threshold has minimal to no effect on the model learning efficiency, an interesting observation worth noting is that a large epoch number does not guarantee the learning efficiency.This is in contrarily with the mini-batch size,where most of the solutions using large mini-batch size produced goodVaccas agrees with the work in [11].We are interpreting this finding as the optimisation system that may only need to identify appropriate initial learning rate and mini-batch value in their process to reduce the search dimensionality and computational complexity using the current dataset.While the results for most hyperparameters in Table 5 are in agreement with that from the state-of-the-art techniques, the epoch number showed an observable difference.Since the computing time is one of the factors to be minimised in our objective function,we do not exclude the possibility that this is an effect of search strategies that attempt to find a balance between computing time and classification accuracies.These search methods are stochastic where randomly distributed points are generated in the feasible space in each run.These random effects are even more pronounced with the increased degree of freedom of the problem and large working space,rendering differences in the results produced by these techniques.This process of optimising computing time is evident in the hybrid global-local search and Bayesian methods that demand higher computational cost and resources,where all points are evaluated before the process converges to a solution with a small epoch value that has a direct influence in reducing the computing speed.At the same, the more extensive and rigorous search (i.e.larger variations)observed for batch sizes and initial learning rates in Figure 4 are likely to compensate for the lack of the epochs,without compromising the classification accuracies.
This research deals with a four-dimensional search problem,suggesting that there is high complexity in identifying globallocal minimum in the space.It is encouraging to note from Table 5 that our proposed approach has better classification accuracy when compared to the existing systems that adopted different search strategies.We attribute this to the following reasons: (1) GA, BP, and PSO used scattered search patterns and random probabilistic models in their search.They cannot prevent their algorithm from getting stuck in a sub-optimal solution among multiple suboptimal locations.Thus, different optimisation techniques find a different best solution.(2) LS method used gradient-based search,but the search is limited to the region proximal to the initial point.Therefore,the selection of the starting point is important,in terms of the quality of the final solution and convergence rate.(3)Our technique evaluates multiple solutions at the global level before the local stage widens and deepens the search by iteratively improving the objective function using its preceding solution.This allows the CNN model to learn better using their solution, leading to improved diagnosis, especially in reducing theFP(increased precision by 11.5%)andFNrates(sensitivity by 5.6%).
Our results in Figure 5 show the best classification accuracy inNvandVascclasses,whereas theAkiecandDfclasses have the least recognition rate.This trend is in general agreement with all optimisation models in Figure 6.We are far from the only ones to recognise that one of the most probable factors causing this is the small data size and imbalance dataset used, as iterated in previous studies [13, 14, 43].And a large number of images from these groups misclassified as theNvclass implies the overfitting of the model to theNvclass label.Even though all models were trained on a smallVascclass training set, most can discriminate it (sensitivity >80%) from other skin lesions.This benign lesion can easily be distinguished by its red colour and regularity in its boundary even by inexperienced personnel.SinceMelandBccare aggressive forms of lesions, it is imperative to recognise these dermatologic disorders to allow effective treatment and prevent the spread of the disease.At the same time, misdiagnosis as these tumours can lead to unnecessary surgical excision.In the aspect of successful lesion diagnosis, our technique showed significant superiority in its ability to distinguishBcclesion(sensitivity score ~71%) using its optimised model.But it losses out to the GA method when identifyingMelimages.Meanwhile, in terms of minimising false alarm rates, our approach demonstrates better ability in preventing misclassification of negatives as positives (i.e.comparable or better precision result for most skin lesion types).Most of these misclassified images have a similar appearance to other lesions.Some images also suffer from vignetting effects (in ~15% of testing images), or are outliers, such as non-skin images (i.e.lips and ear helix parts).Other factors that may hamper the performance of our system include the presence of hairs on skin lesions; thus, the current system can be improved with preprocessing.Meanwhile, the results from testing our system on other deep networks in Figure 7 follow a similar pattern as in Table 5.The prediction accuracies are,on average,increased by 5% when compared to other search techniques.Since each network has vastly different network depths and characteristics,and different learning abilities of features representations,there exists some variation in the classification performance.GoogleNet and ResNet-18 that have deeper depth layers produced generally better results(i.e.testing accuracy increased by 6%)at the price of the increased computational cost(i.e.of about a factor of 1.5 times per iteration) than their shallower counterparts.It should also be mentioned—even though it is not within the scope of this study—the network architectures can be further optimised using the above-mentioned techniques,and a larger training set can be used to allow the model to learn a richer representation of the skin lesions' characteristics to improve the performance of the system.
Our experiment conditions represent the majority of works in the field of computational intelligence.We have not considered the cross-validation technique in [14], which may produce over-optimistic results, nor do we perform weight balancing strategies in addressing imbalanced datasets[13,14].Our proposed system produces a better solution compared to the existing methods.While our presentation may have advantages in these aspects, it is important to recognise that our technique requires more computational time (~3 times longer than the majority).In the future, we may implement a more efficient strategy to cover a larger and more representative range of tunable parameters, possibly using multiple search spaces for fast computational performance while maintaining search accuracy.We also wish to widen our focus by incorporating our strategy to other tasks, such as optimising the network structure or hyperparameters or pruning weight balancing to address the common challenges of the imbalanced dataset.
5|CONCLUSION
To the best of our knowledge, this is the first work that has been done to explore the performance of a hierarchical gradient-based search method in the field of pigmented skin lesions.We found an increased convergence in the learning process from the global to the local stage, even with earlystopping criteria.Our statistical analysis showed a positive significance in the correlations between most of the considered hyperparameters with the classification accuracies.We recommended mini-batch size and initial learning rate as training parameters that demand fine-tuning to obtain good classification outcomes.Using the dual-stage optimisation system,we succeeded in discriminating seven classes of pigmented lesions with an accuracy of 85.3%and a precision value of 75.6%.The classification sensitivity and specificity are given by 64.4% and 97.2%, respectively.These results are notably better than available approaches because,in addition to the optimisation of all feasible points,this system deepens the search to determine the best solution.This minimises the risk of getting stuck in a suboptimal solution from sampling a large search space.This approach also demonstrates good consistency in its performance and better classification accuracy when tested against different CNN models.In future, the implementation of the proposed technique on network architecture optimisation and weight balancing strategy can be investigated to improve model learning efficiency and classification performance.
ACKNOWLEDGMENTS
This work was supported by the Ministry of Higher Education Malaysia(MOHE)through Fundamental Research Grant Sche me (FRGS/1/2020/TK0/UTHM/02/27).We also acknowledge a partial support of Universiti Tun Hussein Onn Malaysia under TIER1 Research Grant(VOT H766).
CONFLICT OF INTEREST
None.
DATA AVAILABILITY STATEMENT
The data that support the findings of this study are available in‘The HAM10000 dataset, a large collection of multi-source dermatoscopic images of common pigmented skin lesions.2018.https://doi.org/10.7910/DVN/DBW86 T’.These data were derived from the following resources available in the public domain: http://www.kaggle.com.
ORCID
Audrey Huonghttps://orcid.org/0000-0002-4505-5860
杂志排行

CAAI Transactions on Intelligence Technology的其它文章
- Deep learning for time series forecasting: The electric load case
- Head-related transfer function-reserved time-frequency masking for robust binaural sound source localization
- A spatial attentive and temporal dilated (SATD) GCN for skeleton-based action recognition
- Improving data hiding within colour images using hue component of HSV colour space
- Several rough set models in quotient space
- Shoulder girdle recognition using electrophysiological and low frequency anatomical contraction signals for prosthesis control