基于谱结构融合的多视图聚类
2022-04-06刘金花钱宇华
刘金花 王 洋 钱宇华
1(山西医科大学汾阳学院 山西汾阳 032200)
2(北方自动控制技术研究所 太原 030006)
3(山西大学大数据科学与产业研究院 太原 030006)
(liujinhua741852@163.com)
聚类算法作为模式识别、计算机视觉和机器学习最关键的技术之一,旨在发现数据内部潜在的分区结构.经过多年研究许多高效的聚类算法已经被提出,如层次聚类的方法、k-means的方法、矩阵分解的方法、谱方法等,然而这些算法都是针对单视图数据的.随着各种采集技术的发展,具有异构表示的多视图数据在学术界和工业界大受欢迎[1].例如,图像可以通过不同描述符来提取特征,如傅里叶形状描述(Fourier shape description, FSD)、RGB值、尺度不变特征变换(scale-invariant feature transform, SIFT)、梯度方向直方图(histogram of oriented gradient, HOG)等[2-3];文学作品被翻译成各国语言进行出版;一则新闻被不同媒体或通过不同形式报道.显然,多视图数据提供了更丰富的信息来揭示对象的内在结构[4].
多视图聚类的目的是利用来自不同视图的异构信息提供一个综合的聚类结果,关键问题是如何有效融合异构信息[5-6].现有的多视图聚类算法有:基于非负矩阵分解(nonnegative matrix factorization, NMF)的方法、基于图的方法和基于子空间的方法等.如文献[7]首次提出了联合非负矩阵分解的多视图聚类方法,首先通过非负矩阵分解得到各视图共享的系数表示矩阵,然后再对该系数矩阵执行k-means聚类.为了保留原始数据局部几何结构,文献[8]提出了多流形正则化的多视图非负矩阵分解算法,该算法使聚类效果得到大大提升.相比之下,基于图的多视图聚类算法是学习一个各视图共享的图信息.Kumar等人[9]利用协同正则的方法最小化每对视图之间的差异.聂飞平等人致力于研究自动加权的基于图谱的多视图聚类,典型的模型有AMGL[10](parameter-free auto-weighted multiple graph learning)和SwMC[11](self-weighted multiview clustering with multiple graphs),然而,基于图的多视图聚类对输入的初始图是敏感的.
近年基于子空间的聚类方法表现出了令人瞩目的性能,主要是由于子空间聚类方法是通过子空间自表示的方式来揭示数据点之间的关系,从而构建相似图.文献[12]提出了潜在的多视图子空间聚类算法(latent multi-view subspace clustering, LMSC),它们利用不同的投影矩阵将多视图数据映射为一个共同的表示矩阵,然后再进行子空间聚类.文献[13]提出了潜在嵌入空间的多视图聚类模型(multi-view clustering in latent embedding space, MCLES),也是先将各视图数据映射为共同的表示矩阵,然后再学习全局相似图进行谱聚类.文献[14]利用希尔伯特·施密特独立准则(Hilbert-Schmidt independence criterion, HSIC)来捕获视图数据的多样性信息来增强多视图聚类,文献[15]在子空间表示学习中联合利用视图数据的一致和互补信息,提出了CSMSC(consistent and specific multiview subspace clustering)算法模型.然而上面提到的子空间多视图聚类算法都是将学习到的各视图子空间表示的平均值作为谱聚类的输入,因此文献[16]和文献[17]提出了在子空间表示学习过程中主动学习公共子空间的方法,可仍然无法避免2步策略(最终通过k-means得到聚类结果)造成的次优解.
如何有效地将具有不同维度和不同形式的多视图数据融合成一个信息丰富的结构,一直是多视图聚类的一大挑战.由于数据噪声的存在,而且来自不同视图的数据差异较大,各视图数据构造出的图或系数矩阵可能会有很大的不同,因此由原始数据生成的共同系数矩阵(如基于NMF的方法),或者由原始数据生成的相似图融合获得的共享图数据(如基于图的方法)可能会严重受损,不能真实地反映数据点之间的关系.本文认为在聚类结果阶段进行信息融合会更有意义,因为这样来自不同视图的数据在聚类过程中受到较少噪声的影响,更容易达成一致.Gao等人[18]提出的多视图子空间聚类算法(multi-view subspace clustering, MVSC)和文献[19]提出的多个分区对齐的聚类算法(multiple partitions aligned clustering, mPAC)就采用了在聚类结果阶段进行融合.MVSC为每个视图学习一个相似图,并强制所有相似图共享一个共同的类簇指标矩阵,但融合方法过于生硬,容易导致大量信息损失.mPAC将每个视图数据生成聚类分区,通过不同的谱旋转矩阵形成一致的聚类指标矩阵,这种直接融合为离散结果的方法过于粗糙,容易出现信息丢失,具体原因在后续3.4节进行了详细分析.因此本文提出了一种基于谱结构融合的多视图聚类模型,如图1所示,首先通过子空间自表示方法分别对各视图进行相似图学习,接着各自进行谱嵌入表示,最后在谱嵌入阶段学习一个共同的谱结构图,同时对该谱结构图进行秩约束,使其恰好具有k个连通分量(k为类簇数).该模型将图学习和谱聚类有效地整合到一个框架中进行联合优化学习,避免2步策略带来的次优结果.另外,相比于现有的聚类结果阶段融合的多视图聚类方法,融合部位前后衔接更自然,有效减少了融合方法过于生硬和粗糙造成的信息丢失.并且,本文在多个公开的多视图数据集上进行大量对比实验,证明了所提模型的优越性.

Fig. 1 Framework of proposed algorithm in this paper图1 本文算法模型框架图
1 相关工作
1.1 子空间自表示图学习
近年来,子空间自表示学习模型被广泛应用于数据的相似性学习.自表示特性认为空间中的每个数据样本都可以由同一子空间中其他样本的线性组合表示[20].给定多视图数据Xv∈dv×N,其中N为样本数,dv为视图v的数据维度,式(1)为多视图数据的自表示图学习:
(1)
式(1)中第1项用于自表示学习,第2项是正则项,α为这2项的平衡参数.为了使学习到的图是连通的,选用F-范数正则化.式(1)中Zv为视图v的自表示系数矩阵,表明各样本点之间的相似性.为了避免样本只被自身表示的平凡解出现,增加了约束条件diag(Zv)=0,另外还对Zv进行了非负约束.
基于图的聚类方法,其性能严重依赖于初始图的质量,传统的初始图的构建,最常用的是近邻法.而近邻的数量会严重影响图的质量,并且最优的近邻数会因数据集的不同而有很大差异.本文通过子空间自表示的图学习方式,有效规避了传统构图时近邻数量的选取问题;另外,本算法模型采用的这种图学习方式会随着模型的优化而不断优化.
1.2 谱聚类
在获得了各视图的相似图后,就可以通过谱聚类得到各视图的谱嵌入矩阵:

(2)
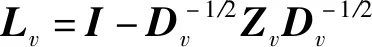
1.3 谱结构融合
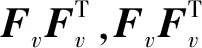
(3)

Fig. 2 The spectral block matrix of FFT corresponding five views on the dataset of MSRCV1图2 MSRCV1数据集5个视图的谱块结构FFT
这里γ为比例常数,S为全局共享的谱结构,Fv是各视图的谱嵌入矩阵,1表示元素全为1的列向量,由于增加了约束条件S1=1,故LS为正则化的拉普拉斯矩阵.另外,为了避免后处理操作带来性能影响,本文模型对S进行了秩约束,要求S严格具有k个连通分量.考虑到各视图数据聚类能力的差异,为各视图分配权重w(v),为与S相似的视图分配大权值,反之分配小权值.受多视图学习自动权重技术[10-11]的启发,该权重可以根据定理1自动获得.
定理1.式(3)中权重w(v)可以定义为
证明.用辅助函数对其进行求解:
(4)
通过拉格朗日乘子法来求解式(4),构造的拉格朗日函数为
(5)
式(5)中Λ为拉格朗日乘子,Θ(Λ,S)是由约束条件导出的.求式(5)关于S的导数并令其为0,得到:
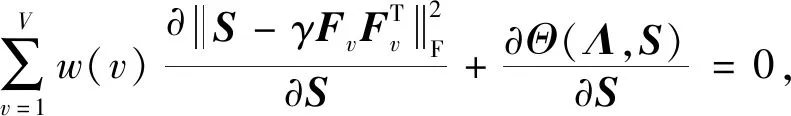
(6)
其中:

(7)
证毕.
2 本文模型
2.1 算法模型
结合式(1)~(3)得到了本文的目标函数:
(8)
式(8)前2项用于各视图的相似图学习,第3项是各视图的谱嵌入矩阵学习,第4项是将各视图的谱嵌入矩阵融合为具有k个连通分量的共享谱结构S,LZv为各视图相似图Zv的拉普拉斯矩阵,LS为共享谱结构图S的拉普拉斯矩阵,α,β是平衡参数,γ为比例常数,w(v)是各视图的权重系数,用来表示各视图对共享谱结构图的贡献程度.
2.2 优 化
式(8)包含Zv,Fv,S这3个变量,若同时考虑3个变量则式(8)是非凸问题,若只考虑其中某个变量式(8)则变成了关于该变量的凸优化问题,因此,本文采用交替迭代的方式对目标函数进行优化.
2.2.1 更新Zv
固定式(8)中的Fv和S,而只考虑变量Zv,得到:
(9)


(10)
其中,ki∈N×1是一个向量,它的第j个元素为对式(10)求关于Z:,i的导数并令其为0,得到了优化解:

(11)
2.2.2 更新Fv
固定式(8)中的Zv和S,而只考虑变量Fv,得到关于Fv的求解:
(12)
式(12)等价于:

(13)
注意:式(13)对各视图是相互独立的,那么最优的Fv就是求解βZv+2γw(v)S的k个最大的特征值对应的k个特征向量.
2.2.3 更新S
固定式(8)中的Zv和Fv,而只考虑变量S,得到关于S的求解:
(14)

(15)


(16)
这样整个更新S的问题就转换为求解式(16),而式(16)的优化可以分为求解S-子问题和F-子问题2步进行:
1)S-子问题
由于式(16)对各列项j是相互独立的,进一步转换为

(17)
其中,sj表示S的j列.

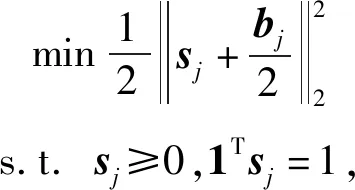
(18)
式(18)是单纯形空间上的欧几里德投影问题,对应的拉格朗日函数为

(19)
其中η,ρ为拉格朗日乘子.根据Karush-Kuhn-Tucker条件[22]可以得到最优解:
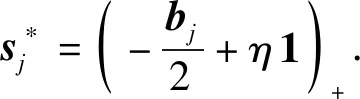
(20)
2)F-子问题
对于式(16),去除与F不相关的项,得到:

(21)
式(21)的最优解F由k个最小特征值对应的k个特征向量组成.根据文献[23],整个更新S的过程可以通过算法1获得.值得强调的是,参数ξ不需要
① http://archive.ics.uci.edu/ml/datasets/Multiple+Features
② http://mlg.ucd.ie/datasets/segment.htm
调试,而是在迭代的过程中确定.初始化ξ为一个较大的值,当连通分量的数量大于k时增加ξ的值,当连通分量的数量小于k时减少ξ的值,直到S恰好有k个连通分量时停止迭代.
算法1.求解共享谱结构S的算法.
输入:各视图谱嵌入矩阵Fv、类簇数k、参数ξ;
输出:具有k个连通分量的谱结构S.
① 初始化S;
② repeat
③ forj=1:Ndo
④ 利用式(20)更新sj;
⑤ end for
⑥S=(S+ST)/2;
⑦ 利用式(21)更新F;
⑧ untilS有k个连通分量.
综上所述,本文提出的基于谱结构融合的多视图聚类模型如算法2所示:
算法2.基于谱结构融合的多视图聚类算法.
输入:多视图数据Xv,类簇数k,参数α,β,γ;
输出:S.
① 初始化Fv,S,w(v)=1/V;
② while不收敛do
③ forv=1:Vdo
④ 利用式(11)更新Zv;
⑤ 利用式(13)更新Fv;
⑥ 利用式(7)更新w(v);
⑦ end for
⑧ 利用算法1更新S;
⑨ end while
2.3 时间复杂度分析
式(8)的第1步是利用式(11)更新Zv,主要计算负担是求矩阵的逆,时间复杂度为O(n3);第2步更新Fv,主要过程是特征分解,每个视图都需要计算出βZv+2γw(v)S最大的k个特征向量,因此更新Fv的时间复杂度为O(knvn2);第3步更新S是单纯形空间上的欧氏投影问题,需要O(n)的时间来计算sj,O(t1n)的时间求解式(18),其中t1为算法1迭代次数,需要n次才能计算出sj,∀j,所以整个第3步求解式(14)的复杂度为O((t1+1)n2);因此,本文所提模型总的时间复杂度为O(n3).
3 实验与分析
为了充分评估本文模型的有效性,在5个广泛使用的数据集上进行聚类验证实验,同时与目前已有模型进行对比.
实验配置:1)编程环境:Matlab 2018a;2)运行环境:64位Windows10操作系统,64 GB内存,64核的Intel Xeon Silver 4110处理器.
3.1 实验数据
本文选择的5个多视图数据集为HW,MSRCV1,BBCSport,ORL,Caltech101-20.各数据集的统计信息如表1所示:

Table 1 Statistics of the Datasets表1 数据集统计描述
1) HW(HandWritten digit)①是选取自UCI机器学习知识库的手写数字(0~9)数据集,每个数字有200幅图片,共2 000幅;包含216维的廓线相关性特征(profile correlations)、76维的傅里叶系数特征(Fourier coefficients)、64维的卡洛南系数特征(Karhunen coefficients)、6维的形态学特征(morphological)、240维的像素平均特征(pixel average)、47维的尼克矩特征(Zernike moments).
2) MSRCV1是一个被广泛应用的场景识别数据集,共包含8个类,每类30幅图片.本实验中选择了飞机、建筑、自行车、牛、汽车、人脸和树7个类别.从每幅图提取5种视图特征,分别为254维的统计特征变换直方图(census transform histogram, CENTRIST)、24维的色矩(color moment, CMT)特征、512维的GIST特征、576维的梯度方向直方图(histogram of oriented gradient, HOG)特征,256维的局部2值模式(local binary pattern, LBP)特征.
3) BBCSport②是一个文本数据集,包含544份来自2004—2005年BBC体育网站的体育新闻,涉及商业、娱乐、政治、体育和技术5个主题领域.多视图BBCSport数据集是通过将单视图文档分割成片段,每个片段至少包含200个字符,并且在逻辑上与它的原始文档相关联.本文选取的是将文档分割成4个片段,每个片段被随机映射为1 991维、2 063维、2 113维和2 158维的文本向量特征,即4个视图特征.
① http://www.vision.caltech.edu/Image_Datasets/Caltech101/Caltech101.html
4) ORL是一个包含40个主题,每个主题有10幅不同图像的数据集,对于每幅图像,与文献[24]相同,也采用生成的4个特征向量,包括512维GIST、59维LBP、864维HOG和254维CENTRIST的特征.
5) Caltech101-20①数据集是广泛使用的图像数据集,是Caltech101的一个子集,Caltech101包含101个类别,而Caltech101-20是从中选取20类,分别是大脑、相机、脸、渡船、犀牛、宝塔、史努比、扳手、订书机、豹子、刺猬、加菲猫、双目望远镜、摩托车、温莎椅、车边、美钞、停车标志、阴阳和水盆.这个数据集共有2 386幅图像,每幅图像被表示成6个不同的视图特征,分别为40维小波矩(wavelet moments, WM)特征、254维CENTRIST特征、48维Gabor特征、1984维HOG特征、928维LBP和512维GIST特征.
3.2 评价指标
由于本文采用的数据集都含有真实的类别标签,为了获得一个全面的评价结果,通过5个广泛使用的指标来评价算法,分别是Acc,NMI,Purity,F-score,ARI.
1) 准确率(accuracy)记为Acc,用于度量聚类结果标签(ν)与真实类标签(μ)之间的一一对应关系,计算为

(22)
其中,N为样本总数,δ(x,y)为指示函数,如果x=y,δ(x,y)=1,否则δ(x,y)=0.map(·)是将簇标签映射到类标签的置换映射函数.
2) 标准化互信息(normalized mutual infor-mation)记为NMI,用来评价聚类结果和真实类别之间的相近程度.给定数据集X(共N个样本点),设μ为K个类簇的聚类结果标签,ν是真实的L个类别的标签,那么NMI计算为

(23)
其中:
(24)
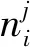
3) 纯度(Purity)指被正确聚类的样本点占总样本点的百分比,计算为
(25)
其中,gi表示第i个类簇,tj代表第j个真实类别.
4)F-score指标是综合考虑类别间准确率(precision)和召回率(recall)的调和值,定义为

(26)
其中:
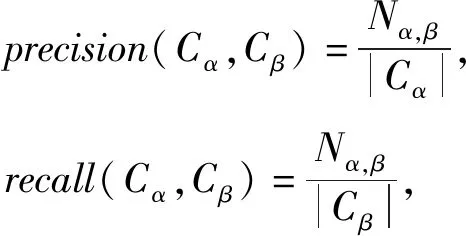
(27)
式(26)和式(27)中的Cα,Cβ是2个不同的类簇,Nα,β代表在类簇Cα中来自Cβ的实例数,|Cα|和|Cβ|分别代表这2个类簇各自的实例总数.
5) 调整兰德系数(adjusted rand index)记为ARI,也是用来评价聚类结果与真实结果的匹配程度的,定义为
(28)
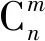
3.3 对比方法
为了评价所提模型的聚类性能,本文将它与现有的多视图聚类模型进行比较,对比模型介绍如下.对于所有对比模型,下载各自作者公开的源代码,按照下面介绍的参数设置进行实验.
1) 经典的谱聚类算法(spectral clustering, SC)[25].在单视图聚类中具有突出效果,本文分别在各个视图数据上进行谱聚类操作,采用近邻方式构建图,并且近邻数的取值为5~60且步长为5的一组数,然后选择聚类结果最好的进行记录,分别标记各视图结果为SC_(i)(SC_(1)表示第1个视图谱聚类结果),SC_(avg)表示将各视图的图取平均值后的聚类结果,也就是说SC_(avg)是将各视图特征以均等权重处理得到的聚类结果.多视图聚类是希望利用来自多个视图的信息比单视图数据获得更准确的聚类结果,增加该对比模型可以清晰看到各模型相比于单视图的效果.
2) 协同正则的多视图谱聚类算法(co-regularized multi-view spectral clustering, ConregSC)[9].通过正则化方法来使得任意2个视图之间具有一致的聚类结果,用线性核来测量每对视图谱嵌入矩阵的相似性,这种通过相似性来寻找一致聚类结果的方法有别于本文模型.该算法中共涉及2种正则化方案:成对协同正则化和中心点协同正则化.而从原文的实验结果可以看出成对协同正则化整体要优于中心点协同正则化,故本文采用成对协同正则化来进行多视图聚类实验;另外,协同正则化参数λ按照作者建议在0.01~0.05范围内取值,选取最佳结果进行记录.
3) 无参的自动加权的多图学习算法AMGL[10].该算法模型通过自动加权的方式将各视图生成的图统一到同一类簇指标矩阵.也是采用近邻方式构图,实验中近邻数的取值与经典谱聚类算法一样,无需指定其他参数.
4) 多图自加权的多视图聚类模型SwMC[11].该算法模型采用秩约束的拉普拉斯算法为各视图构图作为初始图,这种构图方法只需要设置一个近邻参数k,根据文献[11]中作者建议固定k=10.
5) 多个分区对齐的聚类算法mPAC[19].该算法通过旋转矩阵对齐每个分区到一个一致的离散类簇指标矩阵.此模型共涉及α,β,γ这3个参数,根据文献[19]中作者建议的取值范围,α∈{0.1,1},β∈{0.01,0.1},γ取值为10-3.
6) 多视图子空间聚类算法MVSC[18].对于该算法模型,由于文献[18]的作者在论文中没有给出具体的参数设置建议,本文通过网格搜索的方式调整参数,最后将2个参数分别设置为0.01和1,这样得到的聚类效果更好.
对于本文模型与文献[19]和文献[26]一样,首先对数据进行了归一化处理,使数据的取值范围为-1~1;另外,为避免各算法中后续k-means随机初始化造成的误差,所涉及到的对比模型都重复20次实验,并取平均值和标准偏差值作为最终结果进行记录.
3.4 实验结果
表2~6是各个多视图聚类模型在5个公开数据集上进行聚类的结果比较,最好的结果用粗体进行了标记,从这5个表的结果可以得出6个结论:
1) 比较不同视图下谱聚类的性能,可以看到不同视图数据产生不同的结果,证实了多视图的异构性.因此,当构建一个多视图学习模型时,为各视图分配相应的权值是有必要的.
2) 将各视图构建的图平均后进行聚类的结果与每个单独的视图结果进行比较,可以发现简单地对图进行平均可能会得到较好的聚类结果(如BBCSport和MSRCV1数据集),也可能得到不好的结果(如ORL,Caltech101-20,HW数据集).所以,为了获得可靠的聚类性能,需要设计一种有效的融合机制.
3) ConregSC模型也是寻求视图之间共享的一致结构来进行多视图聚类的,只不过它是通过正则化方法,有别于通过融合的方法来寻求一致聚类结果(如AMGL,mPAC,MVSC和本文方法),但这种正则化方法在视图数较少时,效果还差强人意(如ORL数据集上),当视图数增多时,效果就差了(如MSRCV1,HW,Caltech101-20数据集上),而本文方法在视图特征较多时也能达到较好的效果.
4) 本文提出的模型始终比SwMC表现好.特别是SwMC模型在BBCSport数据集上各指标都相对差,尤其ARI值只有0.0653,虽然ARI取值范围为[-1,1],但这也充分说明了按照文献[11]的作者建议的近邻数k取值10根本无法得到质量较好的初始输入图.而进一步查看该数据集上经典谱聚类算法在k取值为50时聚类性能才最好.显然这种近邻构图方式是不好的,首先最佳近邻数很难确定,再则这种方式构造的图只能捕获数据的局部结构.而本文模型中图的学习是建立在子空间自表示基础上,避免了指定近邻数的麻烦,而且能够掌握各个数据样本与其他所有样本之间的线性组合结构.
5) 对于mPAC和MVSC算法,与本文模型相似,都选择融合的方法寻求一致类簇结构.mPAC算法采用子空间自表示来学习得到各视图的相似图矩阵Si,然后通过谱聚类生成各视图的嵌入矩阵Fi,唯一不同的是在融合过程中mPAC采用不同的谱旋转矩阵Ri将Fi直接对齐到统一的离散结果Y.首先该算法中涉及到不同谱旋转矩阵Ri的初始化问题,不同的初始化结果必然会对最终结果造成影响.其次,将嵌入矩阵Fi直接对齐到统一的离散结果Y,多个连续的矩阵信息跟一个离散结果对齐,主要依靠旋转矩阵Ri,而Ri又是没有先验知识的,这种对齐方式必然会造成不少信息的丢失.
对于MVSC算法,它是将子空间表示学习到的各视图的相似图Zi,中间没有经过各视图的谱嵌入矩阵Fi,而将Zi强制融合到同一类簇指标矩阵F.这种融合方式过于生硬且粗糙,因为不同视图的数据有很大差异,生成各视图的相似图Zi差异也是非常大的,直接融合到同一类簇,必然会造成信息的大量损失.相反,若先对Zi进行谱聚类生成Fi,各个视图的Fi差异会缩小,因为多视图数据本就具有潜在一致的类簇结果,选择在这时融合会避免丢失大量信息.
6) 对于AMGL模型,该算法采用的构图方式与SC一样,同样是选取近邻数最佳的聚类性能进行了记录.但是它将各视图数据构建的图Wi,生成各视图的拉普拉斯矩阵Li,然后通过自动加权的方式将各图统一到同一类簇指标矩阵F.该模型只与SC进行比较,除了MSRCV1数据集,其他数据集上聚类性能都不如SC中最好视图特征的效果.因此可以判定此种融合方式确实没有将多视图信息有效利用起来,融合过程出现了信息丢失.

Table 2 Comparison Among Multi-View Clustering Algorithms on BBCSport(Mean±Standard Deviation)表2 在BBCSport数据集上的多视图聚类算法比较(均值±标准差)

Table 3 Comparison Among Multi-View Clustering Algorithms on MSRCV1(Mean±Standard Deviation)

Table 4 Comparison Among Multi-View Clustering Algorithms on ORL(Mean±Standard Deviation)

Table 5 Comparison Among Multi-View Clustering Algorithms on HW(Mean±Standard Deviation)表5 在HW数据集上的多视图聚类算法比较(均值±标准差)

Table 6 Comparison Among Multi-View Clustering Algorithms on Caltech101-20(Mean±Standard Deviation)表6 在Caltech101-20数据集上的多视图聚类算法比较(均值±标准差)
另外,对于表4和表5中本文模型的NMI值都略低于SC算法在ORL的第1个视图特征和HW的第5个视图特征上的值.但这里特别要提醒读者注意的是本文SC算法是从近邻数为5~60且步长为5的一组数中选取结果最好的进行记录.而且由于需要后续k-means获得聚类结果,为了避免初始化误差,重复20次实验取平均值和方差记录的结果.再看表4和表5的NMI和ARI指标,它们都是具有一定偏差的.而本文模型是一个统一的框架直接可以获得聚类结果,是不存在偏差的.从这个角度看,本文模型在这2个指标虽然略低,但整体性能优于其他算法.
总之,本文提出模型选择利用谱结构进行多视图数据融合,在5个数据集上均表现出相对较好的性能.这在很大程度上是由于学习到了质量较好的样本间的相似图,并且选择融合的部位(谱结构融合)和采用的融合方式(加权策略)相比已有算法信息损失更少,另外,对融合后的结构进行秩约束,使得整个过程有机整合到了一个统一框架中,有效避免外接k-means聚类2步策略造成的次优化问题.
3.5 参数分析
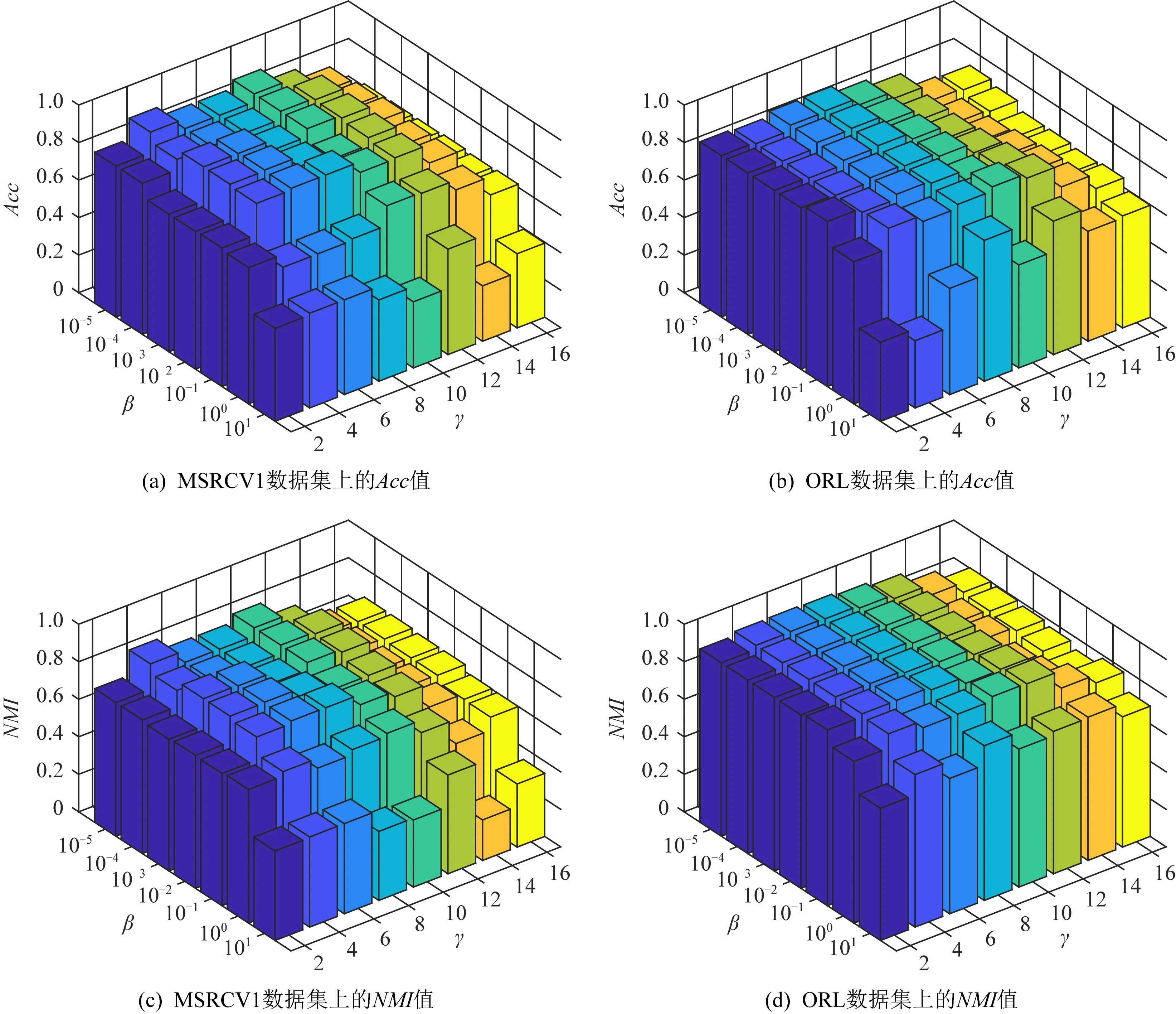
本文算法共涉及3个需要调试的参数α,β,γ,先在小数据集(BBCSport)上以网格搜索的方式进行参数的选择,3个参数的初始取值范围均设置为{10-5,10-4,10-3,10-2,10-1,1,10},通过实验结果再进一步调整各参数的取值范围,然后选择合适的参数范围应用到大的数据集上进行实验.由于参数α在取值为10时各数据集的聚类都能取得较好结果,因此最终固定参数α=10.接着结合BBCSport数据集上各参数的实验结果,以ORL和MSRCV1数据集为例,再次进行实验查看β和γ这2个参数对聚类指标Acc,NMI,Purity的影响,如图3所示.可以看出这2个数据集,β∈{10-4,10-3,10-2},γ∈{4,6,8,10}时,本文算法的性能相对稳定且较好,同样地,在更大的数据集Caltech101-20和HW上进行实验,发现聚类结果较好的参数α,β,γ都稳定在上述范围.
3.6 收敛性分析


Fig. 3 Sensitivity analysis of parameters for our method over MSRCV1 and ORL dataset evaluated with Acc, NMI and Purity图3 用Acc,NMI,Purity对MSRCV1和ORL数据集参数的敏感性分析

Fig. 4 Convergence curves of objective function on four data sets图4 目标函数在4个数据集上的收敛曲线
4 总结与展望
本文提出的多视图聚类模型,与已有模型不同,它寻求在谱嵌入结构层进行多视图信息的融合.同时摆脱了传统受近邻数影响的构图方法,而采用自表示的子空间学习方式将图学习与谱聚类整合在统一的框架下进行联合优化学习,并且通过秩约束的方式来学习一个由各视图共享的恰好具有k个连通分量的谱结构图,这样不需要任何后处理步骤就可以直接获得聚类分配结果.另外,针对本文模型提出了一种高效的优化算法.在5个基准数据集上与已有模型进行大量对比实验验证了本文模型的有效性和优越性.
多视图聚类是大数据算法研究中的关键,本文提出的算法模型虽然克服了现有算法中的多处不足,但仍然存在不完善之处,需要后续更深入的研究和探索.
作者贡献声明:刘金花负责算法模型的提出、实验结果的整理与分析、文章的撰写与修订;王洋负责对比实验的执行与参数的调试;钱宇华提出研究方向,把握论文创新性,提供实验平台,并指导论文修订.
