基于迭代稀疏训练的轻量化无人机目标检测算法
2022-04-06曲国远魏大洲张佳程
侯 鑫 曲国远 魏大洲 张佳程
1(中国科学院计算技术研究所 北京 100190)
2(中国航空无线电电子研究所 上海 200241)
3(北京邮电大学信息与通信工程学院 北京 100876)
(houxin@ict.ac.cn)
随着无人机(unmanned aerial vehicle, UAV)技术的成熟,配备摄像头和嵌入式系统的无人机已被广泛应用于各个领域,包括农业、安防与监视[1]、航空摄影[2]和基础设施检查[3]等.这些应用要求无人机平台能够感知环境,理解分析场景并作出相应的反应,其中最基础的功能就是目标自动高效检测.基于深度网络的目标检测器[4-8]通过卷积神经网络自动提取图像特征,大大提高了目标检测的性能.按照有没有利用候选区域,目标检测主要分为两大阵营:基于候选区域检测阵营与不基于候选区域检测阵营(如CornerNet[9],CenterNet[10]等).基于候选区域检测阵营根据候选框处理手段又可以分为2阶段目标检测(如R-CNN(region convolutional neural network)[11-13],R-FCN(region-based fully convolutional network)[14]等)和1阶段目标检测(如YOLO(you only look once)[15-17],SSD(single shot multibox detector)[18],RetinaNet[19]等).
检测性能提高的同时也带来了巨大的资源消耗和内存占用,这对计算能力受限的无人机处理平台来说是不友好的:1)模型大小.深度卷积神经网络强大的特征表达能力得益于数百万个可训练的参数,如VGG-16网络,参数数量1.3亿多,需要占用500 MB空间,这对嵌入式设备来说是很大的资源负担.2)计算量.深度卷积神经网络前向推理的过程需要执行大量的浮点运算,VGG-16(visual geometry group)网络完成一次图像识别任务需要309亿次浮点运算,这对于计算资源有效的嵌入式设备来说是巨大的挑战.3)推理时间.对于一张高分辨率的输入图像来说,嵌入式平台执行深度卷积神经网络前向推理过程是非常耗时的,可能要几分钟才能处理一张图像,这对于实时应用来说是不可接受的.
因此,很多研究者通过模型压缩方式减小模型复杂度,减少模型参数量与计算量,加快模型前向推理速度.其中比较经典的方法包括模型结构优化[20-23]、低秩分解[24-25]、模型剪枝[26-27]、模型量化[26,28]、知识蒸馏[29]等.模型压缩方法在降低模型参数量和计算量的同时,势必会带来一定的精度损失.对于无人机场景目标检测来说,如何在保持精度基本无损的情况下,进行最大限度的模型压缩是关键的.
针对上述问题,本文提出了一种基于迭代稀疏训练的模型压缩方法,其主要贡献有3个方面:
1) 通过迭代稀疏训练的方式,对经典目标检测网络YOLOv3进行通道和层协同剪枝,可以在保持精度基本无损的情况下实现最大限度的模型压缩;
2) 通过组合不同数据增强方式增加了数据集分布的复杂性和多样性,结合一些优化手段(Tricks),提高了无人机场景下目标检测网络YOLOv3的泛化性能;
3) 实验证明,该方法对于无人机场景下目标检测网络YOLOv3模型压缩效果明显,在保证精度基本无损的情况下可以实现最大限度的模型压缩,而且可以极大地加速模型的前向推理过程,使得模型实时应用成为可能.
1 相关工作
1.1 目标检测
2013年以前,目标检测问题通过手工设计的特征算子与滑动窗口方式解决,处理速度慢、效果不鲁棒,难以满足实际工业需求.2014年,Girshick等人[11]提出R-CNN算法,使用深度卷积神经网络完成对输入图像的特征提取工作,紧接着一系列基于深度卷积神经网络的检测算法出现,包括基于2阶段的检测算法Fast R-CNN[12],Faster R-CNN[13],Mask R-CNN[6],R-FCN[14]等,以及1阶段的检测算法YOLO[15-17],SSD[18],RetinaNet[19]等.随着检测算法的发展,研究者们逐渐发现基于候选区域的目标检测存在一定的缺陷,因此出现了不基于候选区域的目标检测器,典型的有CornerNet[9],CenterNet[10]等算法.
1.1.1 基于2阶段的目标检测器
基于2阶段的目标检测过程主要由2部分组成,首先生成包含感兴趣区域的高质量候选框,然后通过进一步分类与回归获得检测结果.R-CNN是2阶段检测器的基础,首先使用深度网络提取图像特征,然后基于选择搜索[30]生成候选区域,最后通过支持向量机(support vector machine, SVM)分类器对候选区特征进行分类从而得到最终的检测结果.R-CNN不能进行端到端训练,随着网络的发展,逐渐形成了较为成熟的Faster R-CNN检测算法,后续的改进和提升基本都是基于Faster R-CNN进行的.以R-CNN算法为代表的2阶段检测器经过不断的发展和改善,尤其是加入RPN(region proposal network)[13]结构以后,检测精度越来越高,计算复杂度也越来较高,检测速度较慢,难以满足实时应用的需求.因此一般计算能力受限的嵌入式平台不会使用2阶段检测器进行部署应用.
1.1.2 基于1阶段的目标检测器
不同于2阶段检测器,1阶段检测器不包含候选区域生成步骤,直接对预定义锚框对应的特征进行分类和回归以得到最终的检测结果.这种方法相比2阶段检测器来说性能有一定的下降,但速度有明显提升.YOLO[15]首先对训练样本聚类得到候选框,使用这些预定义的候选框密集地覆盖整个图像空间位置,然后提取输入图像的特征并对预定义的候选框进行分类和回归.SSD[18]通过长宽及长宽比来预定义锚框,为提升1阶段检测器的性能瓶颈,SSD从多个尺度特征层出发,同时对预定义的候选框进行类别概率学习以及坐标位置回归,有效提升了检测性能.后续提出的RetinaNet[19]引入focal loss函数来解决类别不平衡问题,1阶段检测器性能有了进一步的提升.
1阶段检测器中YOLO系列算法运行速度非常快,可以达到实时应用级别,但精度差强人意.后续YOLOv2[16],YOLOv3[17]的出现,将精度进行了大幅提升.特别是YOLOv3,借鉴了ResNet(residual network)[31]的残差思想和FPN(feature pyramid network)[32]的多尺度检测思想,在保持速度优势的前提下,进一步提升了检测精度,尤其加强了对小目标的识别能力.在实际部署中,由于非常好的速度/精度均衡性和高度的集成性、灵活性,YOLOv3成为工业界最受欢迎的模型之一.
1.1.3 不基于候选区域的目标检测
2阶段检测器与1阶段检测器都基于候选框进行分类与回归,实际应用中,很多研究者发现如果候选框设置不合适,可能影响检测器的性能.因此,不基于候选区域的目标检测方法被提出,这些方法将目标检测任务转换为关键点检测与尺寸估计.CornerNet[9]将目标检测任务转换为左上角和右下角的关键点检测任务;ExtremeNet[33]将目标检测任务转换为检测目标的4个极值点;CenterNet[10]将左上角、右下角和中心点结合成为三元组进行目标框的判断;FoveaBox[34]则借鉴了语义分割思想,对目标上每个点都预测一个分类结果,物体边界框通过预测偏移量得到.不基于候选区域的目标检测器的成功主要得因于FPN和focal loss结构,但与2阶段检测器和级联方法的检测精度仍然有差距,在灵活性和检测速度上也没有明显优势.因此,目前工业部署应用不是特别广泛.当然,作为一种新的检测思路,随着方法本身的发展,相信未来将会有更多的应用.
1.2 模型压缩
在资源有限的设备上部署深度网络模型时,模型压缩是非常有效的工具,常用的模型压缩方法主要包括模型结构优化[20-23]、低秩分解[24-25]、模型剪枝[26-27]、模型量化[26,28]、知识蒸馏[29]等.模型结构优化是指通过使用轻量化的网络结构来降低模型计算量,但这样会导致模型表达能力下降,从而造成性能下降.低秩分解将原始网络权值矩阵当作满秩矩阵,用若干个低秩矩阵的组合来替换原来的满秩矩阵,低秩矩阵又可以分解为小规模矩阵的乘积,从而实现模型压缩和加速.模型量化主要利用32 b表示权重数据存在的冗余信息,使用更少位数表示权重参数,从而实现模型压缩和加速.上述2种方法在压缩率较高时,都面临精度损失大的问题.知识蒸馏通过学生网络对老师网络的拟合得到一个更加紧凑的网络结构,以再现大型网络的输出结果.学生网络的选择与设计,以及学习老师网络的哪些信息依然是一个值得考虑的问题.模型剪枝指对一个已训练好的高精度复杂模型,通过一种有效的评判手段来判断参数的重要性,将不重要的连接进行裁剪以减少参数冗余,从而实现模型压缩和加速.
Denil等人在文献[35]中提出很多深度卷积神经网络中存在显著冗余,仅仅使用很少一部分(5%)权值就足以预测剩余的权值,因此模型剪枝可以实现非常可观的压缩率.针对无人机场景数据集,本文选择速度/精度均衡的YOLOv3作为基础检测模型,通过模型剪枝来进行压缩和加速,以获得可在算力有限的嵌入式平台部署应用的快速准确检测模型.
1.3 数据增强
数据增强的目标是增加输入图像的可变性,以使模型对从不同环境获得的图像具有更高的鲁棒性.常用的2种数据增强方式包括空间几何变换与像素颜色变换[36-39],其中图像平移、旋转、缩放以及图像亮度、对比度、饱和度是比较常用的.上述提到的数据增强方法都是基于像素级别的,对于无人机场景下的稠密小目标检测任务来说提升作用有限.Kisantal等人在文献[40]中通过剪切粘贴方式来增加小目标数量,该种方法对稠密分布的小目标效果不明显.此外,一些研究员提出使用多张图像一起执行数据增强的方法.Mixup[41]对任意2张训练图像进行像素混合从而起到正则化效果;Mosaic[42]任意混合4张训练图像作为一张新的图像参与训练.这2种方法混合了不同的上下文信息,有效提升了数据集的场景复杂性,从而提升了模型的检测性能.本文除了使用基础的空间几何变换与像素颜色变换增强方式外,巧妙结合了Mixup和Mosaic两种增强方式,进一步提升了YOLOv3在无人机场景下的检测精度.
2 基于迭代稀疏训练的模型剪枝
深度卷积神经网络主要模块包括卷积、池化、激活,这是一个标准的非线性变换模块.网络层数加深,意味着更好的非线性表达能力,可以学习更加复杂的变换从而拟合更加复杂的特征输入.因此,对于同一场景数据集来说,网络越复杂,通常意味拟合能力越强,效果越好.而复杂模型参数量大,推理速度慢,对于嵌入式平台部署应用来说是一个很大的挑战.文献[35]还提出这些剩下的权值甚至可以直接不用被学习,也就是说,仅仅训练一小部分原来的权值参数就有可能达到和原来网络相近甚至超过原来网络的性能.受此启发,本文对一个特征表达能力强的复杂模型通过迭代稀疏训练的方式,巧妙结合层剪枝和通道剪枝,在保持检测精度的同时,实现了模型极大比例的压缩,剪枝流程如图1所示:

Fig. 1 The process of iterative sparse training图1 迭代稀疏训练流程图
2.1 网络结构
在实际部署应用中,由于非常好的速度、精度均衡和高度的集成性、灵活性,YOLO系列模型成为最受欢迎的模型之一.YOLOv3借鉴了ResNet[31]的残差思想和FPN[32]的多尺度检测思想,在保持速度优势的前提下,进一步提升了检测精度,尤其加强了对小目标的识别能力.如图2所示为YOLOv3网络结构,该结构由大量1×1卷积、3×3卷积与残差结构组成,我们把每个这样的结构作为一个单元称为CR块.在检测部分,YOLOv3引入了特征金字塔的思想,采用3个不同尺度的特征图进行检测,以应对目标尺度变化大的问题.本文基础模型基于YOLOv3进行,相比Zhang等人在文献[43]中基于YOLOv3-SPP3(spatial pyramid pooling)开展的工作,同样剪枝率下本文模型参数量更少,推理速度更快,精度更高.

Fig. 2 The network structure of YOLOv3图2 YOLOv3网络结构
2.2 数据增强
数据增强是目标检测中常用的不需要增加太多训练成本但可以有效提升模型性能的方法.Mixup[41]是一种新的数据增强策略,通过对任意2张训练图像进行像素混合来对神经网络起到正则化的效果,可以提高网络对空间扰动的泛化能力,有助于提升检测精准率.Rosenfeld等人在文献[44]中做过一个非常有趣的实验,称为“房间里的大象”,将包含大象的补丁图像随机放置在自然图像上,使用现有的物体检测模型进行检测,发现效果并不理想.Zhang等人在文献[45]方案中将Mixup应用于目标检测,有效提升了模型对“房间里的大象”现象的鲁棒性.如式(1)所示为YOLOv3损失函数:
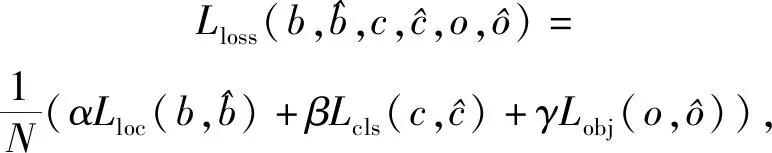
(1)

增加了Mixup数据增广策略之后YOLOv3的损失函数为:
(2)


Mosaic[42]是另一种有效的多张图像混合的数据增强方法,通过混合4张不同图像的上下文信息,有效提升数据集的场景复杂性,有助于提升检测召回率.假设混合后的图像分辨率为S×S,首先创建一个2S×2S的大图,则混合图像的中心点坐标xc,yc~U[S×0.5,S×1.5],随机从训练集中选取4张图像,原图像坐标换算得到混合图像,然后中心裁剪得到最终的增强图像.混合图像左上、右上、左下和右下4张图像坐标范围为
左上角坐标:
ximg1_start,yimg1_start,ximg1_end,yimg1_end=
max(xc-wimg1,0),max(yc-himg1,0),xc,yc;
右上角坐标:
ximg2_start,yimg2_start,ximg2_end,yimg2_end=xc,
max(yc-himg2,0),min(xc+wimg2,2×S),yc;
左下角坐标:
ximg3_start,yimg3_start,ximg3_end,yimg3_end=
max(xc-wimg3,0),yc,xc,min(yc+himg3,2×S);
右下角坐标:
ximg4_start,yimg4_start,ximg4_end,yimg4_end=xc,yc,
min(xc+wimg4,2×S),min(yc+himg4,2×S).
(3)
其中,x,y,w,h分别表示图像的横纵坐标、宽和高.
Mixup通过任意2张图像的像素混合可以有效提升检测精准率,Mosaic通过任意4张图像拼接混合可以有效提升检测召回率,本文将Mixup和Mosaic这2种数据增强策略进行巧妙结合,获得了检测精准率和召回率的大幅提升.在训练时,首先加载batchsize张训练图像,然后对每张图像按照一定概率选择数据增强策略,其中包含只进行Mixup增强、只进行Mosaic增强、同时进行Mixup和Mosaic增强与Mixup和Mosaic增强都不执行这4种方式.需要特别注意的是在选择与其他图像结合时,需要从batch以外的图像中选择.对batch中的每张图像都执行上述操作,直至最后得到新生成的batchsize张增强图像参与模型训练,上述组合增强策略为
dataaug=a1mixup+a2mosaic+
a3(mixup+mosaic)+a4None.
(4)
2.3 模型剪枝
模型剪枝通过对高精度复杂模型进行冗余参数修剪,从而得到计算量和参数量有效降低的轻量化模型.除了2.2节提到的数据增强策略外,本文参考He等人在文献[46]方案中的设置,在YOLOv3训练过程中加入了相关优化方法,其中包括多尺度训练、大的批处理尺寸、热启动、余弦学习率衰减法(cos lr decay)、标签平滑(label smooth)等,有效提高了模型的精度.将该模型作为剪枝基准模型,依次通过迭代稀疏、层剪枝、微调与迭代稀疏、通道剪枝、微调(finetune)的过程,最终得到了不同剪枝比例的可部署模型,剪枝流程如图1所示.
2.3.1 稀疏训练
模型剪枝需要选择可评估权重重要性的指标来剪枝不重要的结构.本文采用批归一化层(batch normalization, BN)中的缩放因子γ的绝对值度量权重的重要程度.BN层的标准化公式为

(5)
其中,μ和σ2为统计参数,分别表示批处理中数据的均值和方差;γ和β为可训练参数,分别对归一化分布进行缩放与平移,从而保留原始学习到的特征.基于BN层原理,缩放系数γ主要用来保留归一化操作前的特征,因此可以作为评估权重重要程度的指标因子.
如果权重分布不稀疏将不利于模型剪枝,需要通过外力强制稀疏化,L1正则化约束是常用的稀疏化方法.加入L1正则后YOLOv3的损失函数为:
(6)
其中,∂为正则化系数,平衡2个损失项之间的关系.由于添加的L1正则项梯度不是处处存在的(在0点导数不存在),因此我们使用次梯度下降[27]作为L1正则项的优化方法.
2.3.2 层剪枝
如图2所示为YOLOv3的标准网络结构,特征提取部分由大量1×1卷积、3×3卷积与残差结构构成,我们把每个这样的结构作为一个单元称为CR块.实际剪枝操作过程中,为保证YOLOv3结构完整,CR块作为一个整体参与.YOLOv3结构中一共有23个CR单元,权重重要程度统计时,我们选择CR单元的均值作为评估剪枝与否的指标,剪掉均值较低的单元.层剪枝是一种非常粗糙的剪枝方法,按照单元裁剪的方式可能会带来较大的精度损失,因此实际剪枝过程中我们通过观察γ的变化趋势设置需要剪枝的CR单元比例,通常不会一次剪掉太多,每次迭代按照50%的概率进行剪枝.通过稀疏训练-层剪枝-微调的迭代过程,保证每次剪掉一些CR单元后,其精度损失可以通过微调补偿回来.图3为层剪枝后的YOLOv3网络结构图,具体剪枝参数设置见3.3节.
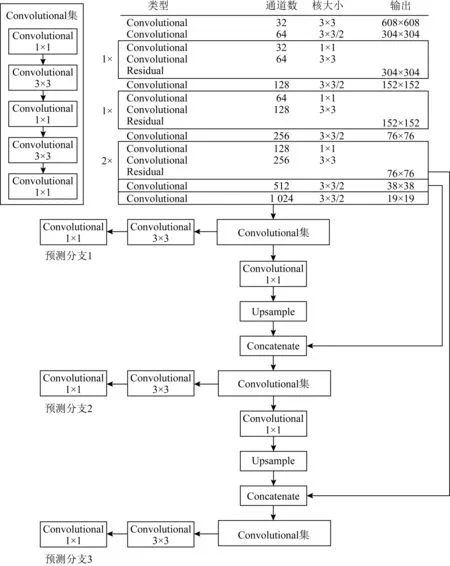
Fig. 3 The network structure of YOLOv3 after pruning图3 YOLOv3剪枝后的网络结构
2.3.3 通道剪枝
层剪枝之后我们得到了相对稳定的网络结构,此时通过通道剪枝对其进行进一步修剪.首先需要定义全局剪枝率λ,表示需要剪枝的通道数占总通道数的比例,同时可以换算出全局剪枝率λ对应γ的阈值π1.为防止通道剪枝时某些层被全部剪掉,需要另外设置一个保护阈值β,表示每层中至少需要保留多少比例的通道,同理也可以换算出每层中对应γ的阈值π2.当且仅当γ<π1,γ<π2同时满足时,该通道可以剪枝.直接使用较大的剪枝率会损失较多的精度,因此通道剪枝时我们通过分析稀疏训练后γ的分布,按照30%的比例设置参数量剪枝率并迭代执行稀疏、通道剪枝、微调的过程,使得由于剪枝带来的精度下降可以通过微调补偿回来,从而得到精度损失较小的轻量化模型.
2.3.4 微 调
在执行完一次层剪枝或通道剪枝后,或多或少都会带来精度损失,一定程度的精度损失可以通过后续的微调补偿回来.本文我们是通过迭代稀疏训练进行剪枝的,因此在每一次剪枝之后必须通过微调来补偿剪枝带来的精度损失,才能不影响下一次迭代的稀疏训练.
3 实验结果与分析
本文提出了一种基于迭代稀疏训练的模型剪枝方法.实验证明,该方法可以获得精度和速度兼备的检测模型.其中,模型训练环境均基于Pytorch框架,服务器配置为Intel®Xeon®CPU E5-2640 v4@2.40 GHz,128GRAM,4块GTX 1080 Ti.
3.1 数据集和评价指标
VisDrone-DET2019[47]是一个典型的无人机目标检测应用数据集.该数据集包含8 599张来自无人机平台从不同高度、不同光照条件下收集的图像,涉及包含人、车在内的10个类别(pedestrian,person,car,van,bus,truck,motor,bicycle,awning-tricycle,tricycle),是一个非常有挑战的数据集.其中训练集6 471张、验证集548张、测试集1 580张,由于测试集标注未开放下载,因此本文中模型都是基于训练集训练、验证集评估的.
模型评估标准与文献[43]中保持一致,我们主要评估输入分辨率为608×608像素下模型的参数量、计算量(floating-point operations, FLOPS)、交并比(intersection over union, IOU)在0.5下的精度度量指标F1-score和平均精度均值(mean average precision,mAP)以及模型压缩中涉及的参数量压缩率、计算量压缩率等指标.为更全面地评估轻量化模型在不同分辨率下的性能,我们选取计算量压缩率为85%的模型与文献[43]中模型进行对比分析,实验证明我们的算法在达到与文献[43]中同等压缩率的情况下可以获得更高的精度与更快的速度.
3.2 训练细节
本文模型训练环境基于Pytorch框架展开,采用动量0.9、权重衰减因子0.000 5的随机梯度下降(stochastic gradient descent, SGD)权重更新策略;正常训练迭代次数为300epoch,初始学习率为0.002 5,分别在240epoch和270epoch衰减10倍;稀疏训练和微调的迭代次数为100epoch,初始学习率为0.001,分别在80epoch和90epoch衰减10倍;批处理大小为128;损失函数中α,β,γ分别设置为3.31,52.0,42.4;数据增强策略中α1,α2,α3,α4按照等概率设置为0.25;多尺度训练设置图像大小变化区间为[416,896];稀疏因子根据γ分布设置为0.01~0.08之间.
3.3 实验结果
3.3.1 数据增强
数据增强是一种成本很低却可以有效提升模型性能的方法.除了常规使用的增强方法外,本文结合了Mixup和Mosaic的优势,有效提升了检测精准率和召回率,增强效果如图4所示:

Fig. 4 The effect of data enhancement图4 数据增强效果图
为获得好的基准模型,我们通过数据增强策略与优化手段共同对YOLOv3标准模型进行了优化.表1中前两行分别表示Zhang等人在文献[43]中的测试结果,行3表示YOLOv3标准网络测试结果,行4~6分别表示单独加入Mixup增强策略、单独加入Mosaic增强策略以及Mixup和Mosaic结合策略的测试结果,最后一行表示加入相关优化手段的测试结果.我们可以看到不论使用Mixup策略还是Mosaic策略都可以提升mAP指标,此外Mixup和Mosaic随机组合的策略对mAP的提升要比单独执行时效果更好.表1最后一行不论mAP还是F1-score都有很大的提升,虽然未加SPP[48]模块,但通过数据增强策略与相关优化手段可以达到甚至优于YOLOv3-SPP3的结果,而且参数量和计算量更少.

Table 1 Test Results Comparison of Benchmark Model表1 基准模型测试结果比较
3.3.2 剪 枝
基准模型获得后,我们通过迭代稀疏训练的方式进行模型剪枝.图5为层剪枝稀疏训练过程中CR单元γ均值变化曲线图,其中实线表示基准模型CR单元γ均值曲线,虚线表示稀疏训练后模型CR单元γ均值曲线.从图5中可以明显发现,模型越靠前的层γ均值越大,越靠后的层γ均值越小.随着迭代的进行,γ均值会逐渐变小,但不改变层之间的相对大小关系,而且越靠后的层越接近0,说明针对当前数据集来说,越靠后的层对模型性能贡献越小,因此会在层剪枝过程中被剪枝.随着剪枝过程的进行,其稀疏训练过程也会变得越来越难,层剪枝难度增大,直至达到一定的结构平衡,如图3所示,完成层剪枝过程.

Fig. 5 The scale factor change curve of CR module图5 CR单元缩放因子变化曲线图
标准YOLOv3模型一共含有72个BN层,如图6所示为通道剪枝过程中稀疏训练前后γ统计直方图分布.对比图6(a)(b)的2张图可以明显地看到,稀疏训练后γ数据分布直方图变得更细更尖了,意味着接近于0的γ值变得更多了,而较大的γ值变少了,也即γ数据分布更加稀疏,有利于通道剪枝的实现.

Fig. 6 The γ statistics histogram before and after channel pruning sparse training图6 通道剪枝稀疏训练前后γ统计直方图
表2表示不同剪枝率下的模型压缩性能对比,其中YOLOv3_baseline表示本文剪枝前的基准模型,YOLOv3_prune_70(85,90)分别表示计算量剪枝率为70%,85%,90%的模型,与文献[43]工作中的SlimYOLOv3-SPP3-50(90,95)一一对应.在计算量达到同等剪枝率甚至更高剪枝率的条件下,我们的方法对参数量的压缩率更高,而且精度误差更低.特别是对于计算量压缩率为85%时,参数量压缩率达到97.3%,比文献[43]方案中的87.48%高了将近10%.此外,mAP误差只有0.3,相比文献[43]方案中提升了2.4个点.
为了与文献[43]方案中结果进行更公平全面的对比,表3针对计算量85%压缩率水平进行了416×416,608×608,832×832这3个分辨率的性能对比,不出意料,不论mAP指标还是F1-score指标,我们的方法都取得了巨大的提升.图7展示了608×608输入分辨率下剪枝前后的检测效果图,可以看到剪枝前后都能检测到绝大多数感兴趣目标,而且剪枝前后误差很小.
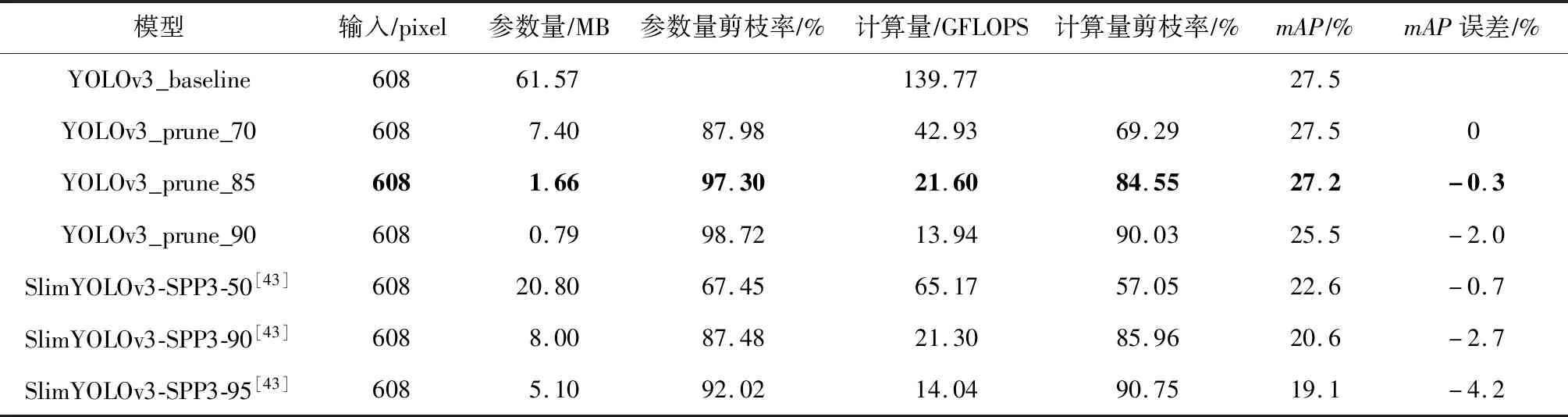
Table 2 Comparison of Model Compression Performance Under Different Pruning Rates表2 不同剪枝率下的模型压缩性能对比
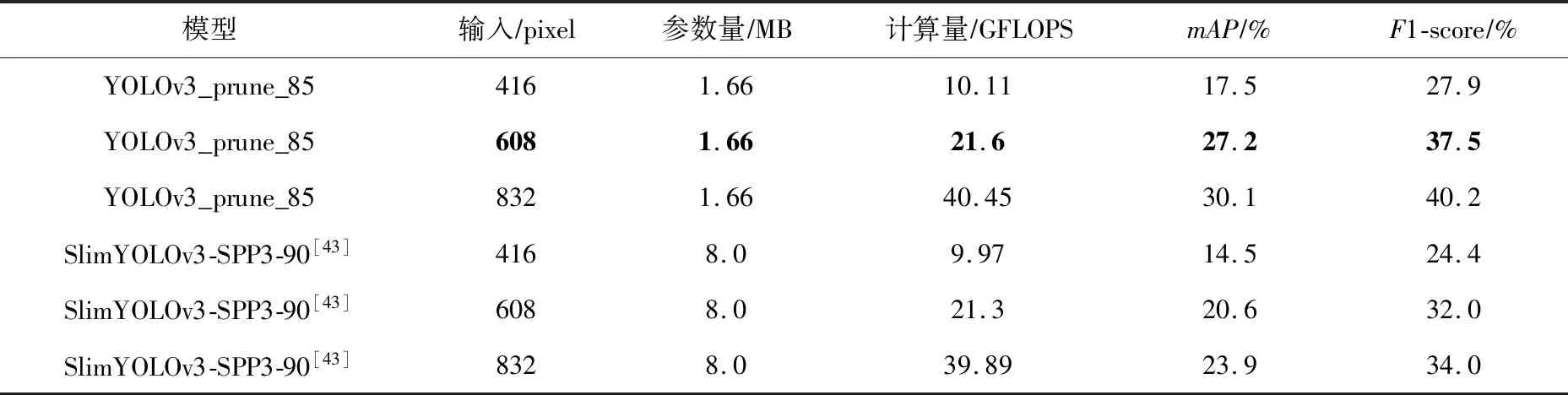
Table 3 Comparison of Model Compression Performance Under Different Resolutions

Fig. 7 Test result of model before and after pruning图7 剪枝前后结果图
4 结束语
本文通过数据增强策略与相关优化手段的巧妙结合,得到了一个性能较好的基准模型.通过迭代稀疏训练的模型压缩方法,对上述基准模型进行了极大程度的参数量压缩与计算量压缩.与现有典型方法[43]相比,本文提出的方法在未添加额外计算量(SPP模块)的情况下,得到了精度更高的基准模型;同时通过迭代稀疏层剪枝与迭代稀疏通道剪枝相结合的方法,在达到同等计算量剪枝率的情况下,参数量更少,精度损失更小,适合在计算资源受限的无人机平台部署应用.模型压缩是生成性能较好的轻量化模型的常用方法,如何保证在一定精度损失的条件下进一步降低计算量和参数量仍然是一个值得深度研究的课题.当前方法只验证了YOLOv3网络在VisDrone-DET2019数据集上的压缩性能,下一步我们将对其他典型检测网络与数据集做进一步验证和推广,以提高方法的普适性.
作者贡献声明:侯鑫参与代码开发、实验测试、数据分析、论文攥写与修改等工作;曲国远、魏大洲参与实验环境搭建、代码开发、实验测试等工作;张佳程参与数据分析等工作.
