基于Vitis-AI架构的语义分割ENET模型实现*
2022-04-01武亚恒
胡 凯,刘 彤,武亚恒,谢 达
(中科芯集成电路有限公司,江苏无锡 214072)
1 引言
近年来人工智能(Artificial Intelligence,AI)技术广泛运用于复杂环境的感知识别中,AI所需要的计算量巨大,现场可编程门阵列(Field Programmable Gate Array,FPGA)单位功率算力远高于CPU和GPU,并且具有高性能、可重编程和部署灵活的优势,适合应用于自动驾驶和可穿戴设备等复杂计算机视觉处理的应用场景。传统的卷积神经网络(Convolutional Neural Networks,CNN)[1-2]在像素级别分类上存在存储开销大、计算能效低下、像素区域限制识别区域的大小、准确性和实时性不可兼得的缺点,语义分割是对图像的像素进行有关联性的预测、推断特征值来实现推理的。PASZKE在2016年提出ENET网络,采用编码器-解码器架构,相比SegNet,速度提升18倍,计算量比原来减少了75倍,参数量比原来减少了79倍,并且具有相当的精度[3],同时语义分割的编码器实现预先训练网络、信息处理和过滤,解码器负责将编码器训练的有效特征(小尺寸)语义进行微调。在保证图像有效精度和特征的基础上,减少编码器和解码器的层数、网络参数和硬件损耗。本文论证了多种语义分割算法并进行仿真验证,XILINX发布的Vitis-AI库和深度学习处理单元(DPU)架构独有的量化模型、编译模型和指令架构,可以有效支撑改进语义分割模式的部署。
2 ENET模型设计
2.1 ENET网络
ENET是一个轻量级语义分割的非对称编解码模型,可以有效减少浮点预算的次数(特别适合FPGA的INT8架构)、内存占用以及推理时间,传统的CNN被用于计算机视觉中的图像分类[4-6],通常CNN由多层卷积组成,每个卷积层后面通常是最大池,最后一层是完全连接的层,它将高维向量映射到对应低维概率向量,是一个对称结构,这样会导致计算量巨大,对硬件的消耗比较大。典型的ENET网络可以很好地解决这个问题,ENET网络架构如图1所示,深蓝色表示解码网络,浅蓝表示编码网络。在压缩网络的一开始就采用了两次下采样,这样使得图像的解析度直接下降了1/4,极大地减少了计算量;采用空洞卷积捕获多尺度上下文信息,扩大感受野的同时保持特征图的尺寸不变;采用非对称卷积n*n的卷积核都可以被分解为n*1和1*n的两层卷积核,使感受野扩大一倍,增加函数多样性,减少过拟合;采用转置卷积的上采样将特征图的分辨还原原始图片的分辨大小。

图1 ENET网络架构
Cityscapes数据集提供了20种分类,是一个大规模城市大量场景理解的数据集,其图像为1024*512*3的数据,通过量化处理,进入ENET模型的初始化,其结构如图2所示,数据经过步距为16个2通道的3*3矩阵卷积后得到13个通道的512*256特征值,池化经过16个通道的2*2矩阵卷积后合并成512*256*16的特征矩阵,减少硬件内存和对位宽的依赖。
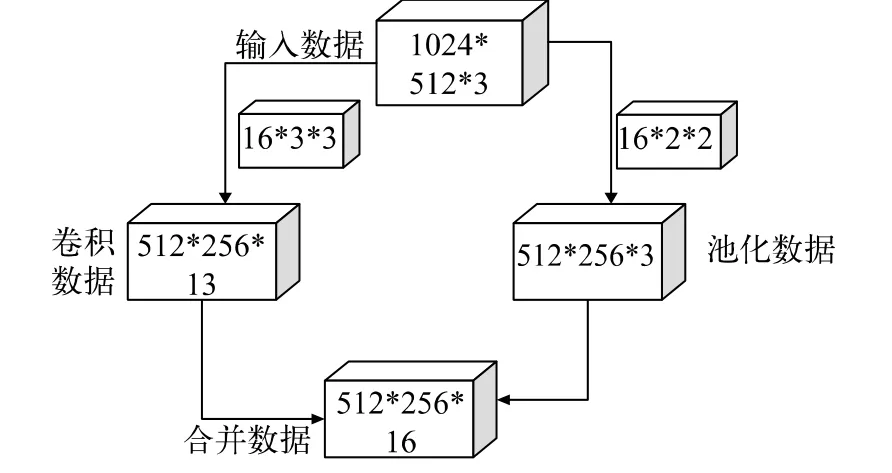
图2 ENET初始化处理
2.2 改进ENET网络
传统的Bottleneck模型为512个通道数据经过2组512个通道3*3卷积,增加了数据深度,降低特征提取效率。采用改进模式可以利用DPU内部的修正线性单元(Rectified Linear Unit,ReLU)激活函数硬件模式减少参数,同时采用1*1的降4维矩阵,减少3*3矩阵的维度[10-11],减少运算量和数据深度,最后通过提升维度矩阵进行1*1的卷积运算。传统和改进DPU的Bottleneck结构如图3所示。
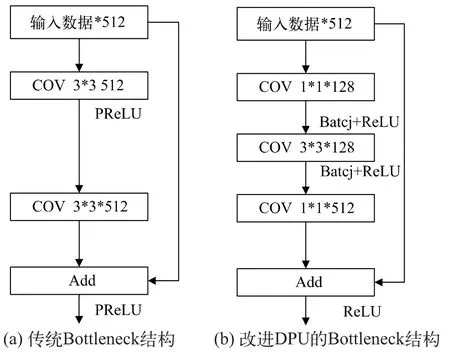
图3 Bottleneck结构
改进DPU的Bottleneck模型一样在上采样和下采样结构中激活函数参数线性单元(Parametric Rectified Linear Unit,PReLU)替换给ReLU,同时把传统结构中的上采样模式删除,用1*1卷积矩阵代替最大池化结构,能提高DPU的工作性能。下采样减少特征矩阵的尺寸并保留有效参数,一定程度上避免过拟合,通过最大池化步距为2的2*2卷积矩阵对输入数据进行4倍数据处理,通过2*2、3*3和1*1的卷积矩阵保证特定特征矩阵,上采样采用反卷积操作恢复经过下采样的编码图像,恢复原有尺寸,改进前后采样结构如图4所示。

图4 采样结构
通过对上述输入数据初始化处理,得到512*256*16的特征数据,通过二次下采样进行尺寸缩小增加通道数,再进行多次的Bottleneck、扩展和非对称处理,编码部分经两次重复Bottleneck 2.1~2.8的操作进行图像特征提取,解码部分采用非对称结构的反卷积上采样模式恢复图像尺寸,保留有效的特征参数,改进ENET架构如表1所示。

表1 改进ENET架构
2.3 平台构建
Vitis-AI基于XILINX平台进行AI加速推断,将最优化的IP核、工具、库文件、神经网络模型和设计组成AI加速应用系统,适用于自适应计算加速平台。Vitis-AI的设计流程由构建模型、构建软件、构建硬件3部分组成[9-12]。
神经网络用Caffe平台构建模型,采用浮点网络模型和校准数据集作为训练的输入,AI优化器对ENET模型进行基线模型分析,通过多次对设定阈值进行优化,去除冗余部分,使得神经网络模型轻量化;AI量化器将ENET模型的32位浮点数据(FP32)转换为8位整数(INT8),通过量化权重、校准激活生成DPU模型,完成DPU模型部署后可降低计算量和硬件损耗,在保证精度的前提下提高运算速度。构建软件由AI库、云端运算和软件交叉编译组成,可以调用AI库的算法库和基本库;通过构建改进型ENET模型网络,在Vitis运行时完成ENET模型的可执行软件构建。
构建硬件采用ENET网络的环境要求,基于VIVADO软件搭建硬件系统,其硬件结构图见图5。

图5 VIVADO硬件结构图
硬件系统由图像采集、可编程逻辑、处理系统、数据存储和外围接口组成。摄像头采集1080P的视频数据,经过处理器接口(MIPI)传递给可重构控制器,可重构控制器完成视频数据拜尔格式(Bayer)的转换,伽马(Gamma)校正模块实现输入图像数据的伽马校正曲线转换,再经过颜色空间转换,完成视频数据的转换。处理器包含多核ARM cortex-A53处理器和实时ARMCORTEX-R5处理器,分别完成系统的应用层处理和图像的实时处理,通过AXI接口完成数据流的传输和存储。系统采用Pertalinux系统进行开发设计,并通过内部构建Vitis-AI的软件模型,完成系统内部调度和内存分配。
3 训练和实测结果
在Ubuntu系统中加载Vitis-AI模块将加速GPU训练,分别依次训练语义分割模型中的特征金字塔网络FPN、轻量级深度学习网络ESPNet、深度学习分割网络Unet-net、图形分割网络Unet-lite。训练模型采用Cityscapes数据库,包含2975个训练图、500个验证图数据和1525个测试图。各语义分割模型训练时的指标交并比的计算公式如式(1)所示,模型输出预测范围和标记实际检测范围的交集除以它们的并集,得到预测的准确度。

IOU表示平均准确率的交并比,truepositive为预测的某标签部分符合真值,flasepositive为预测中分割为某标签的部分,flasepositive为预测中被预测为非标签部分。各个模型训练结果的测试精度见图6,ENET模型采用表1中的参数数据训练模型参数,对训练数据进行量化浮点数据处理,训练解码模型和batch_size设置后采用GPU训练,经归一化处理生成权重参数。
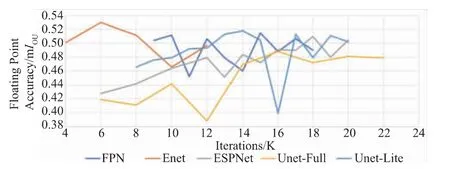
图6 各个模型训练结果
表2分别统计了各个语义分割模型的迭代时间和平均交并比,通过对比分析进行ENET语义分割。

表2 各个模型I OU数值
DPU吞吐量和DDR传输速率如图7所示。根据运行的FPS数据和采样所得的读写传输速率的折线图,可得DPU最大吞吐量满足8.03 FPS,其中4种颜色分别代表4个DDR的读写速度大小,最大读取速度为2400 Mb/s,最大写速度为450 Mb/s,可知改进型ENET模型可以在FPGA硬件上稳定运行,CPU、DPU和存储器的利用率小于硬件所支持的最大损耗,在硬件上可以稳定运行。

图7 DPU处理性能和DDR读写速度
采用语义分割ENET模型的路况效果见图8,能有效分辨汽车、草、树、天空、人、自行车和建筑等信息,可以有效判断道路的宽度。DPU在300 MHz运行下处理1024×512分辨率的视频可以达到8.03 FPS。

图8 ENET分析测试结果
选用GPU进行算力对比测试,选取传统算法和改进算法分别在ZCU102的FPGA平台和GPU的GTX1080ti平台进行算力对比测试,评价每瓦的FPS值,从图9中可知传统ENET网络算力FPGA为2 FPS/W,远高于GPU的0.9 FPS/W,改进型ENET网络算力为3.2 FPS/W,远高于GPU的0.6 FPS/W。

图9 算力分析测试结果
4 总结
本文搭建了Vitis-AI的软硬件平台,借助语义分割的训练、部署等方法,通过对比多种深度学习网络结构,改进ENET网络模型,使用更少的计算资源达到最优的控制精度,并完成像素级的特征提取,在复杂路况上能准确地识别和分类事物,同时整体硬件损耗较小,可以实现1024×512分辨率的图像30 ps的实时处理,算力相较于采用传统ENET网络的GPU提升了350%,此方法可以为后续改进训练模型增加分类种类,可在复杂环境下广泛推广语义识别算法。
