基于排队论的数据链网络节点入退网时隙分配算法研究
2022-04-01田沿平
卢 翰,田沿平,傅 伟
(1.海军航空大学青岛校区,山东 青岛 264000;2.91206 部队,山东 青岛 264000)
0 引言
现代战争是系统间、体系间的对抗,以高度信息化的联合作战为基本样式,包含多军种、兵种的共同协作,统一的指挥、调度、控制等诸多问题都要建立在及时、准确的信息传递基础上。战术数据链的出现使各个独立的作战平台相互链接,是自动化指挥系统的重要组成部分[1]。数据链作为现代战争的“倍增器”,是信息化作战的“战术神经网络”,在多场现代化战争中大放异彩[2]。但是,随着数据链的不断使用,越来越多的问题随之暴露出来,其中节点的入退网时隙分配是一个关键问题。本文基于排队论提出一种数据链网络节点入退网时隙分配算法。
1 算法设计
1.1 算法总体设计思路
首先,将用户节点的信息优先级作为算法设计的重要参考指标。在数据链的实际运用中,优先级的评估要根据节点位于网内的战略地位进行重要程度排序。地位越重要的节点,其信息越需要优先传递。通常情况下,指控中心或主控站等节点负责整个战场态势,担负战场的统筹、调度、指挥任务,需要保证优先发送;而负责战术侦察的各种侦察机、预警机等节点,由于其担负着警戒、侦察、巡逻、预警等任务,因此应当配置位于上层的优先级数,使得态势情况可以及时汇报给主控站;各种战斗机、运输机、轰炸机等因为多数时刻处于接收、执行指令信息的状态,需要上报的信息量少,而且实时性的需求往往偏弱一些,所以往往可以分配较低的优先级[3]。
其次,优先级并不是一成不变的,在战场上随着战场局势的变化,各个节点的作用也会有所改变,导致节点的优先级发生变化。同时,在算法设计的时候要尽量考虑因高优先级节点占据大量时隙导致低优先级节点出现“包饿死”的情况。
最后,当网内有节点增减后,需要依据节点的优先级进行排队分配时隙资源[4]。
1.2 算法具体设计
本算法具体设计的步骤如下:
(1)进行网络的初始化,设定划分总时隙的个数为N,网络初始节点数为X,平均每段时隙长度为L;
(2)约定一个周期的时间T,则一个周期的时隙数目为T/L;
(3)在t时刻,1 个节点入网或退网,统计需要发送信息节点总数。如果没有数据业务,算法自动跳过下面的步骤,默认完成分配周期,不分配,算法结束;如果总数不为0,代表此时存在信息任务,则按照优先级先高后低的顺序排序,形成一个分配顺序表,依次对每个节点划分一个数据时隙,依次分配至最低优先级节点分得时隙,一轮分配结束;
(4)一轮分配结束后,开始第二轮分配,同样按照分配顺序表的安排为节点各分配一个时隙,方法同步骤(3);
(5)按序执行多轮时隙分配至最后一个时隙分配完毕,一个周期内的时隙分配完成;
(6)若在一个周期内时隙分配完成后,存在一个节点在连续两轮未分配时隙的情况,则进行节点的优先级动态调整;
(7)进行节点优先级调整后再进行多轮时隙分配;若出现步骤(6)的情况,对节点优先级进行再调整和多轮时隙分配;
(8)时隙分配完毕。
整体算法流程如图1 所示。

图1 时隙分配算法流程图
为了保证在时隙分配的过程中不出现较高的优先级节点分配时隙时总是率先将时隙分配占有完毕而下层优先级的数据分不到时隙的情况[5],特别规定数据链节点优先级动态修正原则如下。
(1)依据节点优先级进行排序,形成时隙分配顺序表。节点优先级分为1~5 的级别,5 最高,1 最低,5 级作为应急特需优先级。
(2)若出现1 个节点连续2 轮时隙分配过程皆未分配到时隙的情况,则将该节点优先级提高1 级。
2 算法仿真模型构建
本文主要采用OPNET 软件进行算法建模仿真分析。由于节点退网建模模型与入网模型基本一致,本文主要介绍节点入网算法仿真模型。
设置网络环境为:plane_0~plane_3 共4 个飞行节点组成初始数据链网络,且设置它们的优先级分别为5、4、3、1。因此可以得到这4 个节点的时隙分配顺序为plane_0 →plane_1 →plane_2 →plane_3。
在工作一段时间后,新节点plane_4 入网,其优先级为2,则形成的新的时隙分配顺序为plane_0 →plane_1→plane_2→plane_4→plane_3。根据环境描述,建立的新的网络环境如图2 所示。

图2 基于排队论的算法网络域建模图
2.1 节点模型构建
网内节点应当具备以下模块以实现不同功能。
(1)network 模块。对应网络层,作为实现入退网管理过程的最主要模块。将依据节点优先级排列分配表的功能放在此模块。网络数据的产生、包创建、包处理也在这里进行。
(2)mac 模块。mac 模块作为mac 层,但该模块的功能有所缩减,时隙划分放在上一层进行,本模块仅起上下层模块间数据包的中继、转发的作用。
(3)phy 模块。对应物理层,控制收发信机及天线。
(4)rec 模块和trans 模块。对应收发信机,其多项物理工作特性均由phy 模块控制。
(5)ant 模块。对应天线,完成收发及转换,可以在全向与定向之间转换。
本文建立的节点域模型如图3 所示。

图3 基于排队论的算法节点域建模图
2.2 模块模型构建
2.2.1 network 模块
network 模块用于产生网络战术数据,按照网内节点及相应要求划分时隙段,对节点的优先级予以认定。在新节点进入网络后,network 模块形成新的时隙分配顺序表,控制多轮对各节点的时隙划分。同时需要考虑增加对特殊优先级的判断与设定进程,以达到优先级动态提升的要求[6-7]。基于排队论的算法network 模块进程如图4 所示。

图4 基于排队论的算法network 模块进程图
网络运行工作时,首先启动init 状态将各变量进行初始化,包括节点优先级的确认,都在此处完成。其中,对于普通节点优先级的设置将按照要求设置为1~4。new 状态代表接收到来自上级的包含有特殊任务的指令,经判断满足judgement 要求后,启用特殊优先级5,初始化完成后,进入wait 状态等待其他驱动指令。new 状态代表有新节点入网,在经过认证运行满足judgement 条件后,运行入网,还在init 状态确定节点优先级等信息,且在new_init 状态完成初始变量的更新[8]。完成后运送data产生的网络数据经过divide 状态统计时隙段数量并完成时隙段划分后,形成order 状态内的时隙分配顺序,同时要将此轮分配的具体情况传至special状态审定后按顺序进行数据运送与信息交流。如果存在算法中规定的“低优先级节点连续两次分得的时隙资源为0 或请求等待时间超过预定的时间长度”的promote 条件,则在new_init 状态内将该节点优先级提升1 级。
2.2.2 mac 模块
mac 模块进程处于phy 模块和network 模块之间,任务相对轻松,作为中转模块,其负责包流的存储和转发[9]。mac 模块进程如图5 所示。

图5 基于排队论的算法mac 模块进程图
节点最初在init 状态进行变量初始化。初始化完成后,节点始终处于idle状态,这是一个空闲状态。当网络层和物理层上下层之间有包传递交流时,由强制状态init_pk 状态进行包处理,结束后进入end状态。
2.2.3 phy 模块
phy 模块根据上层指令对收发机和天线等物理设备进行工作参数的调节,指令通过包流内的信息进行传达。同时,phy 模块还承担将系统接收到的包转发至上层的任务。phy 模块进程如图6 所示。

图6 基于排队论的算法phy 模块进程图
网络工作时,INIT 状态负责对网元节点的天线参数、工作状态以及收发频率进行初始配置。下一步进入IDLE 状态,等待网内节点发送中断状态作为进行下一步的驱动力。如果有其他节点传来数据包信息,在LOW 状态解析处理数据包。如果是上层模块的数据包时,到HIGH 状态按照数据包内的信息指示更改天线的参数和状态,按指示把数据包发给指定节点。节点可以在SETMOD 状态通过设置天线的指向等参数进行对准,定向接收数据[10]。
3 仿真结果与分析
初始网络由4 架战机组成,分别为plane_0、plane_1、plane_2、plane_3。在某一时刻,新节点plane_4 进入网络。飞机的飞行方向为太平洋海域。假定每个节点的信号发射功率足够大,任意两个节点都可以通信。仿真环境的基本情况如表1 所示。

表1 网络环境参数
在进行本文提出的基于排队论的数据链节点入退网时隙分配算法仿真的同时,对目前数据链使用的基于轮询机制数据链节点入退网时隙分配算法进行仿真,并依据网络吞吐量、队列时延、时隙利用率这3 个指标对网络QoS 性能进行判断。网络吞吐量指单位时间内网络中节点接收到数据的平均速率,队列时延指每个数据包从进入缓存到调度出去的平均时间,时隙利用率指网络时隙发送数据包的比例。
3.1 网络吞吐量
网络吞吐量指单位时间内网络中节点接收到数据的平均速率。基于轮询机制数据链节点入退网时隙分配算法和基于排队论的数据链节点入退网时隙分配算法的网络吞吐量分别如图7、图8 所示。可以看出,基于轮询的节点入网时隙分配算法的网络吞吐量在0.18 Mb·s-1左右,而基于排队论机制网络吞吐量平均在0.52 Mb·s-1左右。据此可以得出结论,排队机制论的网络吞吐量远大于轮询机制,同时轮询机制和排队论机制的网络吞吐量波动较少,整体较为稳定,说明排队论机制更适合大信息量数据链网络。

图7 轮询机制网络吞吐量
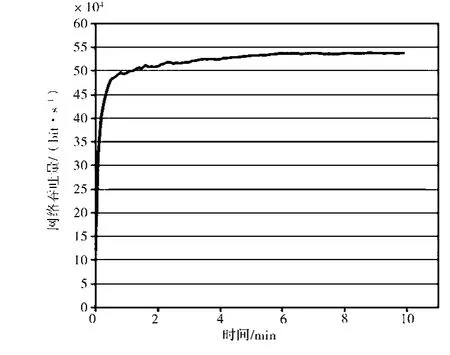
图8 排队论机制网络吞吐量
3.2 队列时延
轮询机制和排队论机制的队列时延情况分别如图9 和图10 所示。队列时延指每个数据包从进入缓存到调度出去的平均时间[11]。从图9可以看出,轮询机制的队列时延大约在0.32 s 左右,波动较小且较为平稳。从图10 可以看出,排队论机制的队列时延大约在0.21 s 左右,在网络形成初期波动较大,但逐渐趋于平稳。通过分析可知,排队论的队列时延明显小于轮询机制,说明排队论网络较为畅通,数据传输速率快,实时性高。

图9 轮询机制队列时延

图10 排队论机制队列时延
3.3 时隙率利用率
轮询机制和排队论机制的时隙利用率对比情况如图11 所示,其中,红色线为基于轮询机制数据链节点入退网时隙分配算法的时隙利用率,为60%,蓝色线为基于排队论机制数据链节点入退网时隙分配算法的时隙利用率,为75%。可见,排队论的节点优先级确定时隙分配和优先级动态调整的机制可以使得网络中时隙资源的分配更加科学。通过优先级动态变化的机制适时增长高优先级节点的时延,适当缩短低优先级节点的时延,高优先级节点“牺牲”时效,但更满足作战行动中整体的信息交互要求。

图11 轮询机制与排队论机制时隙利用率对比
4 结语
本文主要提出一种基于排队论的数据链网络节点入退网时隙分配算法。在设计思路上,一是利用排队论的思想进行时隙分配设计,二是设置最高特情优先级以应对战场随时会发生的特殊情况,三是规定优先级的动态修正原则防止低优先级节点分配不到时隙资源而造成的资源浪费,使网络对于节点优先级的管理更加灵活,在时隙资源分配上更加合理,这防止了网络节点资源分配出现“两极分化”的趋势。
通过与传统数据链使用的轮询机制时隙分配算法进行仿真分析对比可以得出,在网络吞吐量上排队论为0.52 Mb·s-1,轮询机制为0.18 Mb·s-1,排队论远大于轮询机制;在队列时延上排队论为0.21 s,轮询机制为0.32 s,排队论网络的实时性比轮询机制高;在时隙利用率上,相比于轮询的60%的利用率,排队论利用率更高,为75%。综合来看,基于排队论的数据链节点入退网时隙分配算法的时隙资源分配率较高,且算法对节点优先级较为敏感。算法适用于网络节点数目多且具备鲜明优先级关系的网络环境。短时间内,时延特性迅速稳定,可迅速投入战斗使用,满足对网络稳定性的较高要求。
