情感视角下的网络舆情研究综述
2022-04-01史伟薛广聪何绍义
史伟 薛广聪 何绍义
(1.湖州师范学院经济管理学院,湖州,313000; 2.湖州师范学院信息工程学院,湖州,313000; 3.加州州立大学圣伯纳迪诺分校商业与公共管理学院,美国,CA 92418)
1 引言
根据中国互联网络信息中心(CNNIC)发布的第48次《中国互联网络发展状况统计报告》,截至2021年6月为止,我国网民总数为10.11亿,手机网民总数为10.07亿,互联网普及率达71.6%。随着移动互联网的发展和智能设备的普及,信息获取和传递机制的改变不仅能使公众及时地了解国内外发生的突发事件,也使传统的社会舆论从线下转移到线上并演变为网络舆情。一般说来,网络舆情是指在一定的社会空间内,网民们通过互联网表达对于某个社会突发事件的看法、观点和情感的集合,是社会舆论在互联网上的映射与直接反映,并且表现出较强的自由性、多元性和交互性。如何正确处理网络舆情不仅是学术界重点关注的范畴,也是社会各界共同面对的问题[1]。
在大数据背景下,机器学习、深度学习和数据挖掘技术的广泛应用为深层次的网络舆情研究提供了方法支持,同时文本、图片和短视频等载体也为多维度的网络舆情研究提供了丰富的数据支撑。由于载体所包含的情感信息是推动舆情传播和发酵的重要因素之一,国内外学者逐渐开始从情感角度对网络舆情展开研究。通过引入情感分析技术探究网络舆情的情感演变规律和舆情事件的传播特征,有助于政府部门正确处置网络舆情、及时把控舆情导向,这对我国社会的发展和进步具有重要的现实意义。
本文系统整理了近些年国内外学者在情感视角下的网络舆情研究进展并分析了未来的研究趋势。我们的讨论基于Web of Science和中国知网(CNKI)所提供的文献,使用词云和CiteSpace软件作为可视化工具进行知识图谱的构建,通过文献分析法对国内外网络舆情情感分类、情感演化、情感预测和网络舆情治理四个方面的研究进展进行归纳与对比,旨在帮助相关学者进一步了解该领域的研究现状和发展趋势,为将来开展深层次研究提供理论参考和依据。
2 基于情感视角的网络舆情研究文献统计
2.1 文献来源
本文采用文献研究法分析国内外网络舆情的研究现状,中英文文献分别选自CNKI全文数据库和Web of Science数据库。由于网络舆情主要由突发事件引起,并且考虑到2020年爆发的“新冠肺炎”疫情引起的网络舆情,本文分别以“(主题:网络舆情)AND(主题:情感)OR(主题:新冠肺炎)AND(主题:情感)OR(主题:突发事件)AND(主题:情感)”和“sentiment analysis(All Fields)and public opinion(All Fields)”作为CNKI数据库和Web of Science数据库的检索式进行检索(检索时间为2020年12月31日),为了保证参考文献的质量,设置中文期刊来源类别为“北大核心”和“CSSCI”,英文期刊来源为“Web of Science 核心合集”。鉴于2008年国内接连发生诸多重大突发事件,新老媒体的互动使得网络具有巨大的舆论能量,网络舆情开始受到学者们的关注与研究,因此本文设置索引时间范围为“2008-1-1至2020-12-31”,最终检索出304篇中文文献和231篇外文文献。
2.2 文献时间分布
我们统计了2008年至2020年间CNKI和Web of Science数据库历年发表的相关文献数量,如图1所示,一方面反映出该研究领域历年来的发展趋势,另一方面也体现出学术界对网络舆情情感主题方面研究的关注程度。
从图1中可以看出国内外对该领域的研究趋势大致相同,2008年到2011年间该领域研究在国内鲜有人关注,直至2012年关注度才有所上升,“7.23温州动车事故”“雅安地震”“南方各地洪涝灾害”和“上海外滩踩踏事件”等突发事件在网络上不断发酵,致使更多学者从舆情情感的角度出发对突发事件网络舆情的演化和传播进行深入研究。2018年以来机器学习和深度学习等技术被大量应用在网络舆情的情感分析中,使得情感分类和情感演化得到更加精确的研究结果,2019年“凉山州森林火灾事件”和2020年“新冠肺炎疫情”的发生,使得该领域的关注度直线上升。相较于国内研究进展,国外学者从情感角度对网络舆情的研究起步较晚,直至“MH370航班失联事件”“埃博拉病毒肆虐”“拉斯维加斯枪击案”和“印尼海啸”等突发事件发生后该领域研究热度才逐渐上升,并在2018年以后呈现爆发式增长。2020年爆发的新冠肺炎疫情更是成为引爆网络舆情的导火索,网络舆情迅速在全球范围内产生并不断传播,使得该领域的关注度达到顶峰,同时也激发了更多学者对网络舆情的关注和研究。
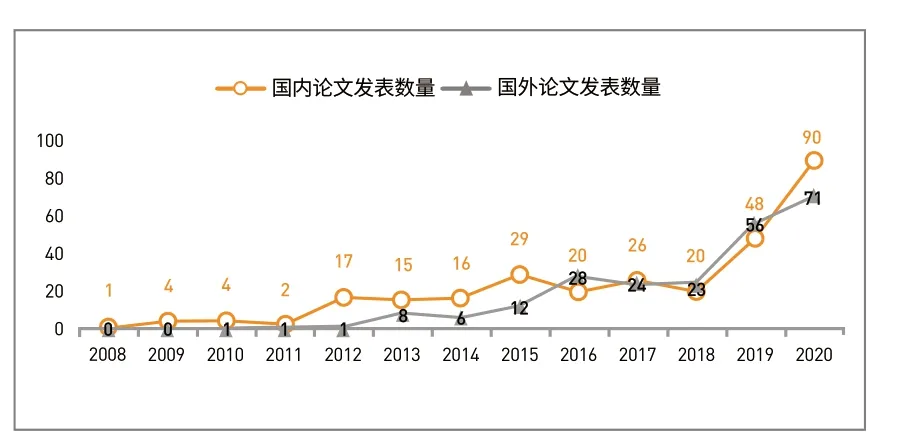
图1 ᅠ国内外网络舆情情感研究论文发表数量趋势图Fig.1 The Trend Chart of the Number of Published Research Papers on Network Public Opinion at Home and Abroad
2.3 文献关键词分析
关键词作为文献的关键信息和知识标签能够反映出文章的中心内容,本文统计了国内外文献中的关键词信息并进行词云可视化构建(如图2所示)。TFIDF是一种常用的信息检索与数据挖掘方法,具有很强的适用性和鲁棒性,其中词频(Term Frequency,TF)用于统计词语在语料库中出现的频次,逆文件频率(Inverse Document Frequency,IDF)则考察词语在多条评论中的共现情况,进而判断候选词对文章的刻画能力。某个词语对文章的重要性与它的TF-IDF值成正比,因此通过计算词语的TF-IDF值可以较客观地提取出文章高频词。我们抽取TF-IDF值排名前10的关键词进行比较,如表1所示,通过关键词对比可以看出,国内外学者在该领域的研究主要基于三种方法,即机器学习、深度学习和情感词典;同时,国内学者倾向于研究网络舆情的舆情分析、舆情监测、情感演化和情感分类,而国外学者对大数据环境下的网络舆情数据挖掘研究较多。
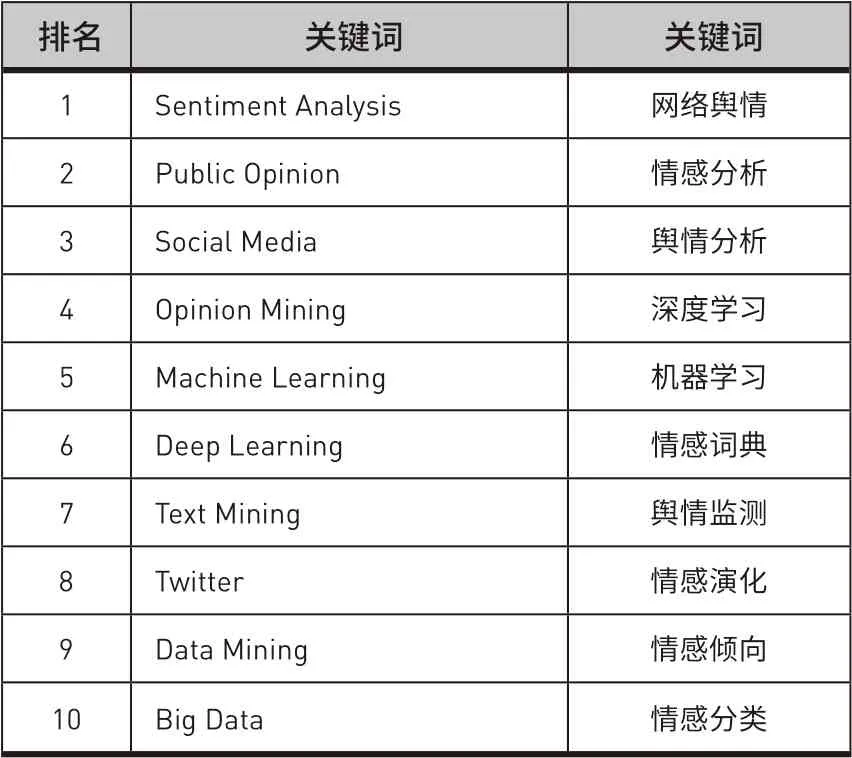
表1 ᅠ国内外网络舆情情感研究文献关键词排序Table 1 Keywords’Ranking of Domestic and Foreign Research Literatures in Network Public Opinion
2.4 国内外网络舆情情感主题研究热点分析
研究相关文献主题的变迁趋势能够反映出不同时期学者重点研究的方向以及该领域的知识发展历史和现状,因此我们利用CiteSpace软件绘制国内外相关文献的时间轴视图(如图3和图4所示)。该视图能够反映出各个聚类发展演变的时间跨度和研究进程,为各个子领域的演变路径提供了直观而准确的参考。从左到右依次表示关键词出现的先后时间顺序,从上到下依次表示递减的聚类信息,通过时间轴视图可以梳理出研究热点的历史来源及其发展脉络。网络舆情和情感分析研究从2010年到2020年一直是学术界研究的热点话题,早期研究方法主要以情感词典为主,随着大数据和新媒体的发展,研究方法逐渐多元化,如机器学习、深度学习、认知情感评价模型、社会网络分析、主题建模等。
3 基于情感视角的国内外网络舆情研究综述
目前文本情感分析技术主要应用在电子商务、市场竞争和在线评论等领域,随着网络舆情研究热度逐渐升高,情感分析也逐渐延伸到网络舆情领域。由于网络舆情受舆情主体、舆情客体和外部环境等多种因素的影响,因此对网络舆情进行情感分析是一个复杂的过程,图5描述了网络舆情情感分析的整个过程,包括网络舆情情感分类、网络舆情情感演化、网络舆情情感预测和网络舆情治理,下文将分别从这四个方面总结国内外网络舆情的研究现状。
3.1 网络舆情情感分类研究
情感分类是情感分析的基础和依据,传统的文本分类只关注文本的客观内容,而情感分类更多研究的是文本作者的“主观因素”,即表达者的情感倾向。本节对比了部分网络舆情情感分类文献的研究数据、研究方法和研究结果(如表2所示),并分别从三种技术层面评述网络舆情情感分类相关研究。

图2 ᅠ国内外网络舆情情感研究文献关键词词云Fig. 2 Keywords Word Cloud of Domestic and Foreign Research Literatures in Network Public Opinion Sentiment
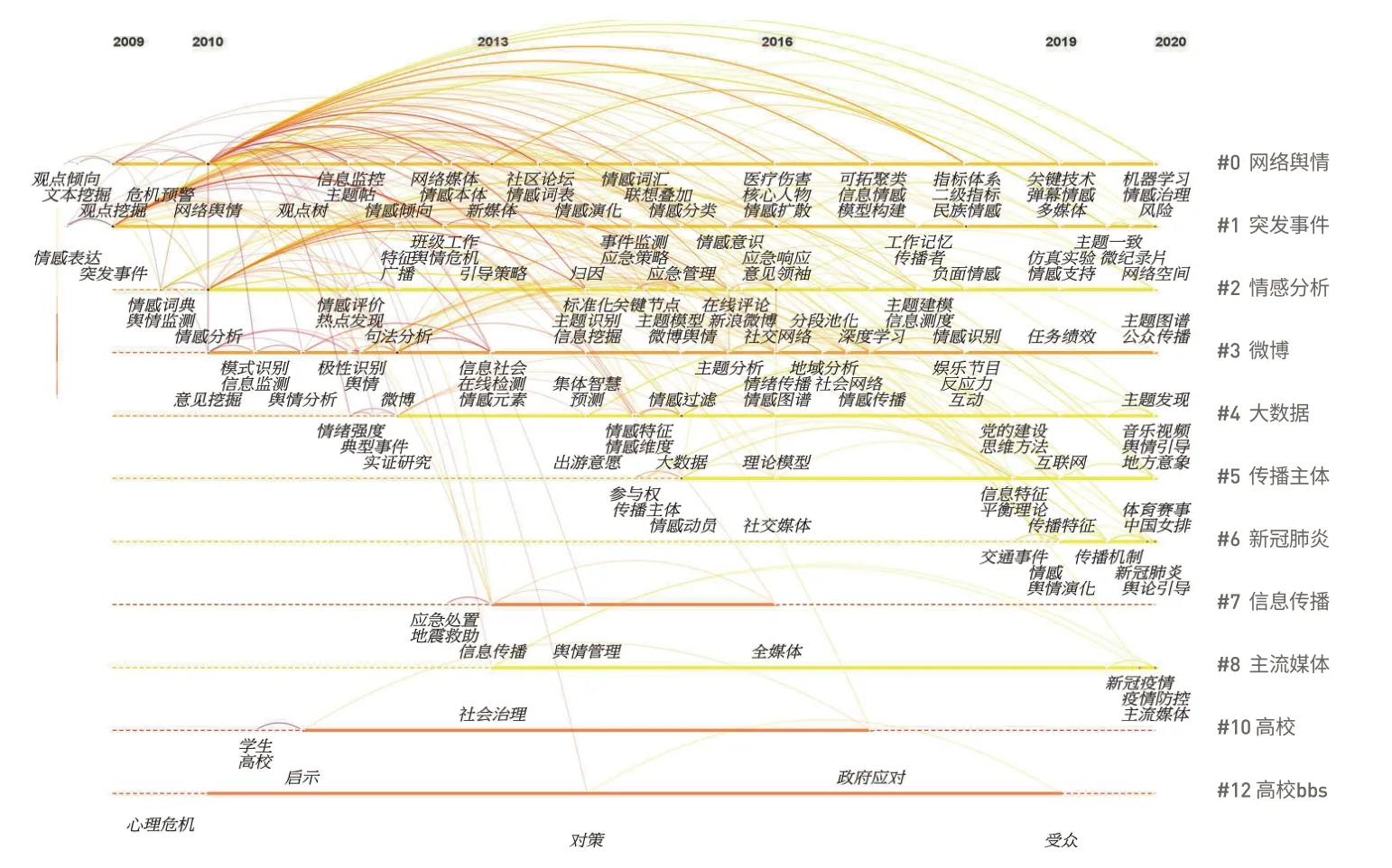
图3 ᅠ国内网络舆情情感研究文献时间轴图谱Fig.3 Timeline Spectrum of Research Literatures in Domestic Network Public Opinion Sentiment
一是基于情感词典分类方法。情感词典作为一种重要的情感分类资源,它的分类粒度的粗细程度直接决定了情感分析结果的准确性。有学者在通用情感词典的基础上结合同义词表、领域情感词和网络词汇等词语构建了不同类型的情感词典,例如表情符号情感词典(分为7种情感类:乐、哀、怒、惊、惧、好、恶)[2]、消防领域舆情情感词典(分为3种情感类:积极、中立、消极)[3]和突发事件领域情感词典(分为7大类21小类)[4]等。鉴于大多数研究集中在文本内容的浅层特征,而对其内在特征关注不足,曾子明[5]基于改进后的情感词典提出一种融合深层演化特征、浅层词性特征和情感特征的多层次特征组合模型,将情感进行正负性分类并且准确度达到85%;栗雨晴等[6]基于HowNet、WordNet和NTUSD词典构建双语情感词典将微博文本情感分为社会关爱、高兴、悲伤、愤怒、恐惧五类,该词典有效解决了文本情感分析方法多基于单一语种的问题;Xu等[7]结合基本情感词、五种场景情感词和多义情感词组建新的情感词典,通过设计的情感计算规则有效实现了文本情感分类。虽然情感词典无须通过大规模数据的训练来提高情感分类准确率,但对不同领域的情感分析研究仍需构建有针对性的领域情感词典。
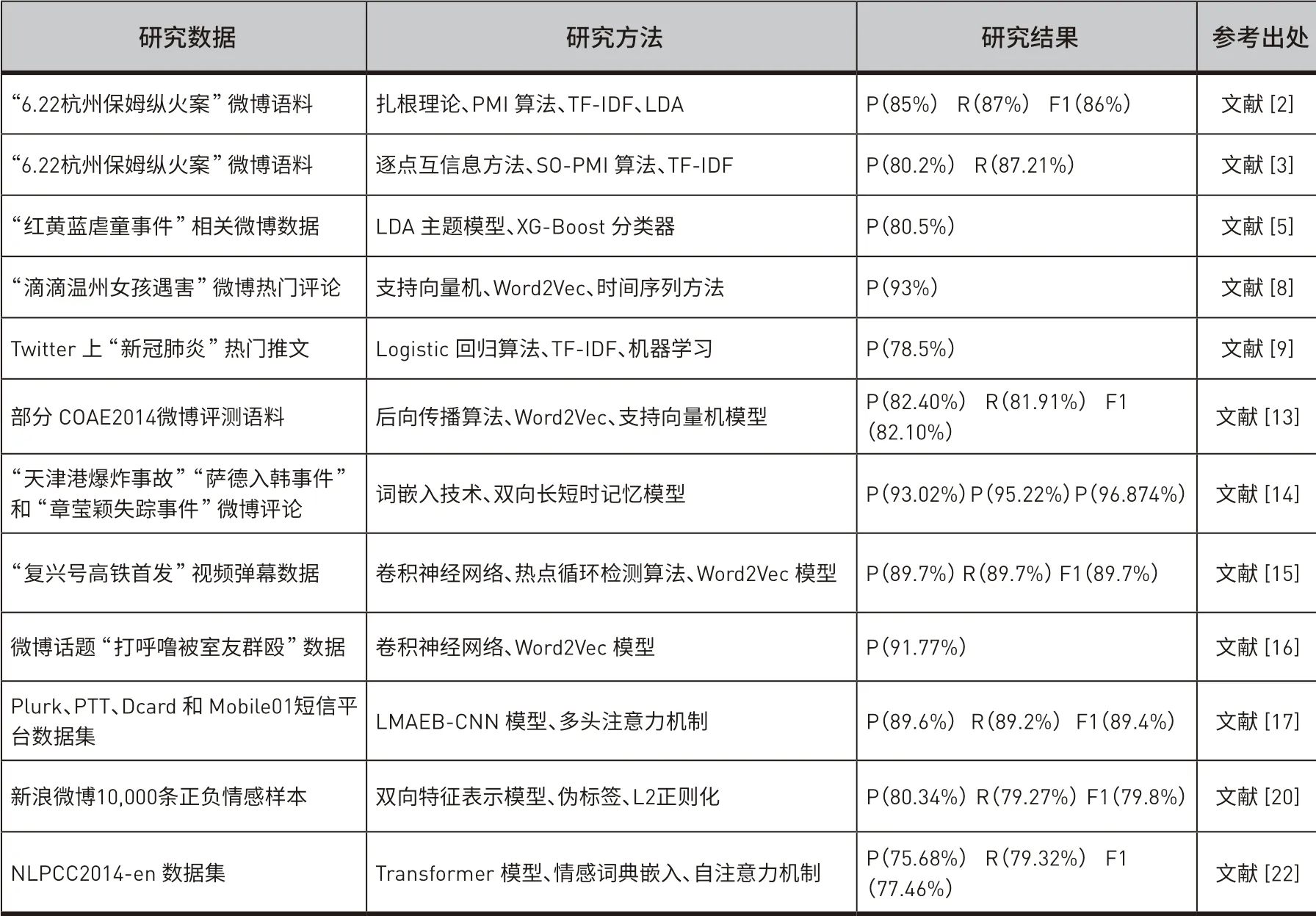
表2 ᅠ国内外部分网络舆情情感分类研究文献对比Table 2 Comparison of Some Domestic and Foreign Network Public Opinion Sentiment Classification Research Literature
二是基于机器学习方法。机器学习是一种使用大量有标注的或无标注的语料进行模型训练的学习方法,目前已经在情感分类方面取得较多不错的成果。邓君[8]基于Word2Vec和支持向量机将微博舆情文本情感分为积极和消极两类,经训练后该模型的分类准确率达到93%,但其并未考虑句式和语法结构对情感分类准确率的影响。C.R.Machuca等[9]运用自然语言处理技术和Logistic回归算法将新冠肺炎疫情相关的Twitter文本自动分为积极或消极两个维度,分类精度达到78.5%。Kaur等[10]采用N-gram算法和KNN分类器分别进行特征提取和情感分类,将文本倾向分为正、负和中性情感,实验结果表明该模型分类性能优于现有模型,情感分类准确率达到82%。Li等[11]开发了一种联合训练算法,结合L-BFGS算法和多标签最大熵模型(MME)将短文本情感分为生气、厌恶、害怕、开心、伤心、惊讶六大类,在微博、推特、BBC论坛等数据集上的平均准确率达到86.06%。Er等[12]提出一个情感词典和机器学习方法相结合的Twitter情感分析模型,根据用户频繁使用的表情符号和非正式英语进行情感分类,总体准确率可以达到81.9%,优于传统的情感词典和机器学习方法。杨爽等[13]提出一种基于SVM多特征融合的情感分类模型,从词性、情感、句式和语义等特征实现情感的五级分类,该模型在短文本情感分类中取得较高的准确率。

图5 ᅠ网络舆情情感分析过程Fig. 5 Analysis Process of Network Public Opinion Sentiment
三是基于深度学习方法。该方法主要通过情感标注、词向量训练以及长短期记忆网络(Long Short-Term Memory,LSTM)[14]、卷积神经网络(Convolutional Neural Networks,CNN)[15-17]和循环神经网络(Recurrent Neural Network,RNN)对情感进行正负性或褒贬性等不同程度的分类。认知情感评价模型(OCC)被认为是第一个以计算机实现目的而发展起来的情感模型,吴鹏等[18]提出一种基于OCC的卷积神经网络情感识别模型,通过OCC模型进行情感标注并建立极性计算规则对舆情文本进行情感分类,最高可达90.98%的准确率。金占用等[19]应用OCC情感规则能提高模型分类准确率的特点,基于长短期记忆网络模型构建了网络舆情多情感分类模型,将情感分为积极情感、消极情感和中性情感。为解决传统模型无法根据语境对词语进行理解,孙靖超[20]设计了一种基于优化深度双向自编码网络的情感分类模型,通过伪标签方法、混合池化以及L2正则化提高模型泛化能力,实验表明该模型在小数据集下具有更好的分类性能。郭修远等[21]基于神经网络模型提出一种多输入多任务协同学习的情感分类模型,有效地解决了单任务单输入模型分类效果不佳的问题。由于循环神经网络编码器受递归模型的限制,导致获取语句序列信息有限,陈珂等[22]提出一种基于情感词典与Transformer模型的融合特征信息情感分类模型,引入自注意力机制使得模型在训练过程中能学习到丰富的情感特征信息,最后在不同语言的数据集上均取得较好的分类准确率。
综上,传统的情感词典方法主要依赖种子情感词和人工设计的规则,但互联网时代信息更新速度加快,不断涌现出热门词语和网络特殊用语等,需要不断扩充情感词典才能满足需要。为了提高情感分类的准确率,学者通过大量有标注或无标注的语料使用各类机器学习算法进行情感分类,虽然情感分类性能一定程度上优于情感词典,但机器学习方法往往忽略了上下文语义信息从而影响情感分类的准确性。与机器学习不同,深度学习具有较强的特征学习能力,能更好地融合上下文信息以解决传统情感分类方法中的缺陷,有效提高情感分类的准确率,但其训练时间长、可解释性差的缺点也较明显。
此外,目前网络舆情情感分类的研究数据多来自不同领域的文本信息,但是随着多媒体时代的到来,网民的情感表达方式逐渐向图像和视频转移,结合多媒体数据中的多模态信息可以挖掘出更加准确和丰富的情感信息,提高情感分类的准确率。例如:Cao等[23]基于视觉情感本体(Visual Sentiment Ontology,VSO)提出一种视觉情感主题模型(Visual Sentiment Topic Model,VSTM)对图像中隐含的情感信息进行正面、负面和中性分类,该模型可以选择出具有区别性的视觉情感本体特征来增强视觉情感分析效果;Huang等[24]提出一种新的图像-文本情感分析模型即深度多模态注意力融合模型(Deep Multimodal Attention Fusion,DMAF),利用视觉内容和文本数据之间的区别特征和内在关联进行联合情感分类,并在四种不同的数据集上验证了该模型的有效性;章荪等[25]提出一种多任务学习的情感分类模型,使用卷积神经网络(CNN)和双向门控循环神经网络(BiGRU)进行模态特征维度的统一和序列数据关联性的挖掘,引入多头自注意力机制实现跨模态信息的融合,以情感评分作为分类依据,在公开多模态基准数据集上测试的模型分类精确度和F1值达到84.7%;范涛等[25]设计一种多模态融合情感识别方法,分别构建BiLSTMs模型和基于迁移学习的微调CNNs模型提取文本和图片的情感特征,在特征层融合后输入支持向量机中进行情感分类,实验将数据集的情感极性分为正面、负面和中性三类,所提出的情感分类模型准确率达到85.3%。多模态情感分析领域的复杂性体现为情感信息之间的关联性,同时也影响对多模态对象的情感判断,如何搭配最佳的模态内容进行情感分析值得学者们进一步研究。
3.2 网络舆情情感演化研究
情感演化是通过分析带有情感色彩的主观性信息,并基于情感态度和观点分析情感在时间和空间上的演化规律。针对各种突发事件中此起彼伏的舆论热潮,国内学者从不同维度对网络舆情的情感演化过程进行了全面分析和研究,而国外学者在这方面的相关研究较少。本节系统整理了国内学者近年来关于网络舆情情感演化的主要研究内容,如表3所示。从表3中可以看出目前国内研究所使用的方法有模型构建[27]、朴素贝叶斯[28]、态势感知理论[29]、K-邻近算法[30]、生命周期理论[31-32]、深度学习[33]、聚类算法[34]、数据仿真[35]等,这些方法的应用进一步拓展了该领域的理论研究和实践探索。例如,为了探究移动环境下网络用户情感演化规律,王晰巍等[28]应用改进的朴素贝叶斯模型对用户评论进行情感倾向性识别,分别基于词频、地域和时间三个可视化维度探究用户的情感变化趋势,深度分析移动环境下网络用户不同的情感表达对舆情传播的影响,但朴素贝叶斯分类器往往会忽略掉特征词的上下文信息,导致情感文本的信息缺失。在此基础上,陈凌等[36]利用长短期记忆神经网络(LSTM)结合情感上下文信息,通过多层次时间序列分析台风“利奇马”事件特性与网民负面情感之间的关联,研究发现不同危机情境下社交化媒体用户表达出的负面情感各不相同,后续可以关注情感波动对舆情事件期间社交媒体信息的影响。福岛核泄漏事故发生后,Hasegawa等[37]通过对推文的区域标识符(名词、地名、邮政编码和电话号码等)进行分类,然后根据单个推文的情感倾向(积极或消极)来分析民众对这些地区的感受,研究结果发现事故发生后网民对辐射的负面情绪随时间推移呈下降趋势,但对福岛县的负面情绪却变得更加极端。
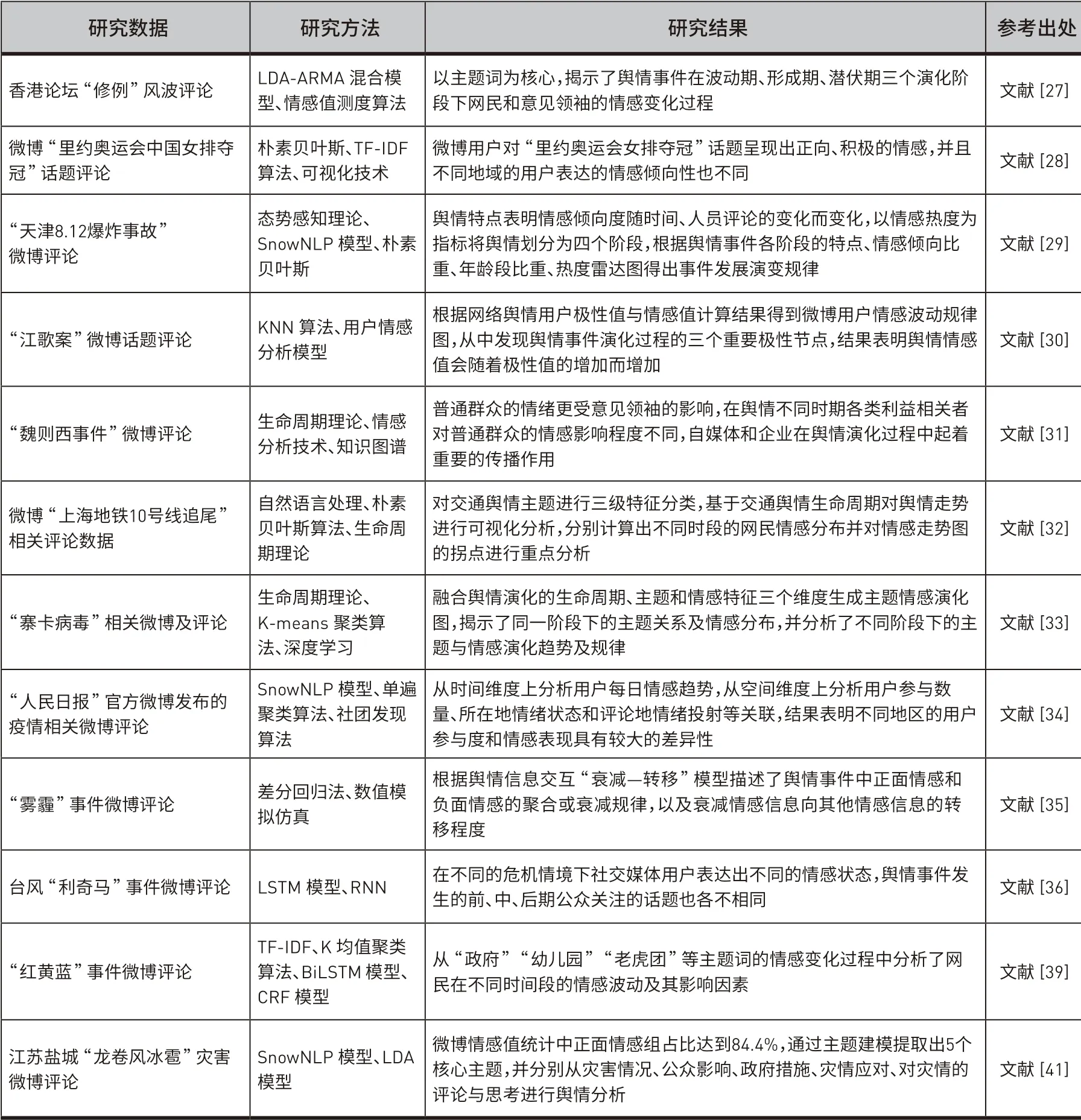
表3 ᅠ国内网络舆情情感演化研究文献整理Table 3 Domestic Network Public Opinion Emotion Evolution Research Literature Collation
在舆情主题分析方面,安璐等[33]通过用户转发关系、情感类型和情感强度绘制社会网络情感图谱,结合舆情话题综合分析利益相关者的情感演化过程,结果表明普通群众的情感更易受意见领袖的影响,各利益相关者的主导情感也随着舆情演化而不断变化。林永明[38]提出一种动态主题情感模型(dSLDA)识别舆情主题和网民情感,依据舆情趋势、词汇主题和情感标签分析舆情事件各个话题的情感分布特征和波动趋势。朱晓霞[39]和Liu[40]针对静态情感判断的局限性提出一个动态主题—情感演化模型来对整个情感演变过程进行动态情感分析,在主题提取方面相较于传统方法性能有所提升。刘丽群等[41]从社会计算视角出发,综合情感分析结果和舆情主题总结了网民关注的热门舆情话题,从灾情情况、政府应对、灾民感受等方面对舆情相关因素进行分析,社会计算技术提高了网络舆情态势的分析能力,从结果上看更贴近舆情本身。此外,Fu[42]和Huang[43]研究了个体情绪、网络结构、舆情传播主体与环境等内外因素对网络舆情演化的影响。Fang[44]运用情感分析技术和分室模型模拟社交媒体上网络舆情信息的传播过程,根据公众情感倾向和模拟结果对七个社会舆情话题的趋势进行评估。Wang等[45]通过分析网民主流情感强度的突变特征来识别舆情爆发的关键时间窗口,有助于防止舆情事件进一步恶化。Andrea等[46]通过探讨Twitter用户的情感极性与每日推文数量峰值的对应关系,从中发现可能会引起公众兴趣或影响公众舆论的疫苗接种事件,然后根据相关事件追踪公众对疫苗接种话题立场的变化趋势。Zhang等[47]研究了大规模金融舆情中公众的情绪状态是否与时间、股票交易数相关,基于网络舆情空间信息生成多维时间序列,采用格兰杰因果分析和信息论的方法研究社交媒体情感对金融舆情演变过程的影响。
目前网络舆情情感演化研究大多从时空关联、舆情主题和传播特征等方向出发,从文本中提取信息进行情感演化分析,往往忽略了社交网络中用户亲密度、用户影响力等多种因素对舆情演化的影响,而这些用户特征可能包含着提高模型解释性和准确性的提示。舆情演化过程作为网络舆情的核心研究内容已经得到国内外学者们的全方位关注,未来可以从深层次、多维度等方向对网络舆情演化进行分析。
3.3 网络舆情情感预测研究
目前网络舆情情感预测的研究普遍基于统计学、机器学习和情感分析等方法,通过对已有情感信息分析来预测未来短期内的网民情感状态,但是网络舆情演化过程中网民情感会受到内外因素作用的影响而产生偏差。我们分别从研究数据、研究方法和研究结果三个侧面对国内外相关文献进行了梳理(见表4)。在情感态势预测方面,李彤[48]以创新的集成学习思路为指导,构建了微博情感走势时间序列提取情感序列特征,然后结合ARIMA、BPNN等回归模型和SVM模型对微博情感趋势进行预测,虽然在特征选择上仍采用了传统的方法,但比单一使用ARIMA模型的预测误差更小。吴青林等[49]通过设置特征词相似度阈值、增加相关特征词数量,克服了短文本相似度的漂移问题,基于微博话题聚类、情感强度计算和灰度模型跟踪并预测了公众所关注热点话题的情感变化趋势,实验表明只有个体情感稳定的情况下情感预测结果才比较准确。Zhang等[50]将文本情感分为20种细粒度情感类,结合文档频率和信息增益原则提取文本特征,基于最大熵模型(MaxEnt)对微博评论进行情绪成分分析和网络舆情趋势预测,该方法收敛时间短,在预测民意的准确性方面优于朴素贝叶斯和支持向量机基线方法。以上研究虽然取得较高的预测准确性,但是并没有考虑到除舆情文本以外其他因素对预测效果的影响。在此基础上,郭韧[51]运用关联函数和可拓聚类理论将舆情事件的情感倾向、舆情演化上升期日均提及量和关注度单位时间内的增长率三种因素封装为一个整体进行舆情演化预测,实现了定量分析和定性分析的有机结合。
在情感倾向预测方面,鉴于已有方法大多侧重于从文本本身挖掘信息而很少研究用户自身特征,Li等[52]提出了一个“时间序列+用户”的双重关注机制模型,将文本情感特征与时间序列特征相结合,实现了单位时间内多用户多文档的情感预测,所提出的双重关注机制模型可以更好地关注强关联信息,弱化噪声数据的影响,对提高预测结果起到一定的作用;X.Dong等[53]利用阻尼振荡模型测量公众情感的自我衰变过程,讨论模型中弹簧系数、阻尼系数和情感临界值等关键参数对舆情动态的影响,使用粒子群优化算法调整模型,并引入自我情感适应机制对意见领袖和极端情绪化个体的情感倾向进行实时预测;Gupta和Halder[54]提出了一种混合情绪和行为的预测系统,通过分析文本极性的不同标志确定作者的态度,使用SenticNet4.0词典和人工配置的文件词典评估输入文本并预测文本所传达的情感,以此识别作者的行为和情感模式。在大数据背景下,Akhta等[55]提出了一种通过使用多层感知器网络组合数种深度学习和经典特征模型来预测情感倾向和情感强度的堆叠集成方法,具有较好的性能。Thota[56]结合深度学习和主题嵌入技术开发了一个主题情感检测框架,实验结果表明该框架具有高准确性。唐晓波构造了一个情感强度时间序列分析方程来预测公众情感倾向,但未考虑到文本相似度漂移、情感强度模糊性等问题,王秀芳等[57]针对这些不足对话题聚类和情感强度量化方法进行改进并建立了随时间变化的公众情感倾向趋势分析模型,其预测精确度达到88.97%。
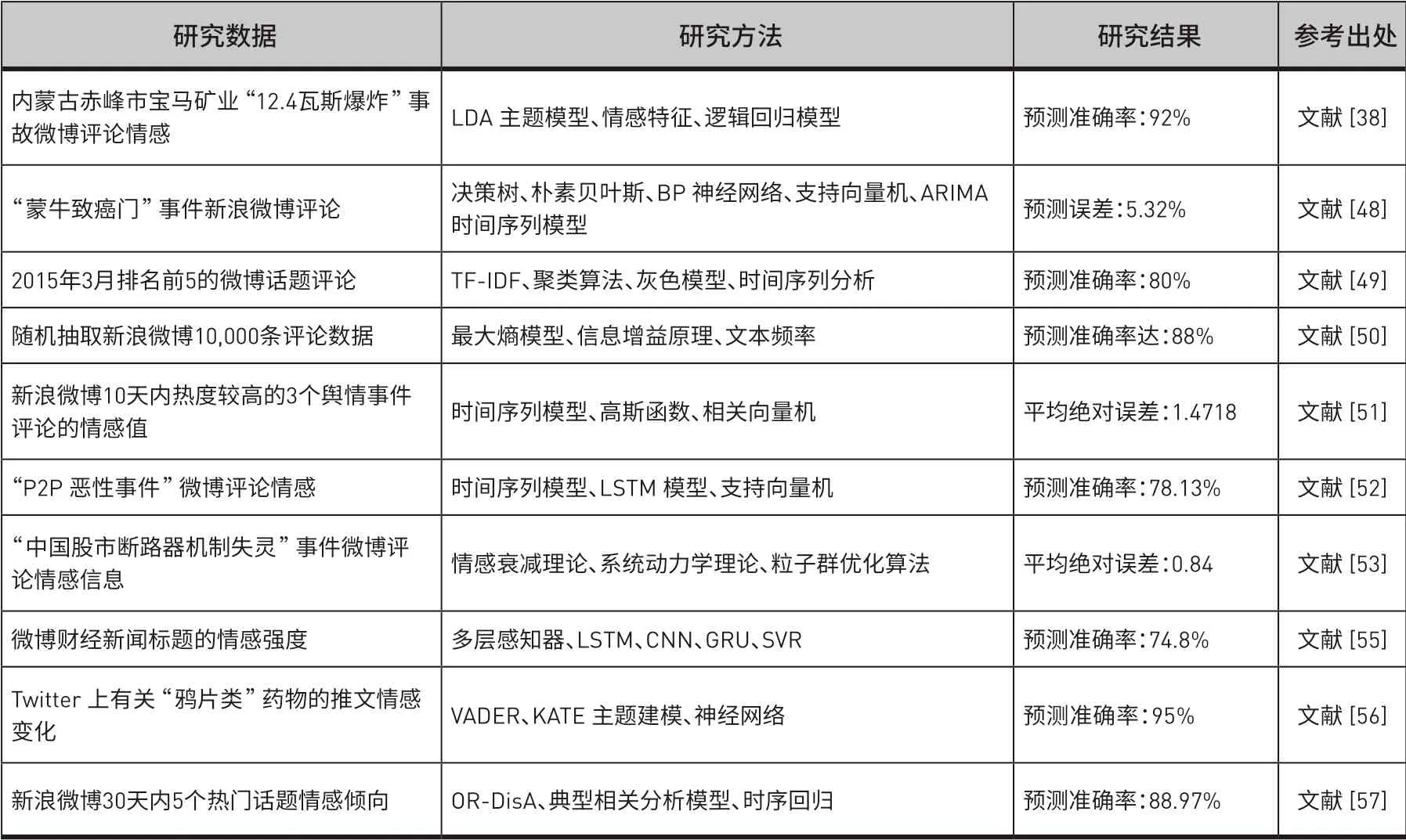
表4 ᅠ基于情感的网络舆情预测研究文献归纳Table 4 Literature Summary of Emotion-based Network Public Opinion Prediction
情感预测研究可以有效地对网络舆情情感的未来趋势进行分析,以便预先提出针对性的舆情应对措施。上述研究大多基于文本单一模态,结合时间序列特征和情感特征对舆情情感态势和用户情感倾向进行预测,但是单模态数据容易存在信息不全面、噪声干扰等问题,使得情感预测系统的鲁棒性和精确性等不能得到保证。因此未来可以结合图像、视频和语音等多种模态数据中的情感特征,合理利用多模态信息互为补充、互为印证的关系提高情感预测模型的性能。
3.4 网络舆情治理研究
网络舆情治理的研究主要针对政府、企业和网络媒体等不同主体展开(如表5所示)。基于政府方面的研究,研究人员利用实证研究、数据仿真等方法分析了不同阶段的舆情载体情感状况,并从信息透明、舆情预警、态度引导、时度效等方面提出建议[4,58-59],这些研究有助于强化政府部门对网络舆情监控、引导和治理。基于企业方面的研究,所提出的舆情治理措施有:提高企业舆情响应速度,加强核心竞争领域监管,及时回应民意等[60-61]。基于网络媒体方面的研究,由于其具有快捷性、开放性和互动性等特点,相关研究提出营造良好网络氛围,明确沟通态度,强调价值引导等建议[62-64]。此外也有学者针对多元主体协同治理提出应对策略[65]。
提高舆情治理能力是网络时代的必然要求,特别是重大突发事件发生期间舆论密度会加剧,政府、企业和网络自媒体等应改进网络舆情的治理方式,现有单一的治理体系并不能有效地引导舆情,政府应加强网络环境建设,与企业和网络媒体等主体形成协同治理格局。
3.5 其他相关研究
网络舆情不仅具有突发性,而且蕴含着强烈的群体情感极性。随着微博、Twitter等社交平台的兴起,研究人员不仅研究话题中舆情特征的分布情况,并且开始结合用户情感进行网络舆情事件识别。例如,张鲁民等[66]基于FP-growth算法和互信息度量构建情感符号模型,利用改进Kleiberg算法检测情感符号序列中的突发期,采用近邻传播AP聚类检测突发事件,大大缩短了舆情事件的检测时间,平均准确率达到85%;兰月薪[67]基于生命周期理论将舆情演化过程划分为潜伏期、扩散期和消退期,并根据特征突发词在不同时期内的情感变化规律来检测突发事件;尉永清等[68]结合具有时序突发性的网络数据流事件特征和用户信息情感特征提出一种融合情感特征的突发事件识别方法,能够在相对较早的时间内识别在线突发事件;由于微博通常使用“#”标签来描述事件,Zou等[69]采用情感和标签结合的模式,基于普鲁奇克情感轮[70]和标签传播算法构建离线情感共现图,通过在线使用互信息和频繁树来提取突发事件关键字,该方法可以在分析微博情感的同时在线检测突发事件,但也受限于标签的存在性。
在对突发事件识别的研究中只考虑网民的情感变化特征还不够全面,张雄宝等[71]发现突发事件相关微博的发布地域随事件演变呈现出一定的变化规律,因此提出一种基于突发词地域分析的突发事件检测方法,从评论文本的地域范围、情感属性两个维度识别突发事件,该方法相较于基于爆发词识别的突发事件检测方法(Bursty Words Distinguishing,BWD)和基于突发词H指数的突发事件检测算法(HIndex,HI)在正确率、召回率和F1均值上都有显著提高;仲兆满等[72]也考虑到突发事件的地域特性和微博评论的时空特点,提出一种地域Top-k突发事件检测框架,利用词出现频率、词关联用户、词分布地域以及词社交行为四种指标计算网络词突发值并提取突发特征集,选用凝聚层次聚类方法获取突发词簇集合,最后融合突发词地域、频率、关联评论、评论影响力以及关联用户五种指标计算Top-k突发事件热度,实现基于网络地域的突发事件识别。

表5 ᅠ国内网络舆情治理的策略研究Table 5 Domestic Network Public Opinion Management Strategy Research
网络舆情在社交媒体上的传播具有较强的地理位置性、传播爆炸性、时空相关性等特点[73],传统的网络舆情识别研究主要依赖于语义信息和复杂社会网络信息,但网络舆情通常是一个从无到有的传播过程,往往仅涉及社会网络的局部区域,通过对关键结构进行监控的方法容易存在滞后和遗漏。除了文本形式,网络舆情也经常以视频、图片、声音等非文本形式存在,基于语义信息的方法无法准确提炼舆情特征,深度学习是近年比较热门的研究方法,将其与情感分析的研究方法相结合,可有效提升模型获取信息、挖掘特征的性能。
4 结语
近年来,国内外网络舆情相关的研究成果主要分为基础理论、支持技术和应用研究三个层次,所分析的领域已经从在线产品评论转向社交媒体文本。除产品评论之外,情感分析的应用已经拓展到了股票市场、选举、灾难、医学、政治和企业等领域。本文对情感视角下的网络舆情情感分类、情感演化、情感预测和舆情治理四个方面的相关文献进行了统计分析、归纳和对比,并对未来研究方向作出如下展望:
(1)多方法融合下的情感分类研究
情感分类是情感分析的重要基础,传统的方法主要基于情感词典和机器学习方法,由于语言的多样性和复杂性,不同语言在不同领域中的情感表达可能有所差异,因此构建高效的通用情感词典和情感分析模型是未来的一个研究方向。此外深度学习方法也被逐渐应用于情感分类领域,该方法的优势在于不依赖人工定义特征,可以实现端到端的自主学习,但其训练时间久、解释性差等缺点也非常明显。最近两年出现的图神经网络是从卷积神经网络拓展而来的一种新型神经网络,在反映实体及其之间的关联性方面展现出了巨大的潜力,图神经网络方法的可推理性和高解释性的特点弥补了传统深度学习方法的局限,可以较好地捕获单词之间的依赖关系,提升方面级情感分类性能,在今后的研究中将图神经网络模型用于情感分析是非常值得探索的方向。
(2)多重信息载体下的舆情情感研究
目前,国内外的网络舆情情感研究主要通过对社交媒体中的文本信息进行情感挖掘与分析,随着互联网逐渐向移动社交化转变,图片和视频等载体因综合了画面、色彩、文字等特征成为网民表达情感的新形式。相较于单模态信息,多模态信息情感表达更加丰富与复杂,多模态情感分析也具有更高的准确性和稳定性。目前,多模态情感分析研究主要包括三种方法:特征级融合、决策级融合和混合融合。虽然已经有学者对图片和视频的情感信息进行了相关研究并取得了不错的进展,但如何将这种新载体的情感分析应用到网络舆情领域,以及在对网络舆情情感分析时如何根据模态的不同选择适当的模态融合方法,将是未来学者们需要研究的问题。
(3)多角度集成视域下的舆情预测研究
网络舆情的预测方法普遍基于统计学、社会学、信息传播学和人工智能等学科,通过分析网络舆情在不同阶段下的差异时序特征以及量化传播过程中用户的情感极性实现网络舆情的演变趋势预测,该过程是一种时空序列预测[74],即根据已获取的历史数据来预测未来某个时刻的时空变量值。目前除了从情感角度对网络舆情波动情况进行研究,还应充分考虑舆情数据中存在的隐藏信息、关联关系以及网民的认知能力等因素,随着深度学习技术的蓬勃发展,如何利用深度学习挖掘舆情数据中的隐含特征、提高舆情预测的精确度、解决“数据过剩,信息匮乏”的困境是未来需要努力的方向。
(4)多元主体协同下的舆情治理研究
网络舆情治理是政府职能的重要组成部分,对网络舆情及时准确的治理可以有效降低其产生社会风险的可能性。有学者针对传统治理模式下的政府信息公开不透明、政府“一元主体”等问题提出了相应的改进建议,但由于网络舆情的影响因素具有多样性特征,未来我们还要根据多主体、多平台、多形式的特点实施有针对性的策略,综合运用政府舆情治理能力和线下各主体的协同治理能力,有效应对网络舆情治理过程中出现的次生风险,构建政府主导下的多主体协同的网络舆情治理模式、治理环境和治理机制。
作者贡献说明
史伟:提出整体研究思路和框架;
薛广聪:论文起草及修改;
何绍义:论文最终版本修订。
支撑数据
支撑数据由作者自存储,Email:xgc735570365@163.com。
1、史伟,薛广聪.Research data of network public opinion and emotion.txt.网络舆情情感研究数据.
