一种基于PCIE总线的多通道DMA传输系统设计
2022-03-31李靖舒夏东方王冬华
沈 洋,李靖舒,夏东方,王冬华
(中国船舶集团有限公司第八研究院,南京 211153)
0 引 言
随着雷达系统在阵列规模、波束数、瞬时带宽、实时性等方面的不断提升,高速数据传输系统的需求也日渐提高,PCIe总线作为第三代高速串行计算机扩展总线标准,因其大吞吐量和支持DMA的特性,被广泛应用于雷达领域的高速数据传输系统和高速数据采集系统中[1-2]。本系统采用PCIe总线实现FPGA芯片与CPU芯片之间的互联,设计一种由FPGA主动发起的BLOCK DMA传输流程,FPGA在DMA包写入完成后立即将DMA描述符写入内存,CPU通过不断查询内存中的DMA描述符来获取DMA传输完成状态和信息。同时,本设计支持多通道虚拟DMA和多地址轮流DMA,更适合雷达系统中数据的流水传输与处理,有效地减少了数据传输过程中CPU的参与和干预,减轻了CPU的负担,从而使得CPU性能在雷达信息处理中得到更好的发挥。
1 系统构成及工作原理
1.1 系统构成
本系统的实现基于全国产软硬件环境。硬件部分采用国微的SMQ7VX690T FPGA芯片和飞腾的FT1500A/16 CPU芯片通过PCIe3.0总线x8模式进行互联,单lane波特率为8 Gbps,编码方式为128 b/130 b编码,理论速度高达7.8 GB/s。软件部分采用国产“银河麒麟”操作系统,并基于“银河麒麟”系统开发对应的PCIe设备驱动和应用程序。本系统在雷达中典型应用的数据流如图1所示,雷达中频数据由光纤进入FPGA中,FPGA通过PCIe总线的DMA方式将数据送入CPU挂载的内存中,CPU再将数据的处理结果通过网络发送给下一级处理机。

图1 雷达数据流
1.2 传统DMA传输原理
传统DMA传输系统的典型流程如图2所示。在CPU打开并初始化PCIe设备和DMA资源后,向FPGA发送一次DMA传输的大小和DMA传输的起始地址等信息,并发送开始一次DMA的命令;FPGA收到开始DMA的命令后,从DDR中读取已缓存的雷达数据,并通过memory write类型的TLP包将数据直接写入内存。当写入的数据达到设置的DMA大小时,FPGA向CPU发送DMA完成中断;CPU收到中断后须对收到的DMA数据进行解析,从而形成雷达的帧数据;CPU将数据拷贝到别处后发送下一次DMA参数(DMA参数不变时可以省略该步骤),并向FPGA发送开始新一次DMA的命令;如此循环[3-4]。
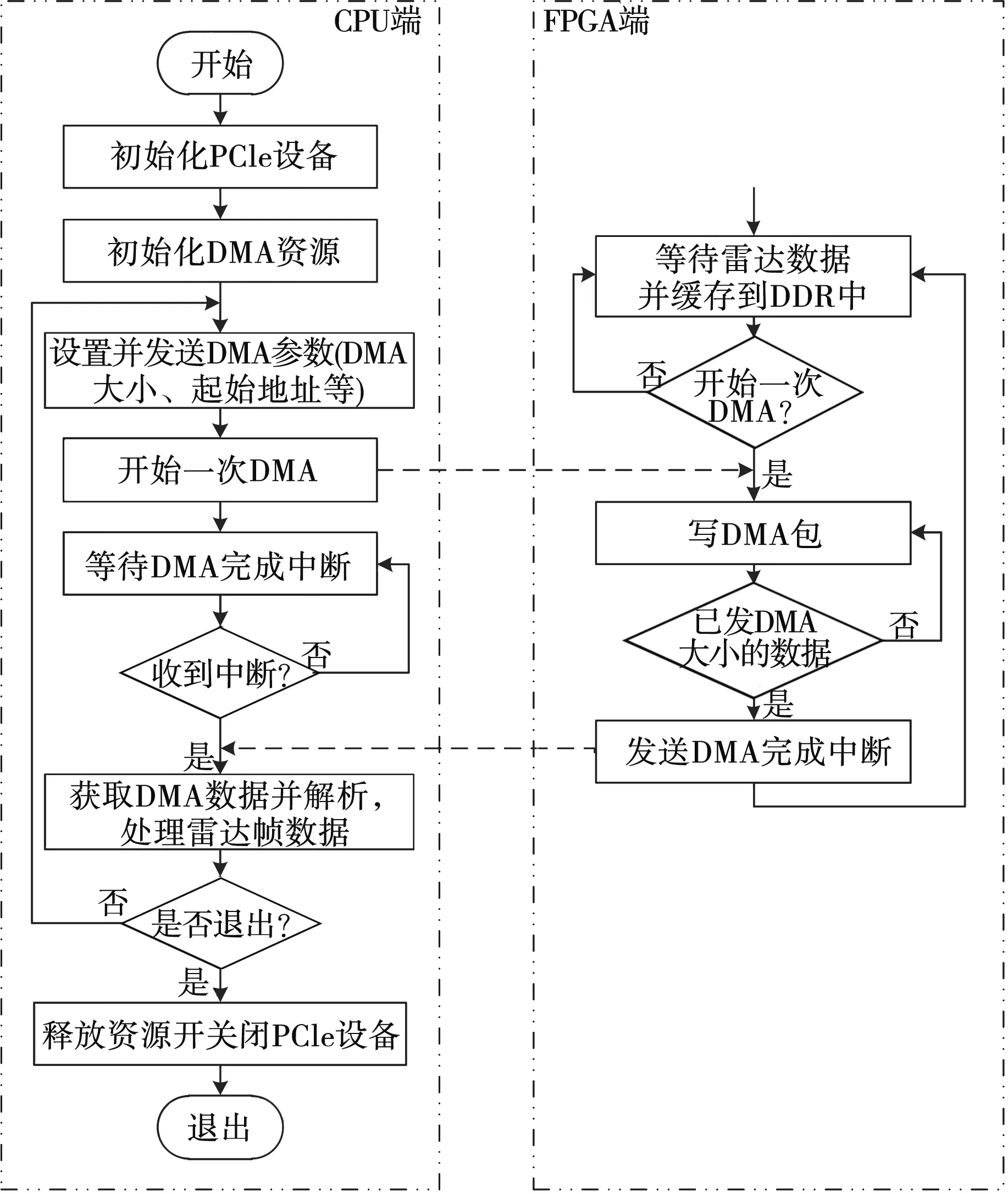
图2 传统DMA传输流程
传统DMA传输流程由CPU发起每次DMA传输,且需要提前知晓并设置DMA大小,而雷达帧数据由FPGA向CPU端流动时,CPU往往无法预计雷达帧数据的大小,因此只能设置一个固定的DMA大小,CPU收到数据后再通过查找雷达帧头的方式来解析并形成雷达帧数据,通常解析数据需占用大量CPU资源。另外,由于每次DMA传输需要由CPU发起,而CPU开始DMA命令的本质是寄存器写命令,因此整个DMA传输过程需要CPU频繁参与并插入相对耗时的操作,从而使得DMA传输效率很难提高。同时,由于DMA的发起时间不受FPGA(数据源端)控制,为了保证DMA传输过程中雷达的流式数据不被丢弃,需要FPGA先将数据写入大容量的外挂DDR进行缓存,DMA传输时再从DDR中读取数据并送给PCIe总线。
1.3 改进DMA传输原理
为了解决传统DMA传输流程在雷达系统中的应用所带来的弊端,本系统设计了一种新的DMA传输流程,如图3所示。图3在CPU初始化PCIe设备、设置DMA参数并初始化DMA资源后,向FPGA一次性发送n组DMA传输的起始地址、上报地址等信息,并发送启动DMA的命令; FPGA收到DMA参数和启动命令后,将循环使用DMA起始地址和上报地址:FPGA将第1帧完整的雷达数据作为一包DMA写入内存的第1组DMA起始地址处,并将该包DMA的大小、编号等信息写入内存的第1组DMA上报地址处;第2帧雷达数据抵达时,FPGA将数据写入第2组DMA起始地址,并将DMA包信息写入与之对应的DMA上报地址处;第N+1组数据抵达时,重新使用第1组DMA起始、上报地址。CPU启动DMA后便轮流查询各组DMA上报地址,发现DMA上报后便可根据DMA包大小获取一包DMA数据,即对应1帧雷达数据。
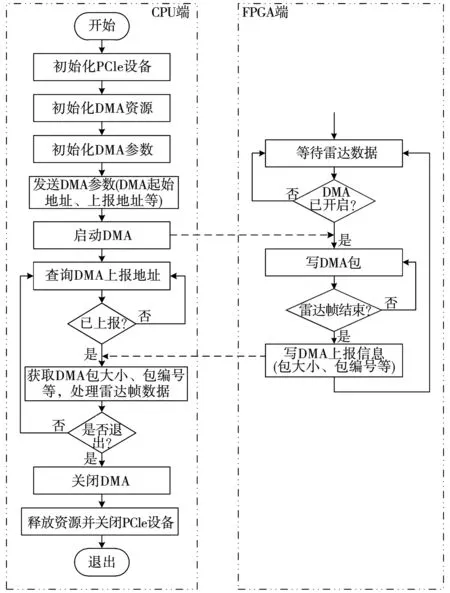
图3 优化的DMA传输流程
本设计的DMA流程具有以下优点:
(1) CPU只给FPGA发送一次启动DMA的命令,每次DMA传输的流程由FPGA(数据源端)发起,减少了DMA传输过程中CPU与FPGA的反复交互,提高了DMA传输的效率;
(2) 由FPGA(数据源端)发起DMA并决定何时结束一包DMA,可实现不定长的DMA包传输,一包DMA传输结束后通过上报的方式将该包DMA大小写入内存,便于CPU获取,更加适合雷达系统中数据流水传输的方式;
(3) 将DMA包与雷达数据帧关联起来,CPU获取一包DMA便对应一帧雷达数据,减轻了CPU解析雷达帧数据的负担;
(4) 设计多组DMA传输的起始地址和上报地址循环使用,FPGA不用等待CPU的处理结果便可以发起下一次DMA,因此FPGA收到雷达帧数据后可以很短时间内通过PCIe总线写入内存,免去了FPGA端外挂大容量DDR缓存的需求,简化了硬件设计的复杂度,降低了硬件设计与调试的难度。DMA传输地址的数量主要受驱动所能使用的内存大小限制,以一组DMA占用4 MB内存为例,1 GB内存便可以划分为256组DMA内存。
2 关键算法设计
2.1 多通道虚拟DMA设计
针对雷达系统中不同业务和控制数据进行同步传输或采集的需求[5-6],本系统设计一种多通道虚拟DMA控制器,如图4所示。本设计中的DMA控制器可通过多个数据通道接收不同数据源产生的数据,各数据通道使用独立的FIFO缓存、寄存器组、DMA起始地址、DMA上报地址,且实际使用的数据通道的数量受用户应用软件的控制[7]。

图4 多通道虚拟DMA传输
在同时多波束的雷达系统中,DMA控制器的不同数据通道可接收雷达不同波束的数据,经各自的FIFO缓存后送入仲裁模块,仲裁模块根据各数据通道已缓存的数据量和优先级进行仲裁后将待发数据送给封包模块,由封包模块封装形成IP核所要求的AXI总线的数据包格式,IP核完成数据链路层和物理层的工作。不同的虚拟DMA通道最终将不同波束的雷达数据写入内存的不同区域,从而免去了CPU解析拆分不同波束数据的过程,减轻了CPU负担。
2.2 DMA控制器设计
针对雷达系统数据流水处理的特点,本系统设计了一种由FPGA主动发起和结束一次DMA传输的流程。以单通道DMA为例,DMA控制器接收用户数据的接口包括clk(时钟)、data(数据)、valid(数据有效标志)、sof(数据帧起始标志)、eof(数据帧结束标志)。DMA写控制状态机包括RST、IDLE、MWR_H0、MWR_D1、MWR_T2、MWR_T3、MWR_REP等状态,其中复位状态RST和空闲状态IDLE为公用状态,其余状态为虚拟DMA通道内部状态,各通道内部状态均相同,调整通道数量时只须调整空闲状态到各通道状态间的跳转逻辑即可。DMA写控制状态机如图5所示。

图5 DMA写控制状态机
RST:复位状态,上电默认进入该状态;
IDLE:空闲状态,各通道切换的中转状态;
MWR_H0:写数据包头状态,向IP核发送memory write TLP的HEAD部分;
MWR_D1:写数据状态,向IP核发送memory write TLP的DATA部分;
MWR_T2:写普通数据尾状态,向IP核发送memory write TLP的DATA部分的最后一个节拍;
MWR_T3:写帧数据尾状态,向IP核发送一次DMA包的最后一个memory write TLP的DATA部分的最后一个节拍;
MWR_REP:上报状态,通过memory write TLP向CPU上报此次DMA包的信息,包括包大小、包编号等。
DMA使能打开后,状态机从RST状态进入IDLE状态;当数据帧起始到来且数据缓存够一个TLP包时,状态机跳转进入MWR_H0状态,写TLP包头;当数据有效且IP核的AXI总线ready有效时,状态机跳转进入MWR_D1状态,写TLP数据部分;当已写数据即将达到TLP的PAYLOAD时,状态机跳转进入MWR_T2状态,写完TLP最后一个节拍的数据后,跳转进入IDLE状态;否则当数据帧结束到来时,状态机从MWR_D1状态跳转进入MWR_T3状态,写完该DMA包最后一个TLP最后一个节拍的数据后,跳转进入MWR_REP状态;MWR_REP状态发送DMA上报TLP包后,进入IDLE状态。
在该状态机中每发送完一个TLP包,状态机都跳转回IDLE状态,重新仲裁下一次进入哪个数据通道的状态机。以PCIe总线中最典型的128 B TLP PAYLOAD为例,256 bit宽的AXI总线只需5个时钟节拍便能将128 B数据发完,再加上IDLE状态的仲裁判断节拍,该状态机每6个时钟节拍便可切换到下一个数据通道,因此最小的时间片单元划分得很短,可以保证各数据通道的数据得以及时写入PCIe总线。
3 性能测试与验证
本研究基于国微电子公司的FPGA芯片SMQ7VX690T和飞腾公司的CPU芯片FT1500A/16进行设计实现,FPGA端使用VHDL语言设计实现,CPU端PCIe驱动、库函数和应用程序使用C语言设计实现。测试时在FPGA中生成2路速率可控的测试数据(连续递增的计数器),同时送入两个虚拟DMA通道,上位机测试程序收到DMA数据后对DMA包内数据的连续性、DMA包间数据的连续性以及DMA包内首尾数据的差值与DMA包大小是否匹配进行校验,同时对各DMA通道所接收数据的平均速率分别进行统计。
使用传统和改进DMA传输方式的测试结果分别如表1、表2所示,表中所测速率均为最大不丢包传输带宽。可以看出,与传统DMA通过中断获取DMA完成信息相比,改进DMA使用查询方式获取DMA完成信息,DMA传输效率较稳定,不易受DMA包大小影响。

表1 传统DMA测试结果
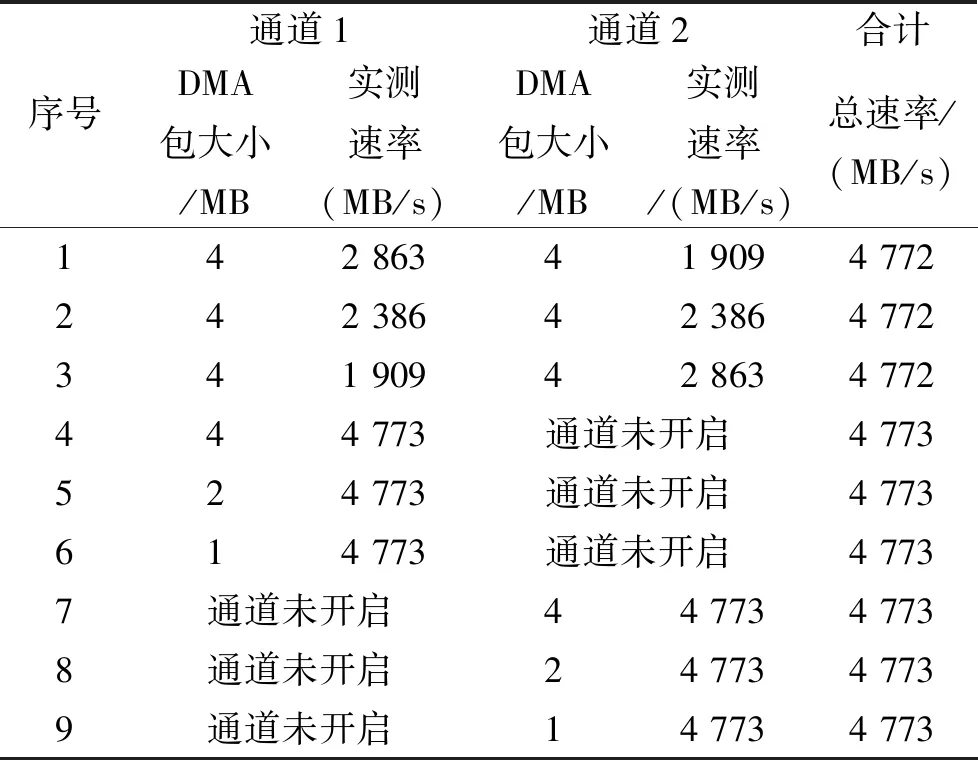
表2 改进DMA测试结果
4 结束语
本系统设计了一种基于PCIe总线的DMA传输流程:由FPGA主动发起和结束一次DMA传输,实现了不定长DMA包的数据传输;将DMA包和雷达数据帧关联起来,更加贴近雷达系统中对数据进行流水传输与处理的需求,同时支持多个虚拟DMA数据通道。实际应用中可同时将不同的业务和控制数据通过DMA方式写入内存的不同区域,极大地减轻了CPU解析雷达数据帧的负担,从而使CPU性能在雷达信息处理中得到更加充分的发挥。
