大规模C++工程单元测试性能优化研究
2022-03-30刘堂臣王雅文宫云战
刘堂臣,王雅文,宫云战
(北京邮电大学 网络与交换技术国家重点实验室,北京 100876)
0 引言
随着互联网技术的飞速发展,软件的规模迅速膨胀,软件测试的困难与代价也变得越来越大。软件测试的基础是单元测试,它可以在软件的初期就发现很多故障,并且修改它们的成本也很低[1]。单元测试的效果会在很大程度上影响到后阶段的测试,会进一步影响到产品的开发时间、费用和质量[2]。
作者所在实验室一直从事着软件测试的研究工作,现有的代码测试系统(CTS-CPP, code testing system for c plus plus)是一款基于JAVA语言编写的测试C++工程的自动化单元测试工具,它可以对被测工程进行以函数为单元的模块划分,进而对各单元进行自动测试并生成测试用例,依据语句、分支和修订条件判定覆盖准则统计出覆盖率。CTS-CPP可以测试单个文件和小规模的C++工程,但是在测试大规模C++工程(含有多个 C++文件的工程,一般超过20个总代码行数超过5 000行)时总是会出现内存溢出故障。经分析,CTS-CPP在测试C++工程时会为每一个CPP文件生成一个分析文件类对象(下文中简称被测对象),当生成的被测对象过多时将会消耗掉虚拟机所有内存从而导致内存溢出故障。如果将生成的被测对象全部序列化到磁盘中,需要用到的时候再进行反序列化操作,这样是可以解决内存溢出的故障,但是对每一个CPP文件都会对应一对I/O操作,频繁的I/O操作将会大大增加系统的测试时间[2]。
为了解决自动化单元测试工具中存在的以上问题,在测试流程中引入了缓存优化[3-7]技术,通过将部分被测对象存储到内存中以提升访问的速度。为了保证缓存的高命中率和高效性,提出了一种面向不同测试方式的缓存优化方法。当用户直接对整个工程进行测试时,采用缓存预取的方法增加缓存的命中率;当用户对单个文件进行测试时,采用改进的GDSF算法(GDSF-UT, GDSF for unit test)进行缓存的替换。实验表明,面向不同测试方式的缓存优化方法能够有效避免内存溢出故障,提升缓存的命中率,减少测试所需的时间。
本文第1节对国内外系统性能优化的相关工作进行概述;第2节介绍缓存预取模型设计;第3节设计并实现GDSF-UT缓存替换算法;第4节介绍方法应用后的实验结果分析;第5节总结全文。
1 相关工作
随着新技术的不断发展,软件规模也日益增大[8],软件的性能优化研究已成为国内外许多学者的重点研究方向,其中通过缓存优化技术来提升系统整体的性能已经成为主流的优化方式之一。
目前国内外有很多学者都在从事缓存优化的研究工作。杨冬菊[9]等人为了保证在高并发、大用户流量的场景下身份认证系统能够稳定高效的运行,提出了基于缓存的分布式统一身份认证机制。它通过将热点数据预存到缓存中以提高响应的速度,并结合复杂多样的用户行为提出了基于 Hybrid的多因素缓存替换算法。胡森森[10]等人通过总结超长指令字处理器发射宽度动态变化的特点,并利用其动态特征来驱动缓存的重构,从而达到合并处理器核或动态分离的目的。王永功[11]等人分析了信息中心网络的架构,指出多跳LRU缓存中“缓存退化”的问题,提出一种基于预过滤的O(1)复杂度的改进算法,极大的增强了内容分发效率。张艳[12]等人比较并分析传统缓存模型MRM和IRM的思想,基于字节代价以及相对流行度的概念,提出满足延迟时间、命中率和字节命中率等多种性能指标要求的缓存优化模型,并给出相关算法。刘磊[13]等人在研究缓存技术的过程中,提出了一种最小驻留价值的缓存替换算法,该算法结合对象大小和访问频率进行驻留价值的计算,优先选取价值最小的对象进行替换,但是其忽略了缓存的使用时间和物理资源的使用情况。
综上所述,针对缓存的研究,一方面是对缓存内容和实现方法的研究,另一方面是对缓存替换算法的研究[14-15]。作者对单元测试工具的优化也将从以上两方面进行。
2 缓存预取模型的设计
当用户选择直接对整个工程进行测试时,为了尽量减少I/O等待的时间,本节设计了一种缓存预取的模型,它借助一个缓存队列将缓存预取模块和文件测试模块彻底解耦,使得原来只能串行执行的两个模块现在可以并行执行。
2.1 模型构成
结合生产者-消费者的思想,本文设计的缓存预取模型如图1所示。

图1 缓存预取模型的基本构成
该模型主要由以下6部分组成:
1)控制器主要负责各部件之间的任务调度和操作控制,并且负责与文件测试模块之间的交互,使各部件有序稳定的运行。
2)协调器主要负责接收对象生产部件和对象消费部件发送过来的数据,通过数据协调双方的运行,并在参数对象中记录数据。
3)对象生产部件主要负责预先批量的从磁盘中读取对象放入缓存队列中,并记录读取对象的个数和所消耗的时间,将数据发送给协调器。
4)对象消费部件主要负责从缓存队列中读取对象交给控制器处理,并记录读取对象的个数和测试所花的时间。
5)缓存队列主要是用来存放预取出来的对象,其大小支持配置,避免对虚拟机内存的过度使用从而导致内存溢出故障。同时,它还支持同步阻塞,例如缓存队列为空时,消费方将一直处于阻塞状态,直到生产方调入下一批预取对象。
6)异常处理器主要负责对各部件运行过程中出现的异常进行捕捉处理。
2.2 预取机制
2.2.1 相关定义及符号表示
定义1:预取对象的总个数:指在测试C++工程时,需要生成的被测对象的总个数,记为CT。由于一个CPP文件对应一个被测对象,所以该参数等于被测工程中CPP文件的个数。
定义2:缓存队列的大小:指缓存队列中最多能存放的被测对象的个数,记为QS。此参数限制了虚拟机内存的使用量,避免发生内存溢出故障。
定义3:生产总批次:指从磁盘中批量预取被测对象的总次数,记为PT。为了尽量减少I/O的次数,约定当磁盘中未取被测对象个数大于等于QS时,按QS大小来预取。因此在数量上PT可以表示为:
(1)
定义4:每批生产被测对的数量:指每批从磁盘中预取到缓存队列中被测对象的个数,记为QSi,其中,i表示生产批次(1≤i≤PT)。在数量上,QSi可以表示为:
(2)
定义5:每次消费的被测对象个数:指每次从缓存队列中取出的被测对象的个数,记为CO。由于每次都是从缓存队列中取出一个被测对象用于测试,测试完毕后再取下一个,所以该参数的大小恒为1,可以表示为:
CO=1
(3)
定义6:生产一批被测对象的开始时间和结束时间:指每次批量从磁盘中读取被测对象的开始时间和结束时间,分别记为TPSi和TPEi,其中,i表示生产批次(1≤i≤PT)。
定义7:生产一批被测对象所消耗的时间:指从磁盘预取一批被测对象到缓存队列中所消耗的时间,记为ΔTPi,其中,i表示生产批次(1≤i≤PT)。在数量上,该参数等于每批生产的结束时间与每批生产的开始时间的差值,可以表示为:
ΔTPi=TPEi-TPSi
(4)
定义8:消费一个被测对象的开始时间和结束时间:指从缓存队列中取出一个被测对象的时间和被测对象测试完毕的时间,分别记为TCSi,j和TCEi,j,其中,i表示生产批次(1≤i≤PT),j表示缓存队列中的第j个元素(1≤j≤QSi)。
定义9:消费一个被测对象所需的时间:指消费方从缓存队列中取出被测对象到测试完毕所消耗的时间,记为ΔTCi,j,其中,i表示生产批次(1≤i≤PT),j表示缓存队列中的第j个元素(1≤j≤QSi)。在数量上,该参数等于消费一个被测对象的结束时间与开始时间的差值,可以表示为:
ΔTCi,j=TCEi,j-TCSi,j
(5)
定义10:消费一批被测对象所需的时间:指从缓存队列中取出第一个被测对象开始到同一批被测对象全部测试完毕所消耗的总时间,记为ΔTCi,其中,i表示生产批次(1≤i≤PT)。如图 2所示,ΔTCi,1表示消费第i批第1个被测对象所需的时间,ΔTCi,2表示消费第i批第2个被测对象所需的时间,以此类推,ΔTCi,j(1≤j≤QSi)表示消费第i批第j个被测对象所需的时间,该参数表示它们的总和。

图2 批量消费与单个消费所需时间关系示意图
在数量上可以表示为:
(6)
2.2.2 等待时间
缓存预取模型设计的核心目的就是尽量减少等待I/O的时间,为了达到这一目的,模型采取了两点关键的设计:1)将原来串行执行的缓存预取模块和文件测试模块通过一个缓存队列实现解耦,使得两模块在一定程度上可以并行执行;2)采用批量预取的方式,减少I/O的次数。
消费方在消费一批被测对象之前需要先等待生产方生产完毕,这一等待时间即为CPU等待I/O的时间,记为ΔTWi,其中,i表示生产批次(1≤i≤PT)。如图 3所示,ΔTP1表示生产第1批被测对象所消耗的时间,此时,缓存队列还为空,消费方需要等待ΔTW1的时间,然后生产方和消费方开始并行执行,ΔTP2表示生产第2批被测对象所消耗的时间,ΔTC1表示消费第1批被测对象所需要的时间,它们的差值即为ΔTW2,如果ΔTC1≥ΔTP2,说明消费第1批比生产第2批花费的时间更长,此时消费完第1批第2批已经生产完毕,因此ΔTW2等于0。以此类推,ΔTPi表示生产第i批被测对象所消耗的时间;ΔTCi-1表示消费第i-1批被测对象所需要的时间,它们的差值即为ΔTWi,如果ΔTCi-1≥ΔTPi,说明消费第i-1批比生产第i批花费的时间更长,此时消费完第i-1批第i批已经生产完毕,因此ΔTWi等于0。
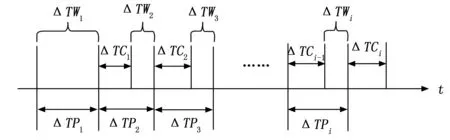
图3 生产时间消费时间等待时间关系示意图
ΔTWi在数量上可以表示为:
(7)
条件2:2≤i≤PT&&ΔTPi>ΔTCi-1;
条件3:2≤i≤PT&&ΔTPi≤ΔTCi-1;
整个测试流程等待I/O的总时间即为各批次等待I/O时间之和,记为ΔTW。在数量上,可以表示为:
(8)
2.2.3 预取流程
当单元测试工具启动对一个工程进行单元测试时,缓存预取模型的运行流程如下:
1)通过参数配置模块配置缓存队列的大小,通过控制器将配置的参数写入到参数对象中;
2)消费方和生产方同时启动,此时缓存队列为空,消费方进入阻塞状态,生产方开始预取数据,记录开始时间和结束时间,通过公式(4)计算出生产当前批被测对象所消耗的时间ΔTP1;
3)消费方阻塞ΔTW1(数值上等于ΔTP1)后被唤醒,与生产方开始并行执行;
4)消费方从缓存队列中一个一个取出被测对象并进行单元测试,记录每一个被测对象消费的开始时间和结束时间,通过公式(5)计算出消费当前被测对象所需的时间,通过公式(6)进一步计算出消费当前批被测对象所需的时间ΔTCi-1(2≤i≤PT);
5)生产方与步骤4)并行执行,预取下一批的被测对象,记录预取的开始时间和结束时间,通过公式(4)计算出生产下一批被测对象所消耗的时间ΔTPi(2≤i≤PT);
6)根据公式(7)计算出当前批的等待时间ΔTWi;
7)重复执行步骤4)~6),直到i=PT;
8)根据公式(8)计算出整个流程中等待I/O的时间。
3 缓存替换算法的设计
当用户选择对工程下的单个文件进行测试时,如果选中文件的被测对象恰好在缓存中,将会少一次I/O操作,从而节省测试的时间。所以一个高命中率的缓存替换算法就显得尤为重要。本节在目前广泛被使用的GDSF缓存替换算法的基础上,进一步考虑了单元测试的空间局部性特征和测试结果等因素的影响,提出了GDSF-UT缓存替换算法。
3.1 GDSF算法
GDSF算法[16-18]是缓存替换算法中考虑影响因素相对比较全面的一种算法,相对传统考虑影响因素比较单一的算法具有较高的命中率,因此也被广泛的使用。它综合考虑了对象的大小、对象访问频率、时间和引入对象到缓存所需的代价的影响[19],通过这些影响因素计算缓存中对象的权重,当缓存空间满时,替换出缓存中权重最小的对象[20]。计算公式为:
(9)
式中,O为缓存对象;W(O)代表缓存对象的权重;L为膨胀因子,初始值为0,每次需要缓存替换时,L被重新赋值为当前缓存中最小的权重值;Ffreq(O)为缓存对象的访问频次,初始值为1,之后每命中一次其值加1;Size(O)为缓存对象的大小;Cost(O)为将对象从磁盘取回到缓存所需的代价。
虽然GDSF算法考虑了比较多的影响因素,且容易实现,计算开销也比较小,但是用在单元测试工具中就缺乏对测试结果、测试行为特征等因素的考虑,接下来将在此算法的基础上设计面向单元测试工具的缓存替换算法GDSF-UT。
3.2 GDSF-UT算法
3.2.1 相关概念
设S={O1,O2,O3,…,Om,…,On}表示被测对象的集合,其下标1…n表示在文件系统中的相对位置。
定义1:对象距离:指两个被测对象在文件系统中相对位置的差值,记为Dmn,其中,m、n分别表示两个被测对象在文件系统中的相对位置。在数值上,该参数等于m与n差值的绝对值,可以表示为:
Dmn=|m-n|
(10)
定义2:分支覆盖率:指程序中被测试执行的判定和分支数占判定和分支总数的比率,记为BCR。
定义3:语句覆盖率:指程序中被测试执行的语句数占可执行的语句总数的比率,记为SCR。
定义4:修订条件/判定覆盖率:简称MC/DC,它是一种特殊的分支覆盖率,它不但会使用分支覆盖率报告复杂条件下的TRUE和FALSE输出,同时也会报告复杂条件下的全部分支条件输出,记为MDCR。
3.2.2 算法描述
用户在对单个被测对象进行测试时的行为特征包括:所测试的对象具有很强的空间局部性,即一段时间内连续多次的测试行为通常只发生在相邻的一些对象中,也就是对象距离越小,被选中测试的概率就越大;测试结果的好坏也将会影响再次被选中测试的概率(测试结果的好坏由定义2、3、4给出的覆盖率来评判),测试结果越好,再次被选中测试的概率就越小,测试结果越差,再次被选中测试的概率就越大。此部分的影响因素用P来表示,计算方式如下:
(11)
式中,Oi为缓存权重计算对象,Oj为访问对象。
结合用户测试行为特征的影响,改进后的算法GDSF-UT的权重计算公式为:
(12)
GDSF-UT算法在原有算法基础上进一步考虑了用户测试行为特征的影响,由此进一步优化了缓存权重的计算公式,可以看出改进后的算法在单元测试工具中具有较强的适应性。
3.2.3 算法流程
GDSF-UT算法的请求处理流程如图 4所示。

图4 GDSF-UT算法的请求处理流程图
由图 4可以看出,当用户发出对象请求时,首先判断缓存中是否有该对象。如果有,更新缓存对象的权重并返回对象;如果没有,则需要从磁盘中反序列化出对象,然后判断缓存是否已满。如果已满,替换出权重最小的对象并更新缓存对象的权重,然后返回对象;如果缓存没有满,则直接将对象放入缓存并更新缓存对象的权重,然后返回对象。
4 实验及实验结果分析
为了验证缓存预取模型和GDSF-UT替换算法的有效性,本文选取了5个不同规模的开源C++工程在CTS-CPP中进行测试实验,它们的工程属性如表1所示。

表1 C++代码工程的属性列表
4.1 实验环境
本文实验中,CTS-CPP运行在lenovo台式机上,CPU型号为Intel(R) Core(TM) i5-1038NG7,CPU频率为3.80 GHz,物理内存为8 GB,操作系统为Windows 10 专业版,编译器为VC14,开发平台为Eclipse,开发语言为Java,虚拟机最大内存设置为512 M。
4.2 实验结果及分析
4.2.1 缓存预取模型对性能的影响
为了评估缓存预取模型对CTS-CPP性能的影响,本文对5个不同规模的测试工程进行了工程级别的测试,分别记录了优化前、每次从磁盘读取和采用预取机制3种情况下对整个工程进行模块划分所需的时间,同时也统计出了每次从磁盘读取和采用预取机制2种情况下CPU等待I/O 的总时间,具体实验结果如表2所示,表中的OOM代表发生内存溢出故障。为了避免缓存队列大小对实验结果的影响,本文实验将其设置为60。
从表2可以发现:当被测工程规模较小,即内存中能存放下所有被测对象,优化前的方案模块划分的速度是最快的;当被测工程规模越来越大,优化前的方案将会发生内存溢出故障,采用每次从磁盘读取和预取机制可以有效避免内存溢出故障,但模块划分的时间也越来越长,采用预取机制相比每次从磁盘读取平均节约15%左右的时间;CPU等待I/O的总时间

表2 缓存预取模型对性能的影响评估
方面,每次从磁盘读取等待的总时间随着工程规模增大而变长,而采用预取机制的等待总时间稳定在第一批被测对象预取完成所需的时间附近,因为由实验结果发现,测试完上一批所需的时间远大于下一批的预取时间,因此测试完上一批后不需要等待I/O,即ΔTWi=0(2≤i≤PT),随着被测工程规模的增大,两种方案等待I/O总时间的差值就越大,采用预取机制节省的时间就越多。
4.2.2 GDSF-UT替换算法对性能的影响
为了评估GDSF-UT替换算法对CTS-CPP性能的影响,本文对5个不同规模的测试工程进行了文件级别的测试,分别记录了优化前、每次从磁盘读取、采用GDSF算法和采用GDSF-UT算法4种情况下抽样测试单个文件的平均响应时间,同时也统计出了采用GDSF算法和采用GDSF-UT算法2种情况下的缓存命中率,具体实验结果如表3所示。

表3 GDSF-UT替换算法对性能的影响评估
从表3可以发现:当被测工程规模较小,即内存中能存放下所有被测对象,此时的缓存命中率都为100%,优化前、采用GDSF算法和采用GDSF-UT算法测试单个文件的平均响应时间几乎相等;针对同一被测工程,在缓存放不下所有被测对象前提下,每次从磁盘读取、采用GDSF算法和采用GDSF-UT算法测试单个文件的平均响应时间依次减小;随着被测工程规模越来越大,由于缓存的大小一定,所以缓存命中率越来越低,但GDSF-UT算法的命中率比GDSF算法的命中率平均高出4~5个百分点。
5 结束语
针对单元测试工具无法测试大规模C++工程且耗时较长这一问题,在测试流程中引入了缓存优化技术,并提出了一种面向不同测试方式的缓存优化方法。对于工程级别的测试,本文提出了一种缓存预取模型;对于文件级别的测试,本文提出了改进的GDSF缓存替换算法。实验结果表明,该方法使得被测工程规模从5 000多行扩大至十几万行,大大提升了单元测试工具的性能,使其在软件规模迅速膨胀的今天具有更强的适用性。同时,该方法提升了单元测试工具的响应速度,缩短了测试所需要的时间,为单元测试工作节省了人力成本和时间成本,具有较高的应用价值。在下一步研究工作中,由于被测工程规模较大,生成的测试用例数量将会急剧增加,要执行所有的测试用例几乎是不可能的,因此,接下来将重点研究测试用例约简方法。
