基于多特征注意力卷积神经网络的旅游领域实体关系抽取
2022-03-26殷纤慧古丽拉阿东别克
殷纤慧,古丽拉·阿东别克
(1.新疆大学信息科学与工程学院,新疆 乌鲁木齐 830046;2.新疆多语种信息技术实验室,新疆 乌鲁木齐 830046;3.国家语言资源监测与研究少数民族语言中心哈萨克和柯尔克孜语文基地,新疆 乌鲁木齐 830046)
0 引言
关系抽取[1]旨在识别文本中实体词之间的语义关系.它是信息抽取中的一个重要组成部分.新疆旅游领域实体关系抽取的研究为构建旅游领域知识图谱奠定了基础.目前研究关系抽取的方法包括传统方法和深度学习的方法.传统的方法包括基于特征的方法和基于核函数的方法[2].传统方法手工依赖性较高,导致额外的传播错误且增加计算成本.近年来,循环神经网络(RNN)、卷积神经网络(CNN)等方法[3-4]被用于实体关系抽取任务中,可自动学习简单的特征,能够发现更多隐含的特征.但仍然存在以下问题:(1)文本特征提取不充分.且对于新疆旅游领域而言,语料中包含大量复杂的人名地名,仅考虑某个单个特征,不足以充分捕捉文本信息.(2)核心词表现弱.不同词语对于整个句子的语义信息影响大小不同,对所有词一视同仁,影响关系预测的结果.(3)大多用于普通领域,缺乏新疆旅游领域相关研究.缺少领域语料库,领域针对性较小.
近年来,大量传统方法被用于解决实体关系抽取问题.主要为基于特征的方法和基于核函数的方法.
(1) 基于特征的方法:该方法利用通过特征提取构造特征向量.常用的特征包括词汇特征、句法特征和语义特征.文献[5]使用了依存句法分析、词性标注两个特征,以支持向量机作为分类器.但没有考虑到位置特征及实体标签,特征提取不充分.
(2) 基于核函数的方法:该方法利用解析树、核函数等丰富句子的句法信息.文献[6]将语义相似度嵌入树核中实现关系抽取.这些方法增强了模型的泛化性,但特征提取耗时耗力,扩展性不强.
目前,解决实体关系抽取问题所用的两大主流的深度学习方法为卷积神经网络(CNN)、循环神经网络(RNN),它们是解决实体关系抽取问题的两大主流的深度学习方法.
Zhang等[7]提出BiLSTM来模拟一个完整的、连续的单词信息的句子.但LSTM无法进行平行化输入,局部信息表示不充分.Zeng等[8]采用CNN实现关系抽取,且首次引入位置标签.Zhou等[9]2016年将注意力机制与双向LSTM相融合,使用位置特征作为输入特征.Wang等[10]提出将注意力机制引入到CNN中.这些方法的提出验证了注意力机制和CNN模型在解决实体关系抽取任务中的有效性.
因此本文将注意力机制与卷积神经网络相融合,提高核心词的影响力.并使用多特征融合的方法解决特征提取不充分的问题.
本文提出了一种基于多特征注意力CNN的实体关系抽取方法.其主要优点:(1)引入多个特征进行特征表示,如位置、词性及实体标签,充分提取特征;(2)将句子级的注意力机制与CNN相结合,提高核心词的权重;(3)面向新疆旅游领域,结合归纳15种实体关系.设计语料标注系统,建立小型语料关系库;(4)设计对比实验,验证本文模型优势.
1 旅游领域实体关系抽取方法
1.1 CNN的基本模型
本文模型由特征层、嵌入层、卷积层、池化层和全连接层组成,如图1所示.

图1 实体关系抽取模型
1.1.1 特征层
本文特征层用多个离散特征进行特征表示.
(1) 位置标签:文本中每个词距离实体e1和实体e2的距离.以图2中句子为例,“美丽”距离实体词“新疆”“天池”的距离分别为3和-2.

图2 表示位置关系的例子
(2) 词性特征:词性为基本语法属性,词的词性蕴含着重要信息.本文采用基于统计模型的标注方法.
(3) 实体类型:旅游领域涉及大量的地名、景点名等,且较为复杂,例如:“霍尔果斯口岸”“江布拉克”等.本文采用命名实体的标注方法,即BMEO标注.
1.1.2 嵌入层

(1)
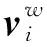
(2)
1.1.3 卷积层
卷积层对输入文本进行卷积操作,以提取句子的局部特征[11].w1,w2,…,wm是所输入句子的特征向量序列,其中wi∈Rd第i个词所包含所有特征向量.假设有一个权重向量参数化的滤波器,权重向量由Wconv∈Rcd表示,其中c表示滤波器的长度,因而输出序列为
hi=f(Wconv·wi:i+c-1+b).
(3)
其中i=1,2,…,m-c+1,操作“·”代表点乘,b是偏倚项,f是线性整流函数(ReLU).
1.1.4 池化层
本文使用最大池化层将卷积层中每个滤波器的输出转化为一个大小固定的向量[12],卷积层的输出长度(m-c+1),依赖于句子中词m的个数.
z=max[hi].
(4)
通过池化层操作得到句子的全局特征,保留句子中最有用的全局特征.
1.1.5 全连接层
本文使用池化层的输出来预测实体关系的类型[13],使用权重矩阵Wfconn∈Ro×le将z转化为分数
s=Wfconnz.
(5)
其中zi∈Rle表示池化层的输出,s表示得分.使用softmax函数将s转化为关系概率
(6)
其中且s=[s1,…,so],o表示为待分类的关系总数.当已知分类标签为y时,损失函数Lsoftmax定义为
Lsoftmax=-∑ylogp.
(7)
其中:p表示关系概率;y表示one-hot向量.
1.2 注意力机制
本文发现句子中每个词语对于整个句子的语义信息影响不同,一部分词影响较小,而另一部分词则能决定整个句子的语义信息.因此本文采用注意力机制,如图2上部分所示.计算注意力公式为:
(8)
(9)
(10)
其中:函数βi表示当前词与设定关系的匹配程度;E={e1,e2};ai,1表示实体1的权重;ai,2表示实体2的权重;bα为偏倚项;权重为ai.
1.3 模型训练
本文采用L2正则避免过拟合问题,使用目标函数Lsoftmax与L2合并,对损失函数权重进行正则化.
(11)
其中:λ表示正则化参数,‖‖F表示Frobenius范式.需要优化的参数为Wemb,Wconv,Wfconn,b,bα.使用Kingma和Ba在2015年提出的Adam算法作为优化器.
2 实验部分
为评估本文模型在新疆旅游领域进行实体关系抽取研究的有效性,在建立的新疆旅游领域小型语料关系库中进行实验.
2.1 数据集
本文实验从去哪儿网、新疆旅游官网等旅游型网站中爬取有关新疆旅游领域的数据,通过对语料的预处理操作,最终获得标注数据5 028条.训练数据3 028条,其余2 000条为测试数据.
(1) 定义实体对:总结定义了15种旅游领域实体关系对,其中“民族-美食”、“民族-习俗”等实体对均为新疆文化特色.如表1所示.
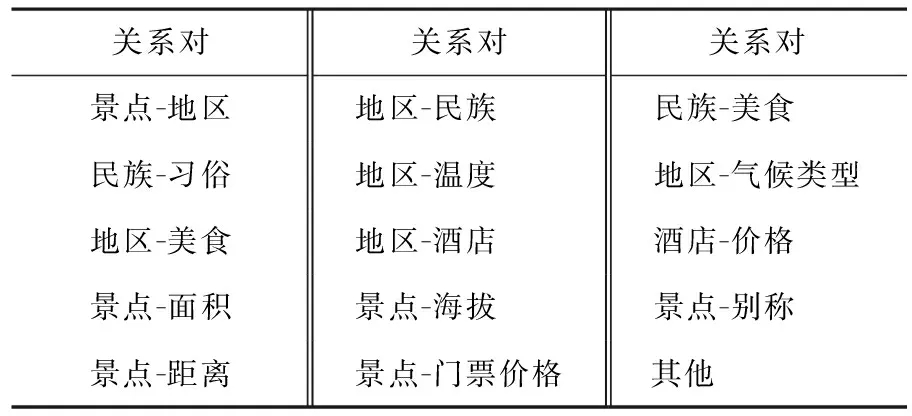
表1 实体关系对
(2) 开发语料标注系统:设计并开发语料标注系统,进行半自动化的语料标注,如图3所示.
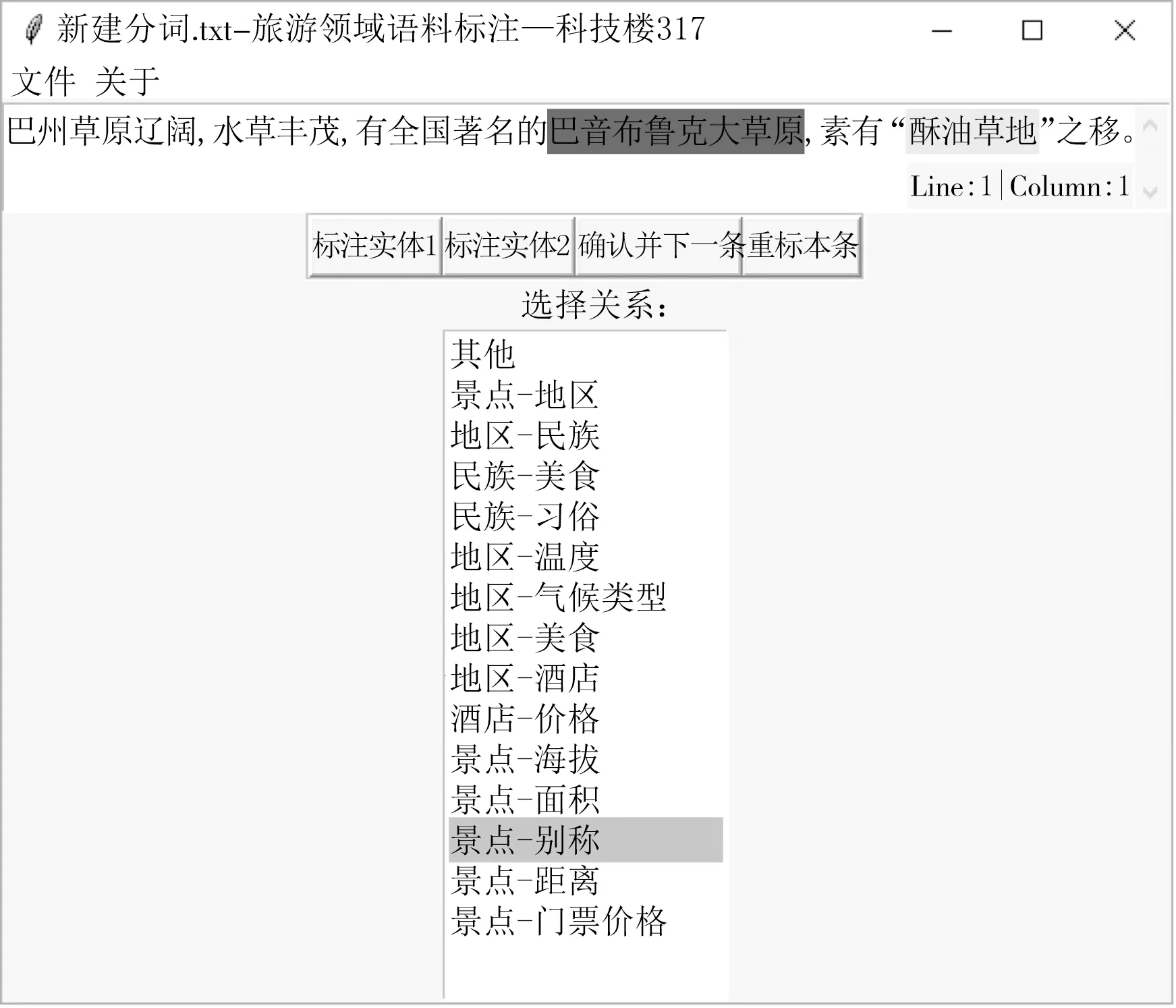
图3 语料标注系统
(3)参数设置:词向量为300,位置向量为20,词性向量为17,实体标签向量为20,卷积窗口大小为[3,4],卷积核数目为100,L2正则化参数为0.000 1.
2.2 实验结果
2.2.1 多特征的有效性验证
本文共使用了多个特征进行特征表示,为了研究每个特征对本文模型的贡献,依次加入不同的特征对模型的性能进行比较,结果如表2所示.

表2 特征对于训练模型的影响效果 %
表2中,WV为使用词训练模型训练好的旅游领域词向量.PF(位置特征)、POS(词性特征)、NER(实体标签),在WV的基础上添加其他特征.其中位置特征最有效,F1值提高了4.03%.词性影响不明显.实体类型考虑了领域复杂名词等,使F1值提高了1.95%.
2.2.2 注意力机制的有效性验证
为了验证注意力机制对关系抽取模型的性能影响,本文模型与未加注意力机制的CNN做了对比试验(见图4).

图4 模型验证
本文方法相较于CNN效果更佳,迭代次数在5~15次内有大幅度提升,迭代次数大于20趋于稳定.最终ATT-CNN的F1值比CNN高3.19%.验证了引入注意力机制能够提升实验F1值.
2.2.3 与同类实验对比
为了比较本文提出的关系抽取模型的性能,与目前关系抽取模型进行了对比实验.
本文实验与表3中的实验进行了对比,本组实验中分别选了SVM、CNN、ATT-CNNN、ATT-BiLSTM 等模型做了对比,不同的模型所选的特征不同,实验结果表明:本文提出的多特征融合的ATT-CNN模型,在实体关系抽取任务中F1值高于其他方法.

表3 同类实验对比
3 结语
本文采用了ATT-CNN模型,并使用了位置、词性、实体类型3个特征进行特征表示.针对新疆旅游领域进行实体关系抽取研究.此外,建立关于新疆旅游领域的小型语料关系库,并总结使用15种关系对.通过实验分析验证了本文模型的有效性.
未来的工作主要为:(1)扩展语料库,研究其他特征对模型的影响.(2)本文通过预先定义的关系对来实现关系抽取任务,今后研究如何将本文方法引入到开发领域,并且自动发现实体关系对.
