基于多任务联合学习的入侵检测方法
2022-03-26刘胜全
刘 源,刘胜全,刘 艳
(新疆大学信息科学与工程学院,新疆 乌鲁木齐 830046)
0 引言
近些年来,互联网技术飞速发展且逐渐成熟,网络所带来的便利已经渗透到了人们生产生活中的各个方面,随之而来的是网络攻击的风险也急剧增加.网络攻击的罪魁祸首之一就是网络入侵,现有的入侵检测技术基于模式匹配,准确率高但却需要人工建立特征库,而基于深度学习的入侵检测方法无须人工提取特征,但对于少数类攻击检测率低,因此如何提高少数类的识别率是目前网络入侵检测方法面临的主要难题.
在文本分类领域,TextCNN取得了非常好的分类效果[1],它采用一个主任务加两个辅助任务完成整个分类模型的构建,借助辅助任务来改善原任务模型的性能.
相较于传统机器学习方法,深度学习在特征提取方面有着更好的表现,近年来随着深度学习的逐渐成熟,入侵检测方法也逐渐向深度学习靠拢.Javaid等[2]采用稀疏自编码器做特征提取,取得了比传统机器学习更好的结果;Tan等[3]将预训练深度置信网络(DBN)引入入侵检测,同时与传统机器学习方法进行了对比;杨昆明等[4]在采用深度置信网络的情况下,使用SVM代替SOFTMAX分类器,在二分类上取得了更好的结果;Deng等[5]将卷积神经网络(CNN)应用于入侵检测,将流量信息转换为灰度图再通过CNN提取特征,加强了模型的通用性,同时取得了较好的成果;Kim等[6]使用了长短时记忆网络(LSTM),同时提出了一种神经语言模型,将系统调用序列建模为一种自然语言,降低了误报率;方圆等[7]提出了一种混合模型,将卷积神经网络和长短时记忆网络串联起来,先经过CNN提取出网络流量的空间特征,再通过LSTM对已经时间序列化的数据进行训练最终得到结果.
上述深度学习方法均采用单一任务,即对模型只进行二分类或多分类训练,该方法虽然对常见类型能够有较好的判别,但流量数据不平衡性导致少数类别召回率低的问题仍然存在.本文结合注意力混合模型与多任务学习,对高维流量特征的权重进行初始化,从众多信息中选择出更关键的信息.再分别提取空间特征与时序特征,将两部分特征进行融合,从而获得更加全面的流量信息,通过辅助任务的加入,降低数据不平衡性的影响以提升分类准确率和泛化性能.
1 模型简介
1.1 多任务学习
多任务学习的主要目标是通过多个相关的不同任务,来优化共享网络的参数,多任务学习能够更好地挖掘任务之间具有的联系[8].
多任务学习包括联合学习、自主学习和带辅助任务的学习.其中带辅助任务的学习方式通过划分任务为主任务和辅助任务,利用辅助任务的信息来改进主任务的学习性能,从而可以学习到多个任务上的统一表示,进而实现对辅助任务的注意力机制.因此通过多任务学习,能够改善样本不平衡性带来的分类误差.多任务学习模型公式为
(1)
其中:wm为第m个任务的一列的权重,xm,j为第m个任务的第j个样例,ym,j代表对应的输出,εm代表噪声.式中多个任务的信息共享是通过共享特征与共享隐层神经元实现的,所有任务都由某种结构相连接,通过同时优化多个损失函数,使网络的泛化能力更加强大.
1.2 胶囊网络
传统的卷积神经网络在池化层会丢失大量的信息,这就导致网络的输入微小变化的敏感度降低,其输出几乎是不变的.但是我们希望网络能够保留更多的细节信息.Sabour等[9]提出了胶囊网络结构克服了这些缺点.胶囊网络提供了一个实体间局部到全局的关系方法,在胶囊网络里,细节的层次结构信息会被网络提取出来,由于提取的细节信息更多,所以胶囊网络仅需少量的数据即可达到更好的效果.
胶囊网络由胶囊层组成,每一层都被划分为一组称为胶囊的神经元,胶囊的输入输出均为向量形式.为使胶囊的输出向量表示为某种概率,Hinton使用了压缩函数(Squashing)对向量进行归一化,保证向量的长度在0,1之间.
图1为胶囊网络示意图,其中squash函数的公式为
(2)
式中:vj为胶囊j的输出,sj为胶囊j所有输入向量的加权和,即前层胶囊的输出向量,其公式为
(3)
其中cij为耦合系数,由softmax函数计算求出,其初值为bij,cij的公式为
(4)
其中bij是胶囊i耦合到胶囊j的对数先验概率,它依赖于两个胶囊的位置和类型.通过计算上一层中每个胶囊的输出vj与预测μij之间的一致性,重新确定耦合系数.
(5)
通过动态路由算法,不断迭代,最终计算出胶囊的输出vj.

图1 胶囊网络结构
1.3 简单循环单元
简单循环单元(SRU)是由Tao等[10]于2017年提出.GRU网络能够很好地解决传统循环神经网络误差梯度随着时间长度的增加而逐渐变小难以收敛的缺点,但是传统RNN结构如LSTM和GRU在计算当前时间步状态时需要上一个时间步的隐层输出,这严重限制了RNN模型的并行计算能力,拖慢了整个序列的处理速度.而SRU对GRU的门结构进行了修改,引入了Skip-Connection结构[11].使当前时间步计算不再依赖上一个时间步的隐层输出,大大加强了并行计算能力.SRU的单元公式为
(6)
ft=s(Wfxt+bf);
(7)
rt=s(Wrxt+br);
(8)
(9)
ht=rt·g(ct)+(1-rt)·xt.
(10)
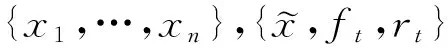
1.4 联合学习模型
入侵检测问题可以看作一个多分类问题,其问题可以形式化如下:存在一个流量空间X以及固定的类别集合L=(l1,l2,l3,…,lj),对于训练集D,D⊆X,每条流量可以表示为〈d,l〉⊆X×L,我们的目标是训练一个分类器C:X→L,对于给定的d⊆X,确定C(d)⊆L.
胶囊网络没法有效提取上下文数据长期的依赖关系,但却能很好地提取局部层次结构特征.SRU能够提取数据间的时序依赖关系,但却对局部层次特征表现较差.通过结合不同模型的特点,更加全面提取数据特征[12].而为了解决数据分布不平衡带来的收敛速度慢、泛化性能差等影响,引入了辅助二分类任务,通过二分类判断流量是否为入侵流量,将单任务学习中难以提取的入侵特征引入作为辅助信息,通过与多分类任务学习相同的共享网络结构,来调整共享隐层的权重,减小模型对多数类别的偏向,增强其泛化能力,联合学习模型的工作流程如图2所示.
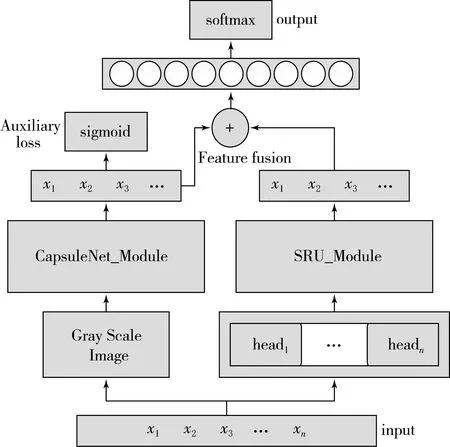
图2 混合模型结构
(1) 对78维的流量数据进行归一化,其中xmin,xmax分别代表X每个分量的最小和最大值.
(11)
(2) 将归一化后的数据一份转化为9*9的灰度图输入胶囊网络模块得到特征向量Hc,一份通过注意力层后输入SRU模块得到特征向量Hr.
(3) 将Hc与Hr拼接,得到混合后的向量Hf.
(4) 通过全连接层由softmax分类器分类.
对于多任务损失函数来说,X为输入向量,Yi为第i个任务的标签,其总损失可以表示为
(12)
其中λi为损失Li的权重,是对于每个任务所做贡献的衡量,手动调节λi十分耗时,本文引入动态权重搜索.
(13)
(14)
首先计算相对下降率wk,即每个子任务与前一轮epoch损失的比值,然后除以超参T,T越大代表个任务间权重差异越小,最后进行exp映射后,计算各个损失所占比.
为了提高少数类的召回率,额外引入一个二分类任务,其中Lc为多分类损失、Lbc为二分类损失,其公式为
Lmc=-α(1-softmax(H))γ·
log(softmax(H));
(15)
Lbc=-α(1-D(H))γlog(D(H))+
(1-α)D(H)γlog(1-D(H)).
(16)
该公式在原始交叉熵损失上加入平衡因子α和γ对损失函数进行约束,平衡因子α用来平衡正负样本,当α趋近1时,1-α趋近0,即负样本比正样本占比小.而平衡因子γ则对样本易分程度进行了平衡,由于D(H)的输出在(0,1)之间,因此当γ>1时,D(H)γ增大而(1-D(H))γ减小,即置信度高则该样本易分,其损失会降低,使模型更关注难分样本.
2 实验方法与分析
2.1 数据预处理
大多数入侵检测模型所采用的数据集KDD-99或NLS-KDD距今已有十多年[13].然而,对于当前的网络威胁环境,这些数据集并不能全面反映网络流量和入侵攻击,考虑到网络数据集应该具有时效性,本文采用了CICIDS2017数据集[14].该数据集由加拿大网络安全研究所提供,其融合了真实的正常和攻击流量.更适合模拟现有网络环境.数据集中所包含攻击类型见表1.其中KDD99与NSL-KDD数据集中并不包含Browser、Bdoor以及DNS攻击类型,而CICIDS-2017包含了现在流行的大多数攻击.因此采用该数据集训练的模型更加适应现有的网络环境.

表1 数据集包含攻击类型
CICIDS2017数据集十分庞大.其包含3 119 345条数据,15个类别标签(14个攻击类型+1个正常类型).删除缺失数据后仍有2 830 540条数据.该数据集虽然包含了大多数攻击场景,但是其缺点是数据分布不平衡.各类别的分布如表2 所示.

表2 入侵类型分布
可以看出BEGIN的占比为83.4%,HeartBleed的占比为0.000 39%,数据集非常不平衡将会对分类器的分类性能有严重影响,分类器会更加偏向将样本判别为多数类,而忽视少数类别,因为这样能够更加轻易获得较低的损失值.因此,在进行训练过程前,需要对数据集的不平衡性进行处理.最简单的方法即为重新划分类别,该数据集中正常类很难再细分,于是可以考虑将少数攻击类合并为新的类别,调整后的类别分布如表3所示.
从表3中可以看出攻击类别的占比有着明显的提升,从而大大降低了类别的不平衡性.由于类别的分布有着很大的不平衡性,正样本是负样本的数倍之多,故模型采用分层K折交叉验证,即在每一折中都保持着原始数据中各个类别的比例关系.选取K为3,将2/3用于训练,1/3用于测试.训练3次,取其平均值.
2.2 实验设置
本文在Ubuntu18.04环境上进行,采用Keras深度学习框架,后端实现为TensorFlow-ROCm,集成环境为Anaconda3.系统硬件配置如下:CPU为AMD ryzen 3600x,内存为16 GB,GPU为AMD RX580.具体设置参数见表4和5.

表4 胶囊网络参数设置

表5 SRU网络参数设置
联合学习模型中,胶囊网络和SRU单元的输出向量均为64维,经过拼接后为128维向量,该向量通过一层前馈全连接网络后由softmax分类.层与层之间加入Layer Normalization对数据进行归一化,使其分布一致,避免梯度消失,加快收敛速度.
本文通过混淆矩阵(见表6)分别计算准确率 (A),查准率(P),查全率 (R),和F1值(F1)来评估模型的性能.
(11)

表6 混淆矩阵
(12)
(13)
其中P是模型预测为正例中预测正确的比重,R是所有真实值是正例的结果中预测正确的比重,F1值是对查准率和查全率进行了综合考虑,F1值越高,说明模型越稳健,性能越好.
2.3 实验结果与分析
2.3.1 收敛性分析
图3和4展示了多任务联合模型训练时的准确率和损失值的变化趋势,其中acc和loss分别代表代表准确率和损失.在20次的迭代训练中,准确率稳定上升直至训练后期趋于平稳,同时损失值也平稳地下降,10轮之后基本稳定不再变化,表明本模型良好且能够快速收敛.训练使用完整数据集,对比试验也采用相同的数据集和测试集.
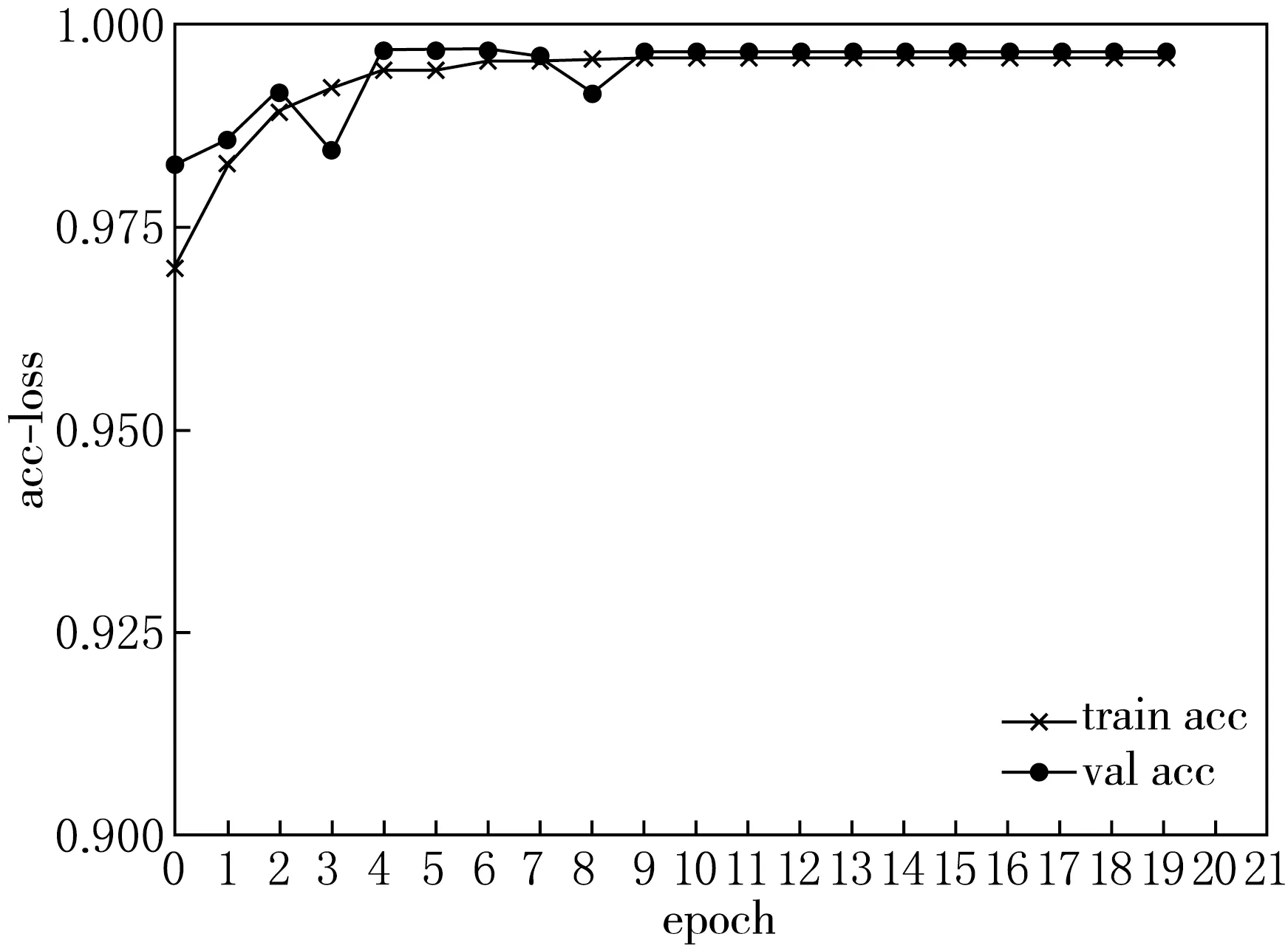
图3 多任务联合模型的准确率

图4 多任务联合模型损失
2.3.2 模型对比分析
为了验证本文模型对入侵检测有着更好的效果,分别对比了文献[5]中基于卷积神经网络的入侵检测方法,文献[6]中基于长短时记忆网络的方法以及文献[7]中基于CNN+GRU混合模型的方法.同时也对比了本文模型添加辅助任务和不添加辅助任务的情况.通过对比各个模型的性能指标来分析模型的优缺点,实验结果如表7所示.

表7 不同模型的性能对比 %
可以看出在单一模型中LSTM和CNN模型的性能基本相同,而由于CNN+GRU混合模型能够提取更加丰富的特征,故所有类别的F1均高于单一模型.但是3个模型对Infiltration和WebAttack类的检测上均表现较差,尤其是 Infiltration类,这3种方法均无法检测出该类.对于不添加辅助函数的本文模型,性能与CNN+GRU模型类似,对Infiltration类别的判断有所提高,而添加了辅助任务的多任务联合学习模型不仅在P,R,F1值方面均优于对比模型,同时能够很好的检测出Infiltration与WebAttack这样的少数类别.这是因为数据集中恶意样本数相对较少,而少数类别对神经网络的权重影响过于小,损失函数通过忽视少数类别能够更简单的降低损失值,因此本文方法引入一个二分类的辅助损失,通过该损失函数来调整网络共享层的权重,使其能够注意到少数的攻击类别.
2.3.3 辅助损失验证分析
在多任务联合学习模型中,需要对每个任务的损失进行权重分配,必须保证辅助损失能够微调模型权重参数但又不能主导整个模型的训练[15].通过使用动态损失权重和不使用动态损失权重进行模型训练来确定该方法是否有效,结果如表8所示.可以发现使用动态损失权重的模型F1值明显优于不使用该方法.其动态调整二分类损失的比重可以更好地调整模型参数,提高少数类别的召回率.

表8 动态损失权重 %
3 结论
本文提出的多任务联合学习方法,很好地解决了流量数据中少数类别检测难的问题,将CapsNet与SRU相结合提取更加全面的流量信息,最后结合辅助任务来提升少数类的召回率.通过对比不同方法的检测结果,结果显示本文方法在大幅提高少数类别召回率,同时查准率也较其他方法有所提升.由于模型针对特定数据集训练,未考虑真实网络环境下的流量数据,所以下一步研究将着重于真实情况下的网络入侵,建立一个泛化能力与抗干扰能力更强的入侵监测系统,来验证多任务联合学习方法的性能.
